消息队列 CKafka 版的事件中心能力支持对实例运行过程中发生的各类运维事件、诊断事件、Broker 变更事件进行集中的管理、存储、分析和可视化展示,便于日后查询、审计和回溯。同时还支持事件告警能力,您可以为关键事件配置告警规则,将事件详情发送给目标对象,便于运维人员及时处理。
开通事件存储
为便于保存和回溯事件记录,建议您在腾讯云可观测平台的事件总线中,为 default 云服务事件集开通事件存储能力。开通后,CKafka 相关事件可按照配置的存储时长进行保存,便于后续查询、审计和问题排查。事件存储能力由腾讯云可观测平台提供,使用规则和计费说明请以腾讯云可观测平台页面展示为准。
您可以登录腾讯云可观测平台控制台开启事件存储,并根据业务需要设置事件存储时长。
1. 登录 腾讯云可观测平台控制台。
2. 在左侧导航栏选择 事件总线 > 事件集 > 云服务事件集 > default 事件集,点击开通事件存储功能。

查看事件记录
开通事件存储后,您可以在 CKafka 控制台或腾讯云可观测平台中查看已存储的事件记录。
1. 登录 CKafka 控制台。
2. 在左侧导航栏选择实例列表 ,单击目标实例的“ID”,进入实例详情页面。
3. 在页面上方选择事件中心下的事件查询页签,设置好时间范围,选择需要查看的事件类型,即可筛选出对应的事件记录。支持通过完整事件 ID、事件类型、影响对象进行筛选。
注意:
事件中心已上线新版页面。新版页面支持更完整的事件记录查询、事件详情展示和历史事件回溯能力。控制台会根据开通状态展示对应页面。旧版事件中心后续将逐步下线,建议尽快开通事件存储功能,使用新版页面。
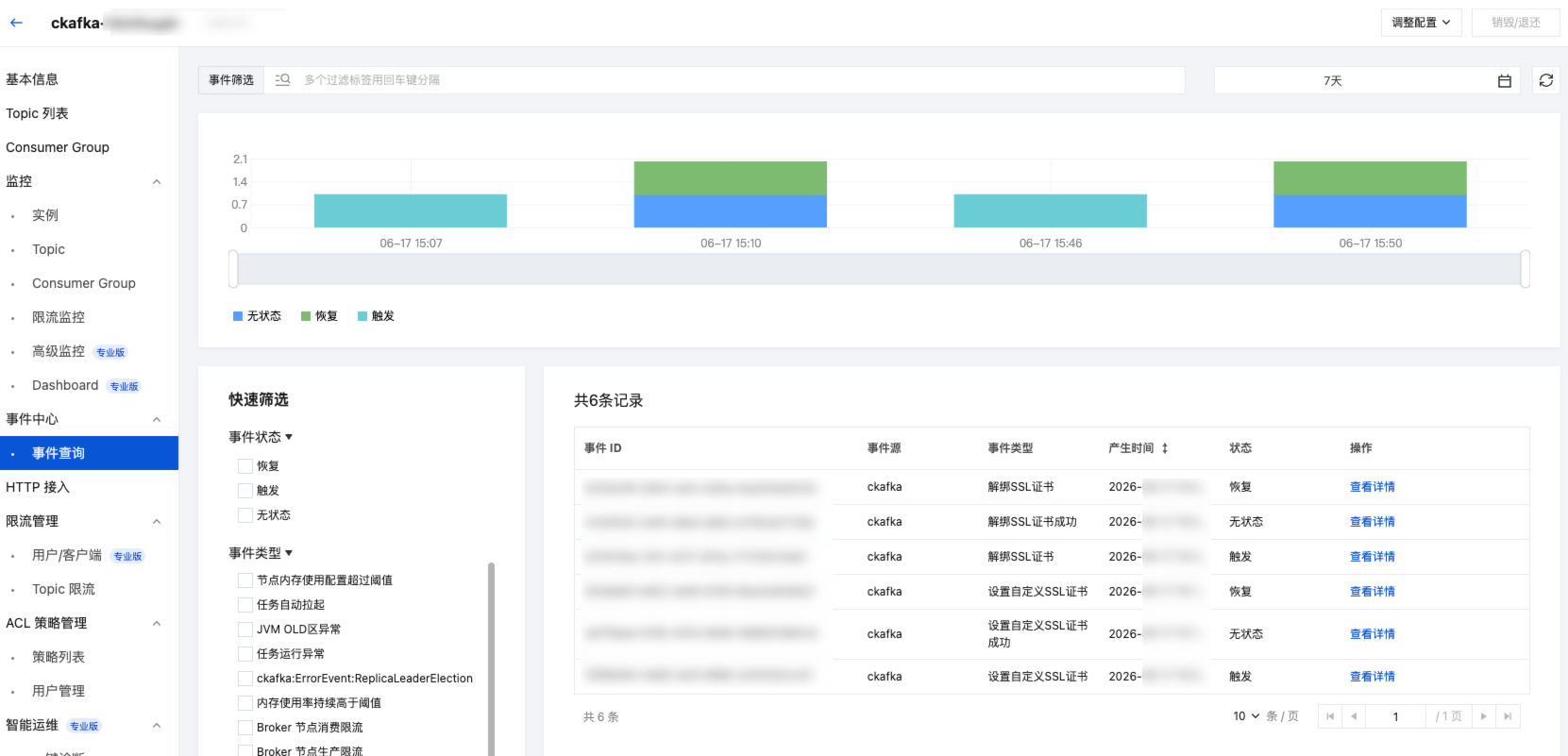
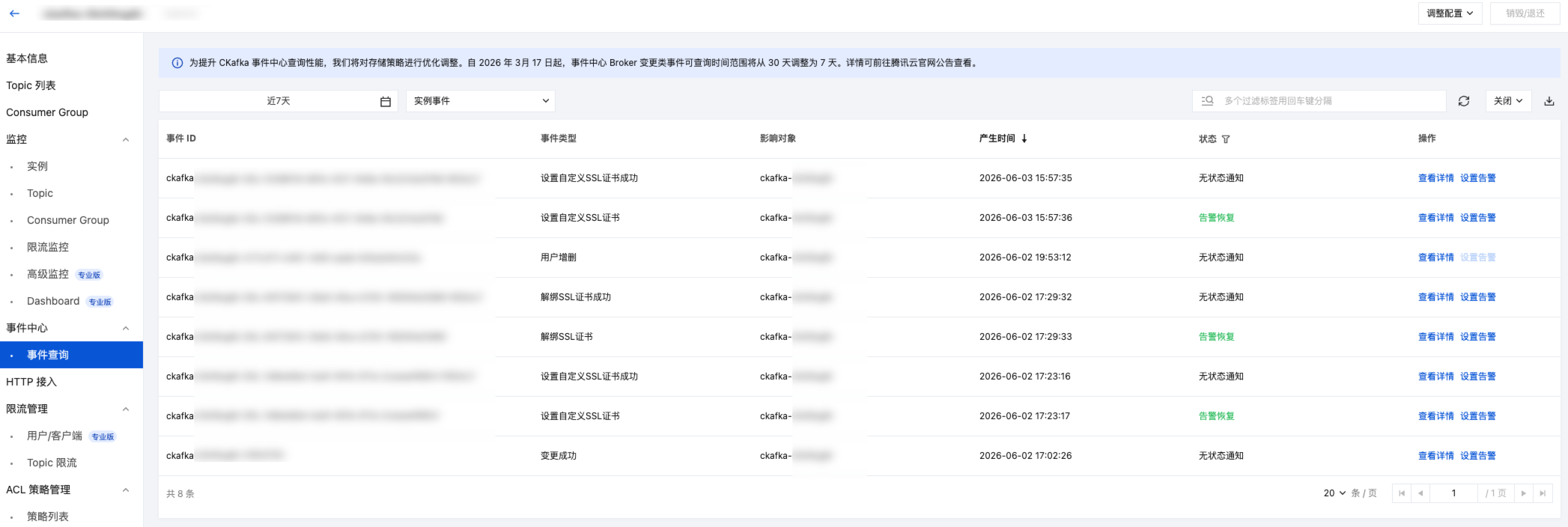
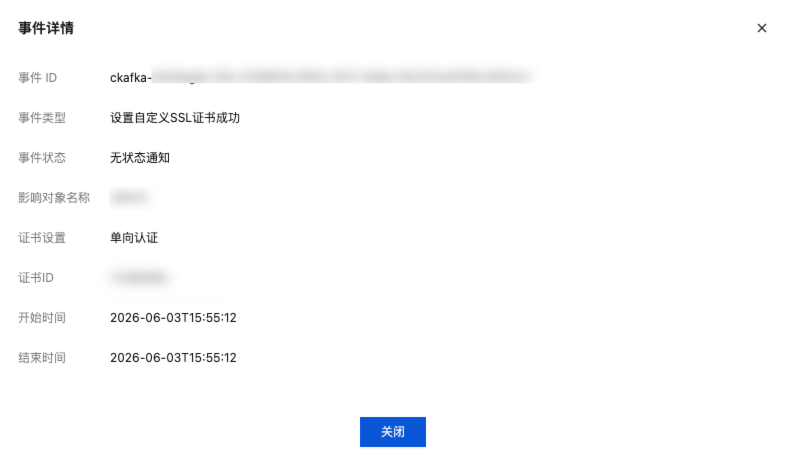
4. 在事件详情页面,单击目标事件操作列的查看详情,您可以在弹窗里查看详细的事件记录。
配置事件告警规则
1. 登录腾讯云可观测平台控制台。
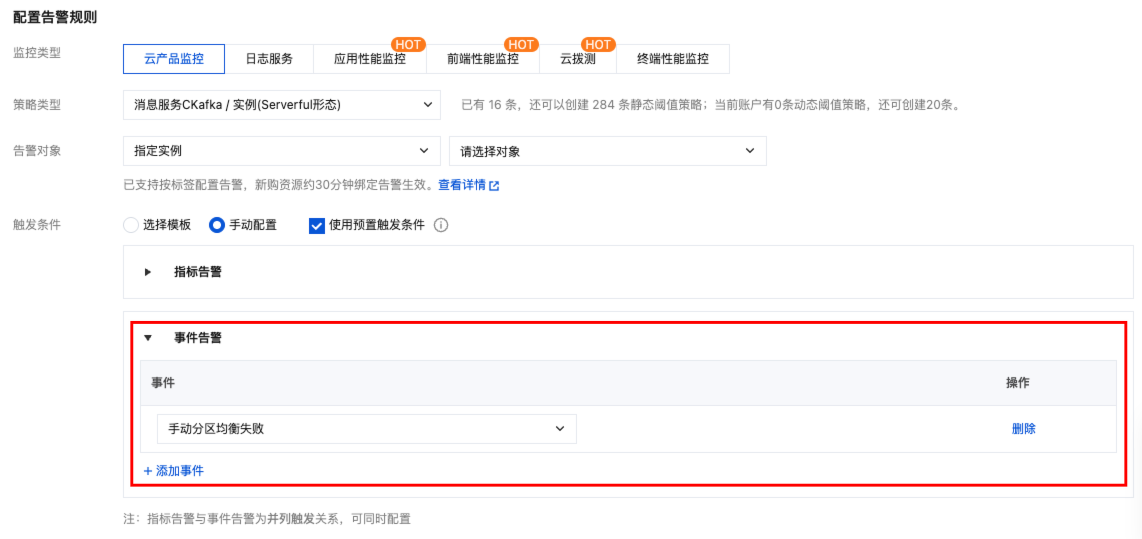
2. 在左侧导航栏选择告警管理 > 告警配置,在左上角单击新建策略 > 自定义告警策略,填写好策略名称后设置告警规则。
监控类型:云产品监控
策略类型:选择消息服务 CKafka 下的相关策略类型。
告警对象:选择需要配置告警策略的 CKafka 实例。
触发条件:支持选择模板和手动配置,默认选择手动配置。此处选择事件告警,并添加要配置告警的事件。
3. 点击下一步:配置告警通知,选择通知模板,也可以新建通知模板,设置告警接收对象和接收渠道。
4. 单击完成,即可完成告警规则的配置。
