自动扩缩容
如果您的业务负载有显著的峰谷特征,为了提升推理算力资源的利用效率,您可以使用在线服务模块的自动扩缩容能力。该功能支持在线服务的实例数量根据您配置的扩缩容策略自动调整,从而实现在业务负载高峰时实例数量自动扩容,在业务负载低谷时实例数量自动缩容。
自动扩缩容支持多种类型的调节策略:基于时间调节、基于 HPA 调节、以及支持时间+HPA 的组合调节,下面详细介绍不同调节策略的使用方法。
基于时间调节(定时策略)
如果您的业务负载有显著的时间特征,则可以根据时间进行自动扩缩容策略的配置。
1. 配置定时策略
1.1 登录 产品控制台,在左侧导航栏中选择模型服务 > 在线服务,单击新建服务进入参数配置表单,配置“副本调节-自动调节”参数,单击编辑配置。

1.2 在配置弹窗中,选择“调节策略:定时策略”,即可进行时间调节策略的规则配置。您可以根据实际业务负载的时间特征自行配置多条定时策略规则,例如若8:00至20:00为业务高峰时段,20:00至8:00为业务低谷时段,则可以配置如下图的定时策略,每日8:00将实例数扩容至2,每日20:00将实例数缩容为1(默认策略为服务启动后的初始实例数量)。
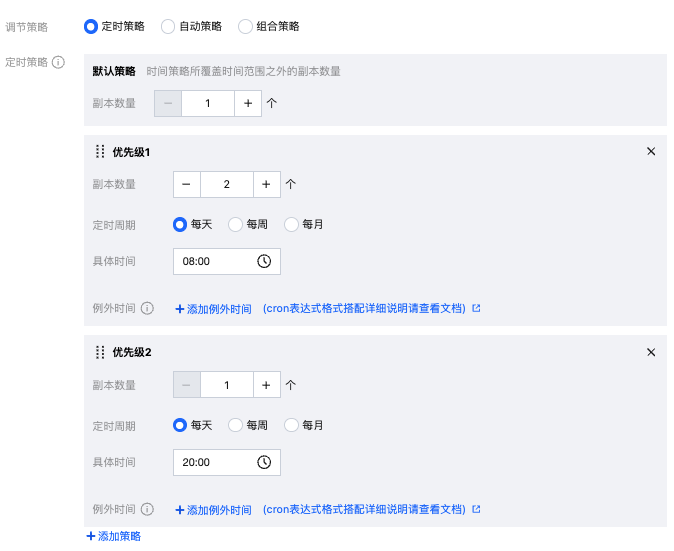
1.3 若您配置了多条定时策略规则,且多条规则之间存在时间冲突,则会以优先级级别较高(即优先级排序靠前)的策略为准。
1.4 使用定时策略时,最小副本数可设置为0,从而实现服务的定时启停(该能力当前为白名单功能,如需开通请联系客户经理或提交工单)。
