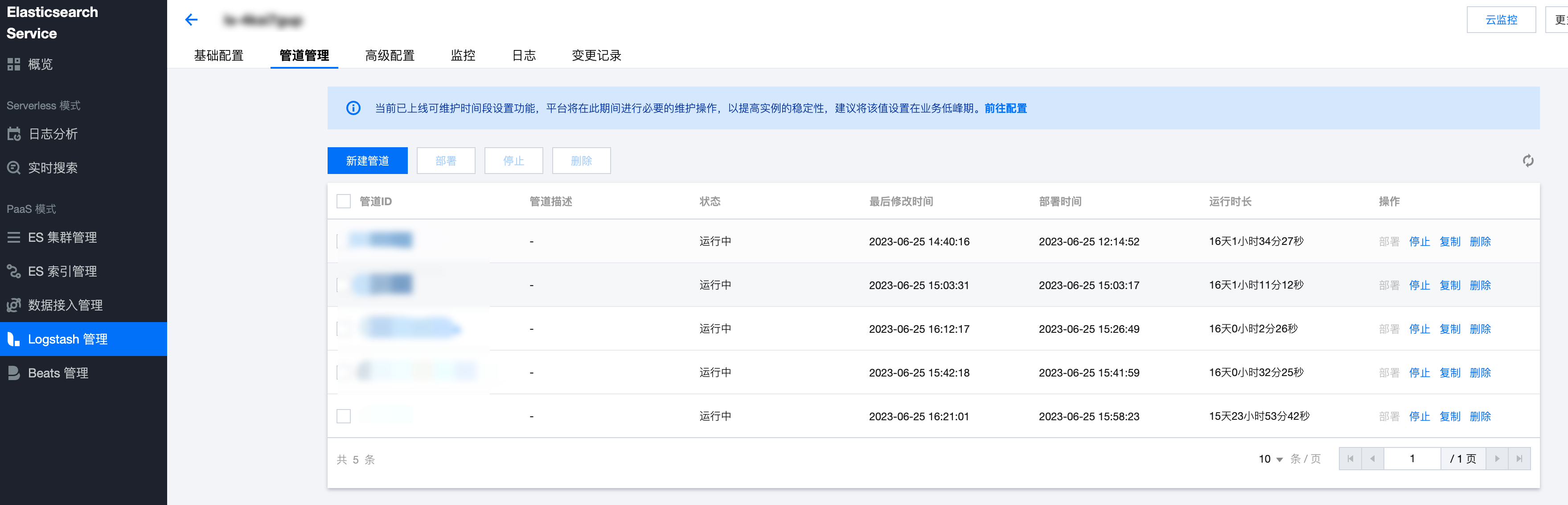
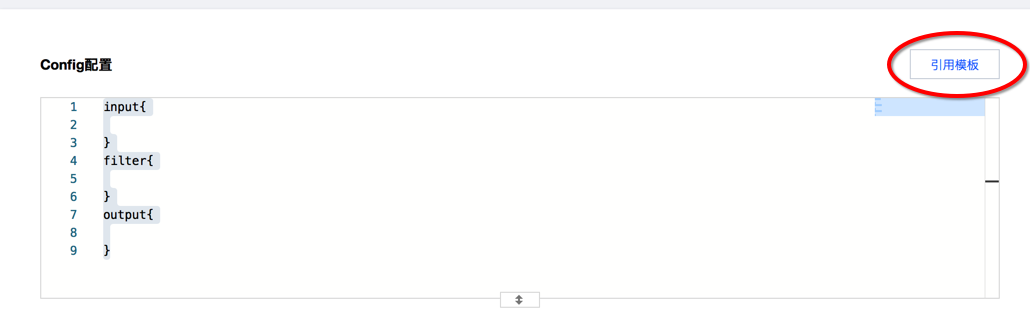
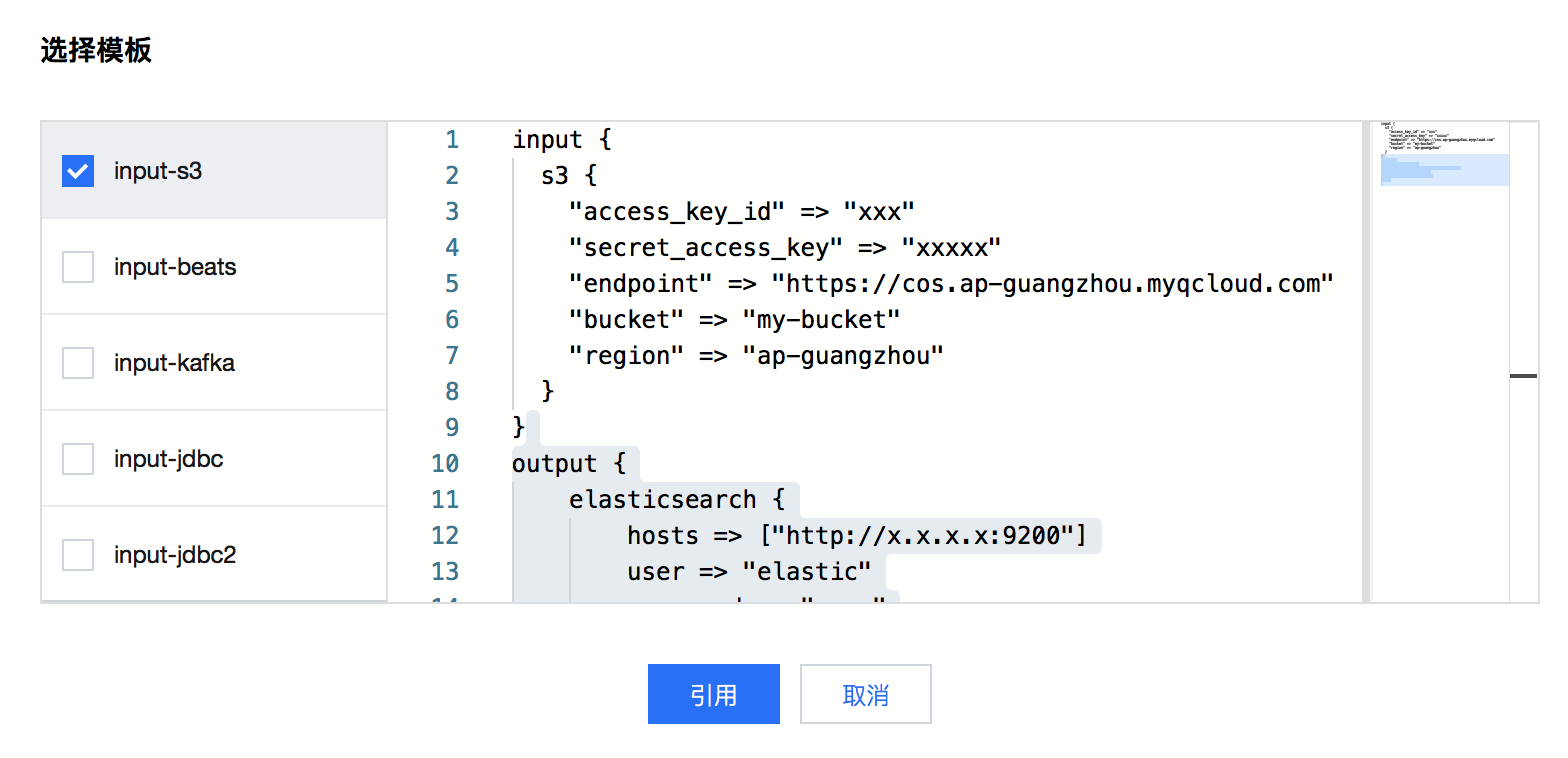
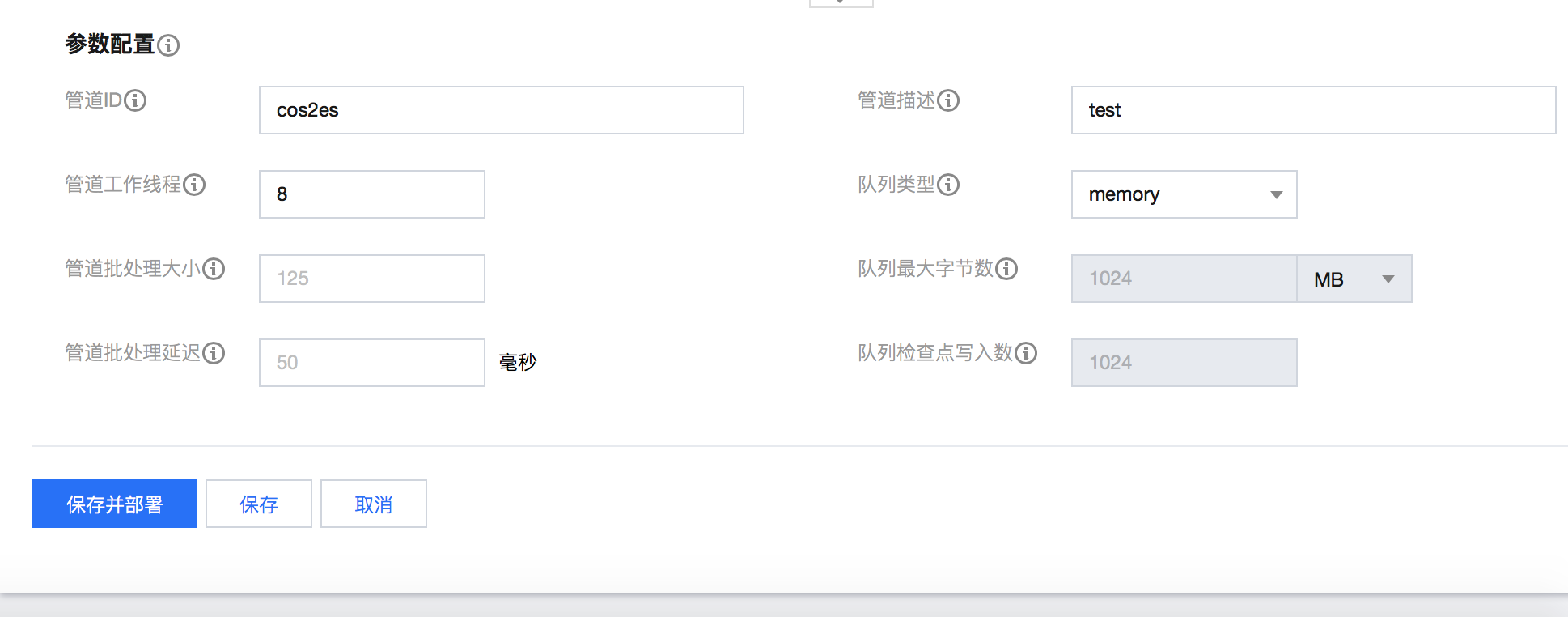
在某些场景中,业务服务端或云上组件的日志会归档存储到对象存储 COS 中,在需要进行查询时,需要从 COS 中获取并查询日志。此时,可借助 Logstash 自动地读取 COS 中指定 bucket 的日志文件,然后写入到 Elasticsearch 中,再使用 Kibana 可视化组件进行查询和分析。
document_type:索引 type,对于不同版本的 ES 集群,该字段有不同的默认值,5.x及以下的集群,默认会使用 input 中指定的 type 字段,如果 type 字段不存在,则该字段的值为 doc;6.x的集群,该字段默认值为 doc;7.x的集群,该字段默认值为_doc;8.x的集群,不会使用该字段。