介绍
Kafka 数据管道是流计算系统中最常用的数据源(Source)和数据目的(Sink)。用户可以把流数据导入到 Kafka 的某个 Topic 中,通过 Flink 算子进行处理后,输出到相同或不同 Kafka 实例的另一个 Topic。
Kafka 支持同一个 Topic 多分区读写,数据可以从多个分区读入,也可以写入到多个分区,以提供更高的吞吐量,减少数据倾斜和热点。
版本说明
Flink 版本 | 说明 |
1.13 | 支持,基于社区 1.13,Kafka client 版本 2.4.1 |
1.14 | 支持,基于社区 1.14,Kafka client 版本 2.4.1 |
1.16 | 支持,基于社区 1.16,Kafka client 版本 3.2.3 |
1.18 | 支持,基于社区 3.2.0,Kafka client 版本 3.4.0 |
1.20 | 支持,基于社区 3.3.0,Kafka client 版本 3.4.0 |
说明:
自 Flink 1.17 版本起,社区已将 Kafka Connector 拆分为独立仓库进行维护,并采用了全新的版本号命名规则。
使用范围
Kafka 支持用作数据源表(Source),也可以作为 Tuple 数据流的目的表(Sink)。
DDL 定义
用作数据源(Source)
JSON 格式输入
CREATE TABLE `kafka_json_source_table` (`id` INT,`name` STRING) WITH (-- 定义 Kafka 参数'connector' = 'kafka','topic' = 'Data-Input', -- 替换为您要消费的 Topic'scan.startup.mode' = 'latest-offset', -- 可以是 latest-offset / earliest-offset / specific-offsets / group-offsets / timestamp 的任何一种'properties.bootstrap.servers' = '172.28.28.13:9092', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'testGroup', -- 必选参数, 一定要指定 Group ID-- 定义数据格式 (JSON 格式)'format' = 'json','json.fail-on-missing-field' = 'false', -- 如果设置为 false, 则遇到缺失字段不会报错。'json.ignore-parse-errors' = 'true' -- 如果设置为 true,则忽略任何解析报错。);
CSV 格式输入
CREATE TABLE `kafka_csv_source_table` (`id` INT,`name` STRING) WITH (-- 定义 Kafka 参数'connector' = 'kafka','topic' = 'Data-Input', -- 替换为您要消费的 Topic'scan.startup.mode' = 'latest-offset', -- 可以是 latest-offset / earliest-offset / specific-offsets / group-offsets / timestamp 的任何一种'properties.bootstrap.servers' = '172.28.28.13:9092', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'testGroup', -- 必选参数, 一定要指定 Group ID-- 定义数据格式 (CSV 格式)'format' = 'csv');
Debezium 格式输入
CREATE TABLE `kafka_debezium_source_table` (`id` INT,`name` STRING) WITH (-- 定义 Kafka 参数'connector' = 'kafka','topic' = 'Data-Input', -- 替换为您要消费的 Topic'scan.startup.mode' = 'latest-offset', -- 可以是 latest-offset / earliest-offset / specific-offsets / group-offsets / timestamp 的任何一种'properties.bootstrap.servers' = '172.28.28.13:9092', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'testGroup', -- 必选参数, 一定要指定 Group ID-- 定义数据格式 (Debezium 输出的 JSON 格式)'format' = 'debezium-json');
Canal 格式输入
CREATE TABLE `kafka_source`(aid BIGINT COMMENT 'unique id',charname STRING,`ts` TIMESTAMP(6),origin_database STRING METADATA FROM 'value.database' VIRTUAL,origin_table STRING METADATA FROM 'value.table' VIRTUAL,origin_es TIMESTAMP(3) METADATA FROM 'value.event-timestamp' VIRTUAL,origin_type STRING METADATA FROM 'value.operation-type' VIRTUAL,`batch_id` BIGINT METADATA FROM 'value.batch-id' VIRTUAL,`is_ddl` BOOLEAN METADATA FROM 'value.is-ddl' VIRTUAL,origin_old ARRAY<MAP<STRING, STRING>> METADATA FROM 'value.update-before' VIRTUAL,`mysql_type` MAP<STRING, STRING> METADATA FROM 'value.mysql-type' VIRTUAL,origin_pk_names ARRAY<STRING> METADATA FROM 'value.pk-names' VIRTUAL,`sql` STRING METADATA FROM 'value.sql' VIRTUAL,origin_sql_type MAP<STRING, INT> METADATA FROM 'value.sql-type' VIRTUAL,`ingestion_ts` TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL) WITH ('connector' = 'kafka', -- 注意选择对应的内置 Connector'topic' = '$TOPIC', -- 替换为您要消费的 Topic'properties.bootstrap.servers' = '$IP:$PORT', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'testGroup', -- 必选参数, 一定要指定 Group ID'scan.startup.mode' = 'latest-offset','scan.topic-partition-discovery.interval' = '300s','format' = 'canal-json','canal-json.ignore-parse-errors' = 'false', -- 忽略 JSON 结构解析异常'canal-json.source.append-mode' = 'true' -- 仅支持Flink1.13及以上版本);