注意:
当最小副本数设置为0时,服务副本将被完全回收。此时新请求将面临完整的冷启动延迟,期间服务不可用。
2. 例外时间配置规则
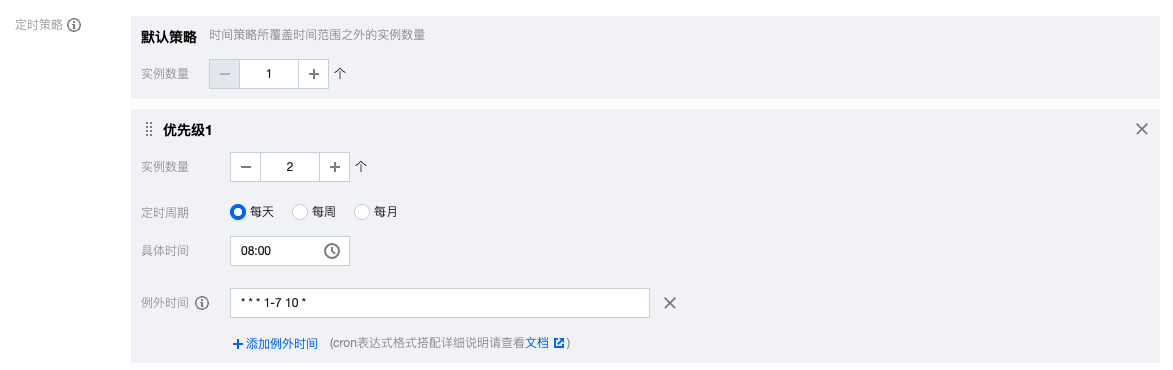
2.1 若某个定时策略希望在特定的时间不执行,则可以为该定时策略规则配置例外时间,支持添加多个。
2.2 例外时间需通过 Cron 表达式进行配置,Cron 表达式共包含6位,分别代表“秒”“分”“时”“日”“月”“星期”,若特定位的取值为任意值则使用星号(*)即可,若特定位取值需包含连续多个数值则可以使用连字符(-),若特定位取值需包含多个离散数值则可以使用逗号(,)。
2.3 例外时间的最小配置粒度是日,因此 Cron 表达式的前三位取值需要使用“*”(前三位配置其他值不会生效),后三位取值可按需配置,第4位“日”的可用值范围为1 - 31,第5位“月”的可用值范围为1 - 12或 JAN - DEC,第6位“星期”的可用值范围为0 - 6或 SUN - SAT。
2.4 示例:每年10月1日至10月7日的 Cron 表达式为“* * * 1-7 10 *”。
基于 HPA 调节(自动策略)
如果定时调节不适合于您的业务模式,您也可以选择“调节策略:自动策略”。
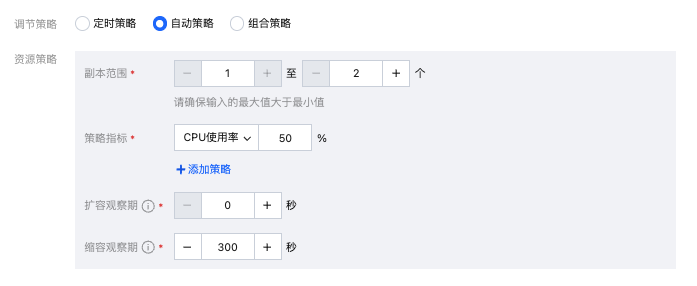
在该策略下,服务实例数量可根据您所配置的策略指标与指标阈值,在实例数的最小值与最大值之间自动进行调节,支持用户配置:
