Java 的标准正则表达式包
java.util.regex 以及其他被广泛使用的正则表达式包如 PCRE、Perl RE 和 Python(re),都使用回溯实现策略,即当一个 pattern 出现两个替代方案a|b 的时候,引擎将首先尝试匹配子模式a,如果匹配失败,它将重置输入流并尝试匹配子模式 b。如果这种匹配模式是深度嵌套的,则此策略需要对输入数据进行指数级的嵌套解析。如果输入的字符串很长,则匹配时间可以趋向无穷大。
相比之下,RE2J 算法通过使用非确定有限自动机在输入数据的单次解析中同时检查所有匹配项,从而实现在线性时间完成正则匹配。
数据处理中的正则提取适用于对长数组类型的消息进行特定字段的提取,下面介绍 CKafka 提供的正则表达式自动生成能力的使用方法和几种常见的提取模式。
正则表达式自动生成
正则表达式自动生成适用于日志文本中每行内容为一条原始日志,且每条日志可按正则表达式提取为多个 key-value 键值的日志解析模式。
配置单行-完全正则模式时,您需要先输入日志样例,再自定义正则表达式。配置完成后,系统将根据正则表达式中的捕获组提取对应的 key-value。
如下内容将为您详细介绍如何采集单行-完全正则模式日志。
