使用 Kafka 协议消费功能,您可以将一个日志主题,当作一个 Kafka Topic 来消费。可将采集到 CLS 的日志数据,消费到下游的大数据组件或者数据仓库。
例如 Flink、Flume、Logstash、Splunk 以及腾讯云 Oceanus。
前提条件
确保当前操作账号拥有开通 Kafka 协议消费的权限,权限问题请参见 CLS 访问策略模板。
内网消费和外网消费说明
内网消费:使用内网域名进行日志消费,流量费用为0.18元/GB。例如您的原始日志为100GB,消费时选择 Snappy 压缩,那么计量约为50GB,内网读流量费用为50GB * 0.18元,即9元。一般来说,如果您的消费端和日志主题在同一个 VPC 或者同一个地域,就可以使用内网消费。
外网消费:使用公网域名进行日志消费,流量费用为0.8元/GB。例如您的原始日志为100GB,消费时选择 Snappy 压缩,那么计量约为50GB,外网读流量费用为50GB * 0.8元,即40元。一般来说,如果您的消费端和日志主题不在同一个 VPC,也不在同一个地域,需要使用外网消费。如您有安全方面的需求, 可在配置项中关闭外网消费。

操作步骤
1. 登录日志服务控制台,选择左侧导航栏中的 日志主题。
2. 在日志主题页面,单击需要使用 Kafka 协议消费的日志主题 ID/名称,进入日志主题管理页面。
3. 在日志主题管理页面中,选择投递和消费 > Kafka 协议消费页签。
4. 单击右侧的编辑,将启用状态的开关按钮设置为打开状态后,编辑如下配置项,然后单击确定。
配置项 | 解释说明 | 规则 |
数据范围 | 历史+最新:新版本,可消费日志主题生命周期内的所有数据。 最新:旧版本,仅可消费最新数据。 注意: 两种不同数据范围的日志主题,不可使用同一个消费组进行消费。例如:日志主题 A 的消费数据范围配置为历史+最新,主题 B 为最新,日志主题 A 和 B 不可使用同一个消费组进行消费。 | 选择 |
