概述
本文详细介绍了腾讯云文档智能 OCR 技术,突出其高精度、灵活性和易用性。通过多模态大模型技术,该 OCR 服务支持个性化模板定制,显著提升数据抓取效率,适用于多种文档识别场景。文章还提供了获取 SecretId 和 SecretKey 的指南,以及如何使用 OCR 服务的步骤,包括前端界面设计和后端 Flask 应用实现。最后,作者鼓励读者亲自尝试 OCR 服务,并对其功能和界面表示满意。
引言



在上述情境中,我们仅对腾讯云文档智能 OCR 这一技术进行了简要提及。凭借其卓越的高精度、出色的灵活性和极佳的易用性,腾讯云文档智能 OCR 正开启跨行业高效且精准的文档处理及数据提取的新篇章。腾讯云文档智能 OCR 以多模态大模型技术为核心,融合了深度学习、图像检测技术及 OCR 大模型能力,通过智能建立键值对应关系,支持客户根据自身需求定制个性化模板,显著提高数据抓取与录入的效率。其基础版本为企业搭建了通用型文本识别的稳固框架,可精准识别常见的印刷体文字、数字及基本符号,满足一般性的数据提取需求。而高级版本则进一步融入了语义理解、上下文关联分析等高级功能模块,能够应对诸如法律合同、医学报告等专业性强、语义复杂且版式多变的文档识别任务,实现关键信息的深度挖掘与结构化输出。例如,在处理法律合同文档时,腾讯云文档智能 OCR 能够快速提取合同双方、金额信息、时间节点等关键信息,大大提高了合同处理的效率和准确性。
其实,撰写这篇文章我内心纠结良久,迟迟未能动笔。究其根本,是因我对这款产品知之甚少,无从下笔。在日常生活中,我们或许接触过类似 OCR 功能的场景,例如部分手机自带的图片文字自动识别功能,又或是微信、QQ中通过截图进行的文字识别,它们的准确率着实令人称赞。眼看活动即将落幕,我终于挤出些许时间,匆匆写下这篇文章,现在就让我们直奔主题。
或许您和我一样,面对产品文档或产品界面时,感到一头雾水,不知该如何着手。为此,我精心整理了一份思维导图,您可以借助这张图,迅速把握产品的核心要点。
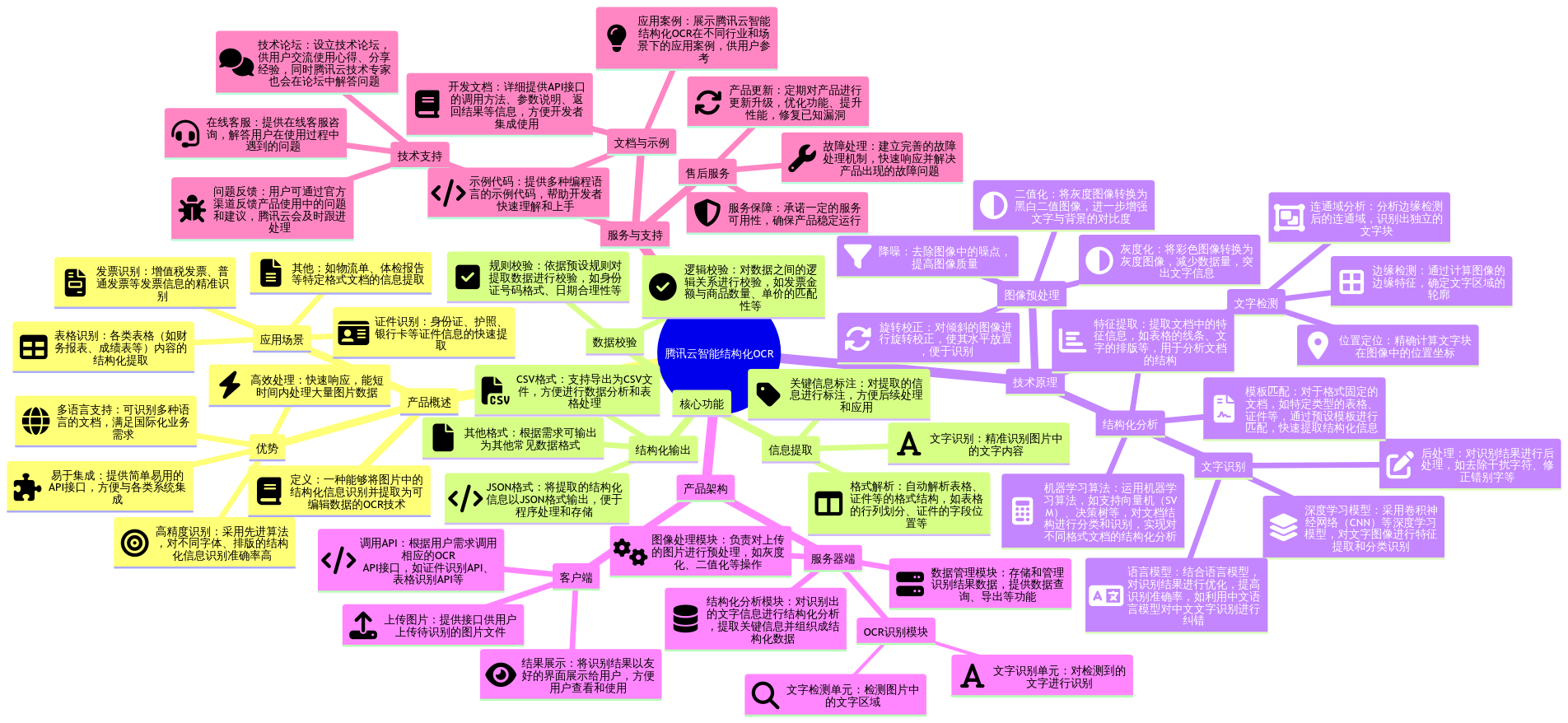
借助这份思维导图,我们能够对产品形成初步的宏观认知。那么,您是否对这款产品有了新的认识呢?又或者,还有哪些疑问未解呢?接下来,让我们一同探究 OCR 识别的原理,这将助我们深入理解产品背后的技术支撑,进而更高效地运用它来满足自身需求。虽然下面这张图较为简单,但它却是最直观地解释文字识别原理的方式。将两张图对照来看,既能让您对产品有更深入的看法,也能增进您对产品使用的了解。下面,就让我们来了解一下如何使用这款产品。目前而言,这款产品几乎没有任何使用门槛,希望大家都能多去尝试,说不定您会喜欢去使用这款产品。
