为了兼容用户通过其他实时计算平台(例如 Dinky/StreamPark)提交作业的情况,使之前使用 yarn 的客户管控平台不需要进行修改;复用 Oceanus 流计算平台的优势。
目前支持Yarn 原生命令,Dinky 和 StreamPark 平台 yarn application 模式对接 Oceanus, 仅支持 Flink-1.14,Flink-1.16,Flink-1.18(历史集群 Flink1.18 需开白使用)版本, Dinky 版本 dinky-release-1.16-1.0.3,StreamPark 版本2.1.4。
注意事项
1. 指定作业发布到指定的空间,在客户端的 flink-conf.yaml,新加一行 Oceanus.WorkSpaceId: space-****(从 Oceanus 控制台获取空间 ID,工作空间目录进入),否则默认将作业发布到名称为 external 的空间。
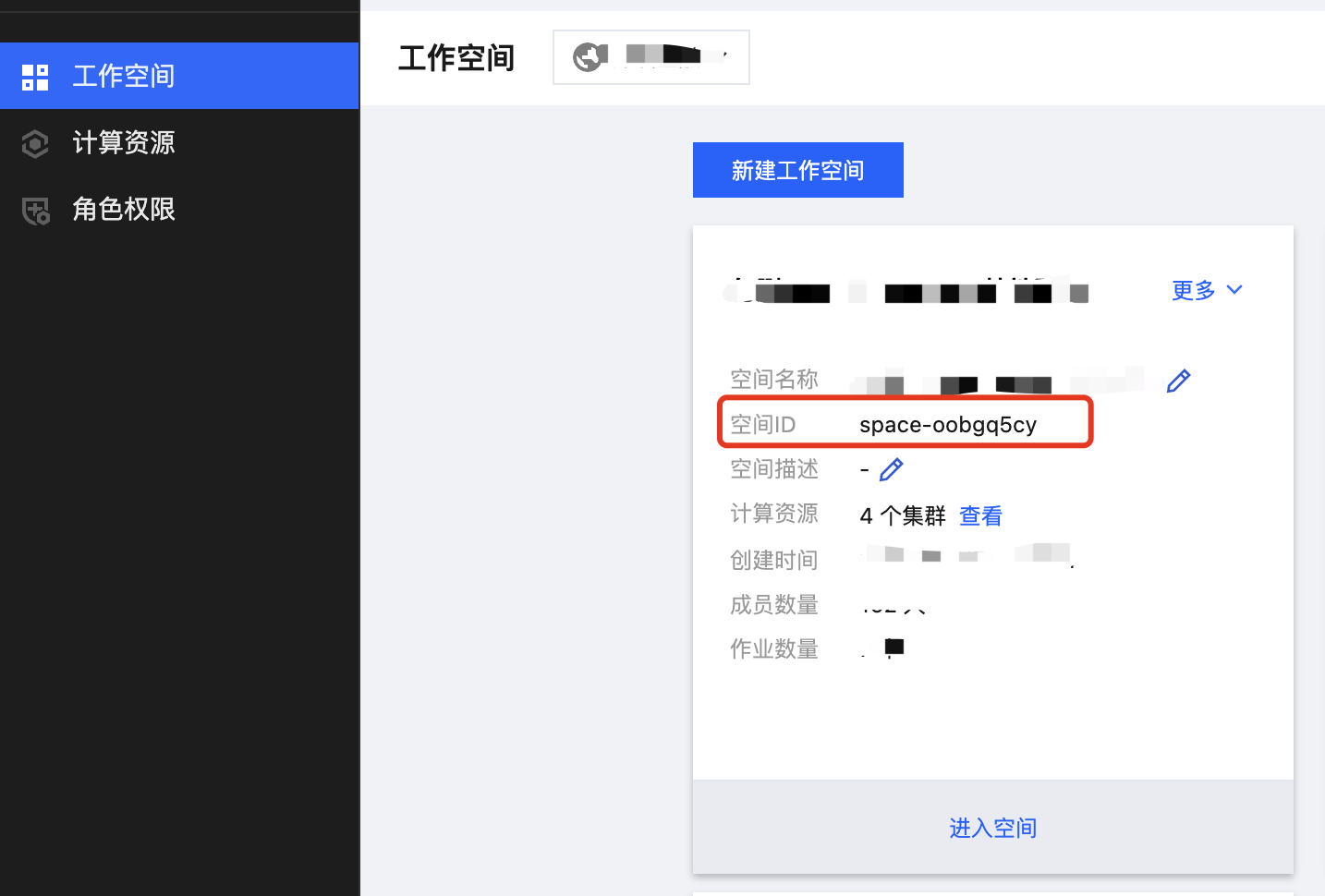
2. 启动、停止作业,触发 savepoint 等操作都可以在 Oceanus 控制台操作。
3. jar 作业的 pom 依赖,除了 flink connector 不设置为 provided,其他如涉及 flink 基本依赖的需要设置为 provided,否则有依赖冲突。
<properties><flink.scope>provided</flink.scope></properties><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>${flink.version}</version><scope>${flink.scope}</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version><scope>${flink.scope}</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