CKafka 支持的事件类型和处理建议
CKafka 事件中心提供实例事件、诊断事件和 Broker 变更事件三类监控能力。事件状态分为有状态和无状态:有状态事件用于记录任务执行过程,可展示事件进行中的相关状态;无状态事件用于记录某一时间点发生的事件。
说明:
有状态事件的状态展示与腾讯云可观测平台的事件告警状态保持一致。事件触发时状态为“告警触发”,事件正常结束时状态为“告警恢复”。其中,“告警触发”仅表示事件开始执行,不代表实例发生异常;“告警恢复”表示事件已正常结束。
CKafka 部分任务会产生一组成套事件,例如“升配”“升配成功”“升配失败”。其中,“升配”用于记录任务执行过程,“升配成功”表示任务已完成,“升配失败”表示任务未成功执行。配置事件告警时,建议优先为您关注的失败类事件配置告警,例如“升配失败”“降配失败”“设置自定义 SSL 证书失败”等,以便及时感知任务异常并处理。
事件告警通过腾讯云可观测平台实现,部分事件支持配置告警策略,并可通过通知模板将事件详情发送给指定接收对象。
实例事件
事件中文名称 | 事件英文名称 | 事件状态 | 事件描述 | 处理方法和建议 |
Kafka 版本升级 | KERNEL_VERSION_UPGRADE | 有状态 | 用户通过控制台或云 API 发起版本升级后产生,用于记录实例升级到目标 Kafka 版本的执行过程。 | 关注升级期间客户端连接、生产消费是否正常,确认升级操作是否符合预期。 |
Kafka 版本升级成功 | KERNEL_VERSION_UPGRADE_SUCCEED | 无状态 | 实例已运行在目标 Kafka 版本。 | 确认实例版本符合预期,观察升级后业务运行情况。 |
Kafka 版本升级失败 | KERNEL_VERSION_UPGRADE_FAILED | 无状态 | 实例未升级至目标 Kafka 版本,可能与实例状态、版本兼容性或任务执行条件有关。 | 查看失败原因,确认实例状态和版本兼容性后重试。 |
可用区变更 | INSTANCE_ZONE_UPGRADE | 有状态 | 用户发起实例可用区变更后产生,用于记录实例迁移到目标可用区的执行过程。 | 关注变更期间客户端连接和生产消费是否正常。 |
可用区变更成功 | INSTANCE_ZONE_UPGRADE_SUCCEED | 无状态 | 实例已迁移至目标可用区。 | 确认实例可用区符合预期,观察业务访问是否正常。 |
可用区变更失败 | INSTANCE_ZONE_UPGRADE_FAILED | 无状态 | 实例未迁移至目标可用区,可能与目标可用区资源、实例状态或任务执行条件有关。 | 查看失败原因,确认目标可用区资源和实例状态后重试。 |
