接口描述
本接口服务采用 WebSocket 协议,对实时音频流进行识别,同步返回识别结果,达到"边说边出文字"的效果。
接口要求
集成实时语音识别 API 时,需按照以下要求。
内容 | 说明 |
语言种类 | 支持中文普通话、英文。 |
支持行业 | 通用。 |
音频属性 | 采样率:16000Hz 或 8000Hz; 采样精度:16bits; 声道:单声道(mono)。 |
音频格式 | pcm。 |
请求协议 | WSS 协议。 |
请求地址 | wss://域名/asr/v2/\\<appid\\>?\\{请求参数\\}。 |
响应格式 | JSON。 |
数据发送 | 每 40ms 发送 40ms 时长(即 1:1 实时率)的数据包,对应 PCM 大小为:8k 采样率 640 字节,16k 采样率 1280 字节。音频发送音频数据包之间发送间隔超过 6 秒,可能导致引擎出错,后台将返回错误并主动断开连接。 |
并发限制 | 默认单账号限制并发数为 200 路。 |
说明:
同一 SDKAppID 下,直接接入 ASR、AI 对话、AI 转录/翻译等所有实时语音识别场景共享该并发池,即各类型的并发路数合计不超过账号上限。一句话识别与录音文件识别独立计算,不占用实时识别并发额度。如您有更多并发需求,请 联系我们。
业务流程图
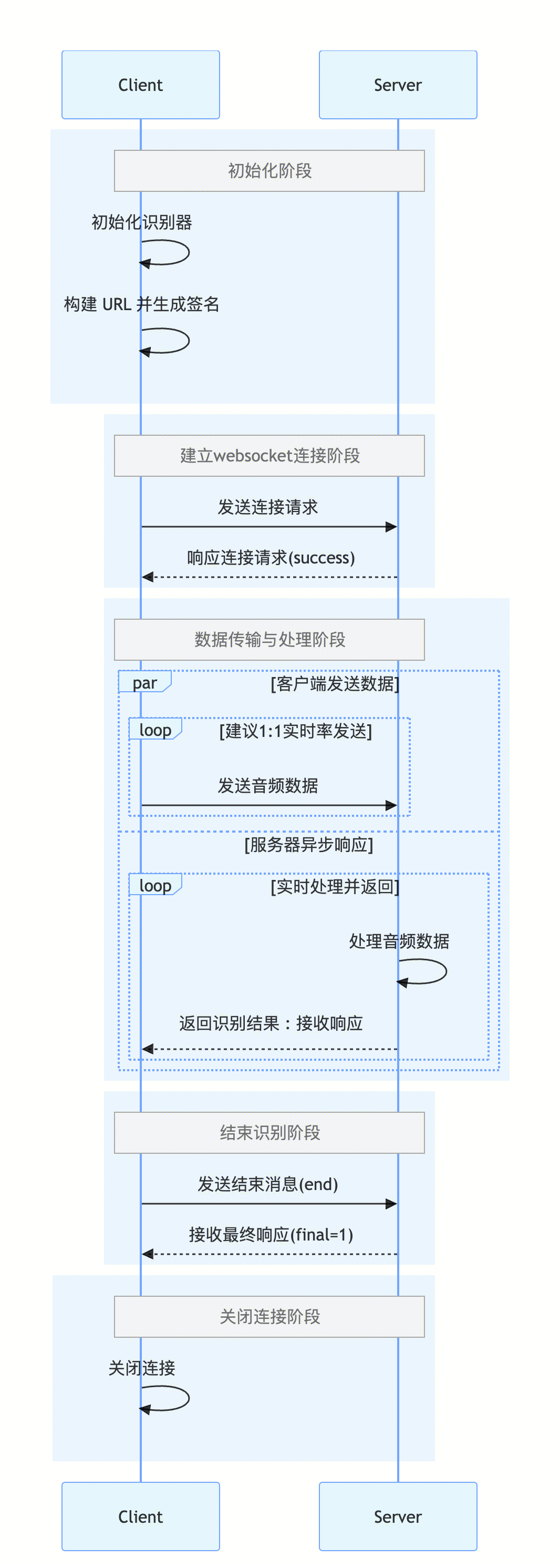
接口调用流程
接口调用流程分为两个阶段:握手阶段和识别阶段。两阶段后台均返回 text message,内容为 json 序列化字符串,以下是格式说明:
字段名 | 类型 | 描述 |
code | Integer | 状态码,0 代表正常,非 0 值表示发生错误。 |
message | String | 错误说明。 |
voice_id | String | 音频流全局唯一标识,一个 WebSocket 连接对应一个,用户自己生成(推荐使用 UUID),最长 128 位。 注意: 每次建立 WebSocket 连接都必须重新生成 voice_id,任何情况下中断了识别或者 WebSocket 连接(如连接失败、正常结束、识别返回错误码等),voice_id 作废,重新发起识别必须使用新的 voice_id。 |
