概述
高质量的训练数据对于提升模型精调效果至关重要。为了帮助用户准备高质量的训练数据,TI-ONE 平台将内部研发所采用的标准数据构建流程沉淀到了“数据中心 > 数据构建”模块,平台内置了三套不同场景下的数据处理 pipeline:有监督-单轮问答-pipeline、有监督-多轮问答-pipeline、无监督-pipeline;且在每套 pipeline 中依据不同的业务诉求分别实现了数据清洗、prompt 优化、数据过滤、数据增强等具体功能。
新建任务
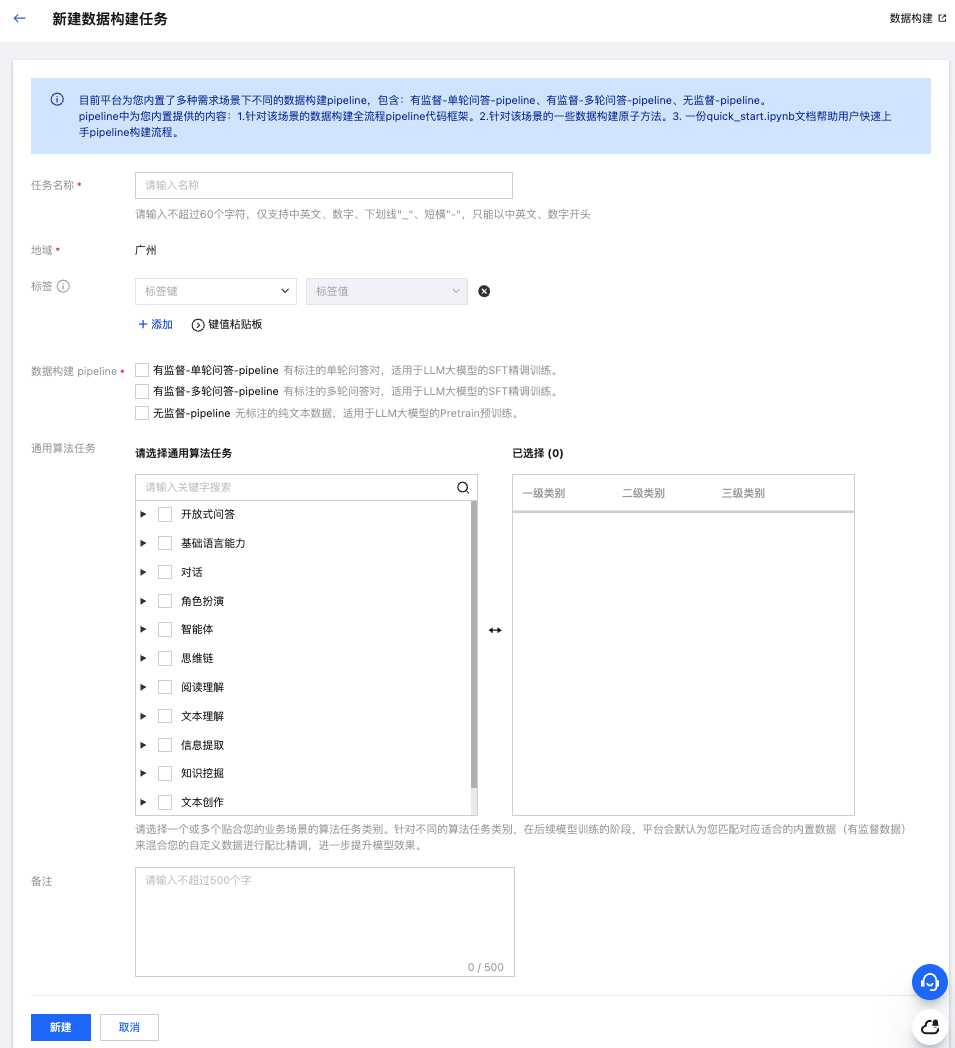
1. 在数据中心 > 数据构建列表页面,单击新建任务,完成参数配置:
任务名称:用户自定义输入,名称在数据构建模块全局唯一;
标签:腾讯云统一的云上资源标记,用于从不同维度对资源分类管理,可参考官网文档 标签;
数据构建 pipeline:可多选,类别包含:
有监督-单轮 QA-pipeline:有标注的单轮问答对,适用于 LLM 大模型的 SFT 精调训练;
有监督-多轮 QA-pipeline:有标注的多轮问答对,适用于 LLM 大模型的 SFT 精调训练;
无监督-pipeline:无标注的纯文本数据,适用于 LLM 大模型的 Pretrain 预训练。