磁盘动态消息保留策略 | MESSAGE_RETENTION_PERIOD | 无状态 | 磁盘水位较高时,系统动态调整消息保留策略以降低磁盘压力。 | 评估是否需要升配磁盘规格,或调整消息保留时间。 |
磁盘自动扩容 | INSTANCE_STORAGE_CAPACITY | 无状态 | 磁盘水位较高时,系统自动扩展实例磁盘容量。 | 关注磁盘使用趋势,评估是否需要进一步升配磁盘规格。 |
实例创建成功 | CREATE_SUCCEED | 无状态 | 实例资源已创建完成,可开始进行接入配置。 | 确认实例规格、网络、Topic、用户权限等配置是否符合业务预期。 |
标准版转专业版 | STANDARD_TO_PROFESSIONAL | 有状态 | 用户发起实例版本转换后产生,用于记录标准版转换为专业版的执行过程。 | 关注转换期间业务运行情况,并确认费用变化是否符合预期。 |
标准版转专业版成功 | STANDARD_TO_PROFESSIONAL_SUCCEED | 无状态 | 实例已转换为专业版。 | 确认实例版本和规格符合预期,观察生产消费是否正常。 |
标准版转专业版失败 | STANDARD_TO_PROFESSIONAL_FAILED | 无状态 | 实例未完成版本转换,可能与实例状态、资源条件或任务冲突有关。 | 查看失败原因,确认转换条件后重试。 |
自动化分区均衡 | INSTANCE_PARTITION_REBALANCE | 有状态 | 系统自动触发分区迁移,用于优化分区分布或负载均衡。 | 关注迁移期间生产消费时延,避免在业务高峰期频繁变更。 |
自动化分区均衡成功 | INSTANCE_PARTITION_REBALANCE_SUCCEED | 无状态 | 分区已按系统策略完成重新分布。 | 检查分区分布和流量均衡情况。 |
自动化分区均衡失败 | INSTANCE_PARTITION_REBALANCE_FAILED | 无状态 | 分区未完成重新分布,可能与 Topic 状态、Broker 状态或实例负载有关。 | 查看失败原因,确认 Topic、Broker 和实例负载状态后重试。 |
手动分区均衡 | MANUAL_INSTANCE_PARTITION_REBALANCE | 有状态 | 用户手动发起分区均衡任务,用于调整分区或 Leader 分布。 | 关注迁移期间生产消费时延,操作后验证流量均衡情况。 |
手动分区均衡成功 | MANUAL_INSTANCE_PARTITION_REBALANCE_SUCCEED | 无状态 | 分区已按用户配置完成重新分布。 | 检查分区 Leader 分布和业务流量是否符合预期。 |
