概述
LogListener 可观测指标是 CLS 为 LogListener 采集器提供的运行时观测能力。LogListener 在采集、解析、发送日志的过程中,会按固定周期上报一系列内置指标,覆盖采集链路完整性、发送质量、解析正确性、异常计数、采集器自身状态、可靠性容错以及系统资源使用等多个维度。这些指标会以指标主题(Metric Topic)的形式存储到 CLS,您可以通过 PromQL 查询、配置仪表盘和告警策略,实时观测每一台机器上 LogListener 的运行状态。
应用场景
采集链路监控:您可以通过仪表盘或 PromQL 查询实时观测每台机器的日志采集情况,重点关注文件滞后量、队列堆积、发送成功率、重发次数等指标。
数据完整性核查:基于输入量、处理成功量、丢弃量、过滤量、截断量等指标,可实现端到端数据流转的完整性校验。
解析与时序问题定位:针对不同解析模式(JSON、分隔符、正则、组合解析),分别监控各类解析失败计数,快速定位日志格式与解析配置的不匹配问题。
采集器资源观测:LogListener 作为常驻采集进程,需要持续观测其自身资源占用。您可重点关注 LogListener CPU 使用率、LogListener 内存使用量、业务线程数等指标。
异常告警与故障定位:您可基于文件读取错误数、文件权限错误数、文件不存在错误数、文件描述符耗尽错误数、网络错误数等异常计数指标,结合进程异常重启次数等进程状态指标,配置告警策略实现实时故障感知。
前提条件
已安装并部署 LogListener,且 LogListener 版本是 v3.6.1及以上版本 。可观测指标能力依赖 LogListener 采集新架构,如您的 LogListener 版本低于 v3.6.1,请先升级,详见 安装升级指南。CLS 中提供如下默认配置:
默认配置项 | 配置内容 |
指标主题 | 指标主题:cls_collector_services_metric |
存储时间 | 默认保存7天。 |
仪表盘 | 默认生成 LogListener 可观测仪表盘。 |
LogListener 可观测仪表盘
1. 登录 日志服务控制台。
2. 您可以在左侧导航栏中,选择仪表盘 > 仪表盘列表,在预置仪表盘标签下找到并进入 LogListener 可观测仪表盘。
3. 在顶部筛选栏中:指标数据源选择 cls-collector-services-metric,实例 IP 选择目标机器 IP。
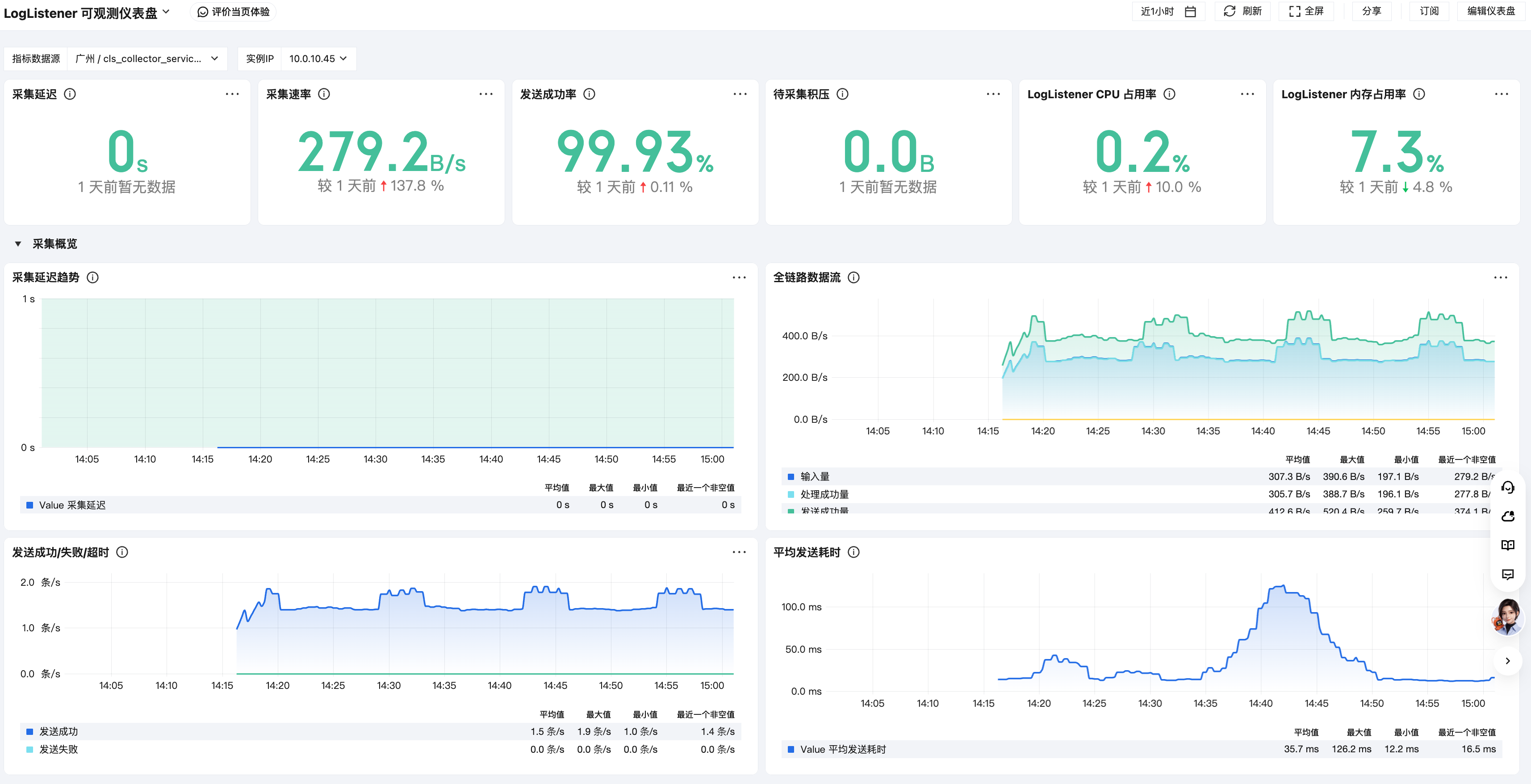
4. 查看 LogListener 可观测的相关信息,包括采集延迟、采集速率、发送成功率、待采集积压、CPU / 内存占用率等指标信息。
采集延迟:CLS 内部处理延迟(CLS 感知到日志至上传完成的耗时),反映从感知日志到上传完成的端到端延迟。
采集速率:单位时间内 LogListener 输入插件读到的原始日志字节数。
发送成功率:日志发送到 CLS 的请求中成功的占比。
待采集积压:文件当前大小减去 LogListener 已读偏移量的差值。
LogListener CPU 占用率:LogListener 进程自身的 CPU 使用率。
LogListener 内存占用率:LogListener 进程驻留内存使用量。
指标字段描述
LogListener 可观测指标按用途划分为六大类:
核心业务指标:例如处理延迟、文件滞后量等。
异常监控指标:例如文件读取错误次数、请求错误次数等。
LogListener 自监控指标:例如 LogListener 进程 CPU 使用率、内存使用量等。
