CREATE TABLE 语句用来描述数据源(Source)或者数据目的(Sink)表,并将其定义为一张表,以供后续语句引用。
表定义语法
语法结构
CREATE TABLE 表名({ <列定义> | <计算列定义> }[ , ...n][ <Watermark 定义> ][ <表约束定义, 例如 Primary Key 等> ][ , ...n])[COMMENT 表的注释][PARTITIONED BY (分区列名1, 分区列名2, ...)]WITH (键1=值1, 键2=值2, ...)[ LIKE 其他的某个表 [( <LIKE 子句选项> )] ]
符号含义
CREATE TABLE 语句创建的表,既可以作为数据源表,也可以作为数据目的表。但是如果没有对应的 Connector,则会在运行时报错。
<列定义>:列名 列类型 [ <列的约束定义> ] [COMMENT 列的注释]<列的约束定义>:[CONSTRAINT 约束名] PRIMARY KEY NOT ENFORCED<表的约束定义>:[CONSTRAINT 约束名] PRIMARY KEY (列名1, 列名2, ...) NOT ENFORCED<计算列定义>:列名 AS 计算列表达式 [COMMENT 列的注释]<Watermark 定义>:WATERMARK FOR 某个Rowtime类型的列名 AS 某个Watermark策略表达式<LIKE 子句选项>:{{ INCLUDING | EXCLUDING } { ALL | CONSTRAINTS | PARTITIONS }| { INCLUDING | EXCLUDING | OVERWRITING } { GENERATED | OPTIONS | WATERMARKS }}[, ...]
子句功能说明
计算列
计算列是一种虚拟列,它是逻辑上的定义而非数据源中实际存在的列,通常由同一个表的其他列、常量、变量、函数等计算而来。例如,如果数据源中定义了 price(商品单价)和 quantity(采购量),那么就可以新定义一个 cost(总成本)字段,即
cost AS price * quantity,即可在后续查询中直接使用 cost 字段。更常见的用法是使用计算列来实现非标准时间戳的标准化。例如在一个数据源中,时间戳字段 mytime 为 Unix 格式(例如以毫秒为单位的1599469771494),则可以通过计算列的方式
ts AS TO_TIMESTAMP(FROM_UNIXTIME(mytime / 1000, 'yyyy-MM-dd HH:mm:ss')),将时间戳处理为 Flink 可识别的 Timestamp(3) 类型。另外,如果数据源时间戳字段虽然是 Timestamp(3) 格式,但是嵌套在 JSON 的其他字段中,也可以用计算列的方式将其解析出来。注意
计算列只允许在 SELECT 语句中使用。
对于 INSERT 语句,目的表中的计算列会被自动忽略。
WATERMARK
Watermark 定义
Watermark 决定着 Flink 作业的时间模式(详见下文的 Event Time/Processing Time 介绍小节),定义方式:
WATERMARK FOR 某个Rowtime类型的列名 AS 某个Watermark策略表达式
例如
WATERMARK FOR my_time_field AS my_time_field - INTERVAL '3' SECOND 表示定义一个容差为 3 秒的 Watermark 策略。某个 Rowtime 类型的列名:必须是 Flink 可识别的
Timestamp(3) 类型,且不是嵌套列。如果类型不对或者属于嵌套字段,则需要使用上文提到的“计算列”功能,创建一个转换后的虚拟列,作为 Rowtime 类型的列。某个 Watermark 策略表达式:用于定义 Watermark 的生成策略,可以用各种表达式来描述一个
Timestamp(3) 类型的值,以作为每次生成 Watermark 时的依据。定义示例如下:
CREATE TABLE StudentRecord (Id BIGINT,StudentName STRING,RegistrationTime TIMESTAMP(3),WATERMARK FOR RegistrationTime AS RegistrationTime - INTERVAL '3' MINUTE) WITH ( ... ... );
Watermark 生成策略
单调递增时间戳的 Watermark 策略
如果时间戳可以确保是单调递增的,不存在乱序的情况,则可以用如下语法,以期得到最低的数据处理延迟。
WATERMARK FOR 某个Rowtime类型的列名 AS 某个Rowtime类型的列名
下面语句的含义是将每个输入数据中最大时间戳作为 Watermark 的取值。因此如果存在乱序,就会造成晚到的数据未达到 Watermark 的界限而被丢弃。例如:
WATERMARK FOR my_time AS my_time
有限容忍乱序的 Watermark 策略
与上述的策略不同,本策略允许数据中存在一定范围的乱序。这个乱序范围由用户自行控制,如果设置的较大,则会带来较长的延迟(数据积压、等待);如果设置的较小,则超过阈值的数据则可能被丢弃(造成结果不准确)。
WATERMARK FOR 某个Rowtime类型的列名 AS 某个Rowtime类型的列名 - INTERVAL '时间长度' 时间单位
