本文介绍云数据仓库 PostgreSQL 如何选择表的分布策略。
选择表分布策略
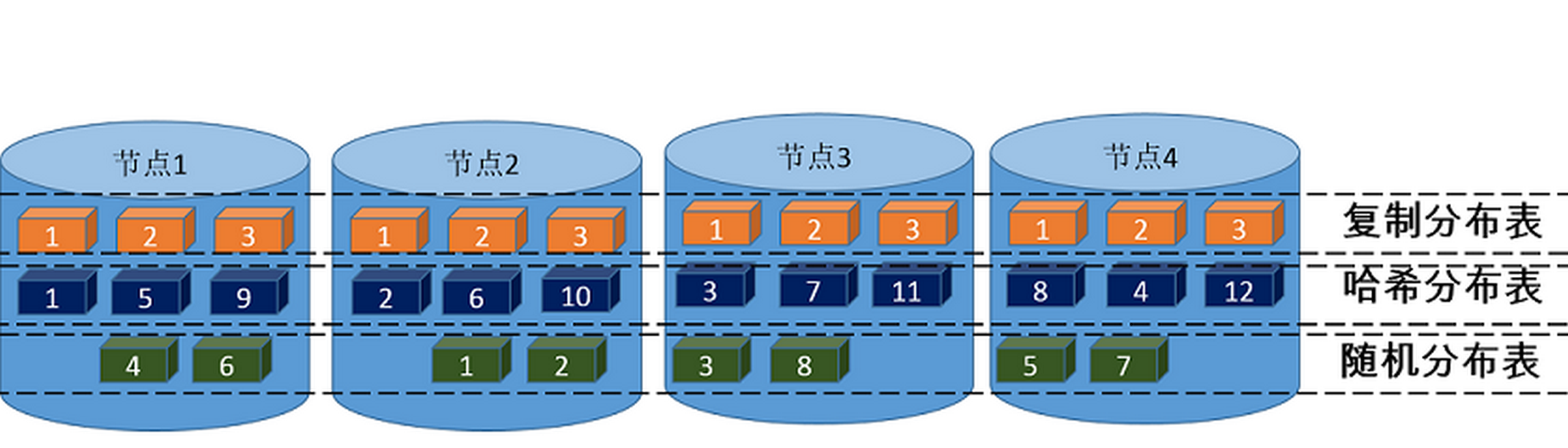
云数据仓库 PostgreSQL 支持三种数据在节点间的分布方式,按指定列的哈希(HASH)分布、随机(RANDOMLY)分布、复制(REPLICATED)分布。
CREATE TABLE <table_name> (...) [ DISTRIBUTED BY (<column> [,..] ) | DISTRIBUTED RANDOMLY | DISTRIBUTED REPLICATED ]
建表语句
CREATE TABLE支持如下三个分布策略的子句:DISTRIBUTED BY (column, [ ... ])指定数据按分布列的哈希值在节点(Segment)间分布,根据分布列哈希值将每一行分配给特定节点(Segment)。相同的值将始终散列到同一个节点。选择唯一的分布键(例如 Primary Key)将确保较均匀的数据分布。哈希分布是表的默认分布策略, 如果创建表时未提供 DISTRIBUTED 子句,则将 PRIMARY KEY 或表的第一个合格列用作分布键。如果表中没有合格的列,则退化为随机分布策略。DISTRIBUTED RANDOMLY指定数据按循环的方式均匀分配在各节点 (Segment) 间,与哈希分布策略不同,具有相同值的数据行不一定位于同一个 segment 上。虽然随机分布确保了数据的平均分布,但只建议当表没有合适的离散分布的数据列作为哈希分布列时采用随机分布策略。DISTRIBUTED REPLICATED 指定数据为复制分布,即每个节点(Segment)上有该表的全量数据,这种分布策略下表数据将均匀分布,因为每个 segment 都存储着同样的数据行,当有大表与小表join,把足够小的表指定为 replicated 也可能提升性能。
示例如下:
示例中的建表语句创建了一个哈希(Hash)分布的表,数据将按分布键的哈希值被分配到对应的节点 Segment 数据节点。
CREATE TABLE products (name varchar(40),prod_id integer,supplier_id integer)DISTRIBUTED BY (prod_id);
示例中的建表语句创建了一个随机(Randomly)分布的表,数据被循环着放置到各个 Segment 数据节点。 当表没有合适的离散分布的数据列作为哈希分布列时,可以采用随机分布策略。
CREATE TABLE random_stuff (things text,doodads text,etc text)DISTRIBUTED RANDOMLY;
示例中的建表语句创建了一个复制(Replicated)分布的表,每个Segment数据节点都存储有一个全量的表数据。
CREATE TABLE replicated_stuff (things text,doodads text,etc text)DISTRIBUTED REPLICATED;