前提条件
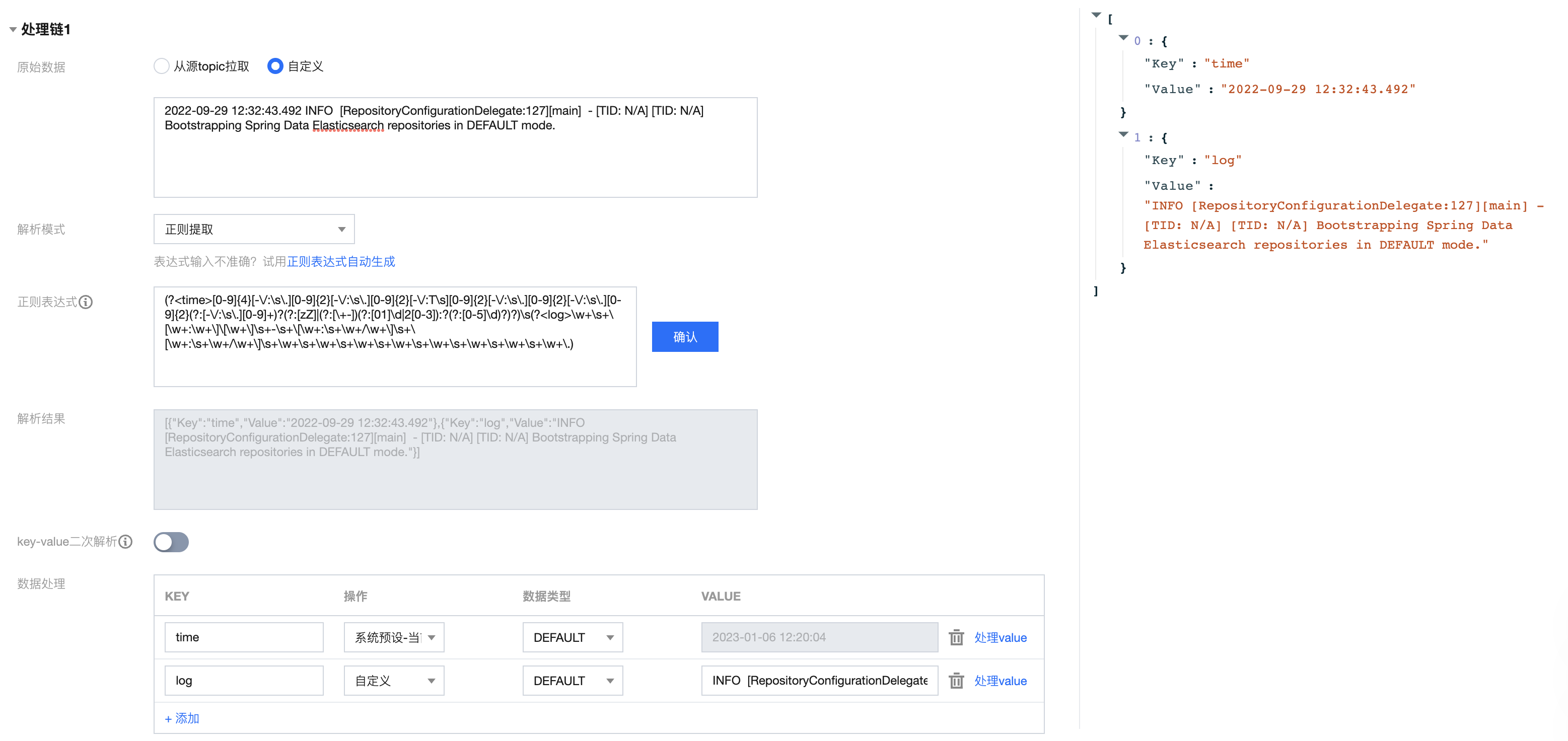
假设您的一条日志原始数据为:
2022-09-29 12:32:43.492 INFO [RepositoryConfigurationDelegate:127][main] - [TID: N/A] [TID: N/A] Bootstrapping Spring Data Elasticsearch repositories in DEFAULT mode.
配置的自定义正则表达式为:
(?<time>[0-9]{4}[-\\/:\\s\\.][0-9]{2}[-\\/:\\s\\.][0-9]{2}[-\\/:T\\s][0-9]{2}[-\\/:\\s\\.][0-9]{2}[-\\/:\\s\\.][0-9]{2}(?:[-\\/:\\s\\.][0-9]+)?(?:[zZ]|(?:[\\+-])(?:[01]\\d|2[0-3]):?(?:[0-5]\\d)?)?)\\s(?