文档智能的注册
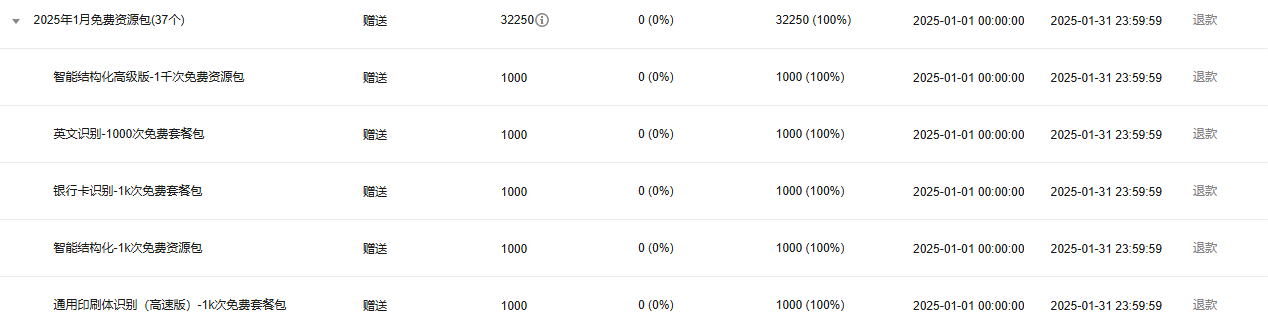
完成首次注册后,系统将贴心地赠送一份免费资源包,有效期为一个月。这份资源包对于普通用户而言,可谓相当充足。其详细资源列表涵盖了从几十次到几千次不等的使用额度,足以满足我们在短期内的使用需求,无需急于再次购买。激活资源后请确保 SecretId 和 SecretKey 的唯一性。
获取 SecretId 和 SecretKey
可能有些小伙伴不清楚 SecretId 和 SecretKey 的获取位置,接下来就让我来为大家详细讲解。首先,点击此处进入腾讯云的访问管理页面。在页面中找到“用户”选项,再点击“用户列表”。接着,点击“新建用户”按钮。当然,您也可以直接使用主账号,但出于安全和资源管理的考虑,我更推荐大家创建一个子账号,这里勾选 QcloudOCRReadOnlyaccess 账号权限。这样既能有效避免他人误用资源导致不必要的消费,又能更好地管理权限和资源使用情况。
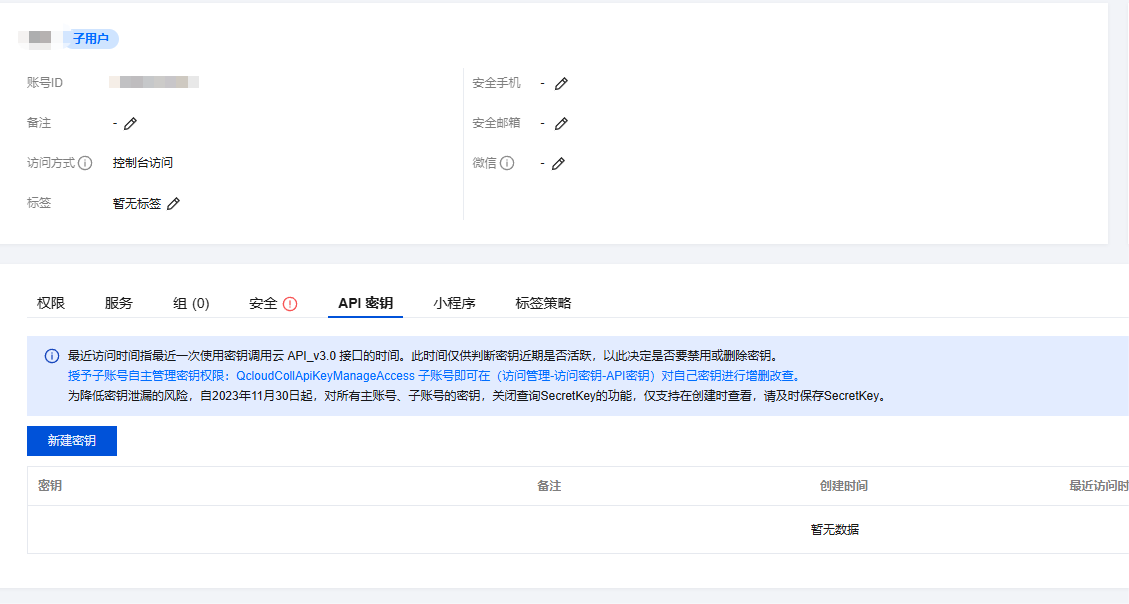
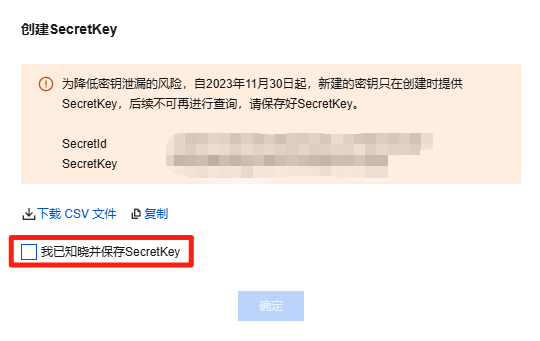
进入子用户面板后,点击“API密钥”选项。再次点击“新建密钥”,此时系统会立即弹出显示 SecretId 和 SecretKey 的界面。需要特别注意的是,这个密钥信息目前仅展示一次,因此务必要及时对密钥进行保存,或者下载 CSV 文件以便安全存储。同时,别忘了勾选“我已知晓并保存 SecretKey”这一选项。完成以上步骤,您的 SecretId 和 SecretKey 就已成功获取完毕啦。
文档智能 OCR 的使用
OCR demo
点击此处,便可直接进入 OCR 的 demo 界面。在这个界面中,您可以充分测试其接口的各项能力,建议对所有功能都进行测试,以全面了解其性能。接下来,我将使用自己准备的几张图片,在 demo 中进行实际测试。
我打算用自己手写的字去测试一下它的识别效果。我的字可能有点潦草,个人感觉要是识别出现些许错误也是情有可原的,毕竟手写字体千差万别,尤其是我这种不太规整的书写风格,对识别系统来说是个不小的挑战。只要不是错误太多,基本上我还是能接受的。那我们现在就一起打开网页,看看它到底能识别成什么样吧!