策略指标:支持 CPU 使用率、内存使用率、GPU 使用率、单副本 QPS、处理中请求数、处理输入 token 数、处理输出 token 数、Token 利用率等指标。
扩容观察期:观察期内采样值全部高于预设指标后执行扩容。
缩容观察期:观察期内采样值全部低于预设指标后执行缩容。
定时+HPA(组合策略)
定时扩缩容和 HPA 自动扩缩容是 Kubernetes 中两种不同的弹性扩缩容策略,它们在触发机制、适用场景和配置方式上存在显著差异。定时+HPA 的混合策略能够充分利用两种机制的优势,在保证服务稳定性的同时实现成本优化和资源利用率的提升。
如下述一个真实业务场景就需要配置组合扩缩容策略:
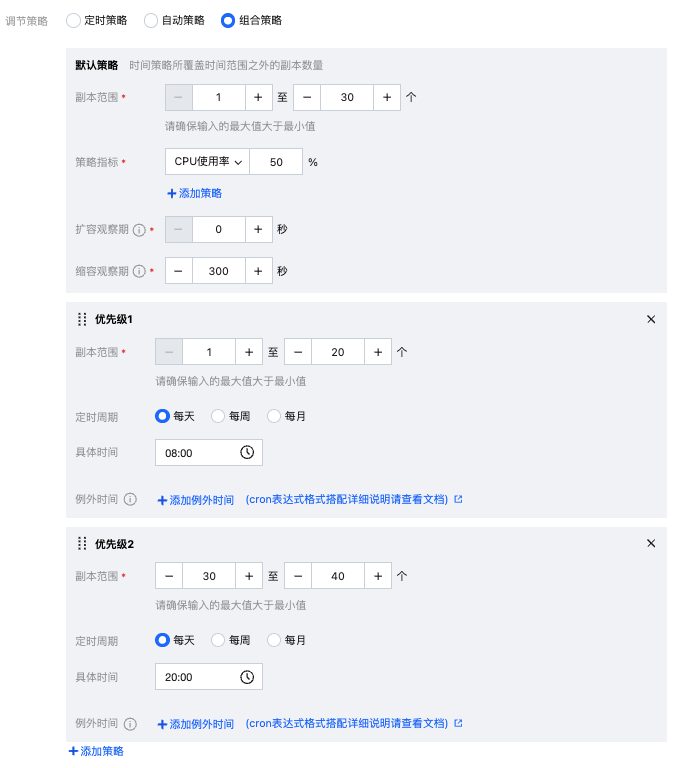
首先,指定一个默认全局的伸缩策略为:副本范围:20-30,CPU 利用率指标是 50%;
然后,特定时间点1:早上8点为低峰期,8点开始伸缩策略配置为:副本范围:10-20,CPU 利用率指标是 50%。
同时,特定时间点2:晚上20点为高峰期,20点伸缩策略配置为:副本范围:30-40,CPU 利用率指标是 50%。
该场景的组合策略配置参考如下:
流量分配
为了满足灰度验证或者 A/B 测试类的服务使用诉求,平台支持用户为单个服务添加多个版本,并进行流量分配。
1. 登录 产品控制台,在左侧导航栏中选择模型服务 > 在线服务,进入在线服务列表页面。