对于按分布键的简单查询,包括 UPDATE 和 DELETE 等语句,云数据仓库 PostgreSQL 具有按节点的分布键进行数据节点裁剪的功能,例如 products 表使用 prod_id 作为分布键,以下查询只会被发送到满足 prod_id=101的 segment 上执行,从而极大提升该 SQL 执行性能:
select * from products where prod_id = 101;
表分布键选择原则
合理规划分布键,对表查询的性能至关重要,有以下原则需要关注:
尽量不使用复制表,复制表容易导致查询退化,反而出现查询变慢情况。
选择数据分布均匀的列或者多个列:若选择的分布列数值分布不均匀,则可能导致数据倾斜。某些 Segment 分区节点存储数据多(查询负载高)。根据木桶原理,时间消耗会卡在数据多的节点上。故不应选择 bool 类型,时间日期类型数据作为分布键。
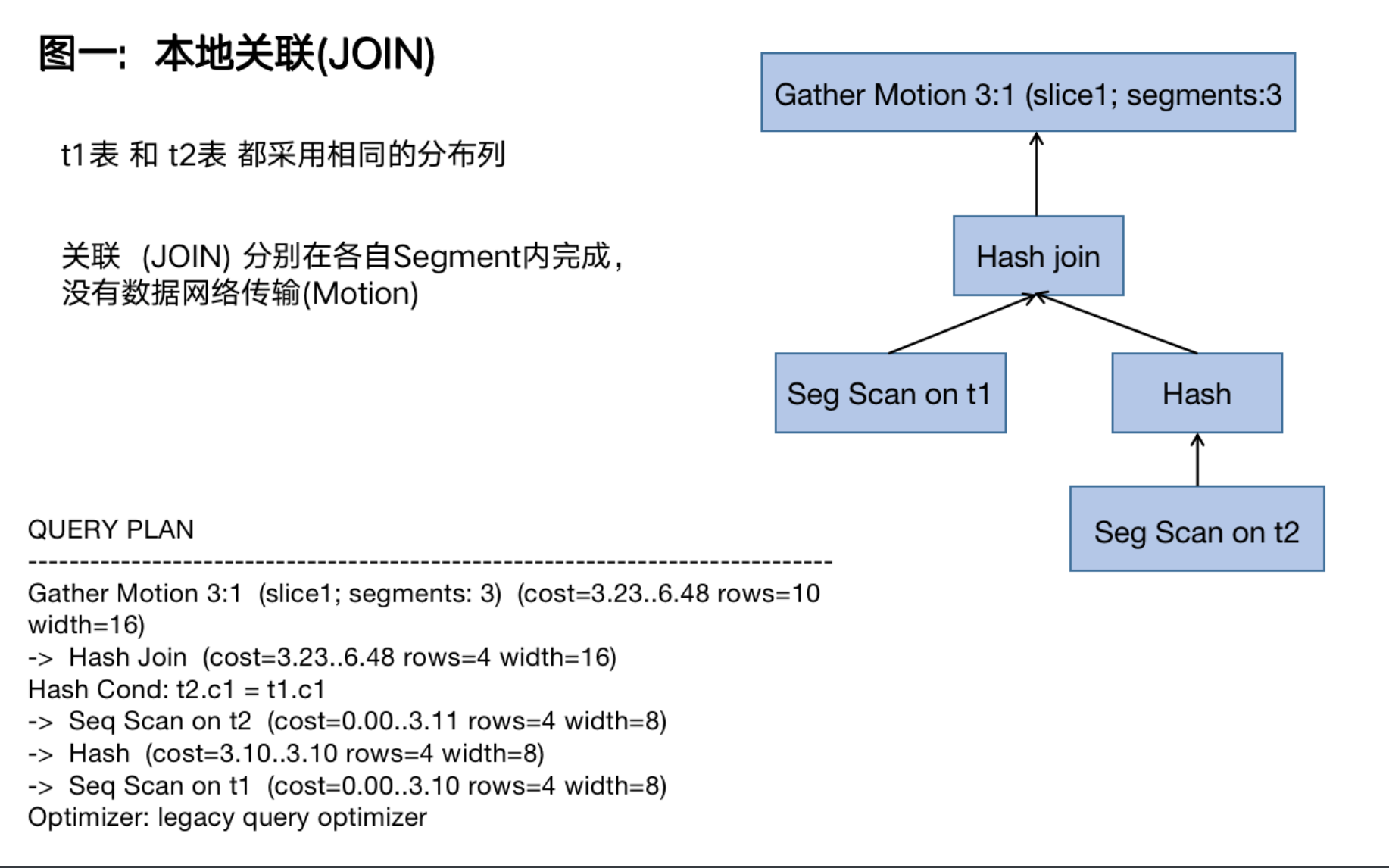
选择经常需要 JOIN 的列作为分布键,可以实现图一所示本地关联(Collocated JOIN)计算,即当 JOIN 键和分布键一致时,可以在 Segment 分区节点内部完成 JOIN。否则需要将一个表进行重分布(Redistribute motion)来实现图二所示重分布关联(Redistributed Join)或者广播其中小表(Broadcast motion)来实现图三所示广播关联(Broadcast Join),后两种方式都会有较大的网络开销。
尽量选择高频率出现的查询条件列作为分布键,从而可能实现按分布键做节点 Segment 的裁剪。
若未指定分布键,默认表的主键为分布键,若表没有主键,则默认将第一列当做分布键。
分布键可以被定义为一个或多个列。例如:
create table t1(c1 int, c2 int) distributed by (c1,c2);
表分布键的限制
主键和唯一键必须包含分布键。例如:
create table t1(c1 int, c2 int, primary key (c1)) distributed by (c2);会创建失败
分布键创建合理性分析
当分布键创建不合理时,会导致表数据出现数据不一致的问题,可以用如下语句查看数据分布情况:
create table t1(c1 int, c2 int) distributed by (c1);select gp_segment_id,count(1) from t1 group by 1 order by 2 desc;gp_segment_id | count---------------+--------0 | 10001 | 68(2 rows)
发现数据节点间差异过大时,可以修改分布键,以使数据更为均衡。
ALTER TABLE <table_name> SET WITH (REORGANIZE=true)DISTRIBUTED BY (<distribution columns>);