<log>\\w+\\s+\\[\\w+:\\w+\\]\\[\\w+\\]\\s+-\\s+\\[\\w+:\\s+\\w+/\\w+\\]\\s+\\[\\w+:\\s+\\w+/\\w+\\]\\s+\\w+\\s+\\w+\\s+\\w+\\s+\\w+\\s+\\w+\\s+\\w+\\s+\\w+\\s+\\w+\\.)
系统根据()捕获组提取对应的 key-value 后,您可以自定义每组的 key 名称如下所示:
{"time":"2022-09-29 12:32:43.492","log":"INFO [RepositoryConfigurationDelegate:127][main] - [TID: N/A] [TID: N/A] Bootstrapping Spring Data Elasticsearch repositories in DEFAULT mode."}
操作步骤
1. 在数据处理规则配置页面,在原始数据中输入日志样例,解析模式设置为正则提取,单击解析模式下的正则表达式自动生成。
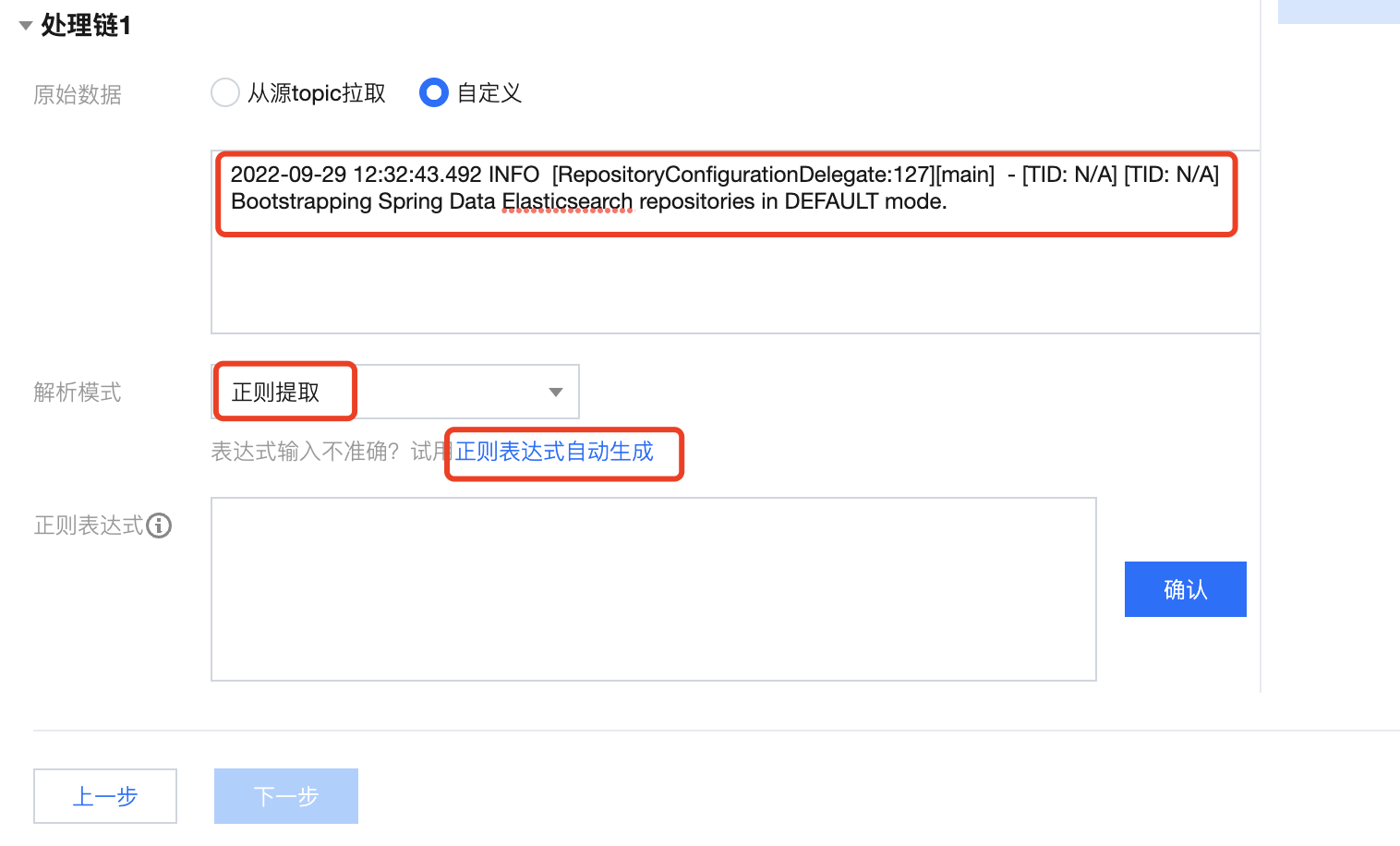
2. 在弹出的“正则表达式自动生成”模态视图中,根据实际的检索分析需求,选中需要提取 key-value 的日志内容,并在弹出的文本框中,输入键(key)名,单击确认提取。