手动分区均衡失败 | MANUAL_INSTANCE_PARTITION_REBALANCE_FAILED | 无状态 | 分区未按用户配置完成重新分布,可能与任务条件或实例状态有关。 | 查看失败原因,确认 Topic、Broker 和实例状态后重试。 |
内核小版本升级 | PATCH_VERSION_UPGRADE | 有状态 | 实例触发内核小版本更新,用于修复缺陷、优化能力或完成安全更新。 | 检查版本兼容性,关注升级期间客户端连接情况。 |
内核小版本升级成功 | PATCH_VERSION_UPGRADE_SUCCEED | 无状态 | 实例内核已更新至目标小版本。 | 确认版本符合预期,观察生产消费是否正常。 |
内核小版本升级失败 | PATCH_VERSION_UPGRADE_FAILED | 无状态 | 实例内核未更新至目标小版本,可能与版本兼容性或实例状态有关。 | 查看失败原因,确认实例状态和版本兼容性后重试。 |
降配 | DOWNGRADE | 有状态 | 用户降低实例规格后产生,用于记录资源规格调整的执行过程。 | 确认降配后规格是否满足业务需求,关注业务负载变化。 |
降配成功 | DOWNGRADE_SUCCEED | 无状态 | 实例已调整至目标低规格。 | 观察磁盘、带宽、连接数和生产消费负载,避免资源不足。 |
降配失败 | DOWNGRADE_FAILED | 无状态 | 实例未调整至目标低规格,可能与实例状态、任务冲突或降配条件有关。 | 查看失败原因,确认实例资源和任务状态后重试。 |
升配 | UPGRADE | 有状态 | 用户提升实例规格后产生,用于记录资源规格提升的执行过程。 | 关注升配期间业务运行情况,并确认费用变化。 |
升配成功 | UPGRADE_SUCCEED | 无状态 | 实例已调整至目标高规格。 | 确认规格符合预期,观察资源使用趋势。 |
升配失败 | UPGRADE_FAILED | 无状态 | 实例未调整至目标高规格,可能与目标资源不足、实例状态异常或任务冲突有关。 | 查看失败原因;若因资源不足导致失败,建议调整目标规格或稍后重试。 |
公网带宽调整 | PUBLIC_NETWORK | 无状态 | 实例公网访问带宽上限发生变化,可能影响公网访问流量。 | 确认带宽配置是否符合业务预期;如访问异常,检查公网配置和客户端连通性。 |
路由策略调整 | ROUTE_POLICY | 无状态 | 实例访问路由策略发生变化,可能影响客户端接入路径。 | 如生产或消费异常,检查 VPC 路由、接入网络和客户端连通性。 |
ACL 策略变更 | ACL_POLICY | 无状态 | Topic、用户或 IP 访问控制规则发生变化,可能影响客户端生产消费权限。 | 如客户端访问失败,检查 ACL 配置、用户名、IP 白名单和客户端错误日志。 |