>${flink.scope}</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version><scope>${flink.scope}</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>${flink.scope}</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>${flink.version}</version><scope>${flink.scope}</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>${flink.scope}</scope></dependency>
操作步骤
1. 在计算资源 > 进入目标集群页面 > 集群服务, 开启 Yarn 接口访问(实际部署了 hadoop yarn 服务),开启 Yarn 接口访问所需要的资源将从独享集群的可用 CU 数中扣除10CU。
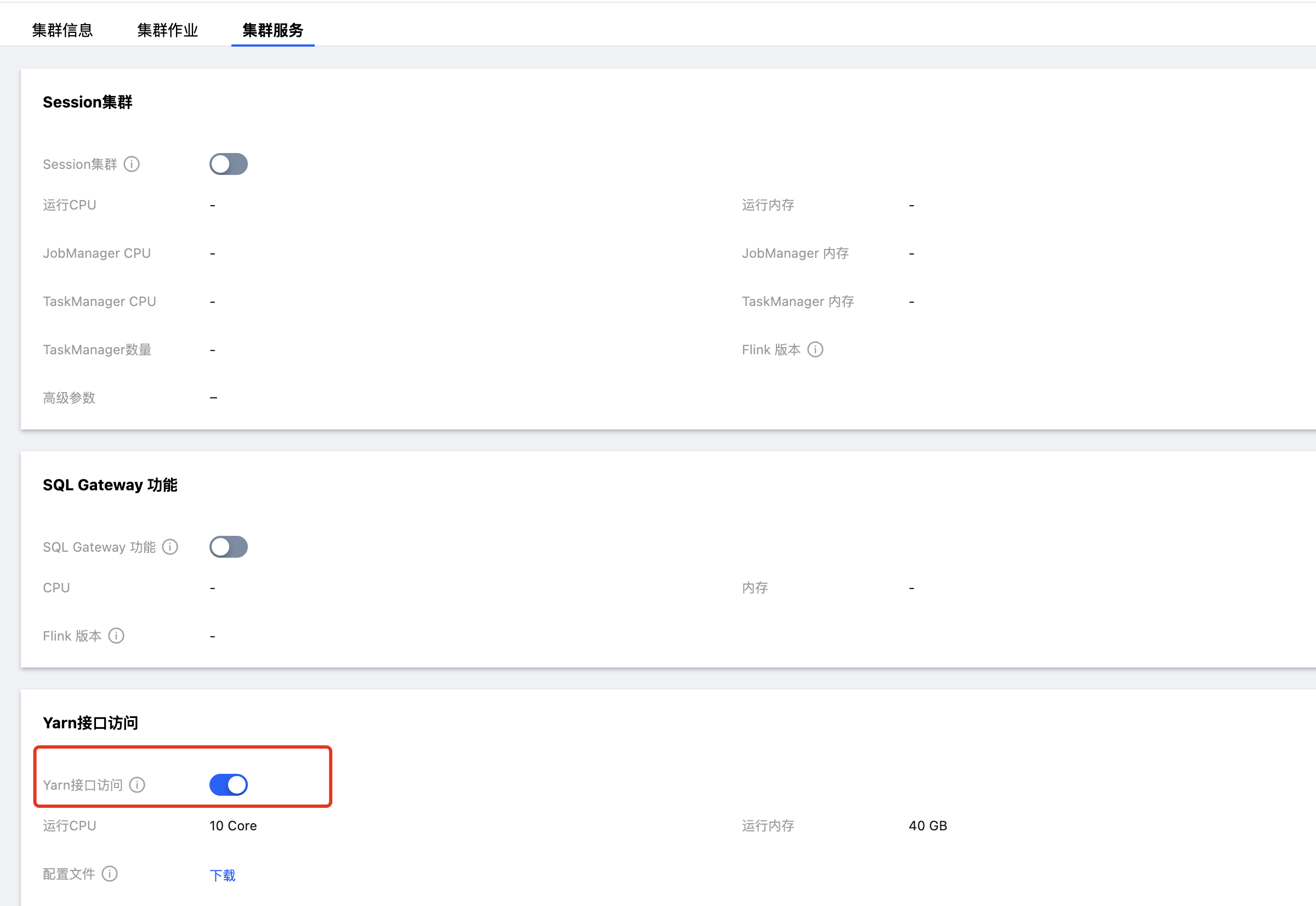
说明:
开启 Yarn 接口访问,若出现"Cluster is not support yarn mode, please contact us to upgrade oceanus control components." 错误,请 提交工单 联系我们升级管控组件后再开启。
2. 下载配置文件,zip 包解压之后有以下7个文件。
core-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xmldinky-config.yamlstreampark-config.yamlhosts
