Logstash 的一个典型应用场景,就是消费 kafka 中的数据并且写入到 Elasticsearch,使用腾讯云的 Logstash 产品,可以通过简单的配置快速地完成这一过程。
创建管道
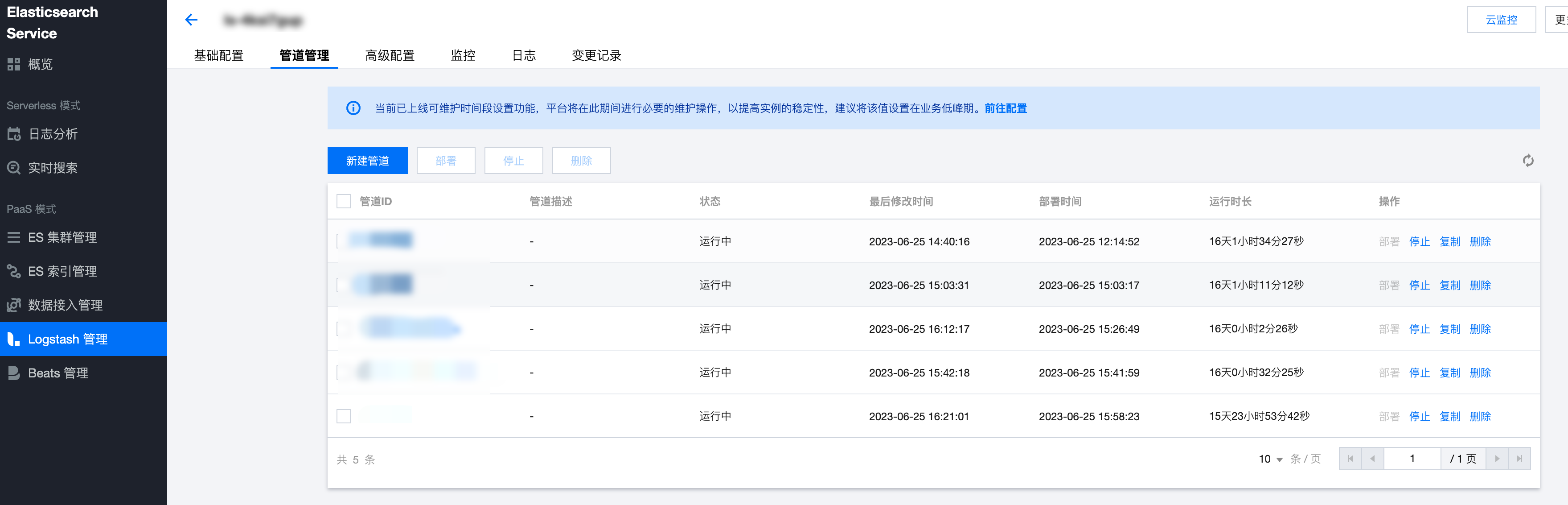
1. 登录 Elasticsearch Service 控制台,单击 Logstash 管理,选择需要操作的实例,单击实例 ID/名称,进入实例基本信息页面。
2. 切换到“管道管理”页签,单击新建管道,创建一个管道。
3. 进入新建管道页面,单击引用模板。

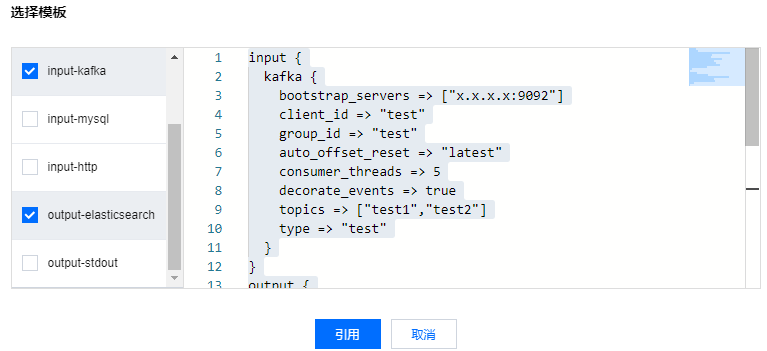
在管道配置中,分别针对“input-kafka”和“output-elasticsearch”进行配置,一些关键的配置参数说明如下:
input-kafka
bootstrap_servers:kafka 服务端地址列表
client_id:客户端 ID
group_id:消费组 ID
consumer_threads:消费线程数量,建议保持:该参数 × Logstash 实例节点的数量 = topic 的 partitions 数量
topics:topic 列表
auto_offset_reset:当 kafka 中 topic 没有初始的 offset 时,如何重置 offset,常用可选值为 earliest(最早)、latest(最新)