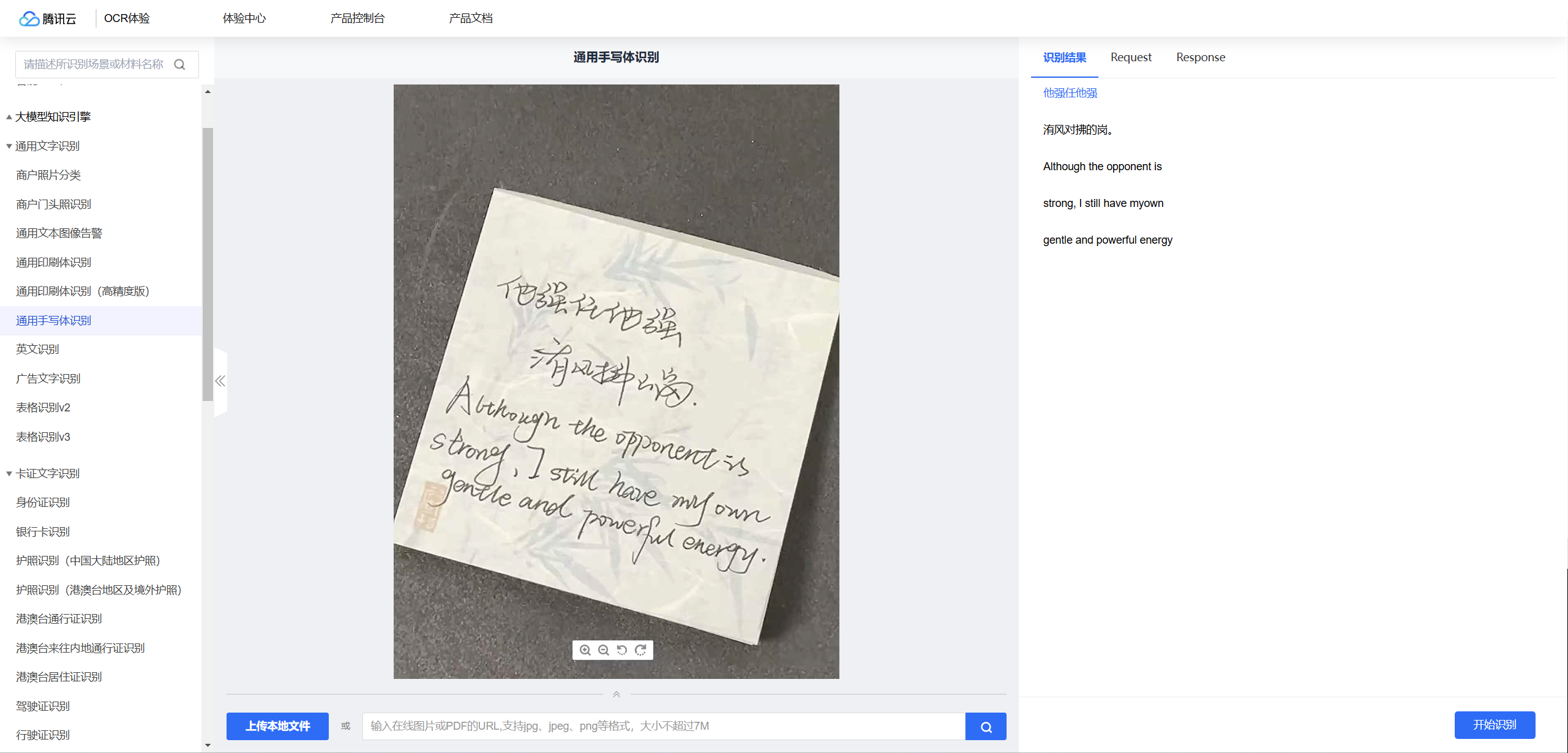
我们仔细观察后发现,虽然每行字的划分很清晰,但文字识别确实存在一些错误。不过这也情有可原,毕竟我写的字实在太像另一个字了。原话应该是“他强任他强,清风拂山岗”。
接下来,我将通过一本书的内页来进行识别测试,以检验其识别率的精准度。这本书是熊培云老师送给我的第一本书,它非常值得一读,我极力推荐大家去阅读。
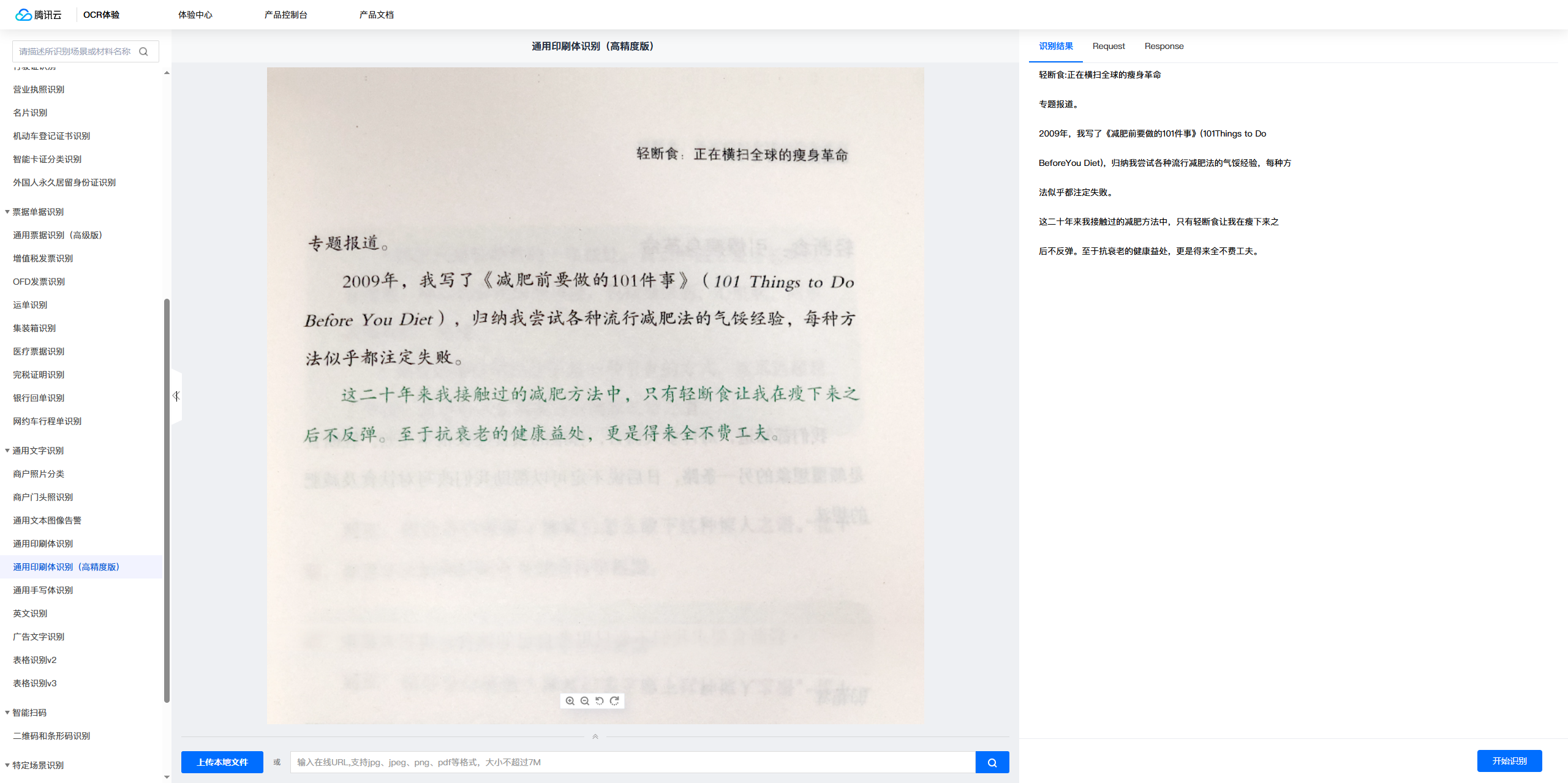
我们发现,此次识别的准确率相当高,几乎未出现任何错误。这充分证明了对于纯印刷体文字,其识别效果是非常出色的。
经过与源文档的细致比对,输出结果毫无瑕疵,图片等内容也均能精准识别,这足以证明其文档解析能力依旧卓越。我仅通过这三个演示,便足以略窥一二。那么,此次演示便暂且告一段落。不过,我也发现了一些待改进之处。例如,在复制公式时,并未保留其原有的格式。许多文档编辑软件都具备插入公式的功能,因此,我在此向产品团队提出一点小建议,希望能尽快实现对公式格式的复制支持。或者,当我们将鼠标悬停在公式上时,能自动弹出选项,让我们能够将其以公式格式复制,以便更便捷地导入腾讯文档等办公软件中,进一步提升使用体验。
既然我们已经通过 Demo 亲眼见证了其出色的实际效果,那么接下来是不是该轮到我们亲自上手部署一番了呢?也就是在自己的本地环境或者服务器上请求调用 OCR 的 SDK,从而真正实现文字识别的强大功能。值得一提的是,官方贴心地为多种编程语言都提供了详细的示例,这无疑为我们接下来的部署工作提供了极大的便利。
简单调用服务接口
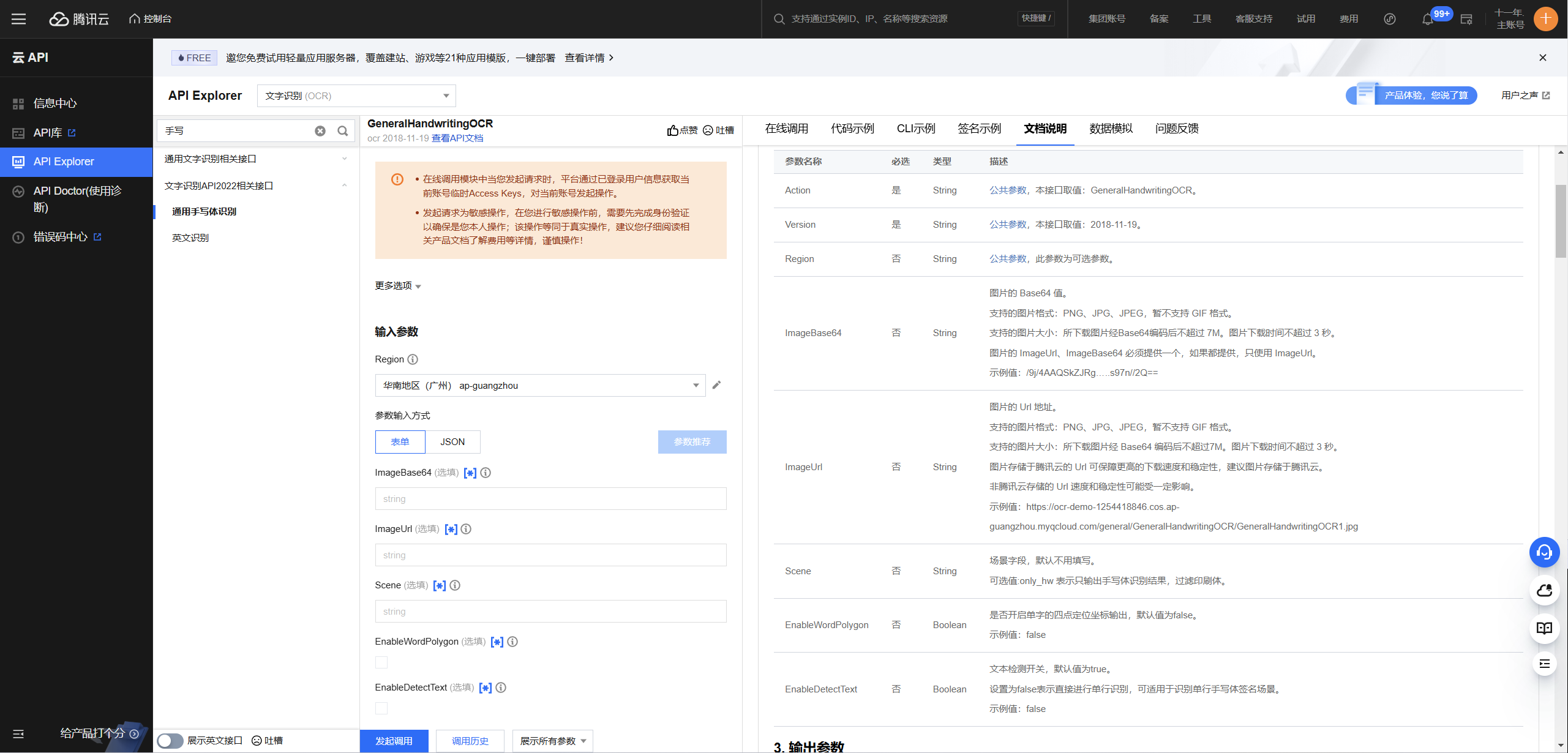
当我们访问这个页面(点击此处直达),您会发现我选择了手写识别作为演示功能。在页面的右侧,有一份文档说明,建议您详细阅读以获取更多信息。实际上,在使用过程中,您并不需要填写太多信息。最关键的部分是提供图片的 ImageBase64 值。 请注意,目前仅支持 PNG、JPG、JPEG 这三种图片格式,其他格式的图片将不被接受。这意味着您上传的图片必须是上述格式之一。接下来,我将为您演示如何操作。

