概述
TensorRT-LLM 是一款由 NVIDIA 推出的大语言模型(LLMs)推理加速框架,为用户提供了一个易于使用的 Python API,并使用最新的优化技术将大型语言模型构建为 TensorRT 引擎文件,以便在 NVIDIA GPU 上高效地进行推理。
TensorRT-LLM 也提供了支持被 NVIDIA Triton Inference Server 集成的后端,用于将模型部署成在线推理服务,并且支持 In-Flight Batching 技术,可以显著提升推理服务的吞吐率并降低时延。
本文以 Baichuan2-13B-Chat 模型为例,展示如何将一个 LLM 使用 TensorRT-LLM 做推理加速并部署。
操作步骤
创建模型转换开发机
MY_IMAGE="<你的仓库地址>"docker pull tione-public-hub.tencentcloudcr.com/qcloud-ti-platform/tritonserver:23.10-py3-trtllm-0.7.1docker tag tione-public-hub.tencentcloudcr.com/qcloud-ti-platform/tritonserver:23.10-py3-trtllm-0.7.1 ${MY_IMAGE}docker push ${MY_IMAGE}
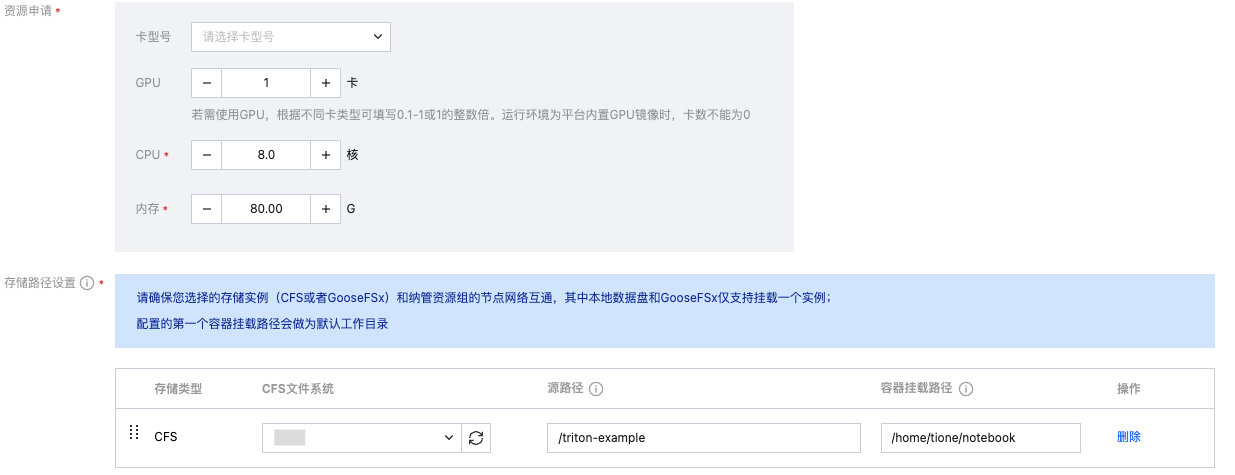
使用上面的自定义镜像来打开一个开发机实例,挂载已申请的 CFS 或 GooseFS 存储,如下图所示。这里开发机实例需要使用 1 卡推理用的 GPU 用于构建 TensorRT 引擎文件。
构建 TensorRT-LLM 模型
进入开发机后,镜像在 /workspace/TensorRT-LLM-examples 目录里已内置好了模型转换的示例代码,可以按示例进行操作:
1. 下载 Baichuan2-13B-Chat 模型
您可以自行下载模型保存到 CFS 的路径中,这里提供一个参考方式:
apt update && apt install git-lfsgit lfs installGIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/baichuan-inc/Baichuan2-13B-Chat.gitcd Baichuan2-13B-Chatgit lfs pull
2. 按注释指引修改 build_triton_repo_baichuan2_13b.sh 文件的内容,然后执行该脚本:
#!/bin/bashset -ex# 指定模型并行数TP=1# 【请修改】指定原始 huggingface 模型本地目录HF_MODEL=/home/tione/notebook/triton-example/hf_model/Baichuan2-13B-Chat# 【请修改】指定 Triton 模型包输出目录(推荐cfs中新建一个目录)TRITON_REPO=/home/tione/notebook/triton-example/triton_model/Baichuan2-13B-Chat/trt-${TP}-gpu# 指定 TensorRT-LLM Engine 构建脚本路径BUILD_SCRIPT=tensorrtllm_backend/tensorrt_llm/examples/baichuan/build.py# 创建输出目录mkdir -p ${TRITON_REPO}cp -r tensorrtllm_backend/all_models/inflight_batcher_llm/* ${TRITON_REPO}/# 拷贝 Tokenizer 相关文件到输出目录cp ${HF_MODEL}/*token* ${MODEL_PATH}/tensorrt_llm/1/# 构建 TensorRT-LLM Engine 文件,参数详见`tensorrt_llm/examples/baichuan/README.md`# 示例1: baichuan V2 13B 参数量模型,使用 FP16,开启 in-flight batching 支持#python3 $BUILD_SCRIPT --model_version v2_13b \\# --model_dir ${HF_MODEL} \\# --output_dir ${TRITON_REPO}/tensorrt_llm/1/ \\# --world_size ${TP} \\# --max_batch_size 32 \\# --dtype float16 \\# --use_gemm_plugin float16 \\# --use_gpt_attention_plugin float16 \\# --remove_input_padding \\# --paged_kv_cache# 示例2: baichuan V2 13B 参数量模型,使用 INT8 weight-only 量化,开启 in-flight batching 支持python3 $BUILD_SCRIPT --model_version v2_13b \\--model_dir ${HF_MODEL} \\--output_dir ${TRITON_REPO}/tensorrt_llm/1/ \\--world_size ${TP} \\--max_batch_size 32 \\--dtype float16 \\--use_weight_only \\--use_gemm_plugin float16 \\--use_gpt_attention_plugin float16 \\--remove_input_padding \\--paged_kv_cache# Triton config.pbtxt 配置文件修改# options.txt 文件可以按需修改,一般推荐使用默认值OPTIONS=options.txtpython3 tensorrtllm_backend/tools/fill_template.py -i ${TRITON_REPO}/preprocessing/config.pbtxt ${OPTIONS}python3 tensorrtllm_backend/tools/fill_template.py -i ${TRITON_REPO}/postprocessing/config.pbtxt ${OPTIONS}python3 tensorrtllm_backend/tools/fill_template.py -i ${TRITON_REPO}/tensorrt_llm_bls/config.pbtxt ${OPTIONS}python3 tensorrtllm_backend/tools/fill_template.py -i ${TRITON_REPO}/ensemble/config.pbtxt ${OPTIONS}python3 tensorrtllm_backend/tools/fill_template.py -i ${TRITON_REPO}/tensorrt_llm/config.pbtxt ${OPTIONS}# 建立 /data/model 的软链(TIONE在线服务中,模型默认挂载到此处)mkdir -p /dataln -s ${TRITON_REPO} /data/model# 本地启动 Triton 推理服务调试# launch_triton_server