type:标识字段
output-elasticsearch
hosts:elasticsearch 集群地址列表
user:elasticsearch 集群账号
password:elasticsearch 集群密码
index:索引名称
document_type:索引 type,对于不同版本的 ES 集群,该字段有不同的默认值,5.x及以下版本的集群,默认会使用 input 中指定的 type 字段。如果 type 字段不存在,则该字段的值为 doc;6.x版本的集群,该字段默认值为 doc;7.x版本的集群,该字段默认值为_doc;8.x版本的集群,不会使用该字段。
document_id:文档 ID
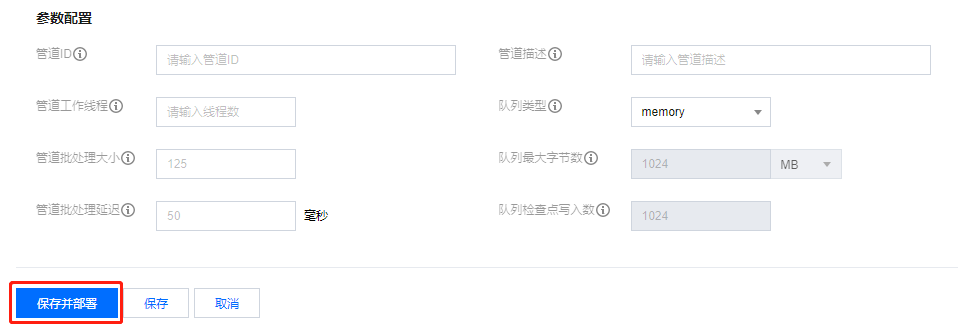
在配置完管道后,单击保存并部署即可创建一个管道并自动部署。
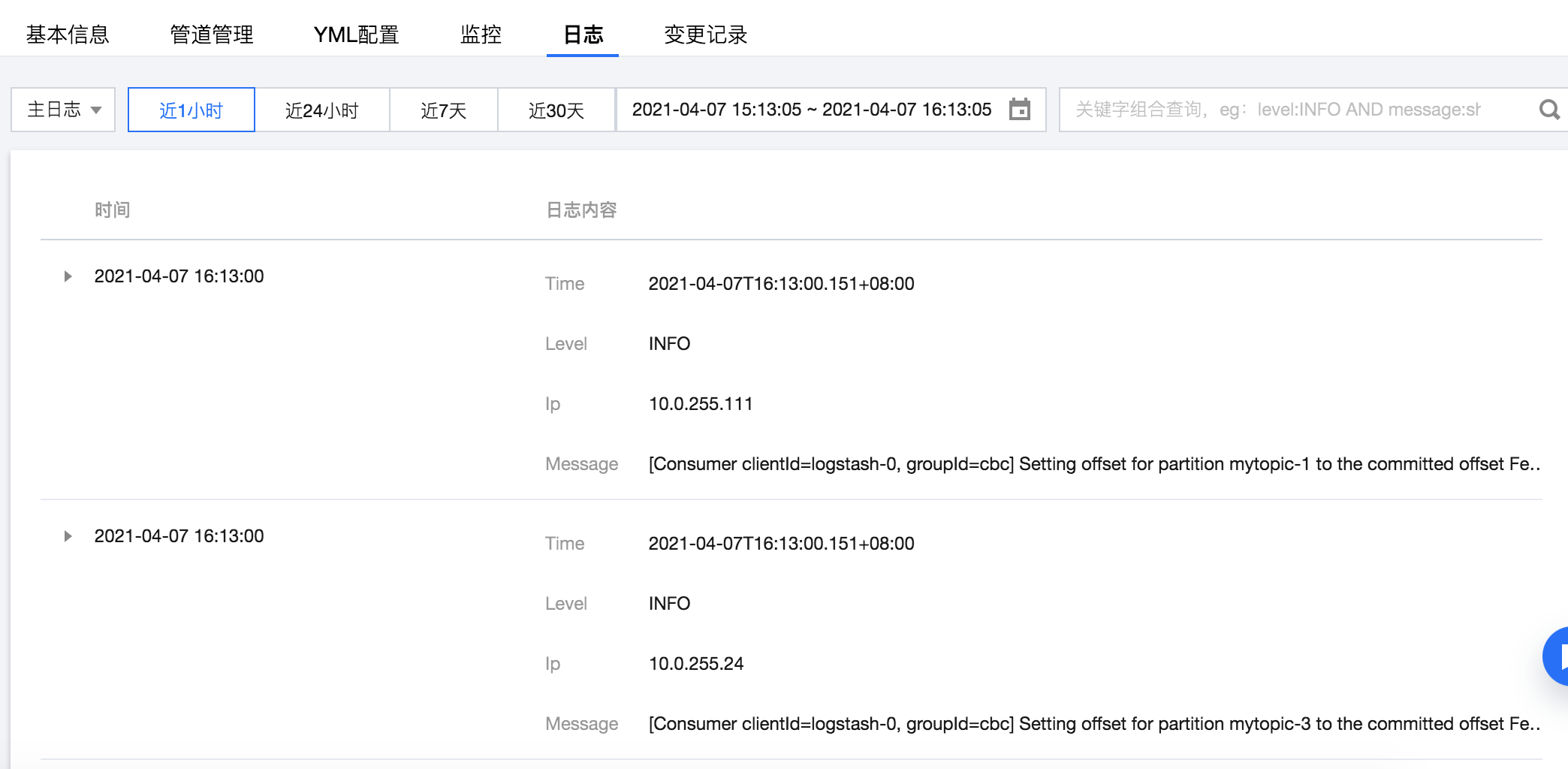
查看日志
在控制台查看 Logstash 的运行日志,如果没有 ERROR 级别的日志,则说明管道运行正常。
查看数据写入情况
进入到 output-elasticsearch 中定义的输出端的 ES 集群对应的 kibana 页面,在 Dev tools 工具栏里查看索引是否存在,以及索引的文档数量是否正确。