用作数据目的(Sink)
JSON 格式输出
CREATE TABLE `kafka_json_sink_table` (`id` INT,`name` STRING) WITH (-- 定义 Kafka 参数'connector' = 'kafka','topic' = 'Data-Output', -- 替换为您要写入的 Topic'properties.bootstrap.servers' = '172.28.28.13:9092', -- 替换为您的 Kafka 连接地址-- 定义数据格式 (JSON 格式)'format' = 'json','json.fail-on-missing-field' = 'false', -- 如果设置为 false, 则遇到缺失字段不会报错。'json.ignore-parse-errors' = 'true' -- 如果设置为 true,则忽略任何解析报错。);
CSV 格式输出
CREATE TABLE `kafka_csv_sink_table` (`id` INT,`name` STRING) WITH (-- 定义 Kafka 参数'connector' = 'kafka','topic' = 'Data-Output', -- 替换为您要写入的 Topic'properties.bootstrap.servers' = '172.28.28.13:9092', -- 替换为您的 Kafka 连接地址-- 定义数据格式 (CSV 格式)'format' = 'csv');
Canal 格式输出
CREATE TABLE `kafka_canal_json_sink_table`(aid BIGINT COMMENT 'unique id',charname STRING,`ts` TIMESTAMP(6),origin_database STRING METADATA FROM 'value.database',origin_table STRING METADATA FROM 'value.table',origin_ts TIMESTAMP(3) METADATA FROM 'value.event-timestamp',`type` STRING METADATA FROM 'value.operation-type',`batch_id` BIGINT METADATA FROM 'value.batch-id',`isDdl` BOOLEAN METADATA FROM 'value.is-ddl',`old` ARRAY<MAP<STRING, STRING>> METADATA FROM 'value.update-before',`mysql_type` MAP<STRING, STRING> METADATA FROM 'value.mysql-type',`pk_names` ARRAY<STRING> METADATA FROM 'value.pk-names',`sql` STRING METADATA FROM 'value.sql',`sql_type` MAP<STRING, INT> METADATA FROM 'value.sql-type',`ingestion_ts` TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp') WITH ('connector' = 'kafka', -- 注意选择对应的内置 Connector'topic' = '$TOPIC', -- 替换为您要消费的 Topic'properties.bootstrap.servers' = '$IP:$PORT', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'testGroup', -- 必选参数, 一定要指定 Group ID'format' = 'canal-json');
WITH 参数
参数值 | 必填 | 默认值 | 描述 |
connector | 是 | 无 | 固定值为 'kafka'。 |
topic | 是 | 无 | 要读写的 Kafka Topic 名。 |
properties.bootstrap.servers | 是 | 无 | 逗号分隔的 Kafka Bootstrap 地址。 |
properties.group.id | 作为数据源时必选 | 无 | Kafka 消费时的 Group ID。 |
format | 是 | 无 | Kafka 消息的输入输出格式。目前支持 csv、json、debezium-json、canal-json、avro(注意 avro 格式需上传依赖的 flink-avro jar ,其他格式不需要上传),Flink1.13 支持 maxwell-json。 |
scan.startup.mode | 否 | group-offsets | Kafka consumer 的启动模式。可以是 latest-offset、earliest-offset、specific-offsets、group-offsets、timestamp 的任何一种。'scan.startup.specific-offsets' = 'partition:0,offset:42;partition:1,offset:300',使用 'specific-offsets' 启动模式时需要指定每个 partition 对应的 offsets。'scan.startup.timestamp-millis' = '1631588815000',使用 'timestamp' 启动模式时需要指定启动的时间戳(单位毫秒)。 |
scan.startup.specific-offsets | 否 | 无 | 如果 scan.startup.mode 的值为'specific-offsets',则必须使用本参数指定具体起始读取的偏移量。例如 'partition:0,offset:42;partition:1,offset:300'。 |
scan.startup.timestamp-millis | 否 | 无 | 如果 scan.startup.mode 的值为'timestamp',则必须使用本参数来指定开始读取的时间点(毫秒为单位的 Unix 时间戳)。 |