message_id | String | 本 message 唯一 ID。 |
result | Result | 最新语音识别结果。 |
final | Integer | 该字段返回 1 时表示音频流全部识别结束。 |
其中识别结果 Result 结构体格式为:
字段名 | 类型 | 描述 |
slice_type | Integer | 识别结果类型: 0:一段话开始识别; 1:一段话识别中,voice_text_str 为非稳态结果(该段识别结果还可能变化); 2:一段话识别结束,voice_text_str 为稳态结果(该段识别结果不再变化)根据发送的音频情况,识别过程中可能返回的 slice_type 序列有: 0-1-2:一段话开始识别、识别中(可能有多次 1 返回)、识别结束; 0-2:一段话开始识别、识别结束; 2:直接返回一段话完整的识别结果。 |
index | Integer | 当前一段话结果在整个音频流中的序号,从 0 开始逐句递增。 |
start_time | Integer | 当前一段话结果在整个音频流中的起始时间。 |
end_time | Integer | 当前一段话结果在整个音频流中的结束时间。 |
voice_text_str | String | 当前一段话文本结果,编码为 UTF8。 |
word_size | Integer | 当前一段话的词结果个数(word_list 数组的长度与 word_size 的值相等)。 |
word_list | Word Array | 当前一段话的词列表,Word 结构体格式为: word:String 类型,该词的内容; start_time:Integer 类型,该词在整个音频流中的起始时间; end_time:Integer 类型,该词在整个音频流中的结束时间; stable_flag:Integer 类型,该词的稳态结果,0 表示该词在后续识别中可能发生变化,1 表示该词在后续识别过程中不会变化。 |
握手阶段
请求格式
握手阶段,客户端发起 WebSocket 连接请求,请求 URL 格式为:
正式环境:
wss://asr.cloud-rtc.com/asr/v2/<appid>?{请求参数}在 WebSocket header 中填写以下字段:
key1=value1&key2=value2...