用户增删 | USER_POLICY | 无状态 | 实例 SASL 用户发生新增或删除,可能影响客户端认证配置。 | 同步更新生产端和消费端认证配置,避免认证失败。 |
开启弹性带宽 | OPEN_ELASTIC_BANDWIDTH | 无状态 | 实例启用弹性带宽能力,带宽可根据流量峰值进行弹性调整。 | 关注带宽使用情况和费用变化。 |
关闭弹性带宽 | CLOSE_ELASTIC_BANDWIDTH | 无状态 | 实例停止使用弹性带宽能力,公网带宽不再自动弹性调整。 | 参考近期峰值流量手动设置带宽上限,避免带宽不足影响业务。 |
小版本原地滚动升级 | SCROLL_VERSION_UPGRADE | 有状态 | 实例以滚动方式更新小版本,升级过程中会逐步完成节点更新。 | 关注升级期间 Broker 状态和客户端连接情况,建议在业务低峰期操作。 |
小版本原地滚动升级成功 | SCROLL_VERSION_UPGRADE_SUCCEED | 无状态 | 实例所有相关节点已完成目标小版本更新。 | 确认实例版本符合预期,观察生产消费是否正常。 |
小版本原地滚动升级失败 | SCROLL_VERSION_UPGRADE_FAILED | 无状态 | 实例未完成滚动升级,可能与 Broker 状态、版本兼容性或任务执行条件有关。 | 查看失败原因,确认实例和 Broker 状态后重试。 |
自动创建 Topic | TOPIC_AUTO_CREATE | 无状态 | 客户端请求不存在的 Topic,且实例开启自动创建能力时,系统自动创建对应 Topic。 | 确认自动创建的 Topic 是否符合业务预期;如非预期,检查客户端请求和自动创建配置。 |
设置自定义 SSL 证书 | INSTANCE_SSL_CERTIFICATE_SET | 有状态 | 用户为实例配置自定义 SSL 证书后产生,用于记录证书设置的执行过程。 | 确认客户端已配置正确的 CA 证书或信任链,避免 SSL 握手失败。 |
设置自定义 SSL 证书成功 | INSTANCE_SSL_CERTIFICATE_SET_SUCCESS | 无状态 | 实例已使用用户配置的自定义 SSL 证书。 | 验证客户端 SSL 连接是否正常,确认生产消费未受影响。 |
设置自定义 SSL 证书失败 | INSTANCE_SSL_CERTIFICATE_SET_FAILED | 无状态 | 自定义 SSL 证书未生效,可能与证书格式、证书链、有效期或实例状态有关。 | 查看失败原因,检查证书配置后重试。 |
更换 SSL 证书 | INSTANCE_SSL_CERTIFICATE_REPLACE | 有状态 | 用户更换实例绑定的 SSL 证书后产生,用于记录证书切换的执行过程。 | 提前确认客户端信任链已同步更新,建议在业务低峰期操作。 |