2. 找到需要测试的服务,单击服务的新增版本操作,打开服务版本创建页,按需配置当前服务版本的容器信息及实例调节信息。
3. 单击启动服务,若为后付费模式则需进行费用冻结确认,即可完成新版本创建。
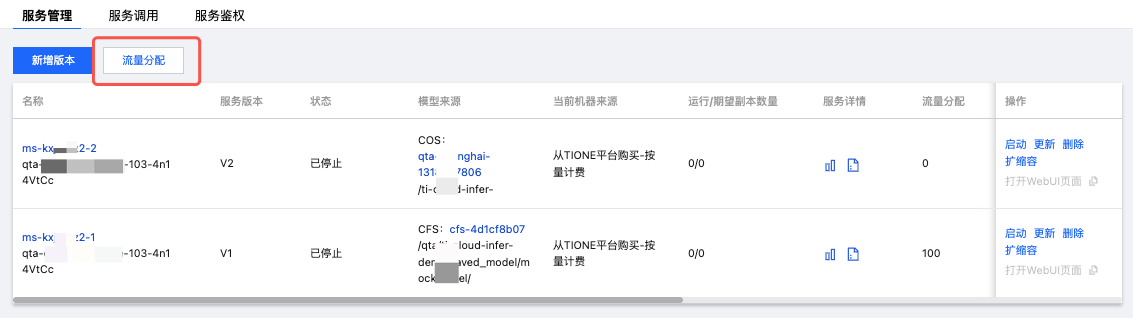
4. 创建新的服务版本后,系统将为您创建网关后端并调度计算资源,需要等待一段时间,待服务版本成功完成部署时,状态将变为运行中。
5. 此时可单击服务版本列表上方的流量分配操作,进行多版本流量比例的设置。
服务监控
为了满足服务运行情况追踪的诉求,平台提供服务数据监控、调用数据监控、事件与日志查看能力。
1. 在线服务列表页面,单击服务名称进入版本列表页后,单击服务调用 > 调用监控,可查看服务调用情况的统计信息,包括接收请求数、成功请求数、失败请求数、被限制请求数、平均响应时间。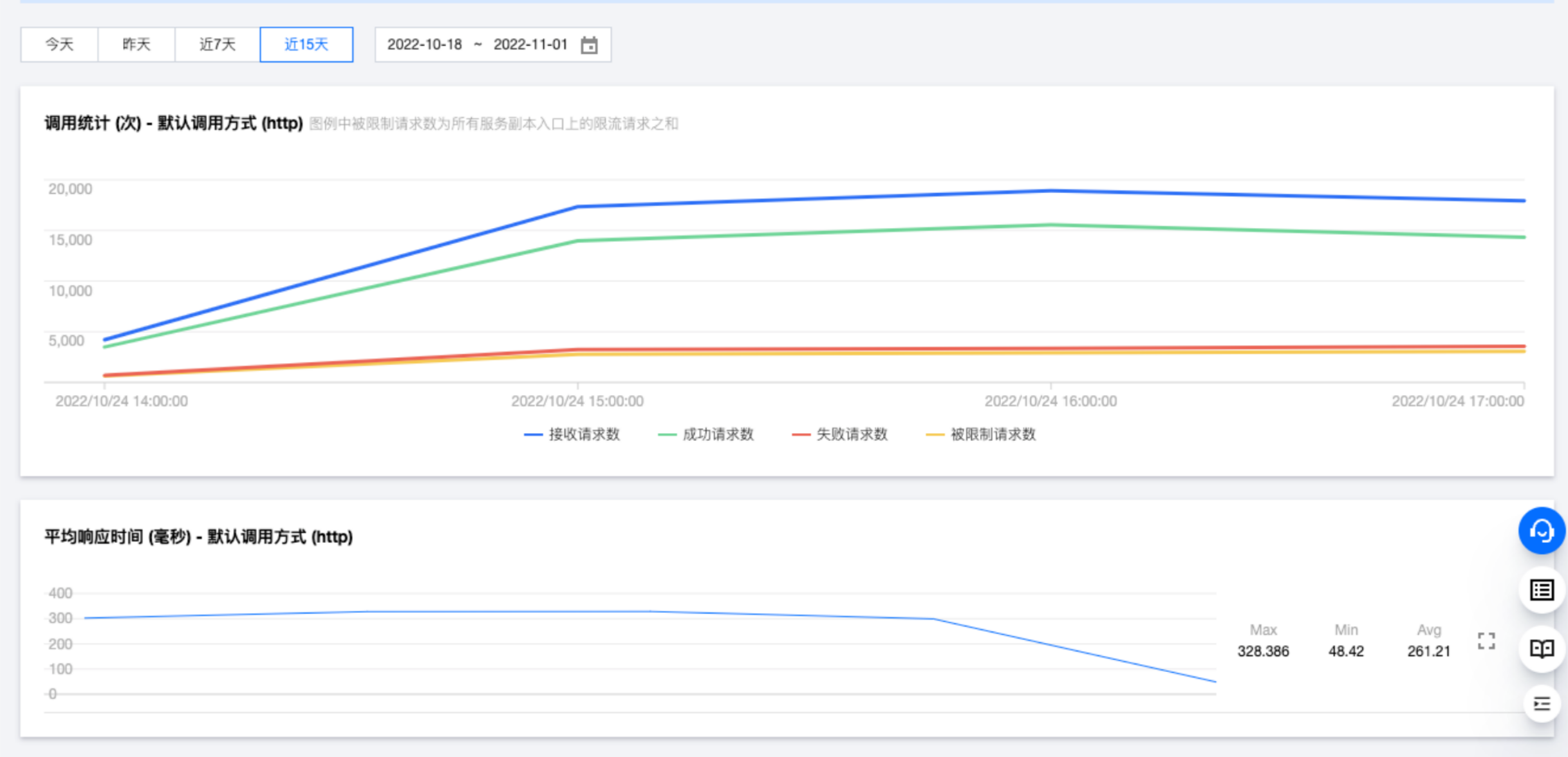
2. 在线服务监控页面,可跳转到腾讯云可观测平台的告警管理里,为服务添加告警策略。
3. 在线服务列表页面,单击服务名称进入版本列表页后,单击服务版本名称进入版本详情页面,可查看服务监控、事件监控、运行日志。其中服务监控分为大模型监控和通用监控:
大模型监控
类别 | 监控指标 | 监控指标含义 |
时延 | 首 Token 时延(s) | TTFT(Time to First Token)表示从用户发起请求到模型开始输出第一个 Token 的时间差。在流式输出场景中,该指标决定了用户界面何时开始更新内容,是用户体验流畅度的关键。 |