其中将 core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml 放到 hadoop home 的目录 etc/hadoop;dinky-config.yaml 文件中有 flink 各版本lib 路径、HDFS 操作用户名、HDFS defaultFS ;streampark-config.yaml 包含 StreamPark 服务目录 conf/config.yaml streampark 部分的内容;hosts 中内容追加到 /etc/hosts 文件中。
Yarn 原生命令提交示例
flink lib 目录下包含flink-shaded-hadoop-**.jar,下载上述配置文件并放在指定目录;仅支持 jar 作业。
参数 | 描述 |
yarn.provided.lib.dirs | 不同Flink版本对应路径不同 #Flink1.14 Lib 路径 hdfs:///dinky/flink1.14/lib #Flink1.16 Lib 路径 hdfs:///dinky/flink1.16/lib #Flink1.18 Lib 路径 hdfs:///dinky/flink1.18/lib |
yarn.application.name | 作业名称 |
JobManagerCpu | |
JobManagerMem | |
TaskManagerCpu | |
TaskManagerMem | |
yarn.ship-files | 依赖程序,在节点本地,例如:/opt/connector/flink-connector-logger-1.14.jar |
Flink 版本 | shell 命令 example |
flink 1.14 | ./bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs=hdfs:///dinky/flink1.14/lib -Dyarn.application.name=wordcount_native_114 -DJobManagerCpu=0.5 -DJobManagerMem=2.0 -DTaskManagerCpu=0.5 -DTaskManagerMem=2.0 -Dyarn.ship-files=/opt/connector/flink-connector-logger-1.14.jar -c com.tencent.cloud.test.WordCount /tmp/flink-hello-world-4.0.0-jar-with-dependencies.jar |
flink 1.16 | ./bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs=hdfs:///dinky/flink1.16/lib -Dyarn.application.name=wordcount_native_116 -DJobManagerCpu=0.5 -DJobManagerMem=2.0 -DTaskManagerCpu=0.5 -DTaskManagerMem=2.0 -Dyarn.ship-files=/opt/connector/flink-connector-logger-1.16.jar -c com.tencent.cloud.test.WordCount /tmp/flink-hello-world-4.0.0-jar-with-dependencies.jar |
flink 1.18 | ./bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs=hdfs:///dinky/flink1.18/lib -Dyarn.application.name=wordcount_native_118 -DJobManagerCpu=0.5 -DJobManagerMem=2.0 -DTaskManagerCpu=0.5 -DTaskManagerMem=2.0 -Dyarn.ship-files=/opt/connector/flink-connector-jdbc-flink1.18.jar -c com.tencent.cloud.test.WordCount /tmp/flink-hello-world-4.0.0-jar-with-dependencies.jar |
Dinky 提交示例
1. 注册中心/集群/集群配置。
将上述 hadoop 的四个配置文件放到 had/usr/hadoop/etc/hadoop 目录名可替换为用户的 hadoop home。
flink 1.14 的集群配置,不同 flink 版本 Flink Lib 路径不一致, Flink 配置文件路径不一致, Jar 文件路径不一致;具体值可以在 dinky-config.yaml 查看。
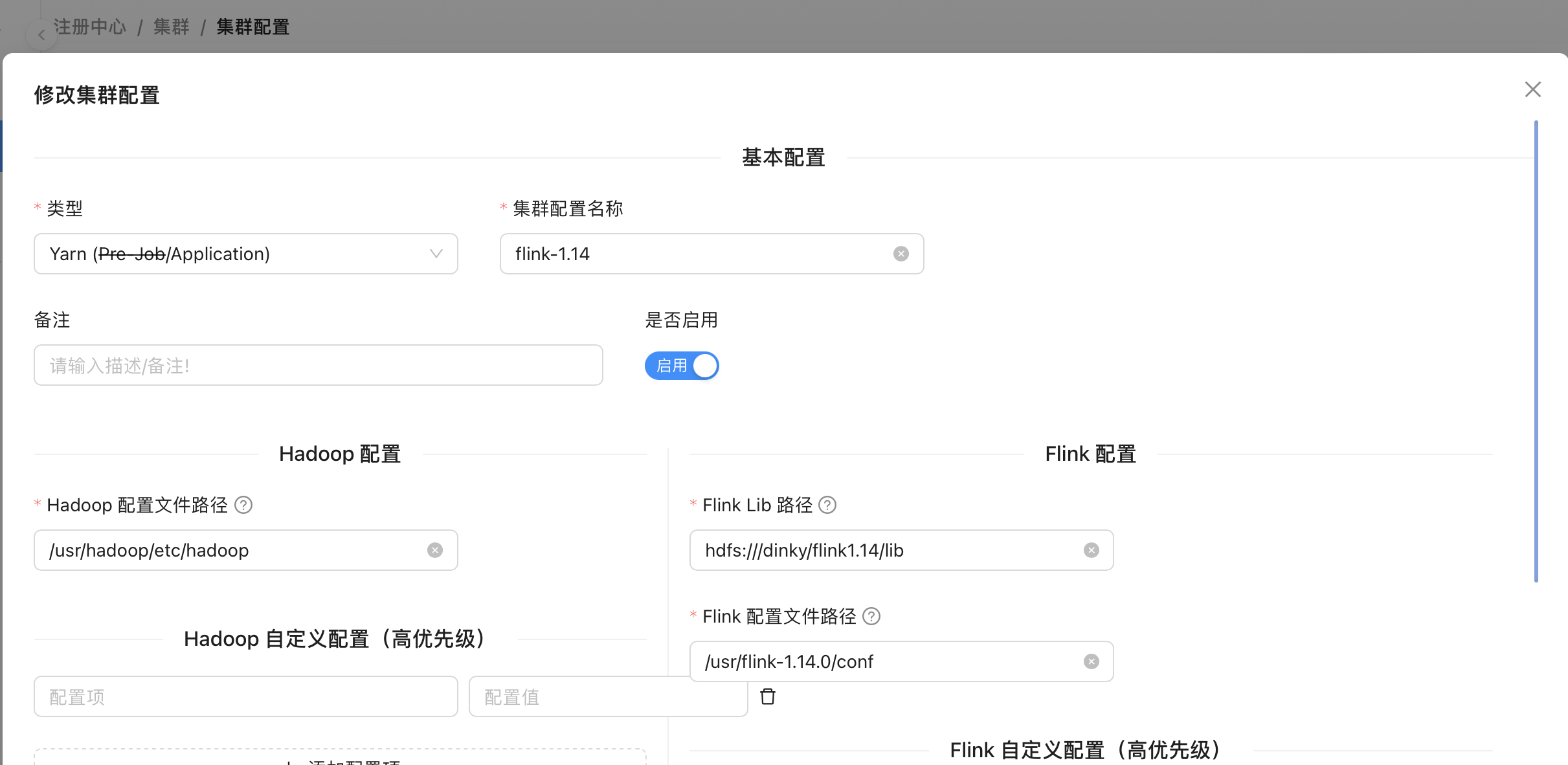
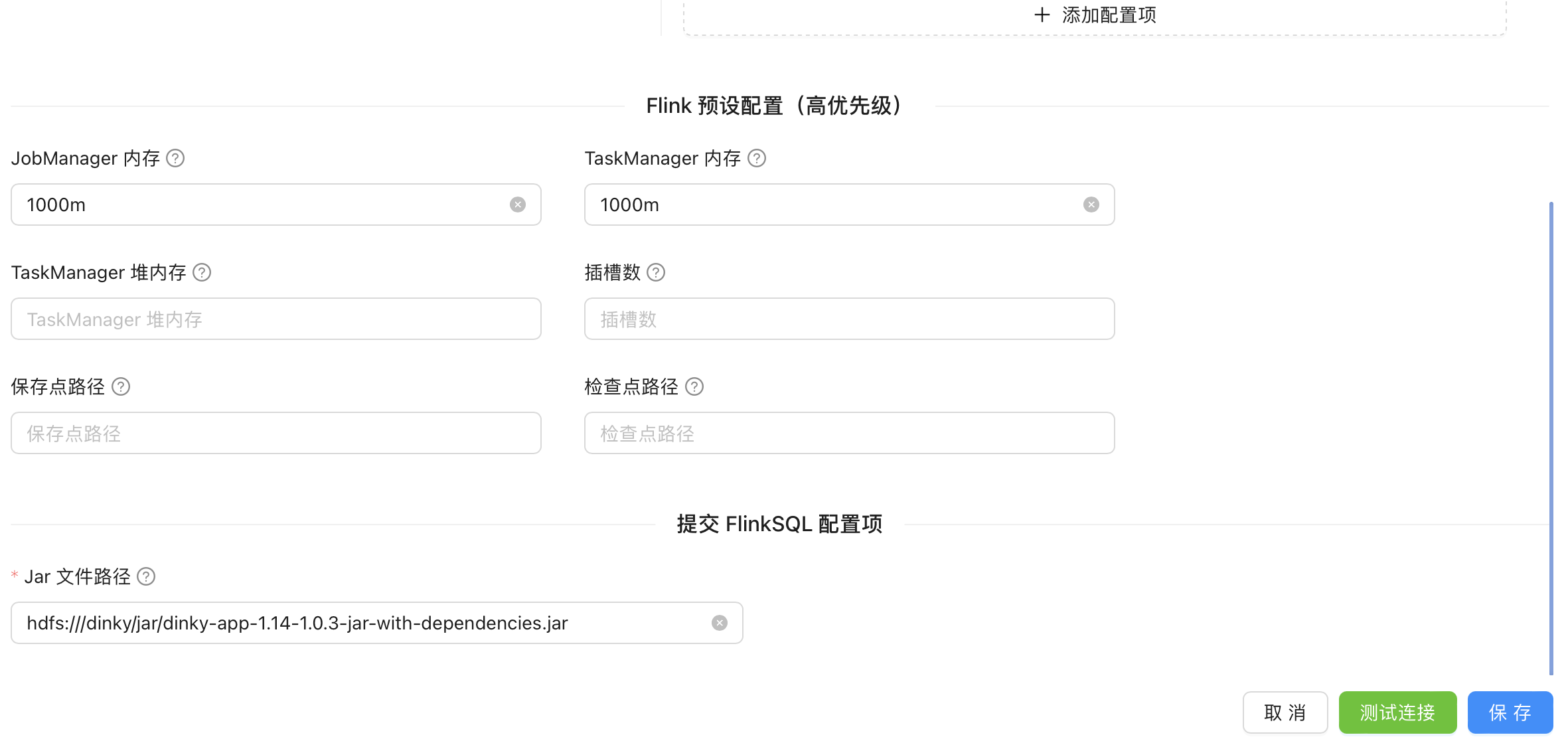
#Hadoop 配置文件路径/usr/hadoop/etc/hadoop#Flink1.14 Lib 路径hdfs:///dinky/flink1.14/lib#Flink1.16 Lib 路径hdfs:///dinky/flink1.16/lib#Flink1.18 Lib 路径hdfs:///dinky/flink1.18/lib#Flink1.14 配置文件路径/usr/flink-1.14.0/conf#Flink1.16 配置文件路径/usr/flink-1.16.1/conf#Flink1.18 配置文件路径/usr/flink-1.18.1/conf#Jar 文件路径 flink 1.14hdfs:///dinky/jar/dinky-app-1.14-1.0.3-jar-with-dependencies.jar#Jar 文件路径 flink 1.16hdfs:///dinky/jar/dinky-app-1.16-1.0.3-jar-with-dependencies.jar#Jar 文件路径 flink 1.18hdfs:///dinky/jar/dinky-app-1.18-1.0.3-jar-with-dependencies.jar