参数说明:
参数名 | 必填 | 类型 | 描述 |
secretid | 是 | String | |
timestamp | 是 | Integer | 当前 UNIX 时间戳,单位为秒。如果与当前时间相差过大,会引起签名过期错误。示例值:1745932688。 |
expired | 是 | Integer | 签名的有效期截止时间 UNIX 时间戳,单位为秒。expired 必须大于 timestamp 且 expired - timestamp 小于 90 天。 |
nonce | 是 | Integer | 随机正整数。用户需自行生成,最长 10 位。示例值:8743357。 |
engine_model_type | 是 | String | 引擎模型类型,目前支持: bigmodel:大模型版; 8k_zh:中文通用,常用于电话场景; 16k_zh_en:中英文通用。 |
voice_id | 是 | String | 音频流全局唯一标识,一个 WebSocket 连接对应一个,用户自己生成(推荐使用 UUID),最长 128 位。 注意: 每次建立 WebSocket 连接都必须重新生成 voice_id,任何情况下中断了识别或者 WebSocket 连接(如连接失败、正常结束、识别返回错误码等),voice_id 作废,重新发起识别必须使用新的 voice_id。 |
voice_format | 否 | Integer | 语音编码方式,目前支持:1:PCM。 |
needvad | 否 | Integer | 0:关闭 vad; 1:开启 vad。 默认为 0。为保证识别效果,如果语音分片长度超过 60 秒,会强制在 60s 断一次,建议客户音频超过 60s 时,开启 vad(人声检测切分功能),提升切分效果。 |
filter_dirty | 否 | Integer | 是否过滤脏词(目前支持中文普通话引擎)。默认为 0。 0:不过滤脏词; 1:过滤脏词; 2:将脏词替换为 "\\*"。 |
filter_modal | 否 | Integer | 是否过滤语气词(目前支持中文普通话引擎)。默认为 0。 0:不过滤语气词; 1:部分过滤; 2:严格过滤。 |
filter_punc | 否 | Integer | 是否过滤句末的句号(目前支持中文普通话引擎)。默认为 0。 0:不过滤句末的句号; 1:过滤句末的句号。 |
convert_num_mode | 否 | Integer | 是否进行阿拉伯数字智能转换(目前支持中文普通话引擎): 0:不转换,直接输出中文数字; 1:根据场景智能转换为阿拉伯数字。默认值为 1。 |
word_info | 否 | Integer | 是否显示词级别时间戳: 0:不显示; 1:显示,不包含标点时间戳。 |
vad_silence_time | 否 | Integer | 语音断句检测阈值,静音时长超过该阈值会被认为断句(多用在智能客服场景,需配合 needvad = 1 使用),取值范围:240-2000(默认 1000),单位 ms,此参数建议不要随意调整,可能会影响识别效果。 |
max_speak_time | 否 | Integer | 强制断句功能,取值范围 5000-90000(单位:毫秒),默认值 60000。在连续说话不间断情况下,该参数将实现强制断句(此时结果变成稳态,slice_type=2)。如:游戏解说场景,解说员持续不间断解说,无法断句的情况下,将此参数设置为 10000,则将在每 10 秒收到 slice_type=2 的回调。 |
signature | 是 | String | 接口签名参数,用于兼容第三方服务。如果不涉及,值与 X-TRTC-UserSig 一致。 |
hotword_list | 否 | String | 临时热词表:该参数用于提升识别准确率。 单个热词限制:“热词|权重”,单个热词不超过 30 个字符(最多 10 个汉字),权重 [1-11] 或者 100,例如:“腾讯云|5” 或 “ASR|11”; 临时热词表限制:多个热词用英文逗号分割,最多支持 128 个热词,例如:“腾讯云|10,语音识别|5,ASR|11”。 注意: 热词权重设置为 11 时,当前热词将升级为超级热词,建议仅将重要且必须生效的热词设置到 11,设置过多权重为 11 的热词将影响整体字准率。 热词权重设置为 100 时,当前热词开启热词增强同音替换功能。 举例:热词配置“蜜制|100”时,与"蜜制"同拼音(mizhi)的“秘制”的识别结果会被强制替换成“蜜制”。因此建议客户根据自己的实际情况开启该功能。建议仅将重要且必须生效的热词设置到 100,设置过多权重为 100 的热词将影响整体字准率。热词不能包含空格,例如:ASR 腾讯云。 |