转换完的模型目录结构如下:
# tree.├── ensemble│ ├── 1│ └── config.pbtxt├── postprocessing│ ├── 1│ │ └── model.py│ └── config.pbtxt├── preprocessing│ ├── 1│ │ └── model.py│ └── config.pbtxt├── tensorrt_llm│ ├── 1│ │ ├── baichuan_float16_tp1_rank0.engine│ │ ├── config.json│ │ ├── model.cache│ │ ├── special_tokens_map.json│ │ ├── tokenization_baichuan.py│ │ ├── tokenizer_config.json│ │ └── tokenizer.model│ └── config.pbtxt└── tensorrt_llm_bls├── 1│ └── model.py└── config.pbtxt
您可以在开发机中直接执行 launch_triton_server 命令启动 Triton Inference Server,并参考 api_test.sh 进行本地调用,若您希望发布正式的推理服务并允许公网或 VPC 内调用,请参考下面的章节。
创建在线服务
创建服务时,模型来源选择 CFS 或 GooseFS,选择模型选择 CFS 或 GooseFS 上转换好的 Triton 模型包路径。
运行环境选择刚才的自定义镜像或内置镜像内置 / TRION(1.0.0) / 23.10-py3-trtllm-0.7.1。
算力资源根据实际拥有的资源情况选择,CPU 不低于 8 核,内存不小于 40 G,GPU 推荐使用 A100 或 A800。
看到类似如下日志,说明服务启动完成:
接口调用
# 公网访问地址可从在线服务实例网页前端的【服务调用】Tab 页获取SERVER_URL=https://service-********.sh.tencentapigw.com:443/tione# 非流式调用curl -X POST ${SERVER_URL}/v2/models/tensorrt_llm_bls/generate -d '{"text_input": "<reserved_106>你是谁?<reserved_107>", "max_tokens": 64}'# 流式调用curl -X POST ${SERVER_URL}/v2/models/tensorrt_llm_bls/generate_stream -d '{"text_input": "<reserved_106>你是谁?<reserved_107>", "max_tokens": 64, "stream": true}'
非流式返回结果:
{"cum_log_probs":0.0,"model_name":"tensorrt_llm_bls","model_version":"1","output_log_probs":[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],"text_output":"我是百川大模型,是由百川智能的工程师们创造的大语言模型,我可以和人类进行自然交流、解答问题、协助创作,帮助大众轻松、普惠的获得世界知识和专业服务。如果你有任何问题,可以随时向我提问"}
流式返回结果:
data: {"cum_log_probs":0.0,"model_name":"tensorrt_llm_bls","model_version":"1","output_log_probs":0.0,"text_output":"我是"}data: {"cum_log_probs":0.0,"model_name":"tensorrt_llm_bls","model_version":"1","output_log_probs":[0.0,0.0],"text_output":"我是百川"}data: {"cum_log_probs":0.0,"model_name":"tensorrt_llm_bls","model_version":"1","output_log_probs":[0.0,0.0,0.0],"text_output":"我是百川大"}data: {"cum_log_probs":0.0,"model_name":"tensorrt_llm_bls","model_version":"1","output_log_probs":[0.0,0.0,0.0,0.0],"text_output":"我是百川大模型"}data: {"cum_log_probs":0.0,"model_name":"tensorrt_llm_bls","model_version":"1","output_log_probs":[0.0,0.0,0.0,0.0,0.0],"text_output":"我是百川大模型,"}... 省略多行 ...data: {"cum_log_probs":0.0,"model_name":"tensorrt_llm_bls","model_version":"1","output_log_probs":[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],"text_output":"我是百川大模型,是由百川智能的工程师们创造的大语言模型,我可以和人类进行自然交流、解答问题、协助创作,帮助大众轻松、普惠的获得世界知识和专业服务。如果你有任何问题,可以随时向我提问"}