2. 配置中心/全局配置-Flink 配置。
Job 提交等待时间:600秒。

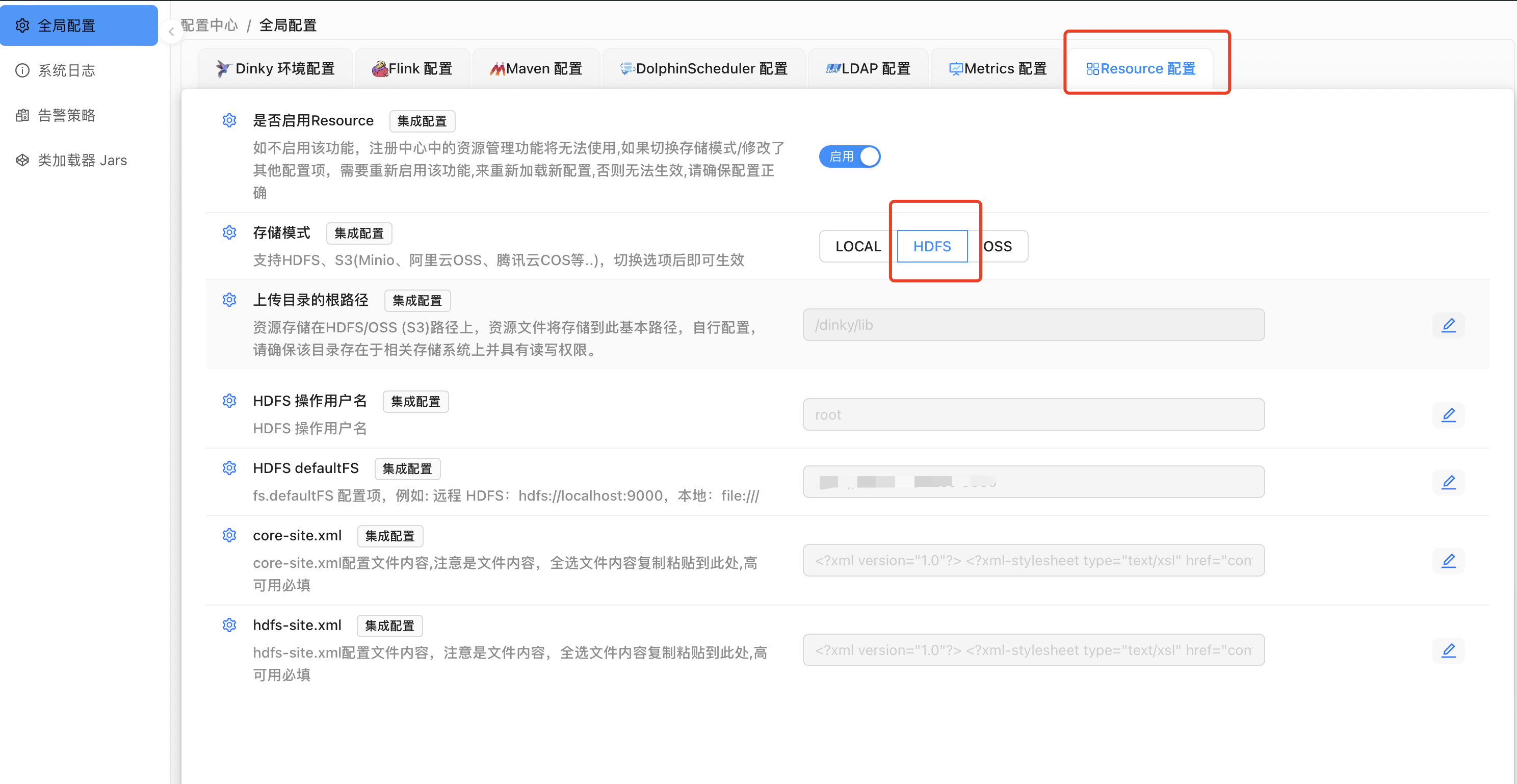
3. 配置中心/全局配置-Resource 配置。
HDFS 操作用户名:root
HDFS defaultFS 用 dinky-config.yaml 文件中的 defaultFS 的值。
core-site.xml 用上述下载的配置文件中的 core-site.xml。
hdfs-site.xml 用上述下载的配置文件中的 hdfs-site.xml。
4. 注册中心/文档,创建 Flink 参数。
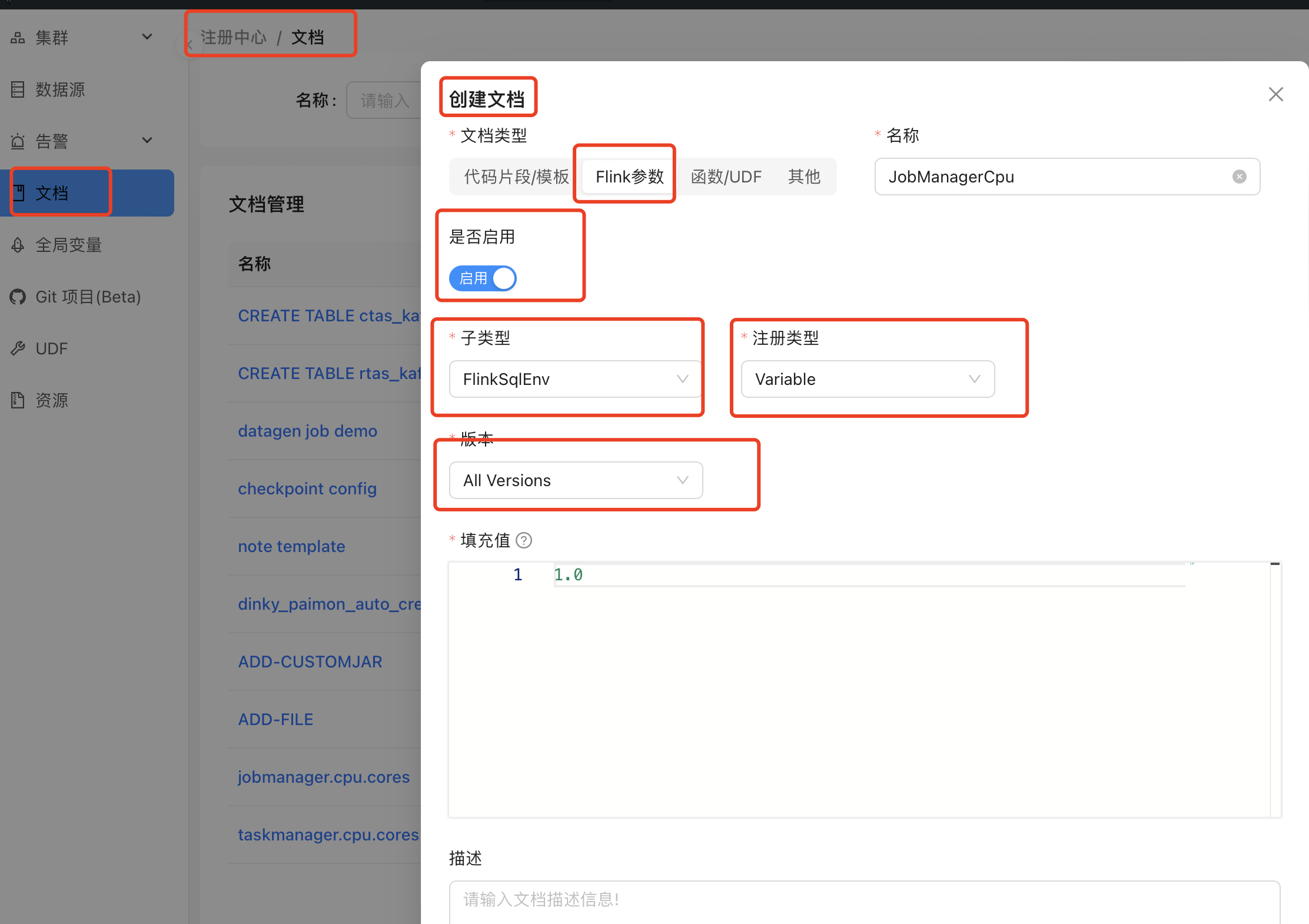
名称 | 文档类型 | 子类型 | 注册类型 | 描述 |
JobManagerCpu | Flink 参数 | FlinkSqlEnv | Variable | #用于 jm cpu 参数 |
JobManagerMem | Flink 参数 | FlinkSqlEnv | Variable | #用于 jm mem 参数 |
TaskManagerCpu | Flink 参数 | FlinkSqlEnv | Variable | #用于 tm cpu 参数 |
TaskManagerMem | Flink 参数 | FlinkSqlEnv | Variable | #用于 tm mem 参数 |
5. 注册中心/资源,上传资源。
6. SQL 作业示例。
其他参数设置:
key | value | comment |
JobManagerCpu | 1.0 | |
JobManagerMem | 4.0 | |
TaskManagerCpu | 1.0 | |
TaskManagerMem | 4.0 | |