scan.header-filter | 否 | 无 | 根据 Kafka 消息是否包含指定的消息头,进行消息过滤,仅满足这个 header 条件的数据会被读取,不满足条件的 Kafka 消息数据会被过滤掉。 header 条件的 key 和 value 之间用 :分隔,多个 header 数据之间使用逻辑运算符(|、&)连接,支持取反运算符!。注意:不支持括号。使用举例: 'scan.header-filter' = 'name:user1|location:current&!hasBuy:book'。1.18 版本及以上版本支持。 计算逻辑顺序是从左到右。 |
sink.partitioner | 否 | 无 | Kafka 输出时所用的分区器。目前支持的分区器如下: fixed:一个 Flink 分区对应不多于一个 Kafka 分区。round-robin:一个 Flink 分区依次被分配到不同的 Kafka 分区。自定义分区:也可以通过继承 FlinkKafkaPartitioner 类,实现该逻辑。 |
scan.topic-partition-discovery.interval | 否 | 由 Flink 版本决定 | Kafka 消费者定期发现动态创建的 Kafka topic 和分区的间隔时间, 300s:每300秒进行一次符合配置的 topic 分区发现行为。10m:每10分钟进行一次符合配置的 topic 分区发现行为。配置的默认值取决于 Flink 版本 1.16版本以下:默认不开启动态发现新分区。 1.16版本及以上:默认配置为 300s。 |
说明:
Flink-1.13 版本可通过设置 'scan.partition-assignment.strategy' = 'ROUND_ROBIN' 将分区均匀分配到 Taskmanager。注意,该参数不可与
'scan.partition-assignment.strategy' 参数同时使用,且在 Flink-1.14 及之后版本已经废弃。
JSON 格式 WITH 参数
参数值 | 必填 | 默认值 | 描述 |
json.fail-on-missing-field | 否 | false | 如果为 true,则遇到缺失字段时,会让作业失败。如果为 false(默认值),则只会把缺失字段设置为 null 并继续处理。 |
json.ignore-parse-errors | 否 | false | 如果为 true,则遇到解析异常时,会把这个字段设置为 null 并继续处理。如果为 false,则会让作业失败。 |
json.timestamp-format.standard | 否 | SQL | 指定 JSON 时间戳字段的格式,默认是 SQL(格式是 yyyy-MM-dd HH:mm:ss.s{可选精度})。也可以选择 ISO-8601,格式是 yyyy-MM-ddTHH:mm:ss.s{可选精度}。 |
CSV 格式 WITH 参数
参数值 | 必填 | 默认值 | 描述 |
csv.field-delimiter | 否 | , | 指定 CSV 字段分隔符,默认是半角逗号。 |
csv.line-delimiter | 否 | U&'\\000A' | 指定 CSV 的行分隔符,默认是换行符 \\n,SQL 中必须用 U&'\\000A'表示。如果需要使用回车符\\r,SQL 中必须使用 U&'\\000D'表示。 |
csv.disable-quote-character | 否 | false | 禁止字段包围引号。如果为 true,则 'csv.quote-character' 选项不可用。 |
csv.quote-character | 否 | " | 字段包围引号,引号内部的作为整体看待。默认是 "。 |
csv.ignore-parse-errors | 否 | false | 忽略处理错误。对于无法解析的字段,会输出为 null。 |
csv.allow-comments | 否 | false | 忽略 # 开头的注释行,并输出为空行(请务必将 csv.ignore-parse-errors 设为 true)。 |
csv.array-element-delimiter | 否 | ; | 数组元素的分隔符,默认是 ;。 |
csv.escape-character | 否 | 无 | 指定转义符,默认禁用转义。 |
csv.null-literal | 否 | 无 | 将指定的字符串看作 null 值。 |
Debezium-json 格式 WITH 参数
参数值 | 必填 | 默认值 | 描述 |
debezium-json.schema-include | 否 | false | 设置 Debezium Kafka Connect 时,如果指定了 'value.converter.schemas.enable'参数,那么 Debezium 发来的 JSON 数据里会包含 Schema 信息,该选项需要设置为 true。 |
debezium-json.ignore-parse-errors | 否 | false | 忽略处理错误。对于无法解析的字段,会输出为 null。 |
debezium-json.timestamp-format.standard | 否 | SQL | 指定 JSON 时间戳字段的格式,默认是 SQL(格式是 yyyy-MM-dd HH:mm:ss.s{可选精度})。也可以选择 ISO-8601,格式是 yyyy-MM-ddTHH:mm:ss.s{可选精度}。 |
Canal 格式 WITH 参数
参数值 | 必填 | 默认值 | 描述 |
canal-json.source.append-mode | 否 | false | 设置为 true 时支持 append 流,例如,消费 Kafka canal-json 数据到 Hive,该参数仅支持 Flink-1.13 集群 |
debezium-json.ignore-parse-errors | 否 | false | 忽略处理错误。对于无法解析的字段,会输出为 null。 |
canal-json.* | 否 | - |
元数据列
在源表和结果表中定义元数据列,可获取或写入 Kafka 消息的元数据。
CREATE TABLE `kafka_source_table`(--读取消息的topic作为`topic_name`字段`topic_name` STRING NOT NULL METADATA FROM 'topic' VIRTUAL,--读取消息的offset作为`data_offset`字段`data_offset` BIGINT NOT NULL METADATA FROM 'offset' VIRTUAL,--读取消息的时间戳作为`ts`字段`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,...) WITH ('connector' = 'kafka',...);CREATE TABLE `kafka_sink_table`(--`ts`字段的时间戳作为ProducerRecord时间戳写入Kafka`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp',...) WITH ('connector' = 'kafka',...);