更换 SSL 证书成功 | INSTANCE_SSL_CERTIFICATE_REPLACE_SUCCESS | 无状态 | 实例已切换至新的 SSL 证书。 | 验证客户端连接是否正常,确认新证书已生效。 |
更换 SSL 证书失败 | INSTANCE_SSL_CERTIFICATE_REPLACE_FAILED | 无状态 | 新 SSL 证书未生效,可能与证书配置、证书链、有效期或实例状态有关。 | 查看失败原因,检查新证书配置后重试。 |
解绑 SSL 证书 | INSTANCE_SSL_CERTIFICATE_UNBIND | 有状态 | 用户解除实例自定义 SSL 证书绑定后产生,用于记录证书解绑的执行过程。 | 确认客户端连接配置是否需要切换回默认证书信任配置。 |
解绑 SSL 证书成功 | INSTANCE_SSL_CERTIFICATE_UNBIND_SUCCESS | 无状态 | 实例已解除自定义 SSL 证书绑定。 | 验证客户端 SSL 连接是否正常,确认业务连接未受影响。 |
解绑 SSL 证书失败 | INSTANCE_SSL_CERTIFICATE_UNBIND_FAILED | 无状态 | 自定义 SSL 证书未完成解绑,可能与实例状态或证书绑定状态有关。 | 查看失败原因,确认实例状态和证书绑定状态后重试。 |
大版本原地升级 | MAJOR_VERSION_IN_PLACE_UPGRADE | 有状态 | 实例发起大版本原地升级,用于完成 Kafka 大版本能力或兼容性升级。 | 提前评估版本兼容性,关注升级期间客户端连接、生产消费和 Broker 状态。 |
大版本原地升级成功 | MAJOR_VERSION_IN_PLACE_UPGRADE_SUCCEED | 无状态 | 实例已运行在目标大版本。 | 确认版本符合预期,观察升级后业务运行情况。 |
大版本原地升级失败 | MAJOR_VERSION_IN_PLACE_UPGRADE_FAILED | 无状态 | 实例未升级至目标大版本,可能与版本兼容性、实例状态或升级条件有关。 | 查看失败原因,确认版本兼容性、实例状态和升级条件后重试。 |
诊断事件
事件中文名称 | 事件英文名称 | 事件状态 | 事件描述 | 处理方法和建议 |
定时实例诊断 | INSTANCE_SCHEDULED_ANALYSIS | 无状态 | 系统定期执行实例健康检查,覆盖网络、磁盘、Broker 状态等。 | 当检测异常时查看诊断报告,针对性处理。 |
即时实例诊断 | INSTANCE_IMMEDIATE_ANALYSIS | 无状态 | 用户手动触发的实时健康检测。 | 当检测异常时查看诊断报告,针对性处理。 |