您已经选择了要上传的图片,接下来的关键步骤是获取这张图片的 ImageBase64 值。您可以轻松地通过在线工具或编程语言中的库来完成这一转换过程。为了简化操作,这里我将直接展示如何使用在线工具来转换图片为 ImageBase64 值。
转换过程非常简单,您只需上传您的图片到在线转换工具,它将自动为您生成 ImageBase64 编码。下面,我将展示这张图片转换后的 ImageBase64 值,您可以将其用于上传。同时,我也鼓励您尝试使用自己的图片进行转换,体验这一过程。
由于 ImageBase64 编码的字符数量过于庞大,导致无法在编辑器内完整展示,因此已将其以文件形式附上。您可自行下载该文件获取完整的编码内容。至此,我们已成功获取到 ImageBase64 编码,接下来的操作便十分简便。您只需将编码粘贴至相应位置,切换到“在线调用”选项卡,然后单击“发送请求”按钮,即可开启实际效果测试,直观地查看调用结果。
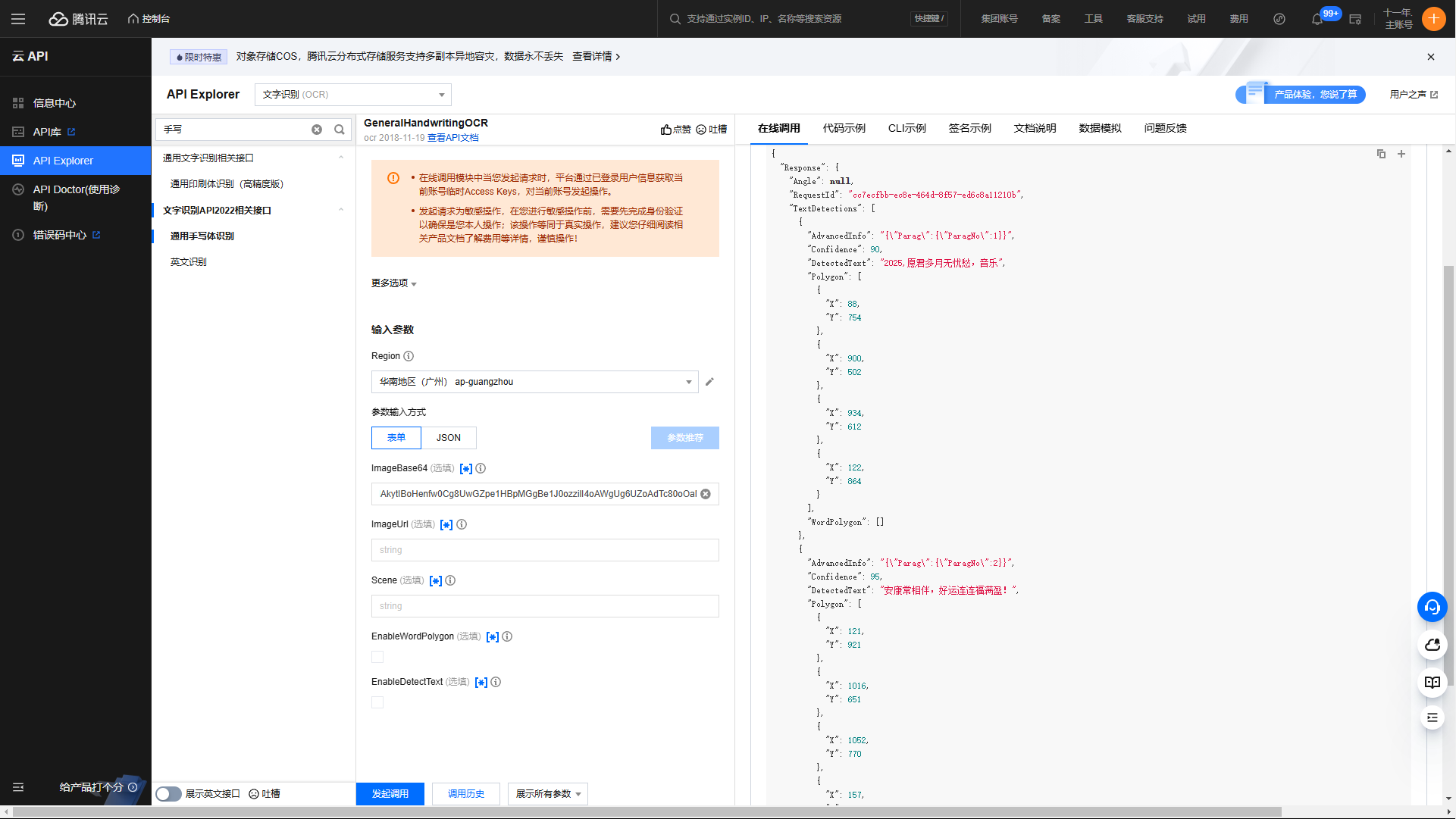
当您完成上述操作后,输出结果便呈现在眼前。不过,正如您所言,由于您的字迹较为潦草,导致这部分内容的识别效果并不理想,而其他文字的识别则毫无问题,准确无误。
此时,您可以留意到选项卡右侧有一个“代码示例”的入口。点击进入后,您会发现这里提供了多种编程语言的示例代码,涵盖了Golang、Python、Java、C++、node.js、PHP、.Net等。这些丰富的示例代码无疑为我们的开发工作提供了极大的便利,让我们能够更加便捷地将相关功能集成到自己的项目中,大大提高了开发效率。
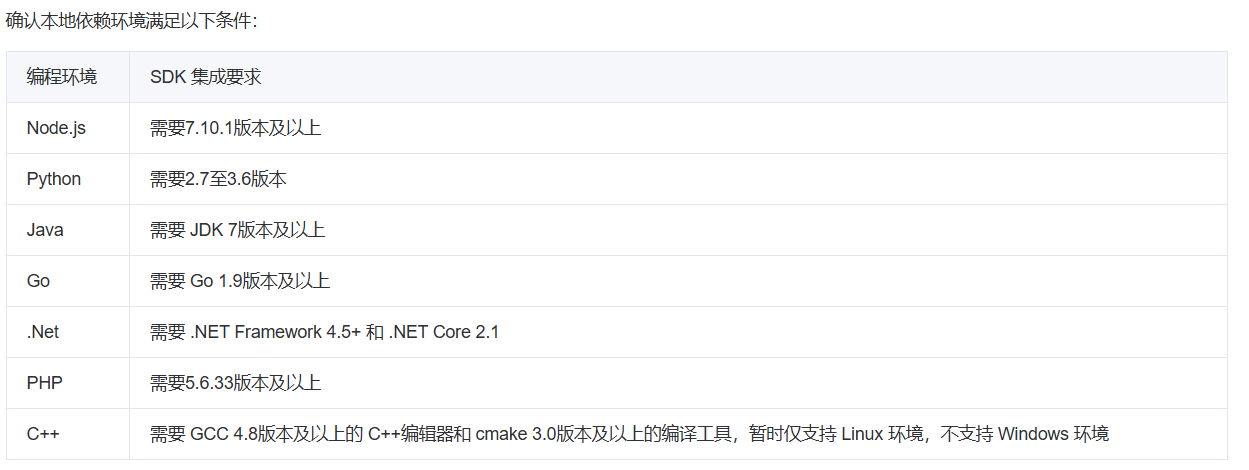
在进行后续操作之前,务必要留意本地依赖环境的版本号。请确保安装与本地依赖环境相匹配的腾讯云文字识别SDK版本,这是保障服务能够稳定、高效运行的关键前提。只有版本适配,才能避免因环境差异导致的兼容性问题,从而确保文字识别功能在本地环境中顺畅地发挥其应有的作用。
1. 安装依赖
pip install Flask tencentcloud-sdk-python
2. 创建 Flask 应用 (app.py)