消费数据格式 | JSON,以 JSON 的数据格式消费日志。 原始内容,以原文的格式消费日志。 | 选择 |
消费日志字段 | 请选择您需要消费的日志字段。 JSON 格式的转义/不转义的说明如下: 转义,将 JSON 第一层节点的值转为 String,如果您的第一层节点的值是 Struct,在下游入库或者计算时,需要提前将该 Struct 转为 String,可以选这个选项。 不转义,不对您的 JSON 结构和层级做修改,日志格式和采集侧保持一致。 注意: 当 JSON 的第一层节点中包含有数值时,消费后会自动转为 int、float。 日志:{"a":123, "b":"123", "c":"-123", "d":"123.45", "e":{"e1":123,"f1":"123"}} 消费:{"a":123,"b":123,"c":-123,"d":123.45,"e":{"e1":123,"f1":"123"}} 将__TAG__元信息平铺或者不平铺,说明如下。 示例:__TAG__元信息:{"__TAG__":{"fieldA":200, "fieldB":"text"}} 平铺:{"__TAG__.fieldA":200,"__TAG__.fieldB":"text"} 不平铺:{"__TAG__":{"fieldA":200, "fieldB":"text"}} | 选择 |
数据压缩格式 | 支持 SNAPPY\\ LZ4\\不压缩三种类型。 | 选择 |
消费日志预览 | 预览您消费的日志数据。 | - |
外网消费 | 关闭后,您不可以从外网消费日志,仅可内网消费。 | 开关 |
服务日志 | 消费的相关日志,用于您的消费监控图表,该数据由 CLS 免费提供。 | 开关 |