以下列出了源表和结果表默认支持的元数据:
列 | 数据类型 | 描述 | 表类型 |
topic | STRING NOT NULL | Kafka 消息的 Topic 名称 | 源表 |
partition | INT NOT NULL METADATA VIRTUAL | Kafka 消息的 Partition ID | 源表 |
leader-epoch | INT NOT NULL METADATA VIRTUAL | Kafka 消息的 Leader epoch | 源表 |
offset | BIGINT NOT NULL METADATA VIRTUAL | Kafka 消息的偏移量(offset) | 源表 |
timestamp-type | STRING NOT NULL METADATA VIRTUAL | Kafka 消息的时间戳类型: CreateTime:消息产生的时间 NoTimestampType:消息中没有定义时间戳 LogAppendTime:消息被添加到 Kafka Broker 的时间。 | 源表 |
headers | MAP<STRING, BYTES> NOT NULL METADATA VIRTUAL | Kafka 消息的消息头(header) | 源表和结果表 |
timestamp | TIMESTAMP(3) WITH LOCAL TIME ZONE NOT NULL METADATA VIRTUAL | Kafka 消息的时间戳 | 源表和结果表 |
Canal 格式支持的元数据(仅支持 Flink1.13 版本集群)
以下元数据只能作为表定义中的只读(VIRTUAL)列,若元数据列与物理列冲突,元数据列可以使用
meta.列名:列 | 数据类型 | 描述 |
database | STRING NOT NULL | 包含该 Row 的数据库名称 |
table | STRING NOT NULL | 包含该 Row 的表名称 |
event-timestamp | TIMESTAMP_LTZ(3) NOT NULL | Row 在数据库中进行更改的时间 |
batch-id | BIGINT | binlog 的批 ID |
is-ddl | BOOLEAN | 是否 DDL 语句 |
mysql-type | MAP | 数据表结构 |
update-before | ARRAY | 未修改前字段的值 |
pk-names | ARRAY | 主键字段名 |
sql | STRING | 暂时为空 |
sql-type | MAP | sql_type 表的字段到 Java 数据类型 ID 的映射 |
ingestion-timestamp | TIMESTAMP_LTZ(3) NOT NULL | 收到该 ROW 并处理的当前时间 |
operation-type | STRING | 数据库操作类型,例如 INSERT/DELETE 等 |
代码示例
JSON 格式使用示例
CREATE TABLE `kafka_json_source_table` (`id` INT,`name` STRING) WITH (-- 定义 Kafka 参数'connector' = 'kafka','topic' = 'Data-Input', -- 替换为您要消费的 Topic'scan.startup.mode' = 'latest-offset', -- 可以是 latest-offset / earliest-offset / specific-offsets / group-offsets / timestamp 的任何一种'properties.bootstrap.servers' = '172.28.28.13:9092', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'testGroup', -- 必选参数, 一定要指定 Group ID-- 定义数据格式 (JSON 格式)'format' = 'json','json.fail-on-missing-field' = 'false', -- 如果设置为 false, 则遇到缺失字段不会报错。'json.ignore-parse-errors' = 'true' -- 如果设置为 true,则忽略任何解析报错。);CREATE TABLE `kafka_json_sink_table` (`id` INT,`name` STRING) WITH (-- 定义 Kafka 参数'connector' = 'kafka','topic' = 'Data-Output', -- 替换为您要写入的 Topic'properties.bootstrap.servers' = '172.28.28.13:9092', -- 替换为您的 Kafka 连接地址-- 定义数据格式 (JSON 格式)'format' = 'json','json.fail-on-missing-field' = 'false', -- 如果设置为 false, 则遇到缺失字段不会报错。'json.ignore-parse-errors' = 'true' -- 如果设置为 true,则忽略任何解析报错。);insert into kafka_json_sink_table select * from kafka_json_source_table;
复杂嵌套 JSON 格式使用示例
JSON 示例
{"id": 1234567890,"name": "tom","date": "2000-10-25","obj": {"time1": "11:11:11","str": "test","lg": 1122334455},"arr": ["aa","bb","cc","dd"],"rowinarr": [{"f1": "f11","f2": 111},{"f1": "f12","f2": 222}],"time": "19:19:19","timestamp": "1999-01-12 14:14:14","map": {"flink": 123},"mapinmap": {"inner_map": {"key": 234}}}
Flink SQL