下面语句的含义是每个输入数据中最大的时间戳减去3秒的容差作为 Watermark 的取值。因此如果存在乱序,但是后来的数据比之前最大值相差不到3秒,也会被允许加入计算。
WATERMARK FOR my_time AS my_time - INTERVAL '3' SECOND
Event Time/Processing Time 介绍
对于基于窗口的操作(例如 GROUP BY、OVER、JOIN 条件中时间段的指定),流计算 Oceanus 支持 Event Time 和 Processing Time 两种时间处理模式。
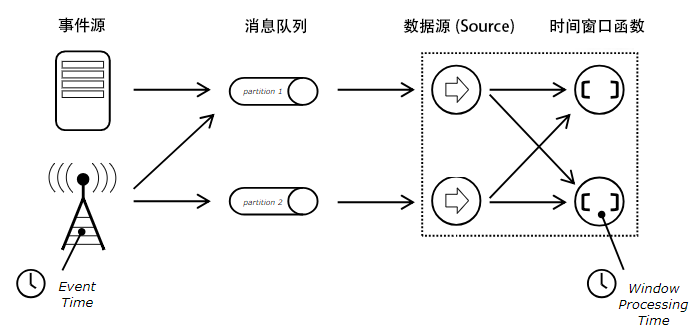
Event Time 模式使用输入数据自带的时间戳,容忍一定程度的乱序数据输入(例如,更早的数据由于各节点处理能力、网络波动等不可预知的原因,来的却更晚),这个参数可以通过 BOUNDED 的第二个参数指定,单位是毫秒。该处理模式最精确,但要求输入数据自带时间戳。目前只支持数据源中以 timestamp 类型定义的字段,未来将会支持虚拟列,可将其他类型的列应用处理函数转换为系统接受的时间戳。
Processing Time 处理模式不要求输入数据有时间戳,而是将该条数据被处理的时间戳自动加入数据,并以 PROCTIME(必须全为大写)字段命名。该列是隐藏的,
SELECT *时不会出现,只有用户手动使用时才会被读取。注意
对于同一个任务的所有数据源,只允许采用一种时间模式。若某个使用 Event Time 模式,则必须要求所有定义的 Table Source 都定义时间戳并声明 WATERMARK 时间戳字段。
主键 PRIMARY KEY
定义表或视图时,可以声明某些字段为主键(PRIMARY KEY),表示这些字段的值不会重复且不会为 NULL(即 SQL 的 NOT NULL + UNIQUE)。
主键的定义可以在列上,也可以单独使用 CONSTRAINT 语句定义。不能对同一个表多次定义不同的主键。Flink 因为无法保证数据源的每条数据主键不重复,目前只支持 PRIMARY KEY NOT ENFORCED 语法,即提醒用户需自行保证主键语义。
分区 PARTITIONED BY
如果在某个列上定义了 PARTITIONED BY 子句,则表明允许 Flink 对该列进行分区。主要影响 FileSystem Sink,它会根据分区的不同,为每个数据分区创建一个单独的目录。
流计算 Oceanus 不建议用户使用 FileSystem Sink,因为所有 TaskManager 运行结束后,文件系统的数据会被自动清理。
WITH 参数
WITH 参数通常用于指定数据源和数据目的的 Connector 所需参数,语法为
'key1'='value1', 'key2' = 'value2'的键值对。例如要写入 Kafka(腾讯云 CKafka 或自建 Kafka)时,需要指定服务器地址、消费的 Topic、消费的起始时间点等信息。
LIKE 子句
LIKE 子句允许用于创建表(下文称为 B 表)时,引用其他表(下文称为 A 表)的结构,这样可以大幅节省 CREATE TABLE 语句的代码量,做到代码复用。例如,把同样的数据一份写入 Kafka Sink,另一份写入 Elasticsearch Sink,还有一部分写入 MySQL,那么就可以通过 LIKE 语句来实现定义三张表,同时复用列定义的效果。
定义一张 A 表:
CREATE TABLE A (Id BIGINT,StudentName STRING,RegistrationTime TIMESTAMP(3)) WITH ( ... 某些参数 ... );
再定义一个含 Watermark 的 B 表,则可以直接基于上面的表,创建一个新的表:
CREATE TABLE B (WATERMARK FOR RegistrationTime AS RegistrationTime - INTERVAL '3' MINUTE) WITH ( ... 另一些参数 ... ) LIKE `A`;
默认情况下 LIKE 语句与 WITH 参数无关,所以两个表允许使用完全不同的 WITH 参数集。如果希望继承原表的 WITH 参数信息,则需要通过 LIKE 子句选项来实现。
LIKE 子句选项
目前 LIKE 子句提供了如下的选项,可以控制引用(继承)某个 A 表的内容:
CONSTRAINTS:主键(PRIMARY KEY)等约束
GENERATED:计算列
OPTIONS:WITH 参数
PARTITIONS:PARTITIONED BY 定义
WATERMARKS:WATERMARK FOR 定义
ALL:以上所有
同时,Flink 提供了三种不同的合并策略:
INCLUDING:继承 A 表的所有指定属性,但如果 A 表和 B 表的某些定义有冲突(例如含有相同字段定义)则报错。
EXCLUDING:B 表中不会包含任何 A 表中已有的指定属性。
OVERWRITING:继承 A 表的所有指定属性,如果 A 表和 B 表定义有冲突,则 B 表的定义会覆盖 A 表的定义。
如果未提供 LIKE 子句选项,默认行为是
INCLUDING ALL OVERWRITING OPTIONS,即 B 表会继承 A 表的所有定义和设置,但是会覆盖掉 WITH 参数。