from flask import Flask, request, render_template, jsonifyimport jsonimport base64from tencentcloud.common import credentialfrom tencentcloud.common.profile.client_profile import ClientProfilefrom tencentcloud.common.profile.http_profile import HttpProfilefrom tencentcloud.ocr.v20181119 import ocr_client, modelsapp = Flask(__name__)def initClient():cred = credential.Credential("您的SecretId", "您的SecretKey")httpProfile = HttpProfile()httpProfile.endpoint = "ocr.tencentcloudapi.com"clientProfile = ClientProfile()clientProfile.httpProfile = httpProfilereturn ocr_client.OcrClient(cred, "ap-guangzhou", clientProfile)@app.route('/', methods=['GET', 'POST'])def upload_file():if request.method == 'POST':f = request.files['file']if f:try:client = initClient()req = models.GeneralHandwriting OCR Request()params = {"ImageBase64": imageToBase64(f)}req.from_json_string(json.dumps(params))resp = client.GeneralHandwriting OCR (req)return jsonify(json.loads(resp.to_json_string()))except Exception as err:return jsonify({"error": str(err)})return render_template('upload.html')def imageToBase64(file_object):binary_data = file_object.read()base64_encoded_data = base64.b64encode(binary_data)base64_message = base64_encoded_data.decode('utf-8')return base64_messageif __name__ == '__main__':app.run(debug=True)
3. 创建 HTML 模板 (templates/upload.html)
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Upload Image for OCR </title><style>body {font-family: 'Arial', sans-serif;background-color: #f0f0f0;margin: 0;padding: 20px;display: flex;flex-direction: column;align-items: center;justify-content: center;height: 100vh;}h1 {color: #333;margin-bottom: 20px;}form {background: white;padding: 20px;border-radius: 8px;box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);}input[type="file"] {margin-right: 10px;border: 1px solid #ddd;border-radius: 4px;padding: 5px;}input[type="submit"] {background-color: #5c67f2;color: white;border: none;padding: 10px 20px;border-radius: 