create table kafka_source(id BIGINT,name STRING,`date` DATE,obj ROW<time1 TIME,str STRING,lg BIGINT>,arr ARRAY<STRING>,rowinarr ARRAY<ROW<f1 STRING,f2 INT>>,`time` TIME,`timestamp` TIMESTAMP(3),`map` MAP<STRING,BIGINT>,mapinmap MAP<STRING,MAP<STRING,INT>>) with ('connector' = 'kafka','topic' = 'test-topic','scan.startup.mode' = 'latest-offset','properties.bootstrap.servers' = '172.28.28.13:9092','properties.group.id' = 'testGroup','format' = 'json');create table logger_sink (id BIGINT,name STRING,`date` DATE,str STRING,arr ARRAY<STRING>,nameinarray STRING,rowinarr ARRAY<ROW<f1 STRING,f2 INT>>,f2 INT,`time` TIME,`timestamp` TIMESTAMP(3),`map` MAP<STRING,BIGINT>,flink BIGINT,mapinmap MAP<STRING,MAP<STRING,INT>>,`key` INT) with ('connector' = 'logger');insert intologger_sinkselectid,name,`date`,obj.str,arr,arr[4],rowinarr,rowinarr[1].f2,`time`,`timestamp`,`map`,`map`['flink'],mapinmap,mapinmap['inner_map']['key']from kafka_source;
输出结果
+I(1234567890,tom,2000-10-25,test,[aa, bb, cc, dd],dd,[f11,111, f12,222],111,13:13:13,1999-01-12T14:14:14,{flink=123},123,{inner_map={key=234}},234)
注意:
1. 各数据类型获取元素的方法:
map:map['key']
array:array[index]
row:row.key
2. array 的起始下标从 1 开始。
JSON 数据类型映射
Flink SQL type | JSON type |
CHAR / VARCHAR / STRING | STRING |
BOOLEAN | BOOLEAN |
BINARY / VARBINARY | string with encoding: base64 |
DECIMAL | number |
TINYINT | number |
SMALLINT | number |
INT | number |
BIGINT | number |
FLOAT | number |
DOUBLE | number |
DATE | string with format: date |
TIME | string with format: time |
TIMESTAMP | string with format: date-time |
TIMESTAMP_WITH_LOCAL_TIME_ZONE | string with format: date-time (with UTC time zone) |
INTERVAL | number |
ARRAY | array |
MAP / MULTISET | object |
ROW | object |
Canal 使用示例
CREATE TABLE `source`(`aid` BIGINT,`charname` STRING,`ts` TIMESTAMP(6),`database_name` STRING METADATA FROM 'value.database_name',`table_name` STRING METADATA FROM 'value.table_name',`op_ts` TIMESTAMP(3) METADATA FROM 'value.op_ts',`op_type` STRING METADATA FROM 'value.op_type',`batch_id` BIGINT METADATA FROM 'value.batch_id',`is_ddl` BOOLEAN METADATA FROM 'value.is_ddl',`update_before` ARRAY<MAP<STRING, STRING>> METADATA FROM 'value.update_before',`mysql_type` MAP<STRING, STRING> METADATA FROM 'value.mysql_type',`pk_names` ARRAY<STRING> METADATA FROM 'value.pk_names',`sql` STRING METADATA FROM 'value.sql',`sql_type` MAP<STRING, INT> METADATA FROM 'value.sql_type',`ingestion_ts` TIMESTAMP(3) METADATA FROM 'value.ts',PRIMARY KEY (`aid`) NOT ENFORCED) WITH ('connector' = 'mysql-cdc' ,'append-mode' = 'true','hostname' = '$IP','port' = '$PORT','username' = '$USERNAME','password' = '$PASSWORD','database-name' = 't_wr','table-name' = 't1','server-time-zone' = 'Asia/Shanghai','server-id' = '5500-5510');CREATE TABLE `kafka_canal_json_sink`(aid BIGINT COMMENT 'unique id',charname STRING,`ts` TIMESTAMP(6),origin_database STRING METADATA FROM 'value.database',origin_table STRING METADATA FROM 'value.table',origin_ts TIMESTAMP(3) METADATA FROM 'value.event-timestamp',`type` STRING METADATA FROM 'value.operation-type',`batch_id` BIGINT METADATA FROM 'value.batch-id',`isDdl` BOOLEAN METADATA FROM 'value.is-ddl',`old` ARRAY<MAP<STRING, STRING>> METADATA FROM 'value.update-before',`mysql_type` MAP<STRING, STRING> METADATA FROM 'value.mysql-type',`pk_names` ARRAY<STRING> METADATA FROM 'value.pk-names',`sql` STRING METADATA FROM 'value.sql',`sql_type` MAP<STRING, INT> METADATA FROM 'value.sql-type',`ingestion_ts` TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp')WITH ('connector' = 'kafka','topic' = 'TOPIC', -- 替换为您要消费的 Topic'properties.bootstrap.servers' = '$IP:$PORT', -- 替换为您的 Kafka 连接地址'format' = 'canal-json');insert into kafka_canal_json_sink select * from source;