通用算法任务:支持您请选择一个或多个贴合用户真实业务场景的算法任务类别。针对不同的算法任务类别,在后续模型训练的阶段,平台会默认为您匹配对应适合的内置数据(有监督数据)来混合您的自定义数据进行配比精调,进一步提升模型效果。
2. 单击配置页面的提交后,返回数据构建任务列表页面:
创建时间:该数据构建任务启动创建的时间点;
操作:
跳转到对应开发机:进入开发机模块,待开发机创建成功后,会同步在“对应开发实例 ID”列中展示相关信息;
删除:若对应的开发机实例已删除,则可直接确认删除任务;若对应的开发机实例还未删除,用户需要先删除后再删除数据构建任务。
搜索框:支持用户通过任务名称模糊匹配搜索。
跳转到对应开发机
选择 数据构建 > 操作 > 跳转到对应开发机 进入开发机模块。
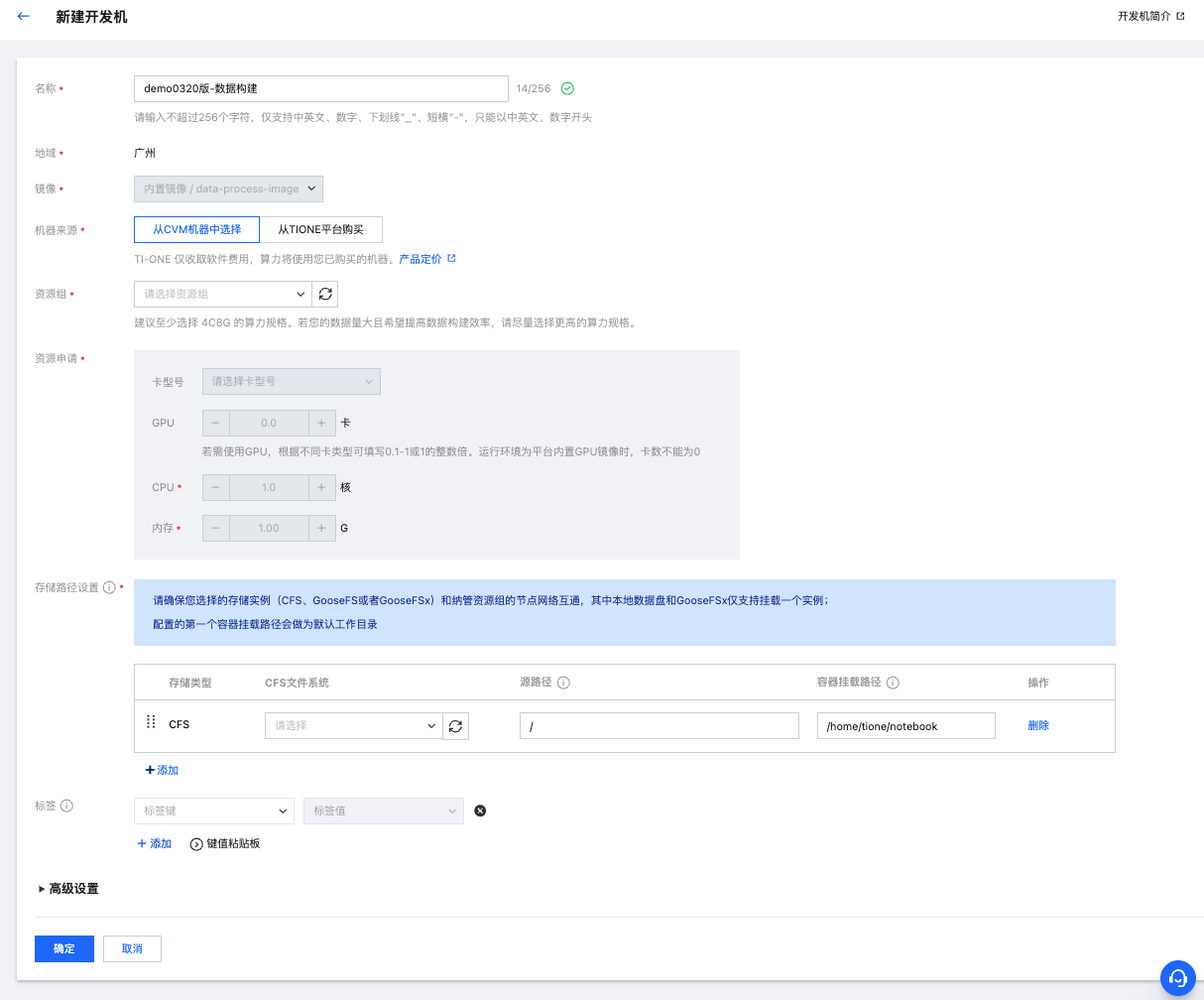
1. 首次点击,新建开发机实例。
当某一个任务首次被单击跳转到对应开发机按钮时,用户需要先创建一个开发机实例,单击后自动跳转到训练工坊 > 开发机 > 新建开发机参数配置页:
镜像:针对数据构建跳转过来的镜像,默认选中数据构建专用的内置镜像且不可修改(只有跳转过来才看得到该镜像,如果是从开发机通用入口进入就看不到本次新增的内置镜像);
算力规格:普通的数据构建任务只需要 CPU 即可,不需要 GPU;
存储配置:目前建议存储是“CFS 文件系统”;
其余参数配置和开发机已有功能要保持一致。
单击配置页面的确定后,新建任务完成后,返回开发机实例列表页面,等待创建成功。