| 非首 Token 时延(s) | TPOT(Time Per Output Token) 表示模型从生成第一个输出 Token 之后,每个后续 Token 的平均生成时间。它聚焦于解码(Decode)阶段的效率,反映模型自回归生成文本的能力,OTPS = 1/TPOT,两者互为倒数。 |
| 总 Token 耗时(s) | TRT(Total Response Time )表示执行一个请求从开始到最后收到响应数据所花费的总体时间,即从客户端发起请求到收到服务器响应结果的时间。又称响应时间,请求处理时间。 |
吞吐 | 每分钟请求数 | RPM(Requests Per Minute)表示模型服务每分钟能处理的请求次数。例如,某模型设置 RPM=300,则每分钟最多响应300次用户请求。 |
| 每分钟处理 Token 数 | TPM(Tokens Per Minute)表示大模型每分钟能够处理的输入和输出 Token 总量,且支持详细查看“每分钟处理 Token 数,仅输入”和“每分钟处理 Token 数,仅输出”。 |
| 系统平均输出 Token (token/s) | OTPS(Output Tokens Per Second)表示模型每秒生成的输出 Token 数量,用于评估模型生成文本的整体效率。OTPS 越高,模型输出越流畅,用户体验越连贯。 |
Token 累计及特征 | 已处理 Token 总量 | 全天输入 Token + 输出 Token 长度 总和,且支持查看“已处理 Token 总量,仅输入”和“已处理 Token 总量,仅输出”。 |
| 输入平均长度(Token) | 所有输入样本的平均长度(Input Length)。 |
| 输出平均长度(Token) | 所有输出样本的平均长度(Output Length)。 |
请求负载 | 处理中请求数 | 采样时在处理中的请求数量。 |
| 排队中请求数 | 采样时处于排队中的请求数量,常见于 KVCache Token 用满的情况。 |
通用监控
类别 | 监控指标 | 监控指标含义 |
流量信息 | 网络入流量 | 服务实例的网络数据传输下行(入口)流量。反映模型服务的通信负载,突发流量可能预示请求量激增或异常调用,可结合 QPS 一起分析。 |
| QPS(次/秒) | 每秒处理的请求数(Query Per Second),衡量服务吞吐量的核心指标。 |
| QPS 限流(次/秒) | 主动限制每秒最大请求数的机制,超过阈值的请求会被拒绝。 |
| 并发请求数 | 同一时刻正在处理的请求数量(包括等待和计算中的请求)。 |
资源信息 | CPU 使用率(%) | 服务实例的 CPU 资源占用百分比。 |
| MEM 使用率(%) | 服务实例的内存占用百分比。 |
| 显存使用率(%) | 服务实例的 GPU 显存使用占用百分比。 |