3. 系统将自动对该部分内容提取一个正则表达式,自动提取结果会出现在 key-value 表格中。
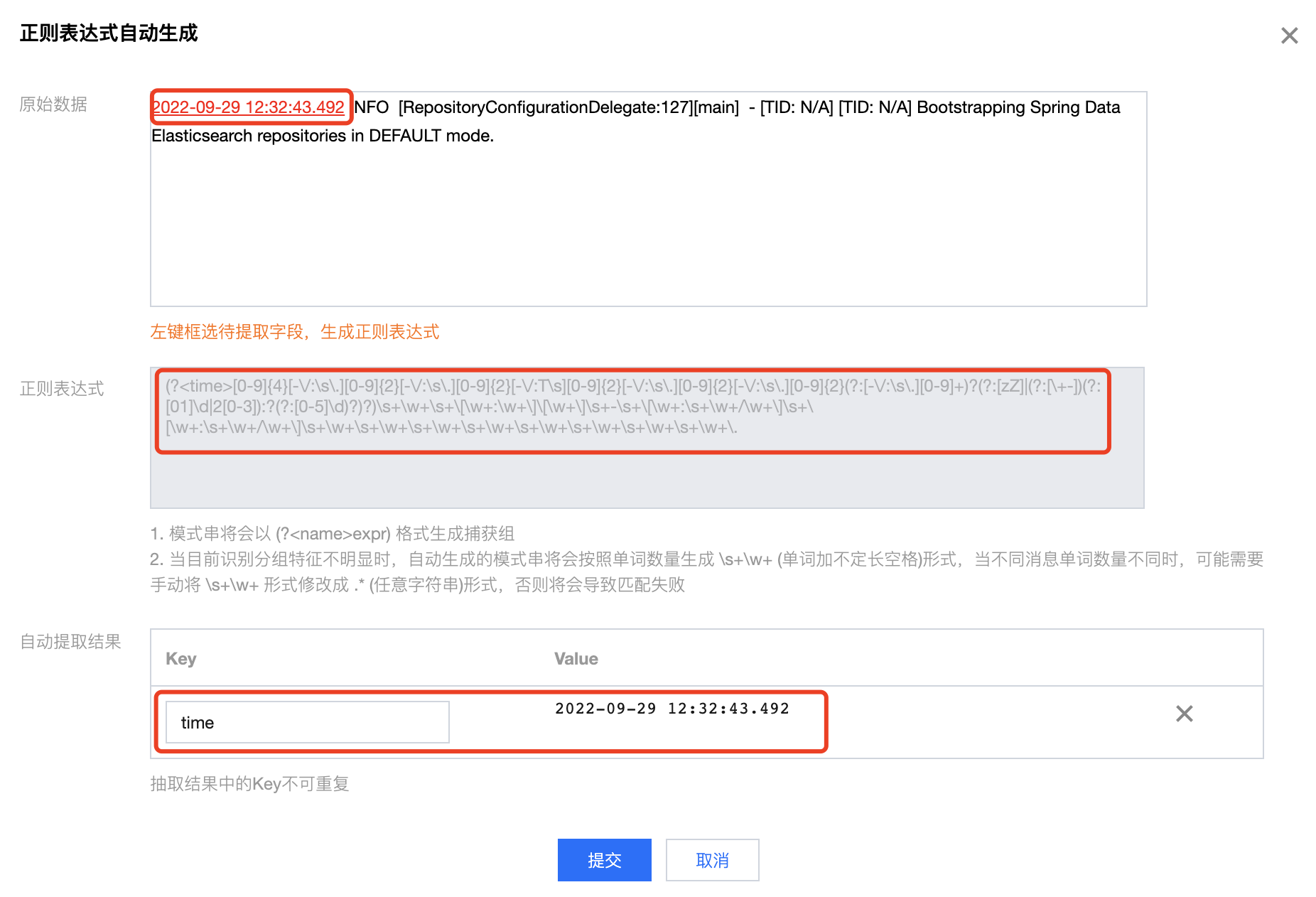
4. 重复步骤2,直到提取完所有的 key-value 对。

5. 单击提交,系统将根据提取好的 key-value 对自动生成完整的正则表达式。
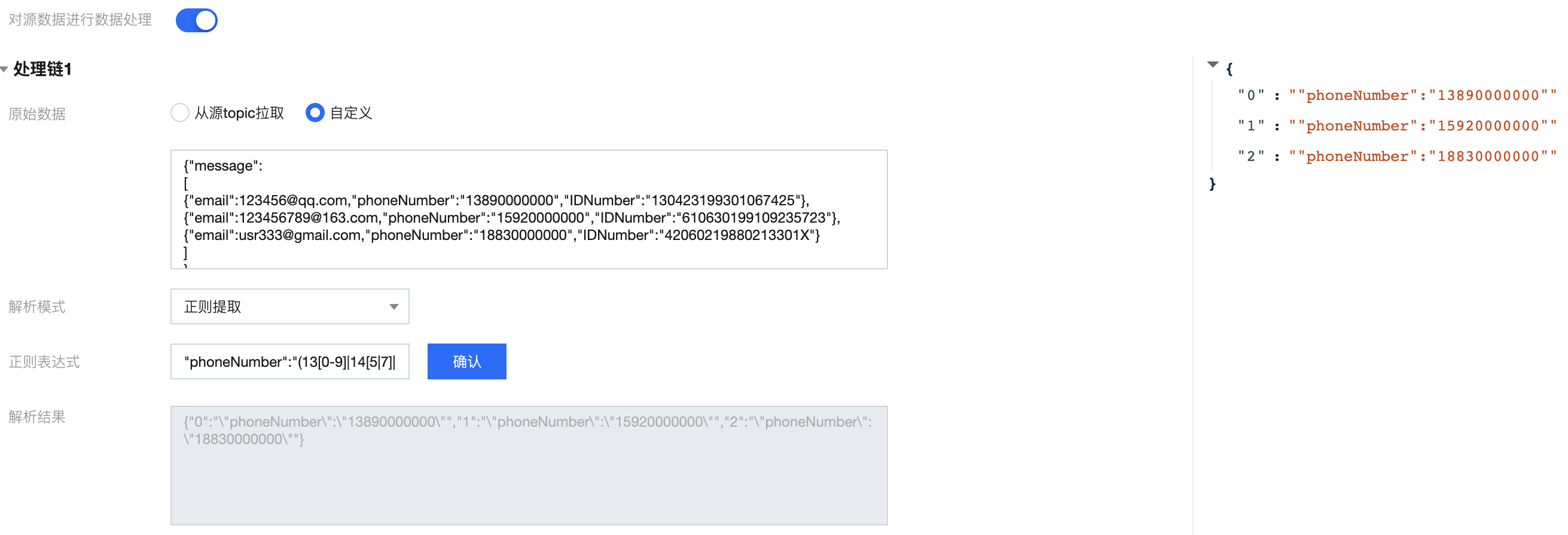
案例1:对手机号字段进行提取
输入 message:
{"message":[{"email":123456@qq.com,"phoneNumber":"13890000000","IDNumber":"130423199301067425"},{"email":123456789@163.com,"phoneNumber":"15920000000","IDNumber":"610630199109235723"},{"email":usr333@gmail.com,"phoneNumber":"18830000000","IDNumber":"42060219880213301X"}]}
目标 message:
{"0": "\\"phoneNumber\\":\\"13890000000\\"","1": "\\"phoneNumber\\":\\"15920000000\\"","2": "\\"phoneNumber\\":\\"18830000000\\""}
使用的正则表达式为:
"phoneNumber":"(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}"
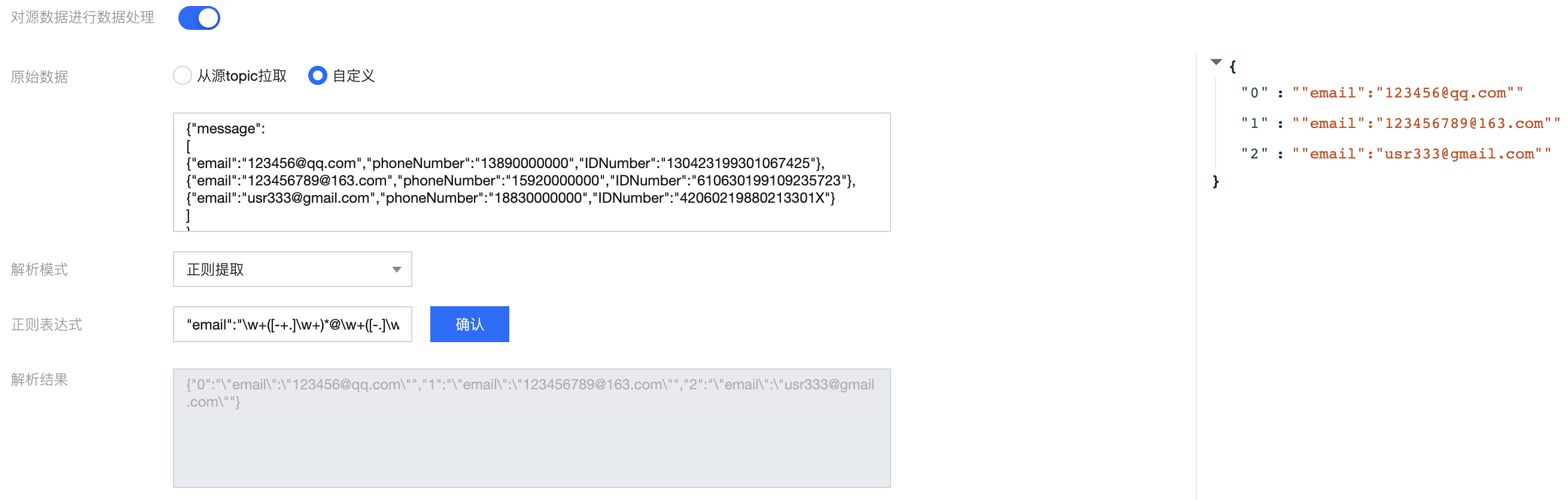
案例2:对 Email 字段进行提取
输入 message:
{"message":[{"email":123456@qq.com,"phoneNumber":"13890000000","IDNumber":"130423199301067425"},{"email":123456789@163.com,"phoneNumber":"15920000000","IDNumber":"610630199109235723"},{"email":usr333@gmail.com,"phoneNumber":"18830000000","IDNumber":"42060219880213301X"}]}