CREATE TABLE `source`(`aid` BIGINT,`charname` STRING,`ts` TIMESTAMP(3),origin_database STRING METADATA FROM 'value.database' VIRTUAL,origin_table STRING METADATA FROM 'value.table' VIRTUAL,origin_es TIMESTAMP(3) METADATA FROM 'value.event-timestamp' VIRTUAL,origin_type STRING METADATA FROM 'value.operation-type' VIRTUAL,`batch_id` BIGINT METADATA FROM 'value.batch-id' VIRTUAL,`is_ddl` BOOLEAN METADATA FROM 'value.is-ddl' VIRTUAL,origin_old ARRAY<MAP<STRING, STRING>> METADATA FROM 'value.update-before' VIRTUAL,`mysql_type` MAP<STRING, STRING> METADATA FROM 'value.mysql-type' VIRTUAL,origin_pk_names ARRAY<STRING> METADATA FROM 'value.pk-names' VIRTUAL,`sql` STRING METADATA FROM 'value.sql' VIRTUAL,origin_sql_type MAP<STRING, INT> METADATA FROM 'value.sql-type' VIRTUAL,`ingestion_ts` TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL,WATERMARK FOR `origin_es` AS `origin_es` - INTERVAL '5' SECOND) WITH ('connector' = 'kafka', -- 注意选择对应的内置 Connector'topic' = '$TOPIC', -- 替换为您要消费的 Topic'properties.bootstrap.servers' = '$IP:PORT', -- 替换为您的 Kafka 连接地址'properties.group.id' = 'testGroup', -- 必选参数, 一定要指定 Group ID'scan.startup.mode' = 'latest-offset','scan.topic-partition-discovery.interval' = '300s','format' = 'canal-json','canal-json.source.append-mode' = 'true', -- 仅支持Flink1.13'canal-json.ignore-parse-errors' = 'false');CREATE TABLE `kafka_canal_json` (`aid` BIGINT,`charname` STRING,`ts` TIMESTAMP(9),origin_database STRING,origin_table STRING,origin_es TIMESTAMP(9),origin_type STRING,`batch_id` BIGINT,`is_ddl` BOOLEAN,origin_old ARRAY<MAP<STRING, STRING>>,`mysql_type` MAP<STRING, STRING>,origin_pk_names ARRAY<STRING>,`sql` STRING,origin_sql_type MAP<STRING, INT>,`ingestion_ts` TIMESTAMP(9),dt STRING,hr STRING) PARTITIONED BY (dt, hr)with ('connector' = 'hive','hive-version' = '3.1.1','hive-database' = 'testdb','partition.time-extractor.timestamp-pattern'='$dt $hr:00:00','sink.partition-commit.trigger'='partition-time','sink.partition-commit.delay'='30 min','sink.partition-commit.policy.kind'='metastore,success-file');insert into kafka_canal_json select *,DATE_FORMAT(`origin_es`,'yyyy-MM-dd'),DATE_FORMAT(`origin_es`,'HH')from `source`;
SASL 认证授权
SASL/PLAIN 用户名密码认证授权
1. 参考 消息队列 CKafka > 配置 ACL 策略,设置 Topic 按用户名密码访问的 SASL_PLAINTEXT 认证方式。
2. 参考 消息队列 CKafka > 添加路由策略,选择 SASL_PLAINTEXT 接入方式,并以该接入方式下的网络地址访问 Topic。
3. 作业配置 with 参数。
CREATE TABLE `YourTable` (...) WITH (...'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.plain.PlainLoginModule required username="ckafka-xxxxxxxx#YourUserName" password="YourPassword";','properties.security.protocol' = 'SASL_PLAINTEXT','properties.sasl.mechanism' = 'PLAIN',...);
说明
1.