language | 否 | String | 当 engine_model_type 指定 bigmodel 时,可指定音频语种。支持语种包括:zh(中文)、en(英语)、yue(粤语)、ar(阿拉伯语)、de(德语)、fr(法语)、es(西班牙语)、pt(葡萄牙语)、id(印尼语)、it(意大利语)、ko(韩语)、ru(俄语)、th(泰语)、vi(越南语)、ja(日语)、tr(土耳其语)、hi(印地语)、ms(马来语)、nl(荷兰语)、sv(瑞典语)、da(丹麦语)、fi(芬兰语)、pl(波兰语)、cs(捷克语)、fil(菲律宾语)、fa(波斯语)、el(希腊语)、ro(罗马尼亚语)、hu(匈牙利语)、mk(马其顿语) 示例值:zh。 说明: 不填写该字段时,模型会自动识别语种。 |
sample_rate | 否 | String | 采样速率,可选值:8k 或 16k。 |
请求响应
客户端发起连接请求后,后台建立连接并进行签名校验,校验成功则返回 code 值为 0 的确认消息表示握手成功;如果校验失败,后台返回 code 为非 0 值的消息并断开连接。
{"code": 0,"message": "success","voice_id": "faab2b17-ba43-4ea4-be58-a03180ba26dd"}
识别阶段
上传数据
在识别过程中,客户端持续上传 binary message 到后台,内容为音频流二进制数据。每 40ms 发送 40ms 时长(即 1:1 实时率)的数据包,对应 PCM 大小为:8k 采样率 640 字节,16k 采样率 1280 字节。音频数据包之间发送间隔超过 6 秒,可能导致引擎出错,后台将返回错误并主动断开连接。
音频流上传完成之后,客户端需发送以下内容的 text message,通知后台结束识别。
{"type": "end"}
接收消息
客户端上传数据的过程中,需要同步接收后台返回的实时识别结果,结果示例:
{"code": 0,"message": "success","voice_id": "faab2b17-ba43-4ea4-be58-a03180ba26dd","message_id": "RnKu9FODFHK5FPpsrN_11_0","result": {"slice_type": 0,"index": 0,"start_time": 0,"end_time": 1240,"voice_text_str": "实时","word_size": 0,"word_list": []}}
{"code": 0,"message": "success","voice_id": "faab2b17-ba43-4ea4-be58-a03180ba26dd","message_id": "RnKu9FODFHK5FPpsrN_33_0","result": {"slice_type": 2,"index": 0,"start_time": 0,"end_time": 2840,"voice_text_str": "实时语音识别","word_size": 0,"word_list": []}}
后台识别完所有上传的语音数据之后,最终返回 final 值为 1 的消息并断开连接。
{"code": 0,"message": "success","voice_id": "faab2b17-ba43-4ea4-be58-a03180ba26dd","message_id": "8d9e6337-2c8a-49e2-aee9-9179d71ab7a8","final": 1}
识别过程中如果出现错误,后台返回 code 为非 0 值的消息并断开连接。
{"code": 4008,"message": "后台识别服务器音频分片等待超时","voice_id": "faab2b17-ba43-4ea4-be58-a03180ba26dd","message_id": "8d9e6337-2c8a-49e2-aee9-9179d71ab7a8"}
错误码
数值 | 说明 |
4000 | 音频数据发送过多,请1秒内最多发送3秒音频数据。 注意: 实时识别的效果是“边说边出文字”,1秒内发送的音频数据总时长应为1秒。 |
4001 | 参数不合法,具体详情参考 message。 |
4002 | 鉴权失败。 |
4003 | AppID 服务未开通,请在控制台开通服务。 |
4004 | 资源包耗尽,请开通后付费或者购买资源包。 |
4005 | 账户欠费停止服务,请及时充值。 |
4006 | 账号当前调用并发超限。 |
4007 | 音频解码失败,请检查上传音频数据格式与调用参数一致。 |
4008 | 客户端超过 6 秒未发送音频数据。 |
4009 | 客户端连接断开。 |
4010 | 客户端上传未知文本消息。 |
5000 | 因机器负载过高、网络抖动等导致失败,请重新发起新识别。 注意: 该问题通常为偶发,少量出现可忽略,发起新识别即可。 |
5001 | 因机器负载过高、网络抖动等导致失败,请重新发起新识别。 注意: 该问题通常为偶发,少量出现可忽略,发起新识别即可。 |
5002 | 因机器负载过高、网络抖动等导致失败,请重新发起新识别。 注意: 该问题通常为偶发,少量出现可忽略,发起新识别即可。 |