yarn.ship-files | /opt/dinky/extends/flink1.16/dinky/flink-connector-mysql-cdc_1.16.jar;/opt/dinky/extends/flink1.16/dinky/flink-connector-logger_1.16.jar | 依赖程序,在dinky 节点本地,mysql-cdc 和 logger connector oceanus 已内置了,可以不用传这两个依赖 |
BuiltInConnector | flink-connector-mysql-cdc,flink-connector-logger | 使用 Oceanus 内置 connector |
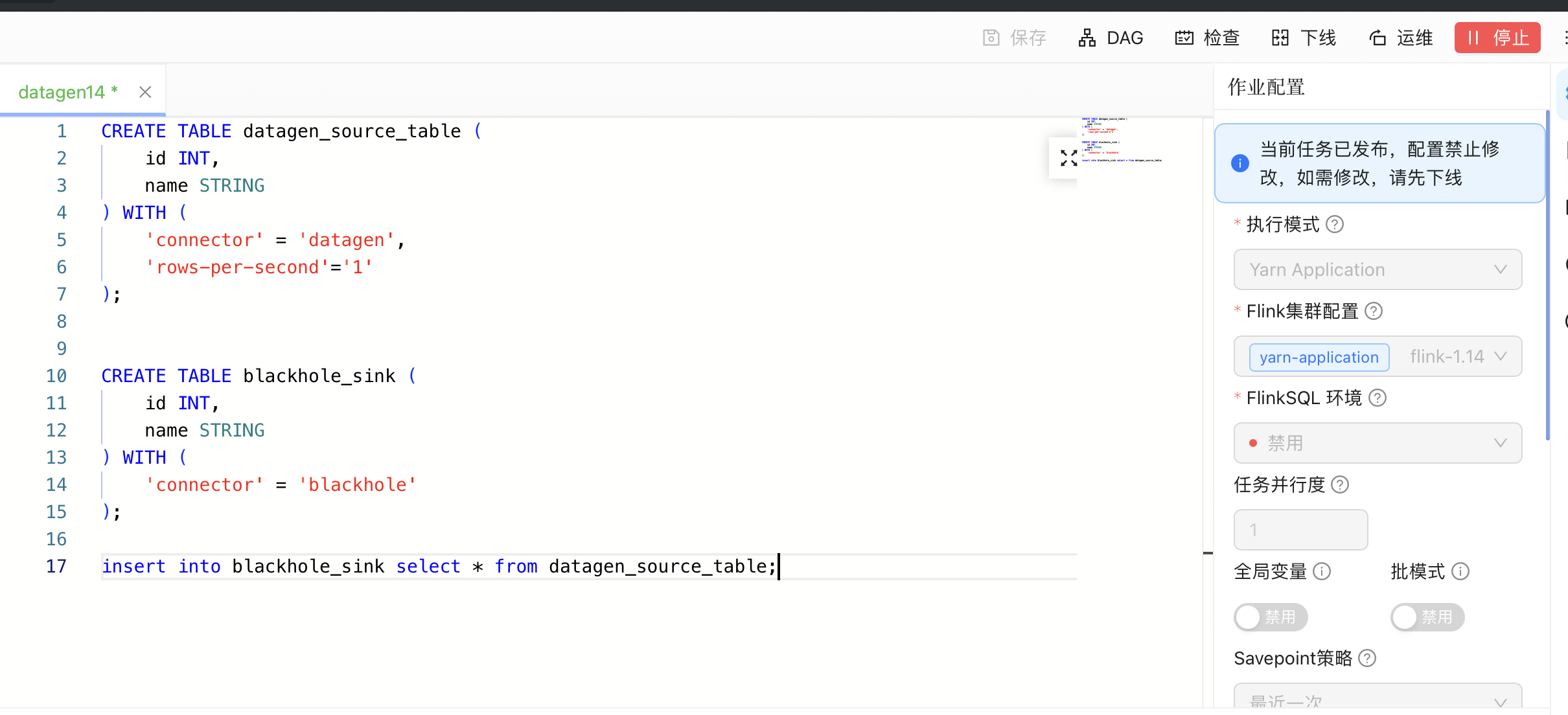
CREATE TABLE datagen_source_table (id INT,name STRING) WITH ('connector' = 'datagen','rows-per-second'='1');CREATE TABLE blackhole_sink (id INT,name STRING) WITH ('connector' = 'blackhole');insert into blackhole_sink select * from datagen_source_table;
7. Jar 作业示例。
flink-hello-world-4.0.0-jar-with-dependencies.jar 主程序包先在注册中心/资源中上传;jar 包不需要写 savepoint dir和 checkpoint dir。
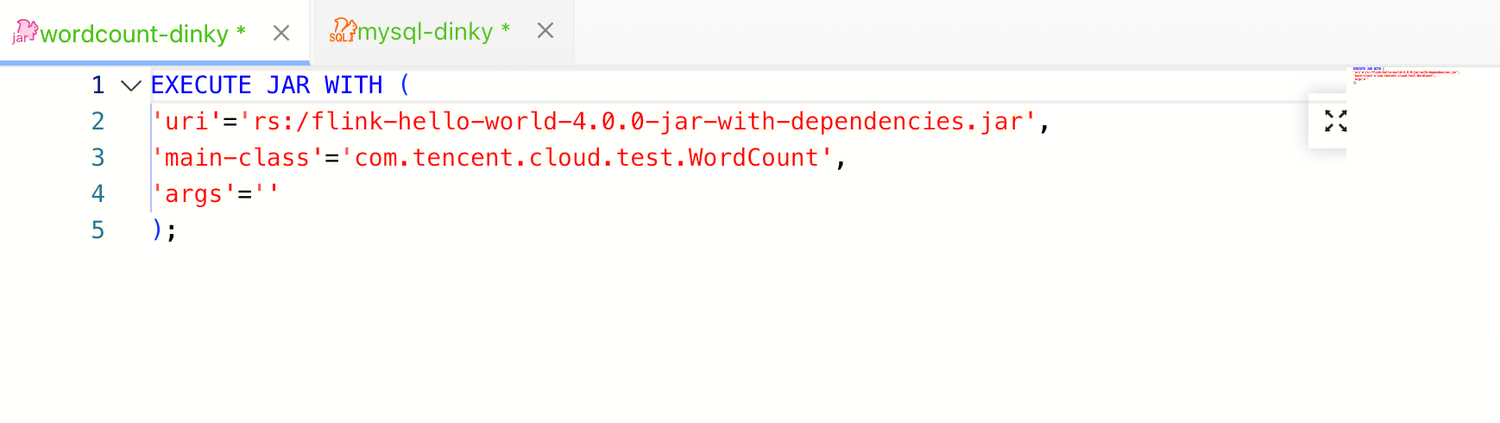
EXECUTE JAR WITH ('uri'='rs:/flink-hello-world-4.0.0-jar-with-dependencies.jar','main-class'='com.tencent.cloud.test.WordCount','args'='');
StreamPark 示例
