Snapshot 迁移常见问题
COS 插件安装问题
插件 zip 包无需解压,直接安装即可。安装时指定的 file:/// 协议是三条斜杠,其中前面两个 // 是协议与路径的分隔符,后面一个 / 是绝对路径开头的根目录。待安装的插件 zip 包不可放在 es 目录下,可以放在 /tmp 或者家目录,否则可能会安装失败。执行安装命令时,不可位于 es bin/ 路径下,需要在 es bin/ 路径外面执行,否则可能会安装失败。
不同版本仓库注册问题
Cos Snapshot API 需要区分 ES 版本 < 8.x 和 ES 版本 ≥ 8.x。
8.x 之前的注册方式为:
PUT _snapshot/my_cos_backup{"type": "cos","settings": {"app_id": "xxxxxxx","access_key_id": "xxxxxx","access_key_secret": "xxxxxxx","bucket": "xxxxxx", // cos bucket后面生成的 -appid 不可以填进来"region": "ap-guangzhou","base_path": "my_cos_backup","max_restore_bytes_per_sec":"40m", // 每个节点的恢复速率,可按需调整"max_snapshot_bytes_per_sec":"40m" // 每个节点的备份速率,可按需调整}}
8.x 及以后版本的注册方式为:
PUT _snapshot/my_cos_backup{"type": "cos","settings": {"cos": {"client": {"app_id": "xxxxxxx","access_key_id": "xxxxxx","access_key_secret": "xxxxxxx","bucket": "xxxxxx","region": "ap-guangzhou","base_path": "my_cos_backup","max_restore_bytes_per_sec": "40m","max_snapshot_bytes_per_sec": "40m"}},"compress": true,"chunk_size": "500mb"}}
仓库快照无法展示问题
由于 ES 自身问题,7.14 版本起不再动态加载仓库的快照列表,当源端仓库发生变化时,目标端仓库需要重新注册,以加载最新的快照列表。注意,该特殊操作只在目标端执行,例如:
# 第一次同步PUT _snapshot/my_cos_backup{"type": "cos",// 省略}# 第二次同步PUT _snapshot/my_cos_backup2{"type": "cos",// 省略}
不同版本冷热属性兼容问题
Elasticsearch 恢复快照时,需要指定数据节点的冷热属性,且不同 ES 版本使用的 API 命令存在差异,具体差异如下。
指定热节点恢复:
// 腾讯云 ES < 7.14版本命令如下:POST _snapshot/my_cos_backup/snapshot_1/_restore{"indices":"{hot_index}*,-.*,-ilm-*","index_settings": {"index.routing.allocation.require.temperature": "hot"},"ignore_index_settings": ["index.routing.allocation.require.temperature"]}// ES >= 7.14版本命令如下:POST _snapshot/my_cos_backup/snapshot_1/_restore{"indices":"{hot_index}*,-.*,-ilm-*","index_settings": {"index.routing.allocation.include._tier_preference": "data_hot,data_warm,data_cold"},"ignore_index_settings": ["index.routing.allocation.require.temperature"]}
指定冷节点恢复:
// 腾讯云 ES < 7.14版本命令如下:POST _snapshot/my_cos_backup/snapshot_1/_restore{"indices":"{warm_index}*,-.*,-ilm-*","index_settings": {"index.routing.allocation.require.temperature": "warm"}}// 腾讯云 ES >= 7.14版本命令如下:POST _snapshot/my_cos_backup/snapshot_1/_restore{"indices":"{warm_index}*,-.*,-ilm-*","index_settings": {"index.routing.allocation.include._tier_preference": "data_warm,data_hot,data_cold"}}