username 是实例 ID + # + 刚配置的用户名,password 是刚配置的用户密码 。2. Flink 版本 SASL 认证配置 对应包:
1.16版本以下:org.apache.kafka.common.security.plain.PlainLoginModule
1.16版本及以上:'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule'
SASL/GSSAPI Kerberos 认证授权
腾讯云 CKafka 暂时不支持 Kerberos 认证,您的自建 Kafka 如果开启了 Kerberos 认证,可参考如下步骤配置作业。
1. 获取您的自建 Kafka 集群的 Kerberos 配置文件,如果您基于腾讯云 EMR 集群自建,获取 krb5.conf、emr.keytab 文件,路径如下。
/etc/krb5.conf/var/krb5kdc/emr.keytab
2. 对步骤1中获取的文件打 jar 包。
jar cvf kafka-xxx.jar krb5.conf emr.keytab
3. 校验 jar 的结构(可以通过 vim 命令查看 vim kafka-xxx.jar),jar 里面包含如下信息,请确保文件不缺失且结构正确。
META-INF/META-INF/MANIFEST.MFemr.keytabkrb5.conf
4. 在 程序包管理 页面上传 jar 包,并在作业参数配置里引用该程序包。
5. 获取 Kerberos principal,用于作业 高级参数 配置。
klist -kt /var/krb5kdc/emr.keytab# 输出如下所示,选取第一个即可:hadoop/172.28.28.51@EMR-OQPO48B9KVNO Timestamp Principal---- ------------------- ------------------------------------------------------2 08/09/2021 15:34:40 hadoop/172.28.28.51@EMR-OQPO48B92 08/09/2021 15:34:40 HTTP/172.28.28.51@EMR-OQPO48B92 08/09/2021 15:34:40 hadoop/VM-28-51-centos@EMR-OQPO48B92 08/09/2021 15:34:40 HTTP/VM-28-51-centos@EMR-OQPO48B9
6. 作业 with 参数配置。
CREATE TABLE `YourTable` (...) WITH (...'properties.security.protocol' = 'SASL_PLAINTEXT','properties.sasl.mechanism' = 'GSSAPI','properties.sasl.kerberos.service.name' = 'hadoop',...);
7. 作业 高级参数 配置。
security.kerberos.login.principal: hadoop/172.28.2.13@EMR-4K3VR5FDsecurity.kerberos.login.keytab: emr.keytabsecurity.kerberos.login.conf: krb5.confsecurity.kerberos.login.contexts: KafkaClientfs.hdfs.hadoop.security.authentication: kerberos
注意:
动态指定 Source 消费模式
当使用 Kafka Connector 作为 Source 时,我们可以在启动时自定义消费模式,目前支持的消费模式有: latest-offset/earliest-offset/group-offsets/timestamp 四种启动模式。 具体用法如下:
1. 在 SQL 代码中对应 With 参数部分加入如下代码定义:
'scan.startup.mode' = '#{CUSTOM_SCAN_MODE}','scan.startup.timestamp-millis' = '#{CUSTOM_TIMESTAMP}',