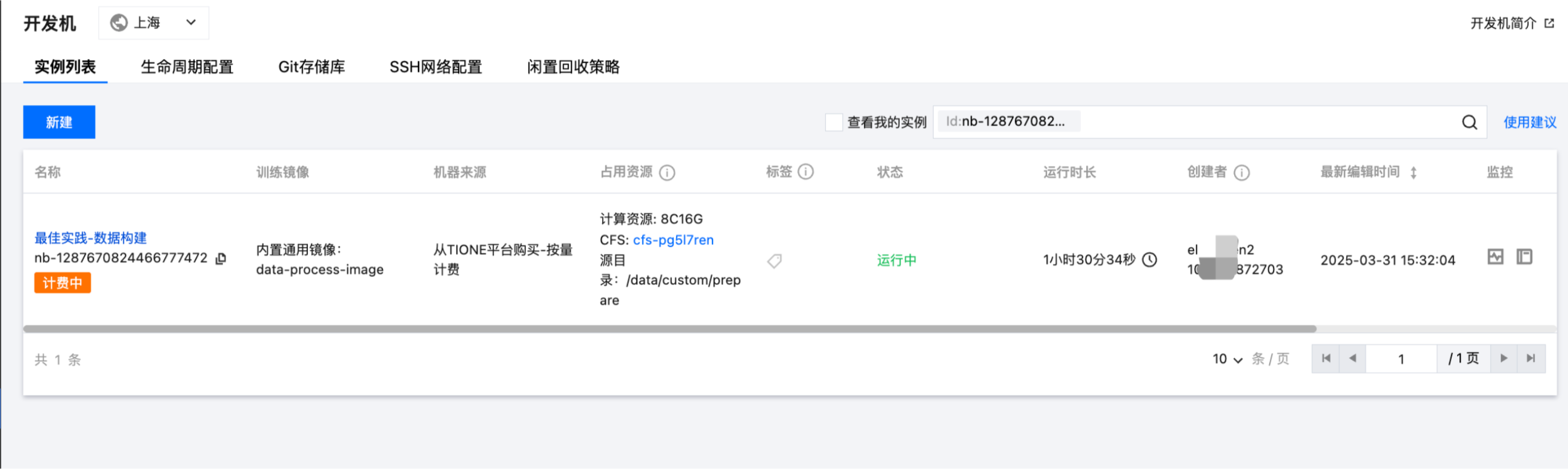
2. 非首次点击,跳转到开发机列表。
开发机实例创建成功后,用户再次单击数据构建 > 跳转到对应开发机按钮,则会直接跳转到开发机实例列表页面,同时列表搜索框会默认带上对应开发机实例 ID 以展示检索后的结果。
3. 进入开发机实例,编辑预置 pipeline 脚本。
在开发机中默认展示平台为客户提前预置好的数据构建 pipeline,由于新建任务时的参数配置页的“数据构建 pipeline”参数支持多选,所以开发机中也可能内置存在一套或多套 pipeline:
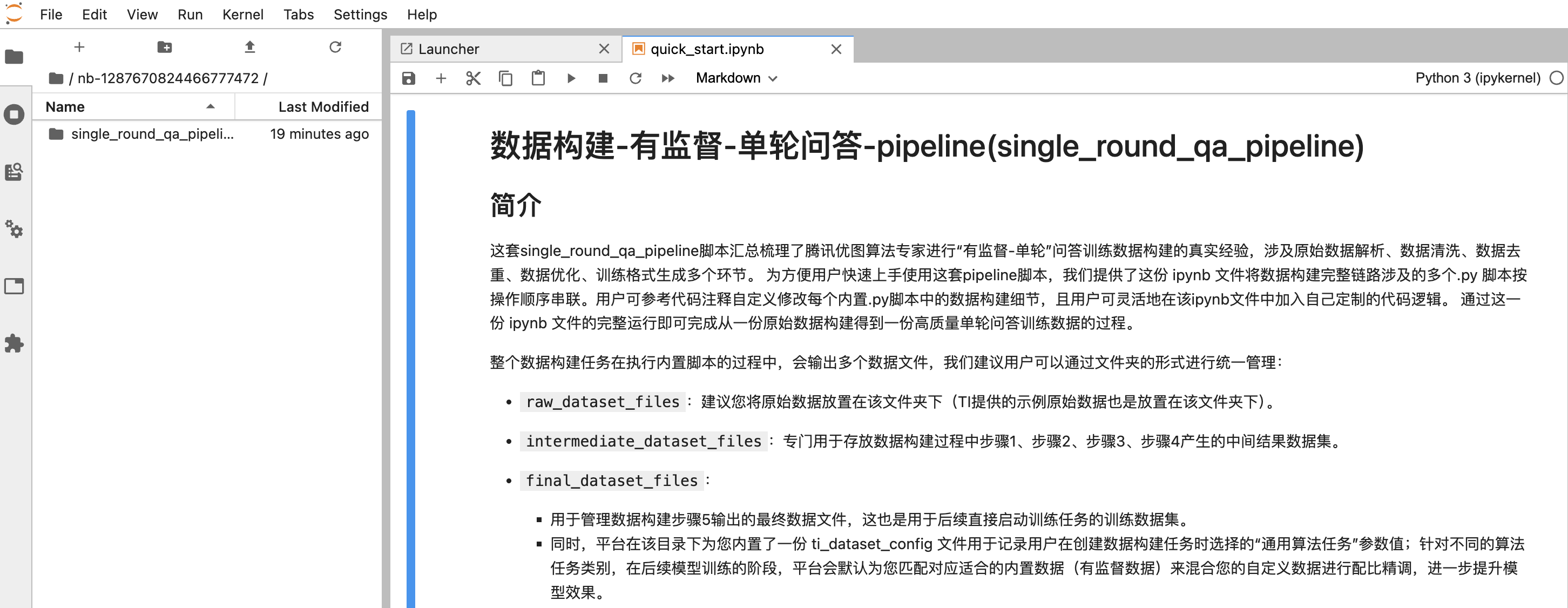
每套 pipeline 中都为用户内置提供了:
a. 针对该场景的数据构建全流程 pipeline 代码框架。
b. 针对该场景的一些数据构建原子方法。
c. 一份 quick_start.ipynb 文档帮助用户快速上手 pipeline 构建流程。
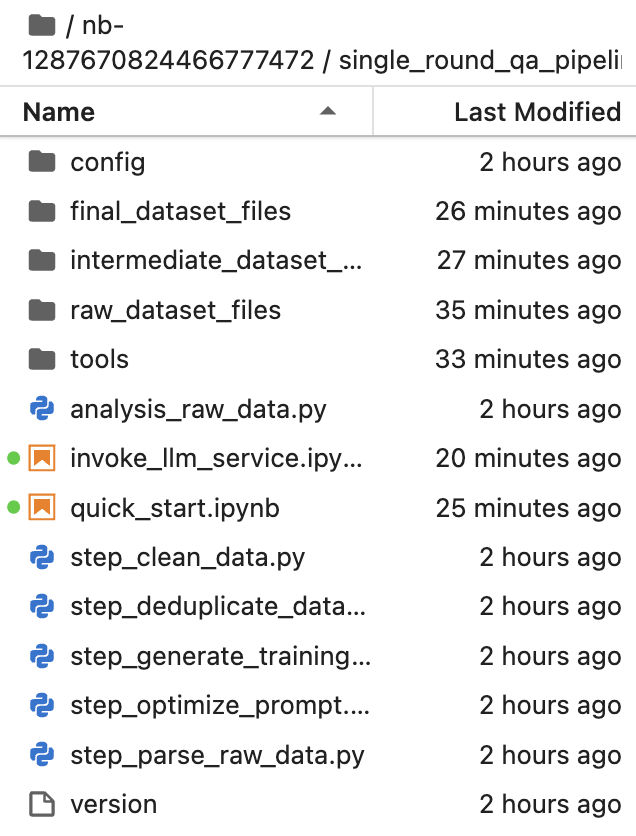
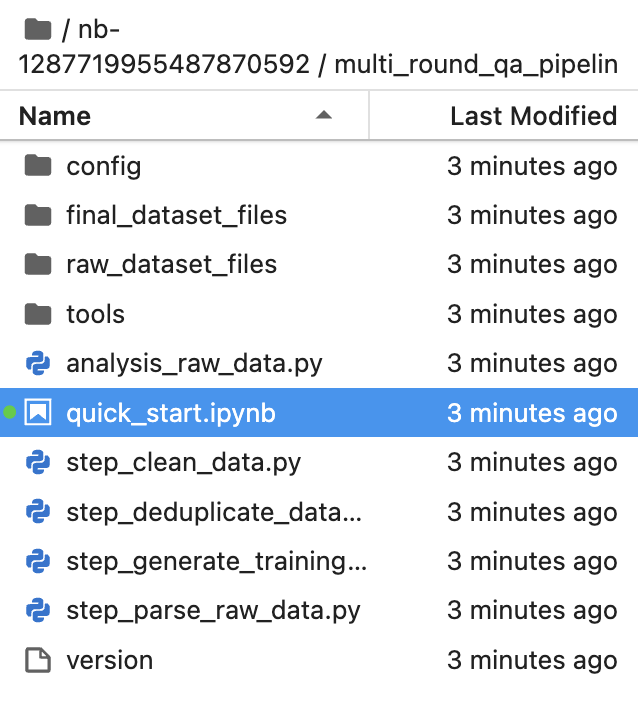
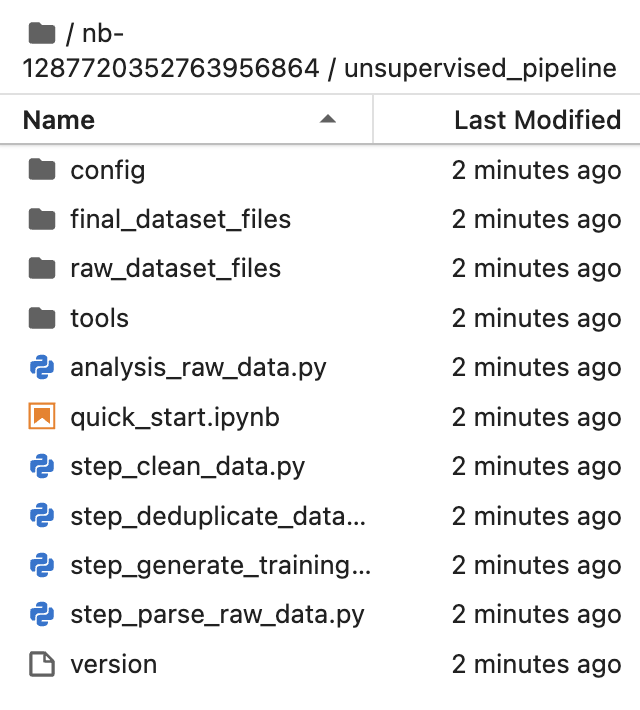
其中文件夹的层级组织形式参考:
single_round_qa_pipeline | multi_round_qa_pipeline | unsupervised_pipeline |
 |  |  |
原始数据集格式说明
有监督数据格式
我们的有监督数据构建脚本代码支持了丰富的大模型常见的数据格式,有监督单轮问答 pipeline 和有监督多轮问答 pipeline 目前支持如下格式:
1. json 文件:json 内容是一个数组,数组中每一项是一个有效的 json 对象,可以转换成单轮问答数据;如果 json 内容不是数组,而是一个 json 对象,我们会解析成长度为1个元素的数组来进行处理;
2. jsonline 文件:每一行是一个有效的 json 对象,可以转换成有监督问答数据;
3. parquet 文件:parquet 列式存储格式是开源数据常见格式(Parquet 文档)。我们会先把 parquet 对象转成 json 对象,您可在下述采样过程中预览转换后的 JSON 格式,再进行数据处理;
4. 数据集文件夹:文件夹中包含若干有效的数据文件(格式可以是 json/jsonline/parquet),此时我们会把该文件夹当做一个数据集进行处理,数据集名称即为文件夹名称,在后续数据解析流程完成后,会把所有文件的内容全部合并后再执行后续流程。
单轮有监督:示例代码提供的原始数据集文件格式为 jsonl,示例内容如下:
{"instruction": "请简要回答下面的问题:", "input": "您平时用什么投资理财方式?", "output": "我一般采用银行储蓄,相对风险较低。"}{"instruction": "请简要回答下面的问题:", "input": "基金拆分是什么意思?", "output": "基金拆分是保持基金投资人资产总值不变的前提下,改变基金份额净值和基金总份额的对应关系,重新计算基金资产的一种方式。"}
多轮有监督:示例代码提供的原始数据集文件格式为 jsonl,示例内容如下:
{"conversations": [{"from": "human", "value": "保险是什么,可靠么?"}, {"from": "model", "value": "保险,是指投保人根据合同约定,向保险人支付保险费,保险人对于合同约定的可能发生的事故因其发生所造成的财产损失承担赔偿保险金责任,或者被保险人死亡、伤残、疾病或者达到合同约定的年龄、期限等条件时承担给付保险金责任的商业保险行为。正规渠道购买的保险都是安全可靠的。"}, {"from": "human", "value": "我想买一些投资理财类的保险,有哪些险种?"}, {"from": "model", "value": "年金保险、分红险、投连险等。"}, {"from": "human", "value": "这些投资理财类保险是不是稳赚不赔的?"}, {"from": "model", "value": "不是,收益受到市场因素影响。"}]}{"conversations": [{"from": "human", "value": "我妈妈最近想买一份大病保险,这个是骗人的么?"}, {"from": "model", "value": "不是,重大疾病保险,它是一种针对严重疾病进行保障的保险产品。"}, {"from": "human", "value": "这个大病保险的报销比例有多少?"}, {"from": "model", "value": "重大疾病保险报销比例是根据保险合同中约定的具体条款来确定的,不同的保险公司和不同的保险产品可能有不同的报销比例。"}, {"from": "human", "value": "我妈也想给我买一份,但是我目前17岁,可以买么?"}, {"from": "model", "value": "可以,但是未成年需要父母作为投保人来购买。"}]}
无监督数据格式
我们的无监督数据构建脚本代码支持了丰富的大模型常见的数据格式,无监督 pipeline 目前支持如下格式:
1. json 文件: 支持 json 对象文件和 json 数组文件的解析;
2. jsonline 文件: 支持 jsonline 多行文件格式;