Broker 变更事件
事件中文名称 | 事件英文名称 | 事件描述 | 处理方法和建议 |
消费分组成员心跳超时 | Consumer group member heartbeat timed out | 消费组成员在指定时间内未完成心跳上报,可能导致成员被移出消费组并触发 Rebalance。 | 建议确认消费者是否正常。 偶尔的心跳超时可能是消费分组成员波动导致,如心跳超时频繁出现,建议根据业务逻辑排查消息处理是否有阻塞。如有阻塞,调整下游阻塞点。 或尝试调整实例配置。 |
消费分组成员更新 | Consumer group member update metadata | 消费组成员信息发生变化,通常由消费者上线、下线、发布重启或新消费者加入引起。 | 建议查看消费组成员变更情况,如是否有发布或新加入。 |
消费分组 Rebalance | Consumer group rebalance | 消费组发生分区重新分配,可能由成员变化、心跳超时、消费者频繁创建或销毁等原因触发。 | 偶尔的消费分组 Rebalance 可能为正常波动导致。如消费分组 Rebalance 持续出现或出现较为频繁,建议进一步排查,防止对消费产生影响。 排查消费组是否有心跳超时并处理。 排查是否有频繁创建/销毁消费者。 排查其余消费组事件。 |
集群节点上线 | Cluster node online | Broker 节点恢复服务或加入集群,可能由实例变配、计划内维护、底层资源恢复等场景触发。 | 建议先在事件中心查看是否有变配事件发生。当有变配发生时,集群节点出现上下线为正常情况,此时无需特殊关注。 偶尔的节点上下线可能为底层机器波动导致,无需特殊关注。 如有集群节点上线事件发生,且有生产或消费持续受到影响,且长时间未恢复,请联系我们。 |
集群节点下线 | Cluster node offline | Broker 节点暂时退出服务,可能由实例变配、计划内维护、底层资源波动或节点异常引起。 | 建议先在事件中心查看是否有变配事件发生。当有变配发生时,集群节点出现上下线为正常情况,此时无需特殊关注。 偶尔的节点上下线可能为底层机器波动导致,无需特殊关注。 如有集群节点下线事件发生,且有生产或消费持续受到影响,且长时间未恢复,请联系我们。 |
Leader 切换 | Leader Election | 分区 Leader 副本发生转移,可能由变配、副本均衡、容灾切换、计划内维护或 Broker 状态变化触发。 | 偶尔的 leader 切换为正常情况,无需特殊关注。 如 leader 切换事件持续发生,有生产消费持续受到影响,且长时间未恢复,可尝试重启客户端。 |