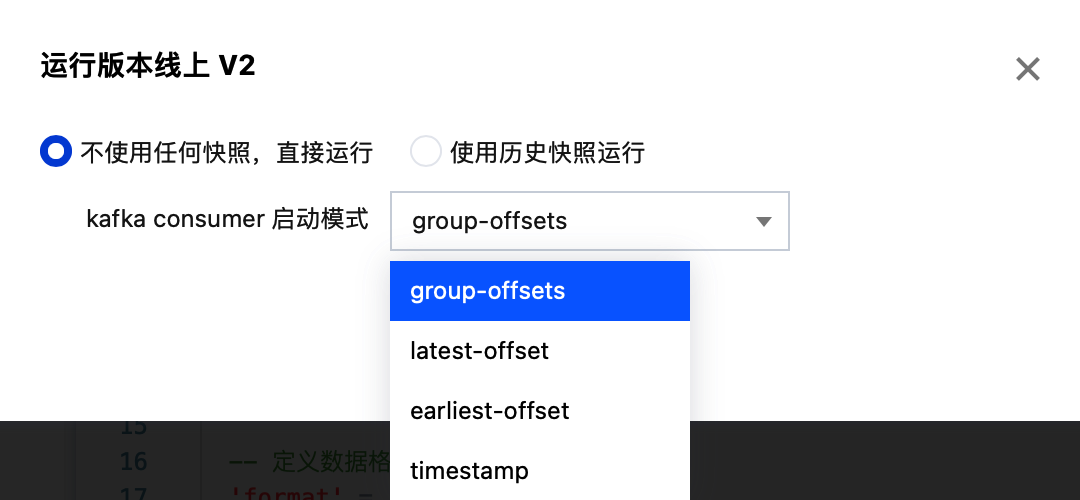
2. 加入之后, 在启动作业时会有选择框选择启动模式,选择“不使用任何快照,直接运行”,在“kafka consumer 启动模式”中可以选择所需启动模式。再进行启动即可实现指定模式启动。
常见问题
Kafka source,Json 格式读取,反序列化报错
在使用 Kafka Source 并配置
'format' = 'json' 时,若消费到 Kafka 格式不规范的脏数据,极易引发 JsonParseException 或 NumberFormatException 等反序列化异常(一般报错会包含 "Failed to deserialize JSON"),进而导致作业报错中断。针对这一场景,可通过在 Kafka Source 的 WITH 参数中配置
'json.ignore-parse-errors' = 'true' 来忽略 JSON 解析错误。注意,该配置的作用范围不仅限于 Source 算子本身,也影响与其处于同一算子链(Operator Chaining)的下游算子(例如紧连的 Calc 算子)。这意味着,如果下游算子在数据处理过程中发生其他类型的报错,也会被一并静默忽略。如果需要观察到非 Source 的报错,可以在高级参数中加
pipeline.operator-chaining: false,把算子链打开,重启作业观察报错。重启作业后拓扑图会变化,需从 group-offsets 或者无状态重启。Kafka source,Json 格式读取,没有数据流出
在使用 Kafka Source 并配置
'format' = 'json' 时,若发现作业已正常消费 Kafka 数据,但下游却无任何输出,这通常是由于消费到的数据均为脏数据,且 WITH 参数中配置了 'json.ignore-parse-errors' = 'true',导致所有格式不合规的数据在解析失败后被静默丢弃。针对此类问题,建议采取以下排查与验证策略:
1. 定位报错信息:可暂时移除 'json.ignore-parse-errors' = 'true' 参数并重启作业,通过观察系统抛出的具体反序列化异常,来进一步分析数据的格式问题。
2. 验证数据格式:若下游算子不便直接查询数据,可通过以下两种方式进行数据校验:
登录 Kafka 控制台,直接查看对应 Topic 中的实际消息内容;
将 Kafka Source 读取到的数据直接输出至 Logger,通过日志直观检查其是否符合规范的 JSON 格式,代码如下:
create table kafka_source(id BIGINT,name STRING) with ('connector' = 'kafka','topic' = 'test-topic','scan.startup.mode' = 'latest-offset','properties.bootstrap.servers' = '172.28.28.13:9092','properties.group.id' = 'testGroup','format' = 'json');create table logger_sink (id BIGINT,name STRING) with ('connector' = 'logger','print-identifier' = 'DebugData');insert intologger_sinkselectid,namefrom kafka_source;
如何配置 Kafka 原生参数
通过 SQL 里面的 with 参数,支持配置 Kafka 原生参数,可配置 Kafka Consumer 参数(Source 可能用到),Kafka Producer 参数(SInk 可能用到),Kafka 连接参数(Source,Sink 都可能用到)等。
注意,所有 Kafka 原生参数必须添加
properties. 前缀,否则配置将无法生效。例如:bootstrap.servers 需写为 properties.bootstrap.servers,具体见上面示例。sasl.mechanism 需写为 properties.sasl.mechanism,具体见上面示例。