3. parquet 文件: parquet 列式存储格式是开源数据常见格式(Parquet 文档)。我们会先把 parquet 对象转成 json 对象,您可在下述采样过程中预览转换后的 json 格式,再进行数据处理;
4. text 文件: txt 文本文件;
5. wet 格式: WET 表示原始网页 WARC 文本化(WET)格式。 我们会把 WET 解析成 json 对象,您可在采样过程中预览,再进行数据处理;
6. 数据集文件夹: 支持以上类型的多个文件放在同一文件夹下面处理, 同一文件夹下面目前只支持一种类型的多个文件同时处理。
数据格式的示例如下:
json:json 数组的每一行作为一条数据
["this is statement 1","this is statement 2"]
jsonl:每一行的"text"key 对应的 value 字段作为一条数据,例如:
{"text": "this is statement 1"}{"text": "this is statement 2"}
text:
this is statement 1this is statement 2
wet:支持标准的 Web Archive,详情请参考 示例数据。
数据蒸馏
在【有监督-单轮问答-pipeline】的开发机脚本中,我们新增内置了一段“通过数据构建的 notebook 调用在线服务得到批量预测结果”的数据蒸馏脚本。该脚本用于帮助用户实现如利用 DeepSeek-R1 模型构建蒸馏训练集的目标。