快照备份/恢复慢的问题
当使用腾讯云 ES 的快照功能时,可能会遇到备份或恢复速度慢的情况。下面提供两种优化方案,帮助用户根据实际网络环境和集群状态调整配置,提升效率。
问题流程诊断

1. 检查集群网络环境
若能访问腾讯云内网:优先通过增加快照仓库备份/恢复速率和增加分片迁移线程并发数进行优化。
若通过公网访问:需确认快照备份/恢复速度是否已达到公网或 COS 带宽上限。
2. 根据结果选择优化方案
若带宽未达上限,可能是集群配置或硬件性能问题,需进一步排查。
更改快照仓库备份/恢复速率。
调整快照恢复速率属于高风险操作,在数据恢复过程中可能对集群产生影响,需谨慎操作。该参数不支持动态修改,若备份/恢复任务正在进行,API 将拒绝请求,需等待任务完成后再更新。修改仓库参数时应仅调整恢复速率,避免改动其他仓库参数,否则可能导致恢复异常。以 ES 7.x为例:
PUT _snapshot/my_cos_backup{"type": "cos","settings": {"app_id": "xxxxxxx","access_key_id": "xxxxxx","access_key_secret": "xxxxxxx","bucket": "xxxxxx","region": "ap-guangzhou","compress": true,"chunk_size": "500mb","base_path": "my_cos_backup","max_restore_bytes_per_sec":"100m", // 每个节点的恢复速率,可按需调整"max_snapshot_bytes_per_sec":"100m" // 每个节点的备份速率,可按需调整}}
更改集群分片迁移线程并发数:
PUT _cluster/settings{"transient":{"cluster.routing.allocation.node_concurrent_recoveries":10,"cluster.routing.allocation.node_concurrent_incoming_recoveries":10,"cluster.routing.allocation.node_initial_primaries_recoveries":10,"cluster.routing.allocation.node_concurrent_outgoing_recoveries":10,"cluster.routing.allocation.cluster_concurrent_rebalance":2,"indices.recovery.max_bytes_per_sec":"100mb"}}
恢复完成后,还需要回滚加速操作:
PUT _cluster/settings{"transient":{"cluster.routing.allocation.node_concurrent_recoveries":null,"cluster.routing.allocation.node_concurrent_incoming_recoveries":null,"cluster.routing.allocation.node_initial_primaries_recoveries":null,"cluster.routing.allocation.node_concurrent_outgoing_recoveries":null,"cluster.routing.allocation.cluster_concurrent_rebalance":null,"indices.recovery.max_bytes_per_sec": null}}
索引只读(read only)问题
在进行最后一次增量前的切割操作时,建议通过业务主动停止写入的方式实现停写。若采用 index block write/read only 的方式停写,该索引属性会被同步到快照,在恢复时也会携带禁写属性。因此恢复后必须主动回滚索引的只读属性设置并验证业务写入功能,否则会导致业务不可写。
删除快照导致 shard lock 的问题
快照创建过程中应避免执行 DELETE snapshot 操作,该操作属于高负载行为,可能导致集群稳定性问题,比如引起索引 shard lock,且存在较高超时风险。如确需删除,建议等待当前快照任务完成后操作。
通配符匹配 closed 索引问题
当源端存在处于 closed 状态的索引时,无法通过通配符模式进行备份操作,需明确指定待备份索引的全称,若涉及多个索引需使用英文逗号作为分隔符进行罗列。
rollover 场景问题
在日志场景有 rollover 的情况下,如果 is_write_index 属性发生变化,则会发生恢复失败的问题,具体表现为日志里会抛异常:
Caused by: java.lang.IllegalStateException: alias [xxxxx] has more than one write index [xxxxx-2023.10.25-000001, xxxxx-2023.10.26-000002]
解决方案为取消目标端索引旧的 is_write_index 属性:
POST _aliases{"actions" : [{"add" : {"index" : "xxxx-2023.10.25-000001","alias" : "xxxx","is_write_index" : false}}]}
此外在日志场景有 rollover 的情况下,建议业务切割上云之后,再同步 ilm 任务,否则会发生目标集群 ilm 提前触发 rollover 的可能,同样会导致 is_write_index 属性冲突问题。
数据量 > 10T的备份场景
当集群索引数量或数据量达到一定规模时,为避免单次快照备份耗时过长引发异常中断,需要进行分组备份。下方提供了在线和离线两种分组工具的安装方式。
在线安装:通过执行以下命令,直接从指定的网络地址在线安装分组工具。
rpm -vih https://tools-release-1253240642.cos.ap-shanghai.myqcloud.com/elasticsearch/packages/es-index-grouping-1.4-1.el7.x86_64.rpm
离线安装:先将工具包下载至本地,然后上传,再使用以下 rpm 命令进行安装。
rpm -vih es-index-grouping-1.4-1.el7.x86_64.rpm
完成分组工具安装后,需按以下步骤执行备份:首先,通过分组工具对 Elasticsearch 集群索引进行分组,生成分组索引列表(index list);其次,将分组后的 index list 根据不同快照进行备份;最后,在恢复时选择时间最新的完整快照执行全量恢复即可。
Logstash 迁移常见问题
不同版本冷热属性兼容问题
在 Logstash 迁移过程中,不同版本 ES 会存在冷热属性兼容问题,需要将目标端创建好的空索引预先进行冷热分层。
指定热数据:
// 腾讯云 ES < 7.14版本命令如下:PUT {hot_index}-*/_settings{"index.routing.allocation.require.temperature": "hot"}// ES >= 7.14版本命令如下:PUT {hot_index}-*/_settings{"routing": {"allocation": {"include": {"_tier_preference": "data_hot,data_warm,data_cold"},"require": {"temperature": null}}}}
指定冷数据:
// 腾讯云 ES < 7.14版本命令如下:PUT {warm_index}-*/_settings{"index.routing.allocation.require.temperature": "warm"}// ES >= 7.14版本命令如下:PUT {hot_index}-*/_settings{"routing": {"allocation": {"include": {"_tier_preference": "data_warm,data_hot,data_cold"},"require": {"temperature": null}}}}
索引同步加速问题
在索引数量较大的场景下,需将索引分成多个组,以启动多个管道来加速迁移。下方提供了在线和离线两种分组工具的安装方式。
在线安装:通过执行以下命令,直接从指定的网络地址在线安装分组工具。
rpm -vih https://tools-release-1253240642.cos.ap-shanghai.myqcloud.com/elasticsearch/packages/es-index-grouping-1.4-1.el7.x86_64.rpm
离线安装:先将工具包下载至本地,然后上传,再使用以下 rpm 命令进行安装。
rpm -vih es-index-grouping-1.4-1.el7.x86_64.rpm
完成索引分组后,将分组后的 index list 根据不同的管道要求,填入对应的 index => 配置项中。例如,若将索引分为了 10 个组,则需创建 10 个管道来分别处理这些索引组。
Logstash 增量同步问题
Logstash 本身不支持自动增量同步功能。若需实现增量同步,需依赖业务侧通过 query 语句筛选数据,并确保业务数据包含类似 update_time 的字段以标识更新时间。若业务数据仅包含 create_time 或 @timestamp 等字段,则只能实现增量同步(新增数据),无法实现差异同步(更新数据)。同时应注意 logstash 不支持自动同步删除操作。
以下为 Logstash input 增量同步示例:
input {elasticsearch {# 源端ES地址。hosts => ["http://localhost:9200"]# 安全集群配置登录用户名密码。user => "xxxxxx"password => "xxxxxx"# 需要迁移的索引列表,多个索引使用英文逗号(,)分隔,支持通配。index => "sample_data"# 按时间范围查询差异数据,以下配置表示查询最近5分钟更新的数据。query => '{"query":{"range":{"update_time":{"gte":"now-5m","lte":"now/m"}}}}'# 定时任务,以下配置表示每分钟执行一次。schedule => "* * * * *"scroll => "5m"docinfo=>truesize => 5000}output {elasticsearch {hosts => ["http://10.2.x.x:9200"]user => "elastic"password => "your_password"index => "%{[@metadata][_index]}"document_type => "%{[@metadata][_type]}"document_id => "%{[@metadata][_id]}"}}
在进行 logstash 增量同步操作前,建议进行充分调试。具体做法是将 input 插件里的 query 语句提取出来,在源端执行该语句,查看是否能够查询到数据,以此确保同步操作的准确性和稳定性。例如:
GET sample_data/_search{"query": {"range": {"update_time": {"gte": "now-5m","lte": "now/m"}}},"_source": "update_time"}
当排除字段名称输入错误的可能后,若查询仍无数据返回,通常存在两种原因。
1. 源端数据存在同步延迟或通过定时批量任务进行更新。当前查询时间范围(例如 now-5m)可能无法覆盖实际数据到达时间,此时可逐步扩大查询窗口,例如调整为 now-5h 以适配延迟周期。也可以直接查询源端数据的最大时间戳验证数据实时性,例如:
GET sample_data/_search{"sort": [{"update_time": {"order": "desc"}}],"_source": "update_time"}
2. 源端数据的时间字段类型为 keyword 或 text,而非 date 类型。此时即使该字段存储的是时间格式的字符串,也无法直接进行时间运算或使用 range 查询,最终将导致查询结果为空。
若查询结果中的时间字段值比当前系统时间少8小时,属于正常现象,因为 ES 默认采用 UTC 时间标准,此时无需对时间进行额外转换处理。
若查询结果的时间值与当前系统时间完全一致(未出现8小时差值),则表明数据在写入时未采用 UTC 时间标准,此时需在 logstash 同步配置中使用 now 时间运算进行补偿,例如配置为now+8h。若数据本身存在延迟写入的情况,可在基础补偿值8小时的基础上,根据实际延迟时长额外增加对应的时间偏移量。
若查询报错,则说明使用的时间字段不是时间类型,而是数值类型或其他类型,例如:
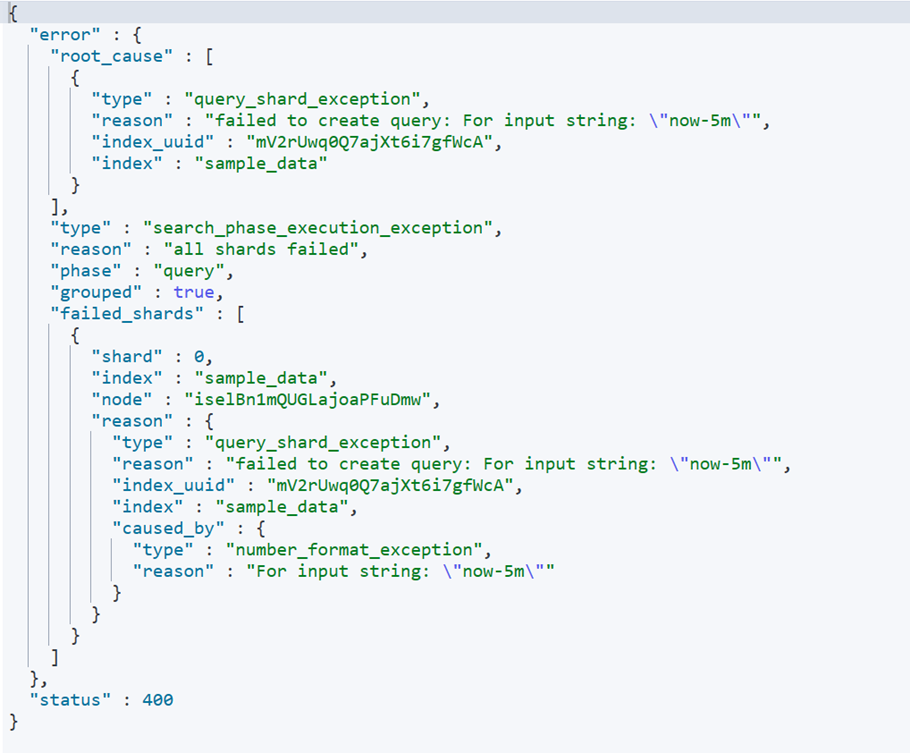
跨版本 Type 变更问题
ES 各版本多索引 Type 支持如下表:
ES 版本 | Type 支持 | 默认 Type |
5.x | 多 Type | 无 |
6.x | 单 Type | doc |
7.x | 单 Type | _doc |
8.x | 无 | 无 |
如果将 ES 5.x 多 type 索引迁移到 ES 6.x 需要使用如下配置将每个 type 的数据单独导入一个索引。
input {elasticsearch {hosts => ["10.0.x.x:9200"]user => "elastic"password => "passwd"index => "test" #多type索引docinfo => truesize => 5000scroll => "5m"}}output {if [@metadata][_type] == "type1" {elasticsearch {hosts => ["http://10.0.x.x:9200"]user => "elastic"password => "passwd"index => "type1"document_type => "_doc"document_id => "%{[@metadata][_id]}"}}else if [@metadata][_type] == "type2"{elasticsearch {hosts => ["http://10.0.x.x:9200"]user => "elastic"password => "passwd"index => "type2"document_type => "_doc"document_id => "%{[@metadata][_id]}"}}}