1. 用 streampark-config.yaml 包含 StreamPark 服务目录 conf/config.yaml streampark 部分的内容,启动 StreamPark 服务。
streampark:workspace:local: /tmp/streamparkremote: hdfs:///streamparkproxy:lark-url:yarn-url: http://******:8088yarn:http-auth: 'simple' # default simple, or kerberoshadoop-user-name: root
2. SQL 作业示例。
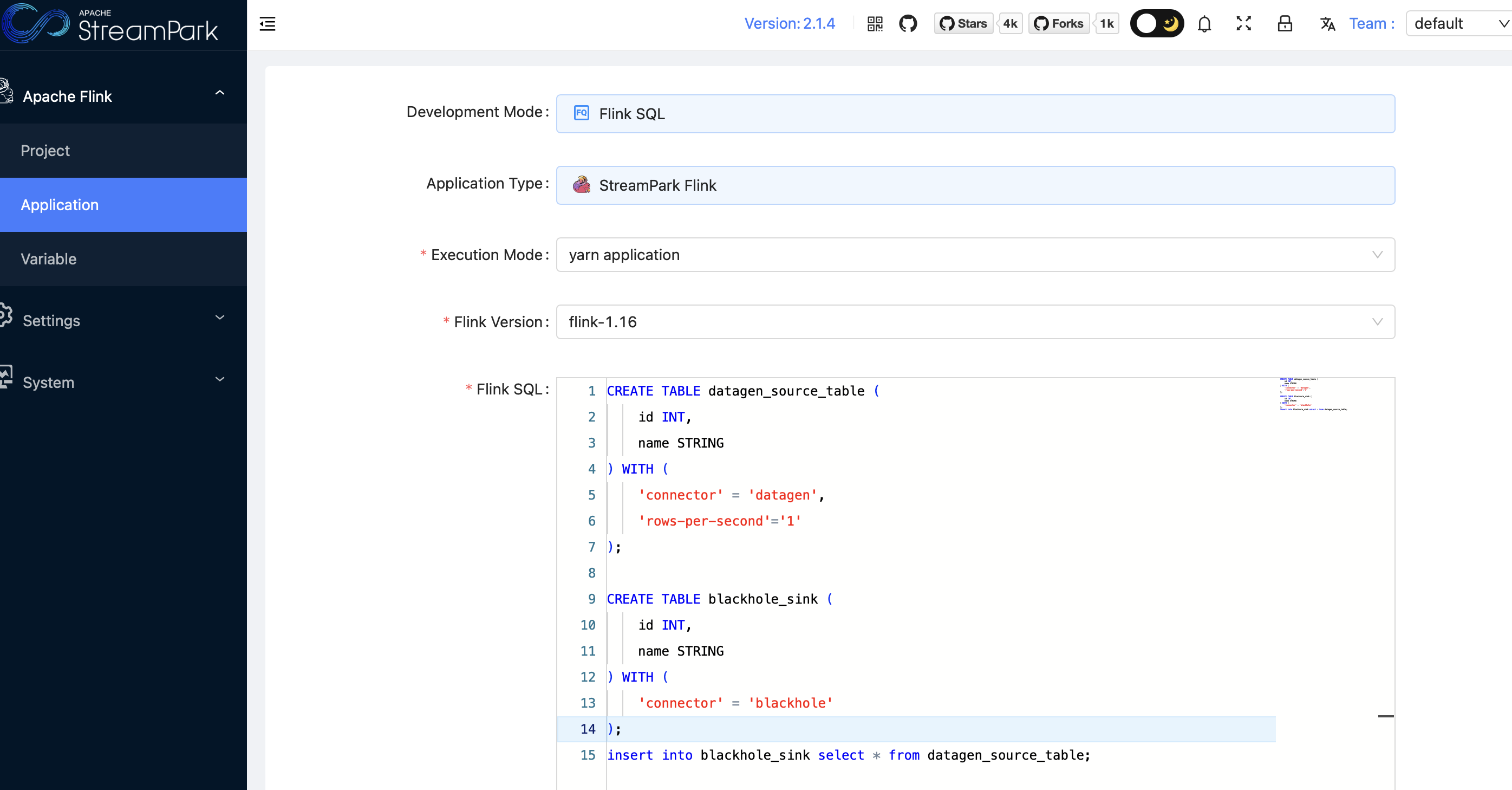
CREATE TABLE datagen_source_table (id INT,name STRING) WITH ('connector' = 'datagen','rows-per-second'='1');CREATE TABLE blackhole_sink (id INT,name STRING) WITH ('connector' = 'blackhole');insert into blackhole_sink select * from datagen_source_table;
3. Jar 作业示例。
jar 包不需要写 savepoint dir 和 checkpoint dir。
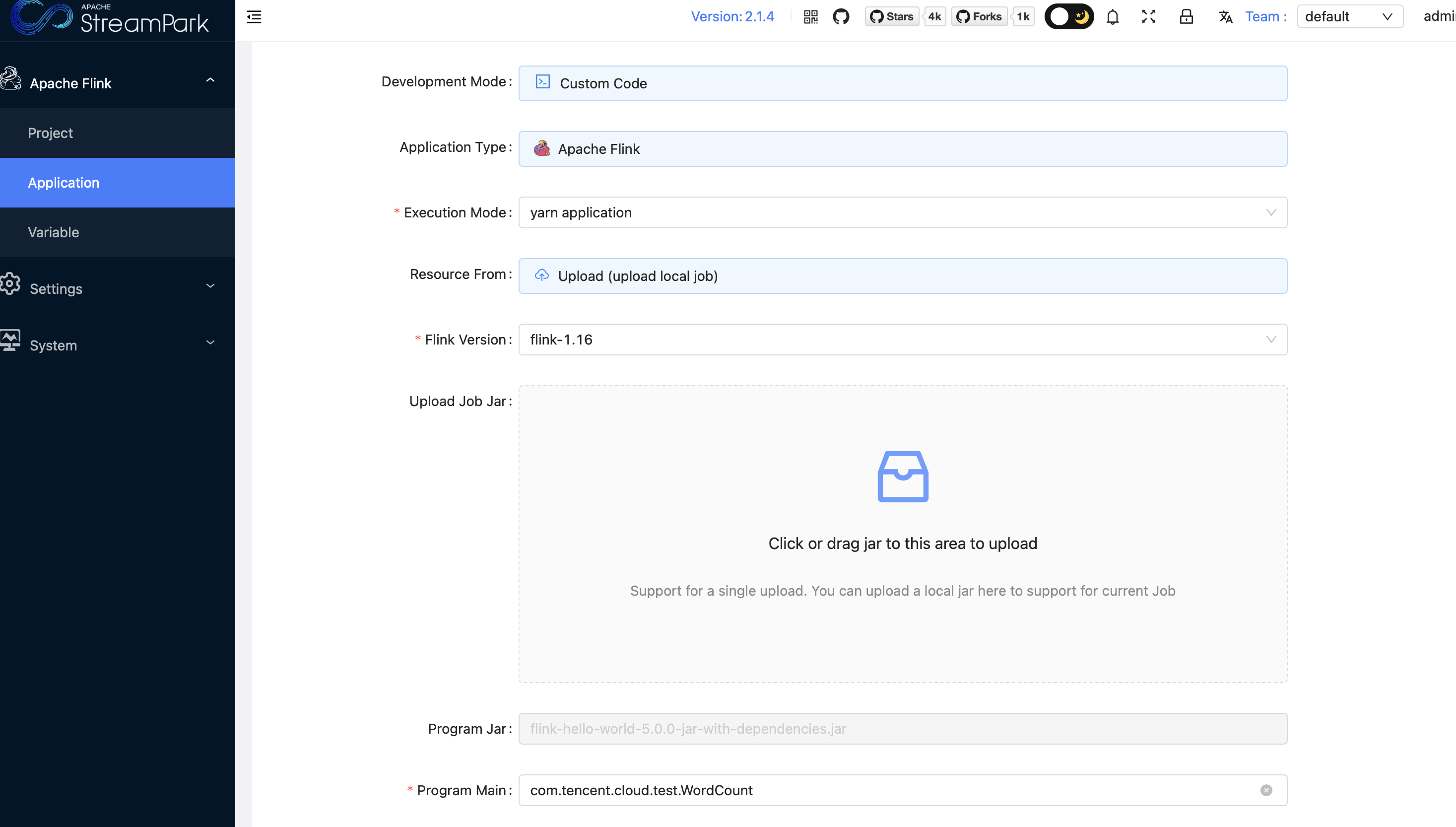
4. 作业参数设置。
在 Dynamic Properties 设置 -DJobManagerCpu=1.0 -DJobManagerMem=4.0 -DTaskManagerCpu=1.0 -DTaskManagerMem=4.0 可参考作业资源配置。
使用内置 connector 例如添加 -DBuiltInConnector=flink-connector-mysql-cdc;如果多个 connector 用“,”连接。