可靠性容错指标:例如点位更新写入次数等。
系统监控指标:例如系统整体 CPU 使用率、内存大小等。
独立的告警监控指标:例如 LogListener 告警数量统计。
核心业务指标
核心业务指标反映 LogListener 在日志采集、解析、发送链路上的处理量、性能与质量,指标如下:
字段 | 描述 |
cls_processing_delay_ms | CLS 内部处理延迟(CLS 感知到日志至上传完成的耗时),反映从感知日志到上传完成的端到端延迟。 |
file_lag_size | 文件滞后量(待采集积压);文件当前大小减去 LogListener 已读偏移量的差值,按采集器所有文件累加。该指标反映采集进度,数值持续增长说明采集速度跟不上日志生成速度。 |
pipeline_queue_size | 当前流水线队列中待处理的数据量。 |
pipeline_queue_count | 当前流水线队列中待处理的队列长度。 |
send_queue_size | 当前发送队列中待处理/待发送的数据量。 |
send_queue_count | 当前发送队列中待处理/待发送的队列长度。 |
event_queue_size | 事件队列大小。 |
polling_event_queue_size | Polling 事件队列大小。 |
events_produced_total | 累计产生事件数。 |
events_consumed_total | 累计消费事件数。 |
events_lag | 当前积压事件数。 |
events_consumed_failed_total | 消费失败事件数。 |
send_log_time | 单次发送请求耗时,单位 ms。指标类型:Histogram,分桶边界为 10、25、50、100、250、500、1000、2500、5000、10000ms。可通过 histogram_quantile 函数计算 P50/P90/P99延迟。 |
send_log_size | 累计发送日志大小。 |
process_count | 处理日志条数。 |
process_bytes | 处理日志大小。 |
input_size | 输入插件接收的原始日志总大小。该指标是数据完整性核查的源头基准。 |
processor_success_count | 成功处理的日志数量。 |
processor_success_size | 成功处理的日志大小。 |
dropped_log_count | 丢弃日志数量。日志在采集或处理过程中被主动丢弃的数量。 |
dropped_log_size | 丢弃日志大小。 |
truncate_log_size | 截断日志大小;超过单条日志长度限制时被截断的累计大小。 |
multi_line_parse_failures_count | 多行解析失败日志条数。 |
multi_line_parse_failures_size | 多行解析失败日志大小。 |
total_filter_count | 过滤日志数量。日志被采集配置中过滤规则过滤掉的数量。 |
total_filter_size | 过滤日志大小。 |
send_success_count | 发送成功的日志数量。 |
send_success_size | 发送成功的日志大小。 |
send_failed_count | 发送失败的日志数量。 |
send_failed_size | 发送失败的日志大小。 |
send_timeout_log_count | 发送超时的日志数量;发送超时通常由网络异常或服务端响应慢导致。 |