4px;cursor: pointer;transition: background-color 0.3s;}input[type="submit"]:hover {background-color: #4a54e1;}#result {margin-top: 20px;width: 100%;max-width: 600px;padding: 10px;background-color: #e9ecef;border-radius: 4px;overflow-x: auto;white-space: pre-wrap;word-wrap: break-word;}</style></head><body><h1>Upload Image for OCR </h1><form action="" method="post" enctype="multipart/form-data"><input type="file" name="file" required><input type="submit" value="Upload"></form><div id="result"></div><script>document.querySelector('form').onsubmit = function(event) {event.preventDefault();const formData = new FormData(this);fetch('/', {method: 'POST',body: formData}).then(response => response.json()).then(data => {document.getElementById('result').innerText = JSON.stringify(data, null, 2);}).catch(error => {document.getElementById('result').innerText = 'Error: ' + error.message;});};</script></body></html>
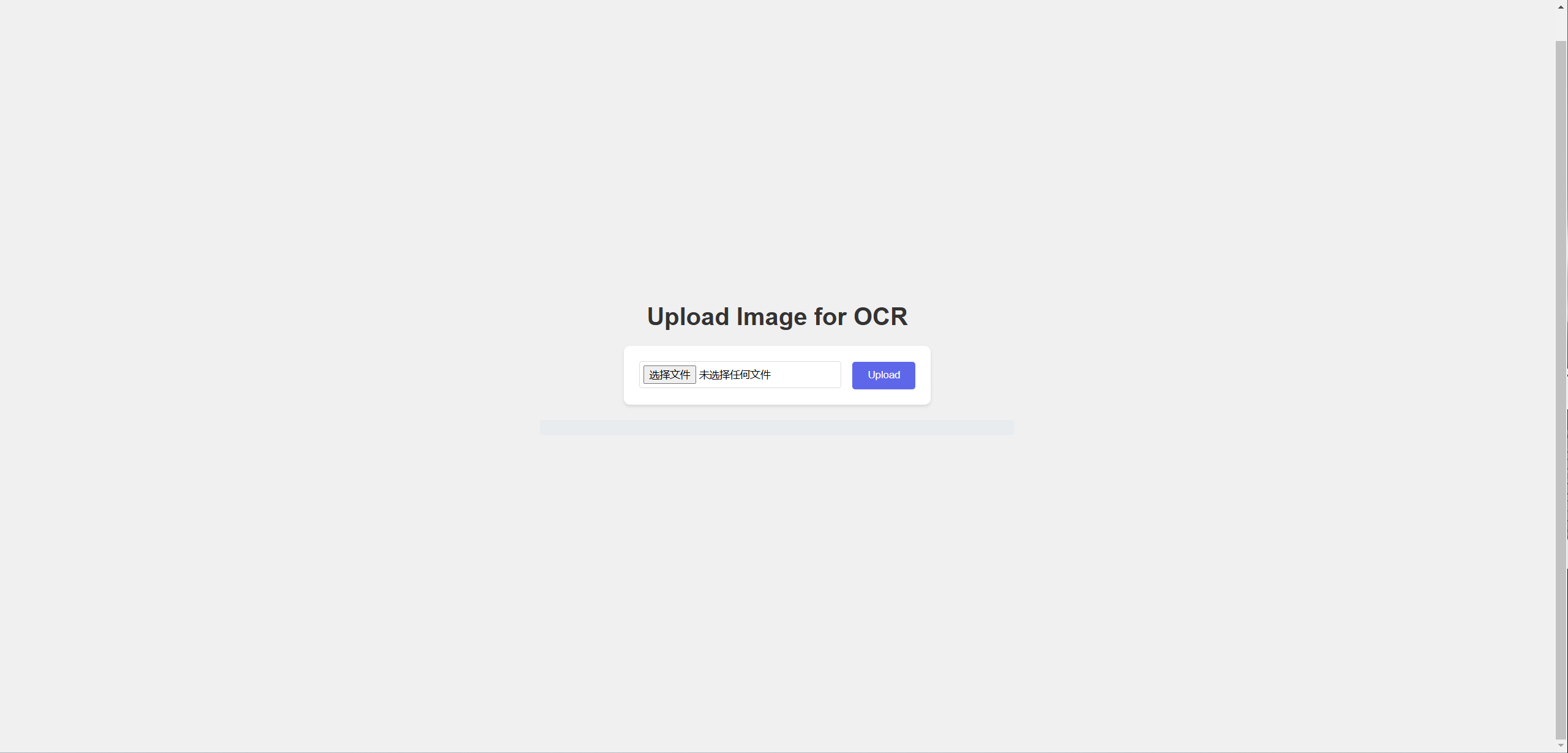