| GPU 使用率(%) | 服务实例的 GPU 计算单元负载百分比。 |
实例信息 | 实例数量 | 当前配置的服务实例总数(包括启动中、运行中、异常等所有状态)。 |
| 运行中实例数量 | 实际正常处理请求的实例数。 |
服务更新
“操作-更新”适用于更新服务参数配置:1)更新实例/副本数量,用于实现扩缩容策略;2)更新副本设置参数用于迭代模型版本。
1. 在线服务列表页面,单击服务名称进入版本列表页后,单击服务版本“操作-更新”操作进入服务更新页面。
更新支持编辑修改副本设置、请求限流、副本调节等服务参数。请注意:单副本的情况下更新会导致服务重启过程中出现服务不可用的情况,无法实现服务高可用;多副本的情况下更新服务时,后台会依据您在参数配置页面的滚动更新策略对多副本进行分批滚动更新,不影响生产业务对服务的调用,实现高可用。

2. 配置信息确认无误后,单击更新服务完成服务参数配置的更新操作。
3. 在服务版本列表页单击服务版本名称,进入更新记录模块,可查看当前服务版本历史的更新记录信息。
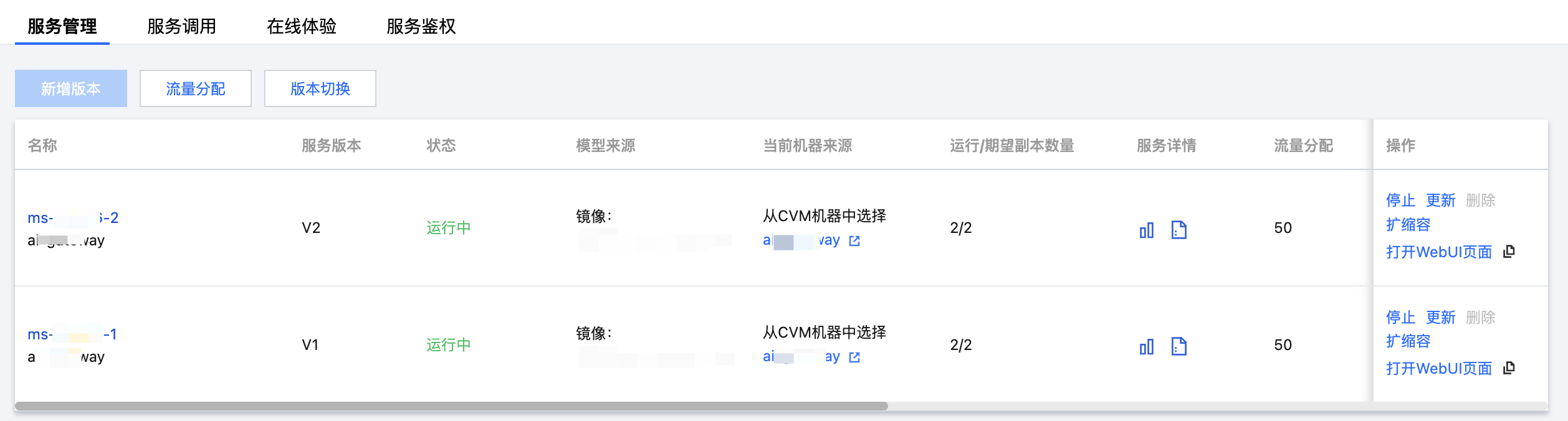
版本切换
针对存在多个版本的服务,单击服务名称进入版本详情列表页面,在“服务管理” Tab 页支持配置版本切换。用户使用场景如:
V1 运行中,V2 运行中或不在运行中,用户配置版本切换,可实现从 V1 升级到 V2。
V2 运行中,V1 运行中或不在运行中,用户配置版本切换,可实现从 V2 回滚到 V1。