5. 控制台给出 Topic、Host+Port 的信息。您可以复制该信息,构造您的消费者(KafkaConsumer)。您也可以在基本信息 Tab 页面的右上角使用自动生成消费者小工具,生成一个可运行的消费客户端,如有其他业务逻辑请修改代码。
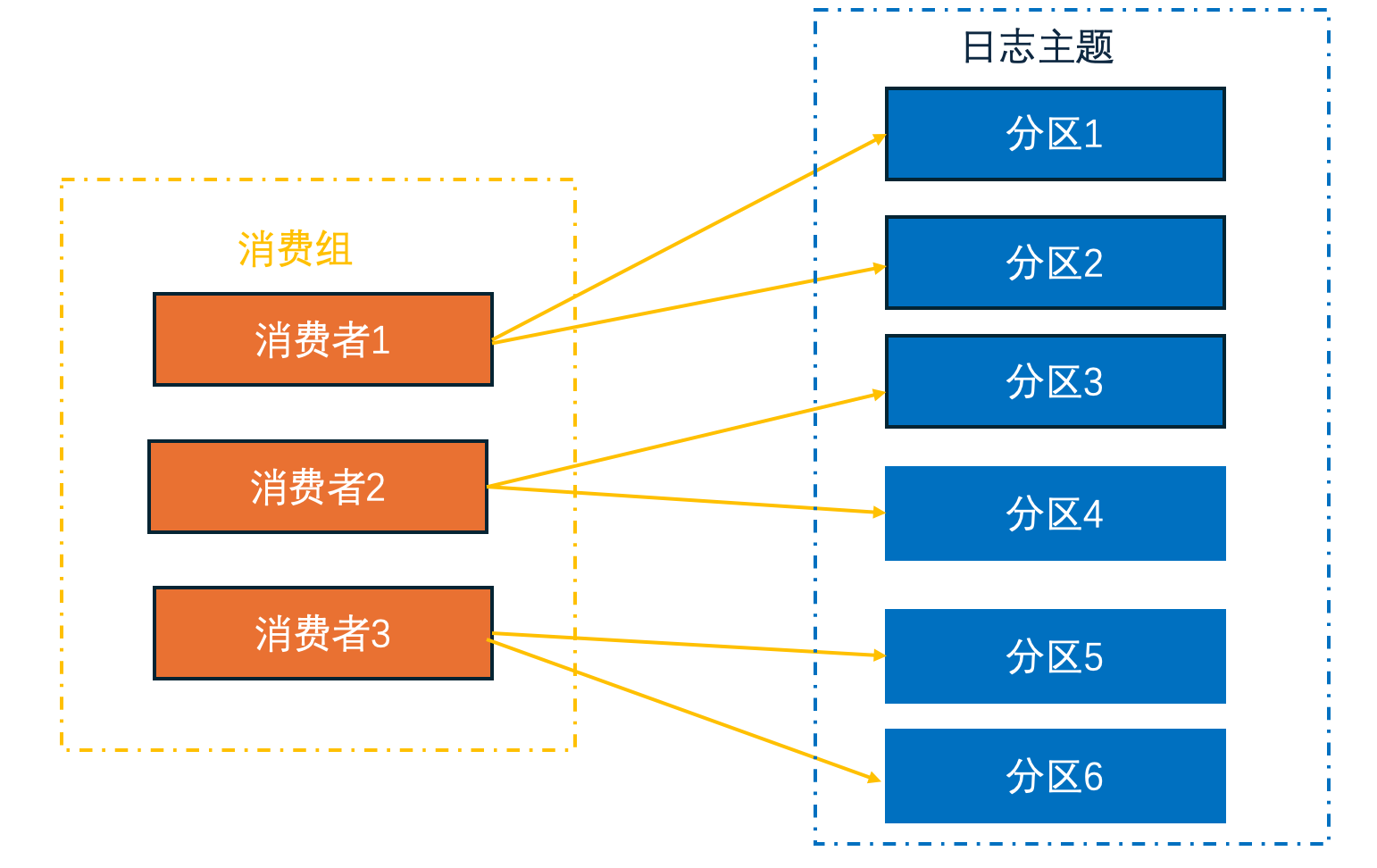
消费者参数说明
参数 | 说明 |
用户认证方式 | 目前仅支持 SASL_PLAINTEXT。 |
hosts | 内网消费:kafkaconsumer-${region}.cls.tencentyun.com:9095。 外网消费:kafkaconsumer-${region}.cls.tencentcs.com:9096,详细请参见 可用域名 - Kafka 消费日志。 |
topic | 消费主题 ID,请在 Kafka 协议消费的控制台复制。例如 XXXXXX-633a268c-XXXX-4a4c-XXXX-7a9a1a7baXXXX。 |
username | 配置为 ${LogSetID},即日志集 ID。 例如:0f8e4b82-8adb-47b1-XXXX-XXXXXXXXXX ,请在 Kafka 协议消费的控制台复制。 |
password |
消费者 Demo
消费组管理
重置消费位点:如果您选择消费的数据范围为历史+最新,在提交消费组以后,您可在消费者 Tab 页面找到该消费组,然后对消费组进行重启消费位点的操作。
说明:
消费组的状态为 Empty 时,才可重置消费位点,停止消费客户端的程序后,消费组的状态将被服务端识别为 Empty。
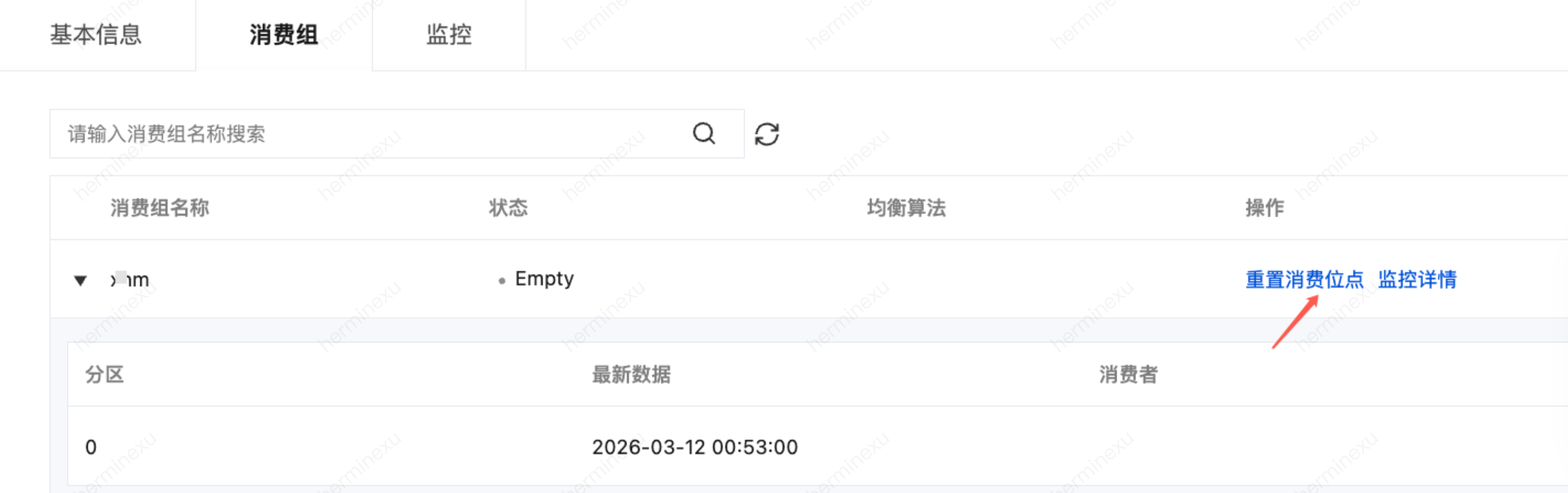
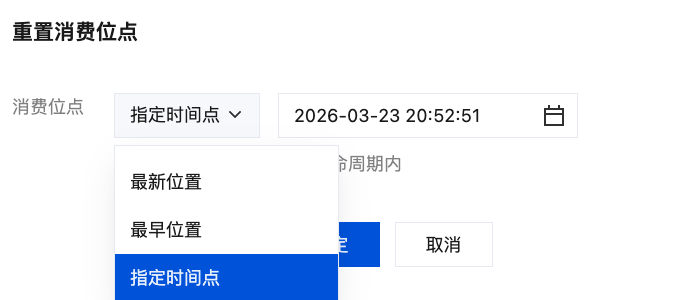
消费位点有如下三种:
最新位置:从最新数据开始消费。
最早位置:从最早数据开始消费。
指定时间点。注意该时间点需在日志主题生命周期。
监控详情:单击监控详情,可跳转到该消费组的监控信息。