目标 message:
{"0": "\\"email\\":\\"123456@qq.com\\"","1": "\\"email\\":\\"123456789@163.com\\"","2": "\\"email\\":\\"usr333@gmail.com\\""}
使用的正则表达式为:
"email":"\\w+([-+.]\\w+)*@\\w+([-.]\\w+)*\\.\\w+([-.]\\w+)*"
案例3:对身份证字段进行提取
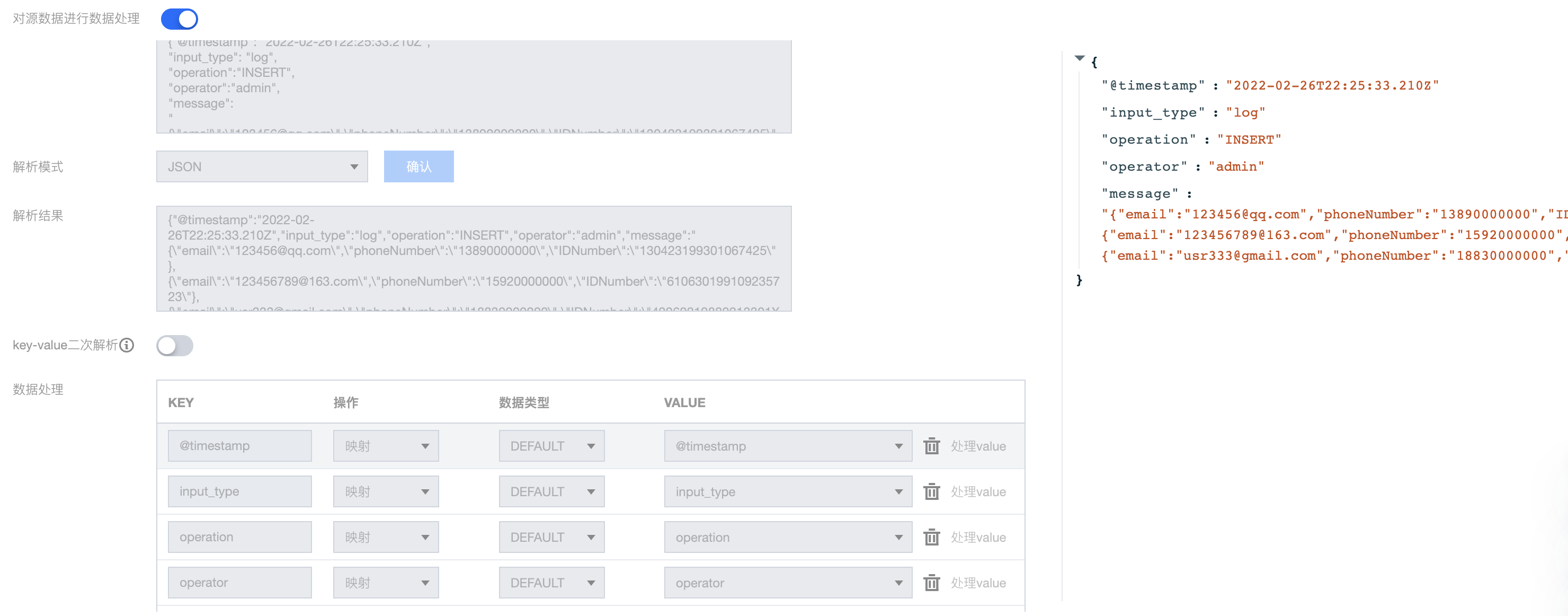
输入 message:
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","operation": "INSERT","operator": "admin","message": "{\\"email\\":\\"123456@qq.com\\",\\"phoneNumber\\":\\"13890000000\\",\\"IDNumber\\":\\"130423199301