send_timeout_log_size | 发送超时的日志大小。 |
total_resend | 累计重发次数。LogListener 在发送失败后会自动重试,重发次数过高通常意味着网络抖动或服务端限流。 |
parse_success_count | 解析成功日志数量。该指标统计全局解析情况(涵盖所有解析模式)。 |
parse_success_size | 解析成功日志大小。 |
parse_fail_count | 解析失败日志数量;全局解析失败统计。 |
parse_fail_size | 解析失败日志大小。 |
json_parse_failures_count | JSON 解析失败的日志数量;仅 JSON 采集模式下统计。 |
json_parse_failures_size | JSON 解析失败的日志大小。 |
delimiter_mismatch_failures_count | 分隔符匹配失败的日志数量;仅分隔符采集模式下统计。 |
delimiter_mismatch_failures_size | 分隔符匹配失败的日志大小。 |
multi_parse_failures_count | 组合解析失败的日志数量;后续数据加工的解析成功情况也并入此项。 |
multi_parse_failures_size | 组合解析失败的日志大小。 |
regex_match_failures_count | 正则匹配失败的日志数量;仅完整正则采集模式下统计。 |
regex_match_failures_size | 正则匹配失败的日志大小。 |
time_format_success_count | 时间格式解析成功日志数量。 |
time_format_success_size | 时间格式解析成功日志大小。 |
time_format_failures_count | 时间格式解析失败日志数量。 |
time_format_failures_size | 时间格式解析失败日志大小。 |
异常监控指标
异常监控指标统计 LogListener 在运行过程中遇到的各类错误事件。
字段 | 描述 |
file_read_error | 文件读取错误次数,覆盖磁盘 I/O 错误、文件损坏等场景。 |
file_permission_error | 文件权限错误次数,文件权限不足导致读取失败。 |
file_not_found_error | 文件不存在错误次数,文件不存在或无法打开。 |
file_stat_error | 文件状态获取失败错误次数,调用系统 stat() 函数获取文件元数据(大小、修改时间、inode 等)失败时计数。 |
file_open_limit_error | 文件描述符耗尽错误次数,系统文件描述符达到进程或系统级别上限时触发。 |
params_invalid_error | 配置参数错误次数,例如配置了内网访问但实际机器地域与目标 CLS 服务地域不一致等。 |
send_network_error | 网络错误次数,覆盖网络超时、连接失败、DNS 解析失败等。 |
request_error | 请求错误次数,其他所有类型的请求错误,如 HTTP 429、404、401、Topic 不存在等。 |
LogListener 自监控指标
LogListener 自监控指标用于观测 LogListener 进程自身的资源消耗、生命周期与工作状态。
字段 | 描述 |
loglistener_cpu_usage | LogListener 进程 CPU 使用率。 |