我打造了一个简洁的前端界面,使其不再显得空旷。虽说是随意构思,但仅用几行 CSS 和 JS 代码便实现了效果。经过严谨的实际测试,确认所有代码精准无误,在使用过程中未出现任何重大问题,大家可以放心直接使用。当然,如果觉得这个前端界面过于简单,也可自行重新设计一个。接下来,让我们检验一下它上传图片时是否能够准确识别吧。
这次我选取了之前另一张手写体图片来进行识别测试。在识别过程中,我同样对效果充满好奇,不知其准确度如何。现在,就让我们一同揭晓答案。图片也已附在下方,大家可以仔细查看,核对识别结果是否精准无误。

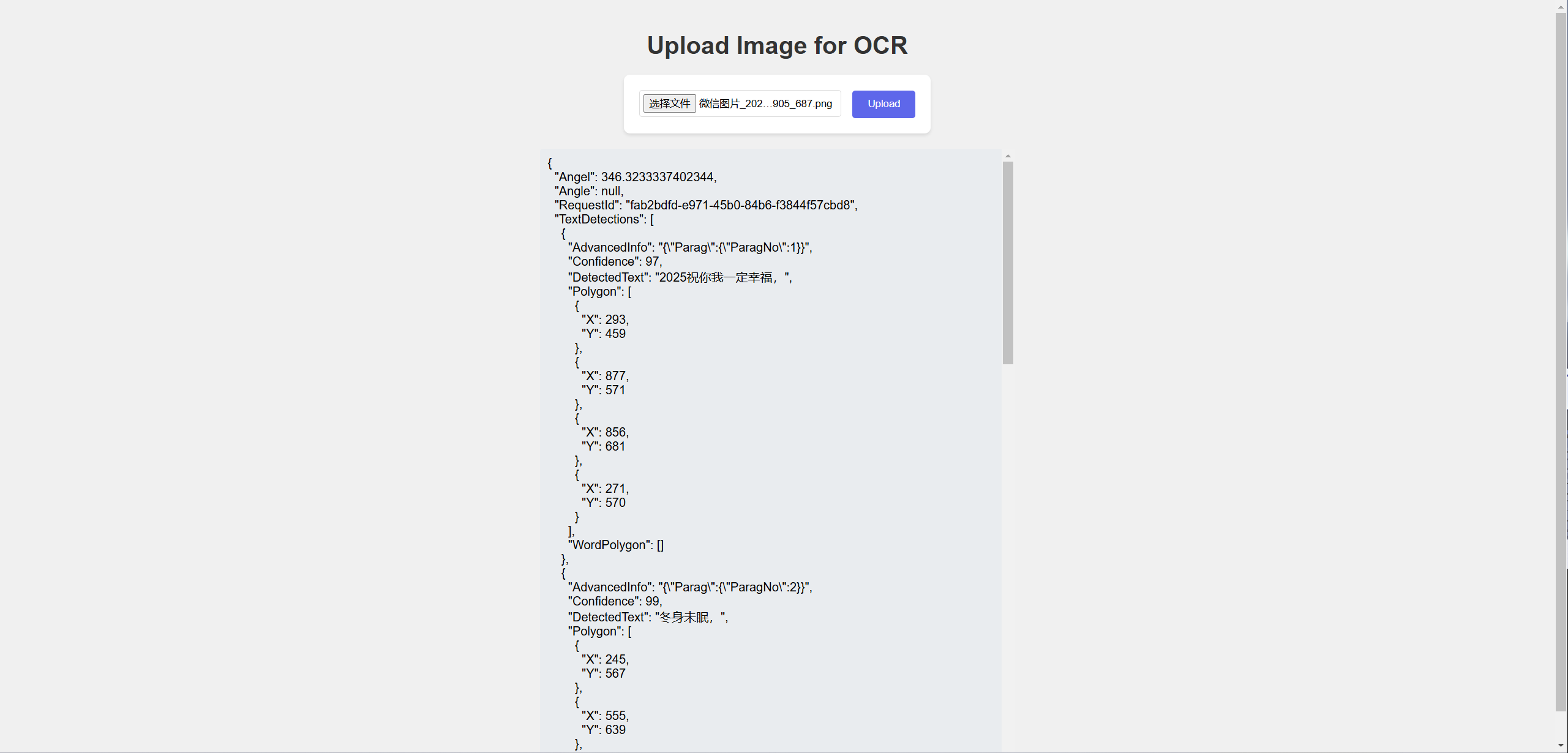
由于篇幅有限,这里仅展示这张图片。前端输出的样式,我个人认为相当出色,毕竟对于实用工具来说,简洁的界面往往是最佳选择。大家可以对比图片仔细查看,我经过核对,发现识别结果并无差错。因篇幅限制,只能展示这张图,但各位完全可以亲自动手尝试一番。 不得不提,OCR 的手写体识别功能确实表现出色,值得大力夸赞。这段话也是我送给各位的 2025 年祝福,愿大家在新的一年里,都能顺利达成自己心中的目标,收获满满。
实际上,我并未深入讲解接口调用的细节,原因在于我认为凭借参考代码示例与文档说明,大家已足以清晰地理解其原理与操作。因此,本文直接附上代码,未对代码进行逐行解释。但我认为,在学习与实践过程中,大家应多投入自己的思考,深入探究代码背后的逻辑与原理。
结语
在本文的探索之旅中,我们一同领略了腾讯云文档智能 OCR 的强大功能和应用潜力。从基础的文本识别到复杂的文档处理,这款产品无疑为我们的工作和生活带来了前所未有的便利。通过精心设计的前端界面和稳健的后端支持,我们不仅提升了交互体验,也确保了功能的高效与准确。
随着技术的不断进步,OCR 技术的应用场景将越来越广泛,其重要性也日益凸显。我们期待腾讯云文档智能 OCR 在未来能够持续优化,加入更多创新功能,如公式格式的保留、更丰富的API支持等,以满足用户日益增长的需求。
在此,我想对每一位读者表达最诚挚的感谢。感谢您们的关注与支持,也感谢您们在探索过程中的耐心与热情。希望本文能为您提供有价值的信息和启发,也希望您能在实践中发现更多 OCR 技术的魅力。