067425\\"},{\\"email\\":\\"123456789@163.com\\",\\"phoneNumber\\":\\"15920000000\\",\\"IDNumber\\":\\"610630199109235723\\"},{\\"email\\":\\"usr333@gmail.com\\",\\"phoneNumber\\":\\"18830000000\\",\\"IDNumber\\":\\"42060219880213301X\\"}"}
目标 message,这里希望保留外部字段,并将message字段中的N个 IDNumber字段单独提取出来:
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","operation": "INSERT","operator": "admin","message.0": "130423199301067425","message.1": "610630199109235723","message.2": "42060219880213301X"}
使用的正则表达式为:
[1-9]\\d{5}(18|19|20)\\d{2}((0[1-9])|(1[0-2]))(([0-2][1-9])|10|20|30|31)\\d{3}[0-9Xx]
这里通过多个处理链进行处理,处理链1的处理结果为:
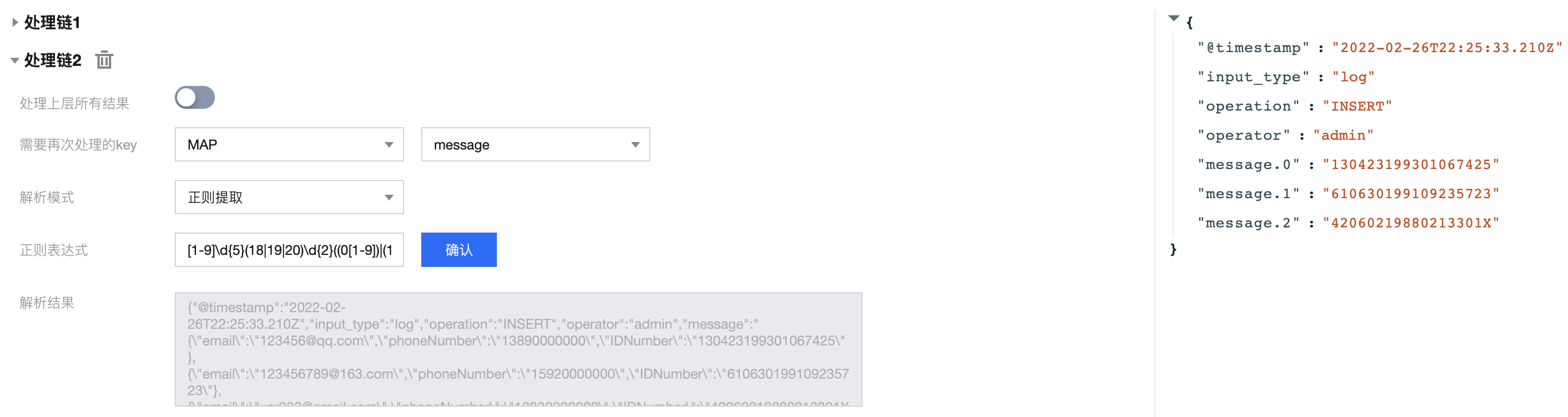
此时需要对 message 字段进行二次处理,处理链2的处理结果如下:
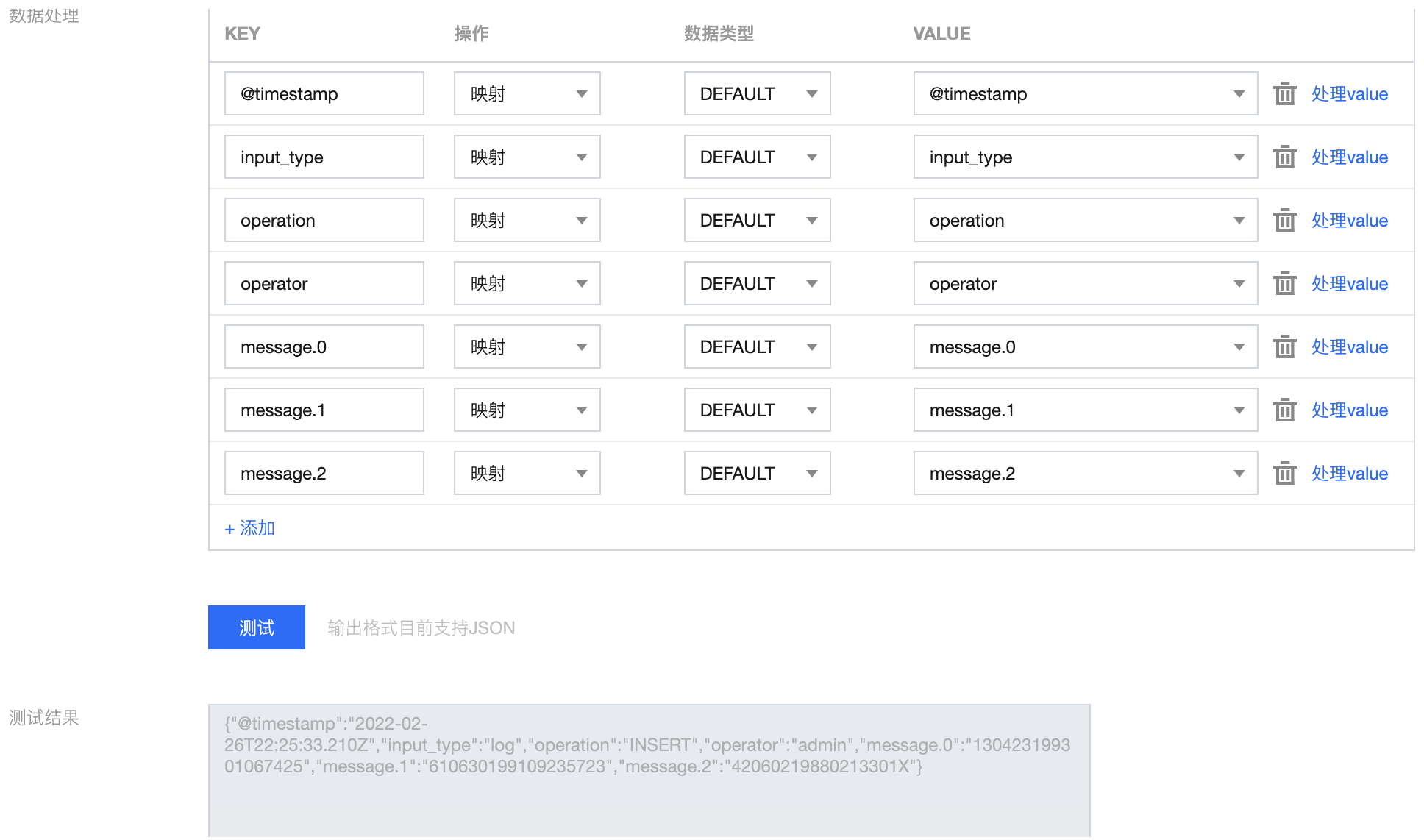
处理结果:
{"@timestamp": "2022-02-26T22:25:33.210Z","input_type": "log","operation": "INSERT","operator": "admin","message.0": "130423199301067425","message.1": "610630199109235723","message.2": "42060219880213301X"}
这里将需要的 IDNumber 字段提取出来后,删除了原来的 message 字段,保留了外部需要的 operation 等字段,以及 message 中的 N 个需要的数据信息。