loglistener_mem_used | LogListener 进程内存使用量。 |
total_open_files | LogListener 当前打开的文件数。当数值接近 ulimit -n 上限时会出现新文件无法打开的风险。 |
total_monitor_dirs | LogListener 当前持续监控的目录总数量。统计采集插件在当前时刻正在监听 inotify 事件的目录数。 |
max_file_limit | LogListener 配置的最大可打开文件数限制。 |
max_dir_limit | LogListener 配置的最大可监控目录数限制。 |
process_stop_code | 进程退出码;记录 LogListener 进程正常或异常退出时返回的状态码,不同数值对应不同退出原因。 |
process_restart_times | 进程异常重启次数;统计 LogListener 进程从首次启动到当前累计发生的异常重启次数。 |
thread_count_business | 启动的业务线程数;LogListener 进程在当前时刻成功启动的采集任务相关的线程数。 |
thread_count_system_total | 启动的系统总线程数;LogListener 进程在当前时刻的系统级总线程数(含运行时框架线程、采集业务线程等所有线程),该指标额外带有 pid 标签。 |
task_process_time | 任务处理耗时;记录 LogListener 内线程处理日志采集任务所累计消耗的时长。 |
task_process_count | 任务计数;统计 LogListener 从启动到当前累计处理完成的日志采集任务总数。 |
total_log_configs | LogListener 当前生效的采集配置数量。 |
可靠性容错指标
可靠性容错指标用于观测 LogListener 在配置热加载、Checkpoint 持久化等场景下的可靠性表现。
字段 | 描述 |
checkpoint_update_count | 点位(Checkpoint)更新写入次数,LogListener 周期性持久化采集点位以保障重启不丢数据。 |
config_reload_success_count | 配置热加载成功次数。 |
config_reload_failure_count | 配置热加载失败次数。 |
系统监控指标
系统监控指标反映 LogListener 所在主机的整机资源使用情况,用于辅助判断采集异常是否由系统级资源紧张导致。
字段 | 描述 |
system_cpu_usage | 系统整体 CPU 使用率。 |
system_mem_usage | 系统内存总大小。 |
system_mem_available | 系统当前可用内存大小。 |
system_mem_used | 系统当前已用内存大小。 |
system_mem_util | 系统内存使用率。 |
system_disk_total_bytes | 系统磁盘总容量;当前默认采集根目录( /)所在磁盘。 |
system_disk_used_bytes | 系统磁盘已用容量。 |
system_disk_usage_percent | 系统磁盘使用率。 |
告警监控指标
告警监控指标统计 LogListener 内部产生的告警事件数量,配合服务日志可用于快速定位采集器异常。
字段 | 描述 |
loglistener_alarm_alarm_count | LogListener 告警数量统计。统计 LogListener 内部触发的所有告警事件总数。 |