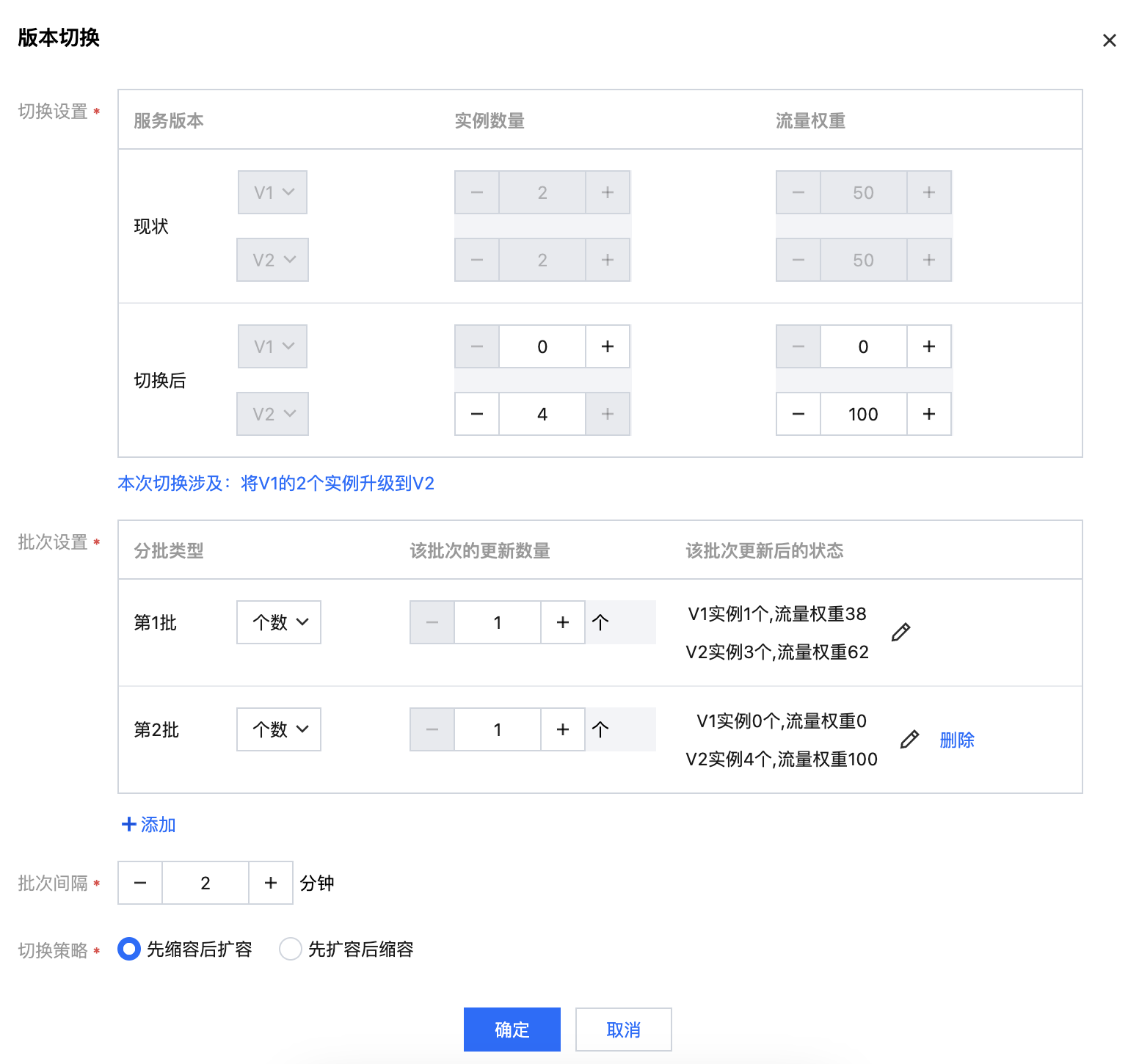
核心参数配置说明如下:
切换设置-现状:展示当前服务的多版本、实例数量、流量权重信息,只读不可编辑。
切换设置-切换后:服务版本不可编辑,用户可自定义调整每个版本对应的实例数量和流量权重。
批次设置:支持设置多个批次进行分批完成服务切换。分批类型支持:个数/百分数(请注意同一个切换任务的不同批次之间的分批类型必须保持统一)。
批次间隔:上一批次切换完成后,等待下一批次启动切换的时间间隔。
切换策略:
先缩容后扩容:适用于算力资源不足的情况下,只能先缩容释放出算力资源后,再进行扩容的操作。
先扩容后缩容:适用于有额外的算力资源的情况,需要先使用额外的算力资源才能完成扩容的操作,然后再进行缩容。
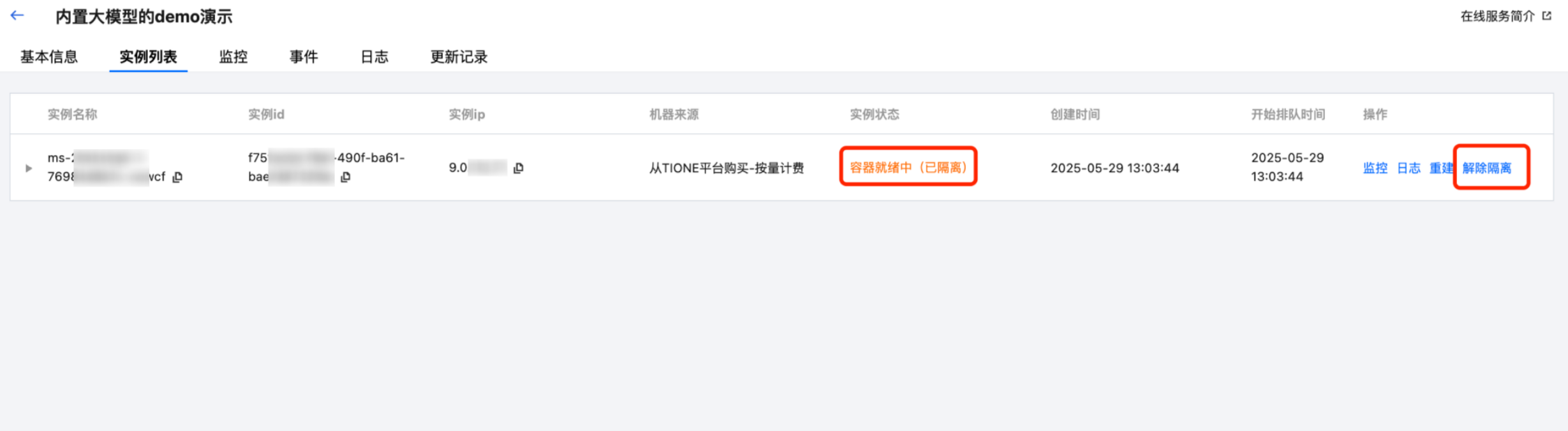
隔离异常实例
当服务的某个实例出现异常导致服务质量受影响时,平台支持用户在诊断期间手动隔离该实例的流量,而不需要重建实例 Pod。这样可以保留现场进行诊断,并支持在修复后手动恢复流量。
单击服务名称进入实例列表的详情页面,针对“实例状态”是“运行中”的实例,用户可单击“操作 > 隔离”按钮主动隔离指定实例,此后流量将不会再分配到被隔离的实例上。
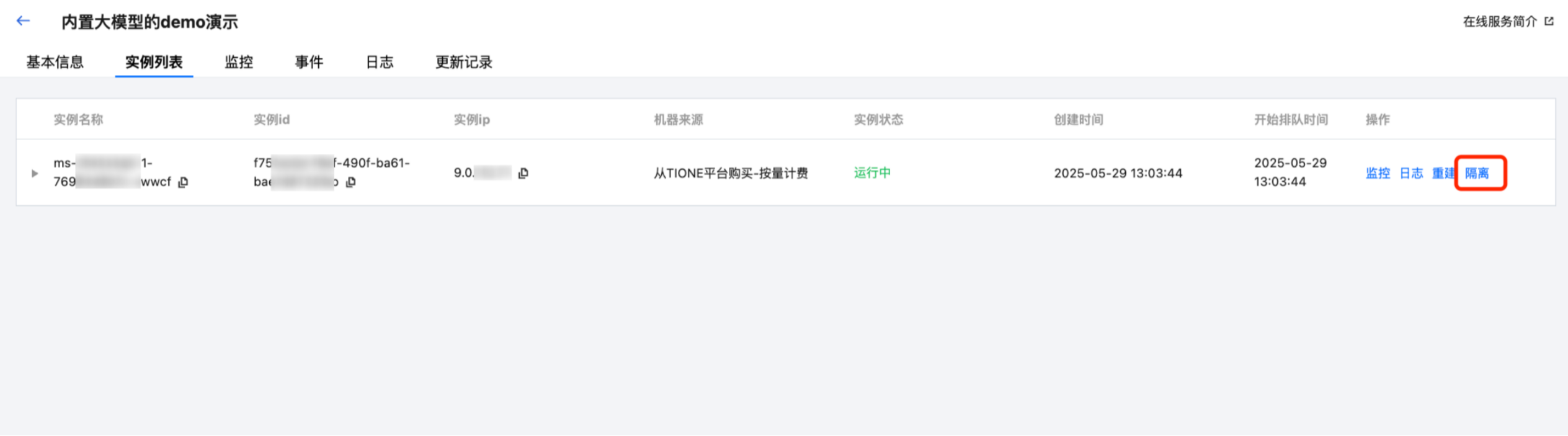
针对已隔离的实例,用户可单击“操作 > 解除隔离”手动恢复该实例,解除隔离成功后,实例会重新恢复到“运行中”的状态。