且将该数据蒸馏环节内置到已有的数据构建 pipeline 中,便于用户灵活处理数据,如在调用蒸馏模型之前先通过 pipeline 中的数据清洗、去重等子模块过滤一些低质量、冗余的样本数据,以此降低服务调用的成本。
开发者可通过 tools/generate_reasoning_stream.py 查看核心实现代码,该脚本基于 Hugging Face 开源方案重构,并深度适配了 TI-ONE 平台的计算资源调度特性,集成了高效并发机制来调用在线推理服务实现快速生成推理结果。
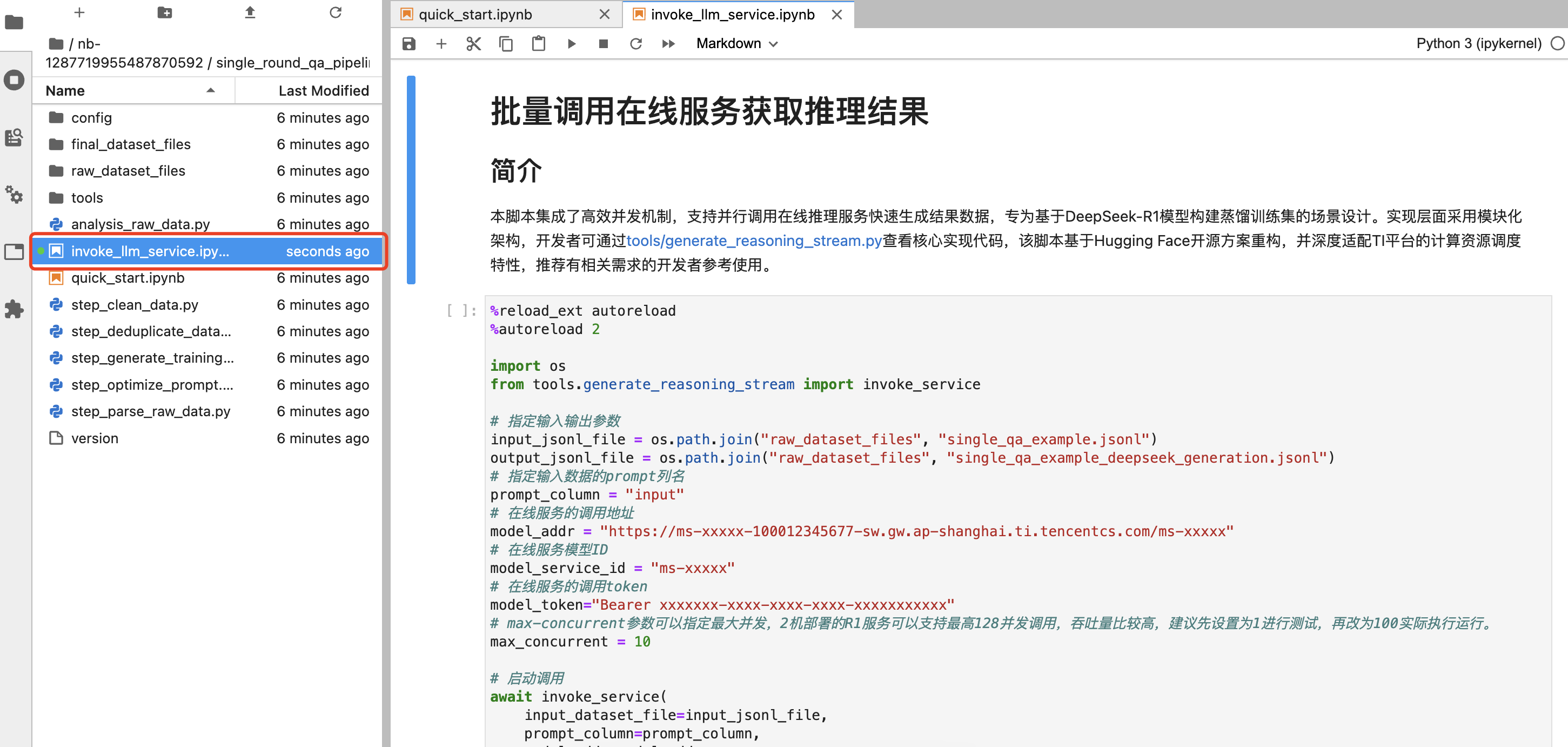
首先,在运行该脚本功能前,请确保您在模型服务 > 在线服务模块的自定义在线服务已处于“运行中”状态,您的目标就是利用已有样本集批量调用该在线服务得到样本推理结果。
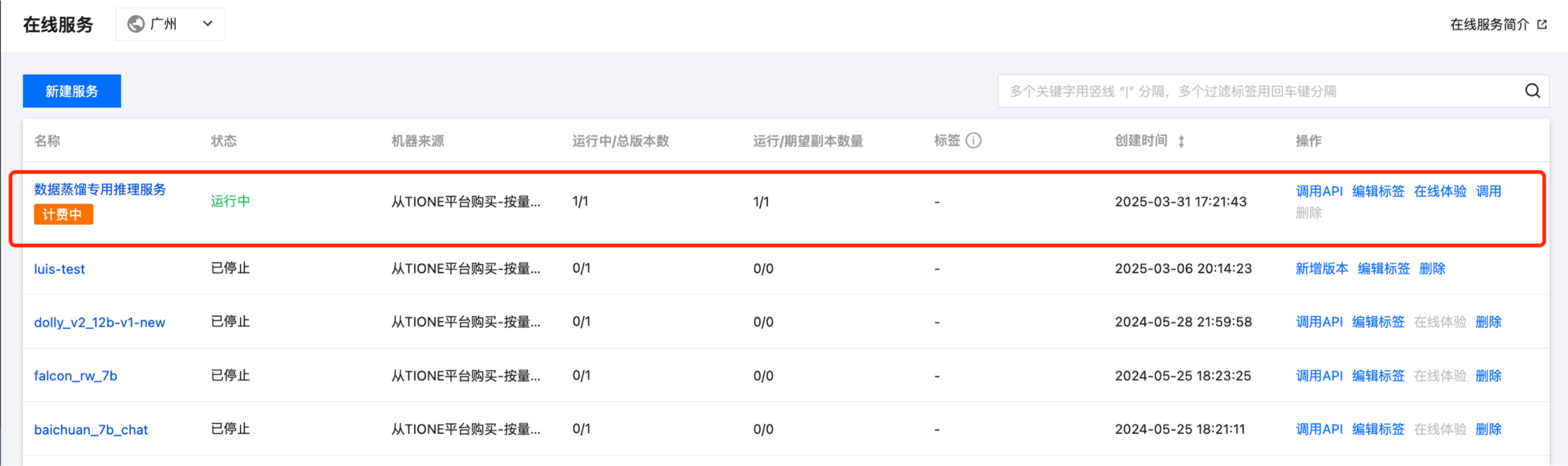
然后,单击在线服务名称查看详情,将以下三处红框信息分别填写到数据构建脚本参数中。
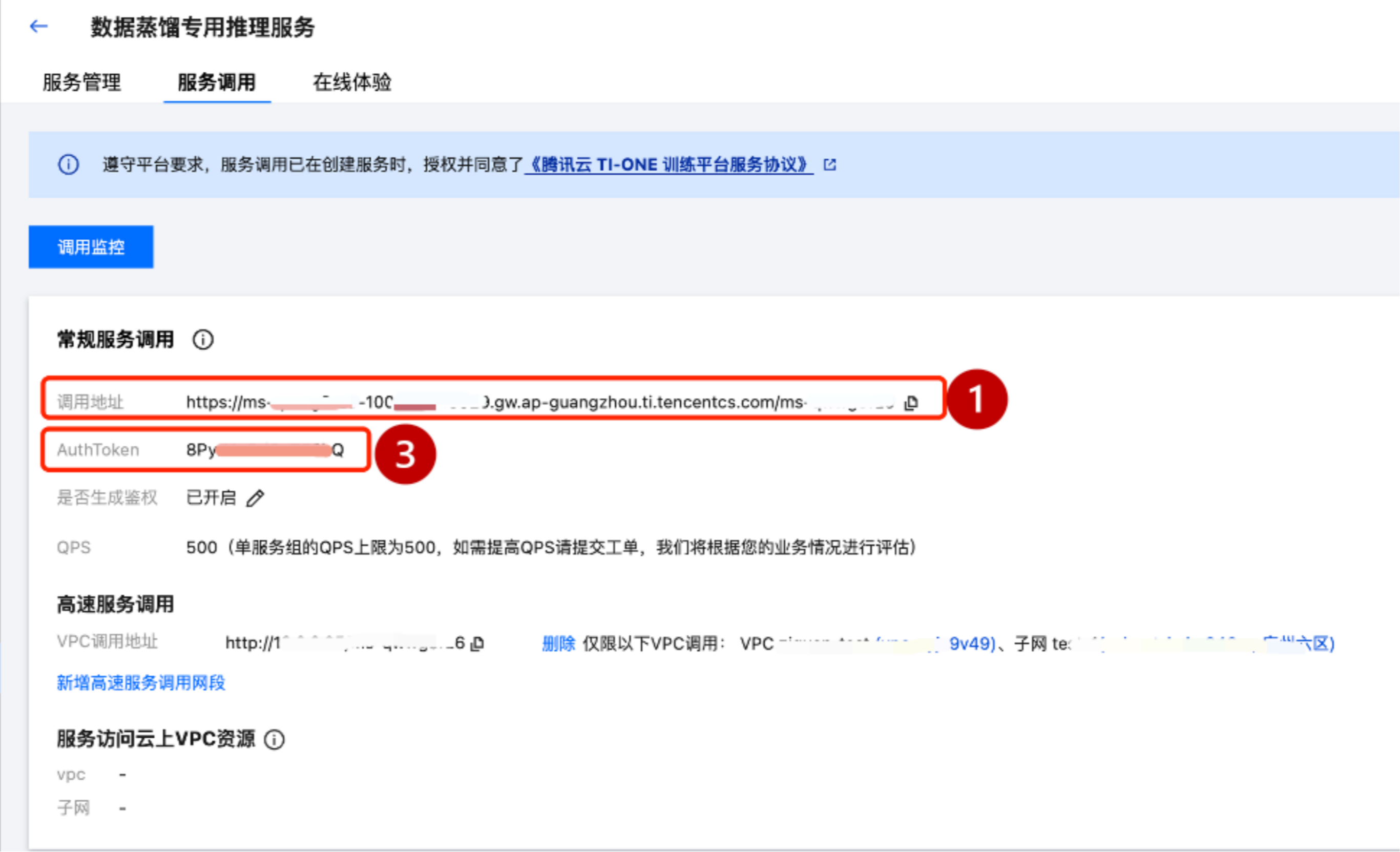

填写完您的在线服务参数的同时,自定义修改您的数据样本路径“input_jsonl_file/output_jsonl_file”,最后单击运行该 notebook,即可实时查看本次数据蒸馏任务的构建进度。