当强化学习遇见泛函分析
原创

随着 DeepMind 公司的崛起,深度学习和强化学习已经成为了人工智能领域的热门研究方向。除了众所周知的 AlphaGo 之外,DeepMind 已经与著名的游戏公司 Blizzard 合作,准备挑战热门的即时战略游戏 StarCraft II。之前 DeepMind 已经成功地使用 Deep Learning 和 Reinforcement Learning 来搭建能够自行玩游戏的人工智能,并且成功挑战了 Atari 的一些游戏。虽然目前还没有成功地使用 AI 来战胜 StarCraft II 的顶尖职业玩家,但是 AI 却能够带给大家无穷的想象力和期待。
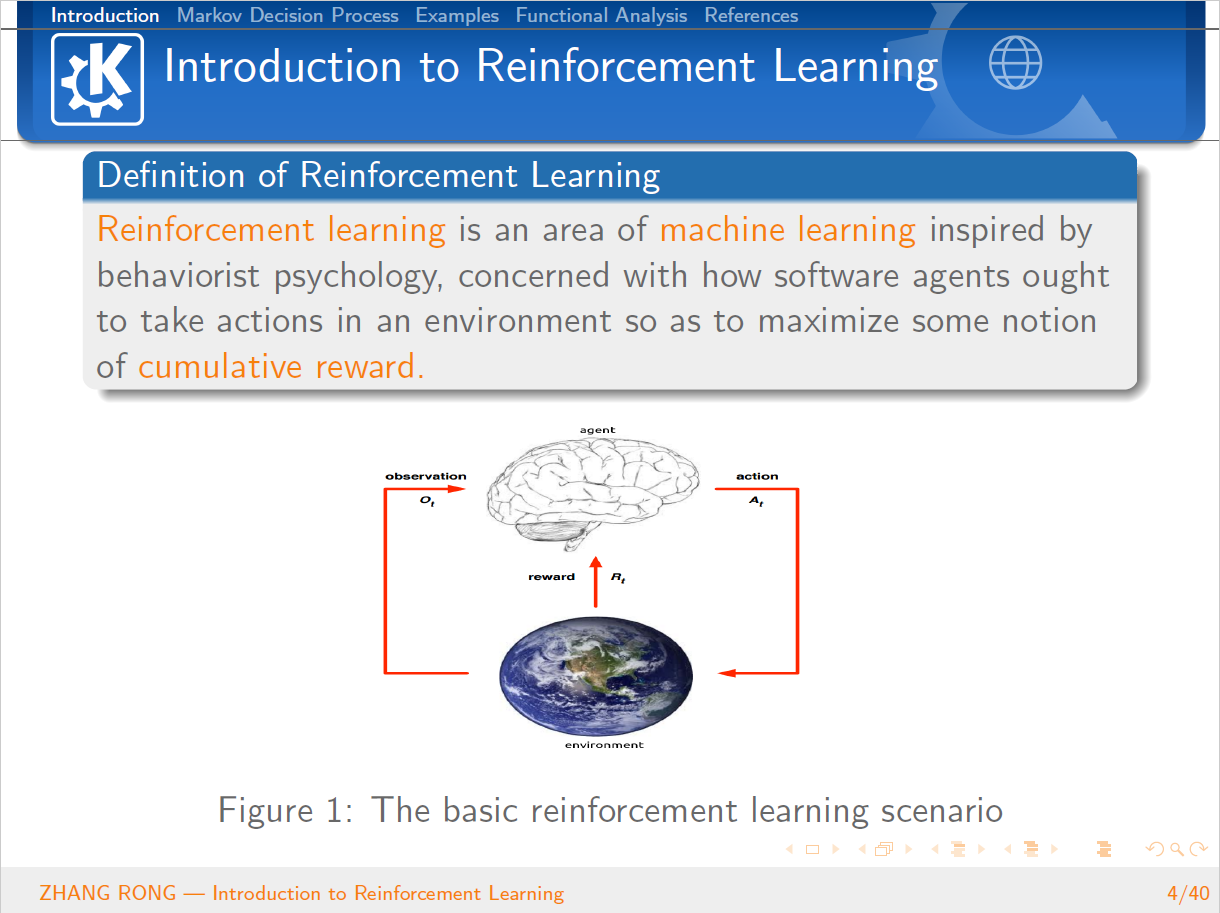
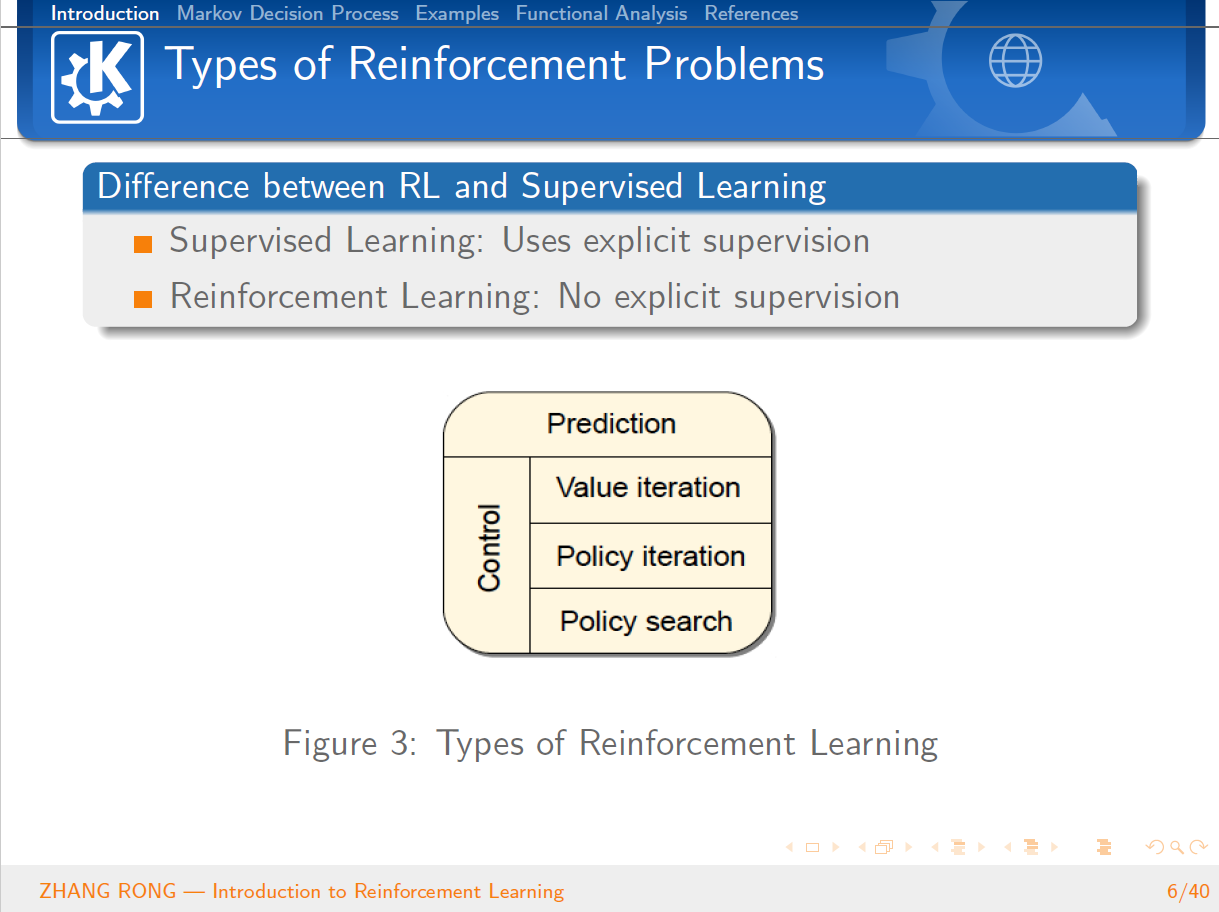
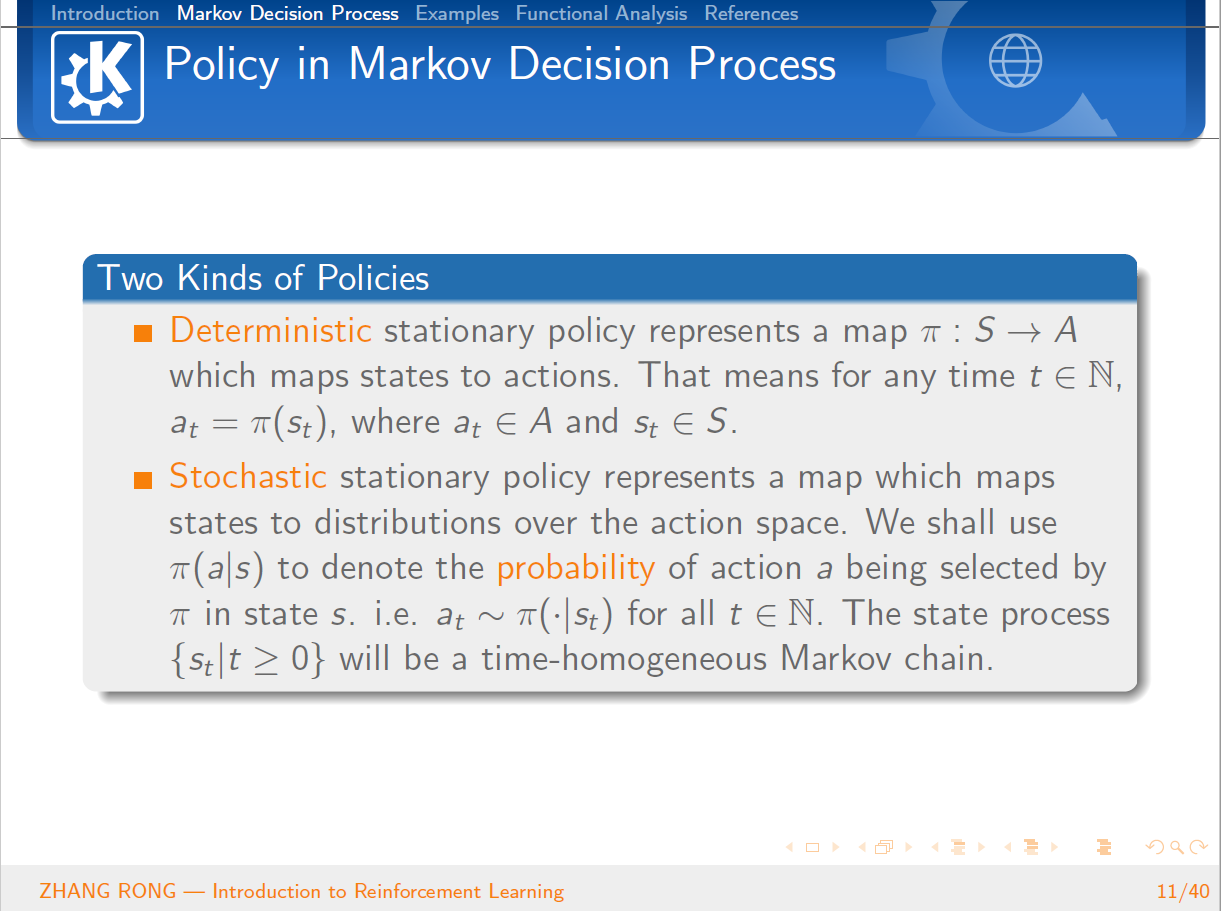
那么强化学习到底是什么呢?其实,强化学习其实是一个交叉学科的产物,本质上是为了学会自动进行决策,也就是“Decision Making”的问题。在计算机领域就体现为机器学习算法,在经济学领域就体现为博弈论的研究,在神经学领域体现在理解人类大脑如何做出决策。这一类问题本质上都是一个问题,人为什么能够并且如何做出最优决策。强化学习是一个序列的决策问题,需要选择一系列连续的行为,在这些行为结束之后能够获得最大的收益。一开始并没有任何标签告诉算法应该怎么做,是通过这个持续动作的行为来调整之前的结果。通过不断地持续调整,强化学习算法就能够学习到在什么样的情况下选择什么样的行为可以获得最好的结果。
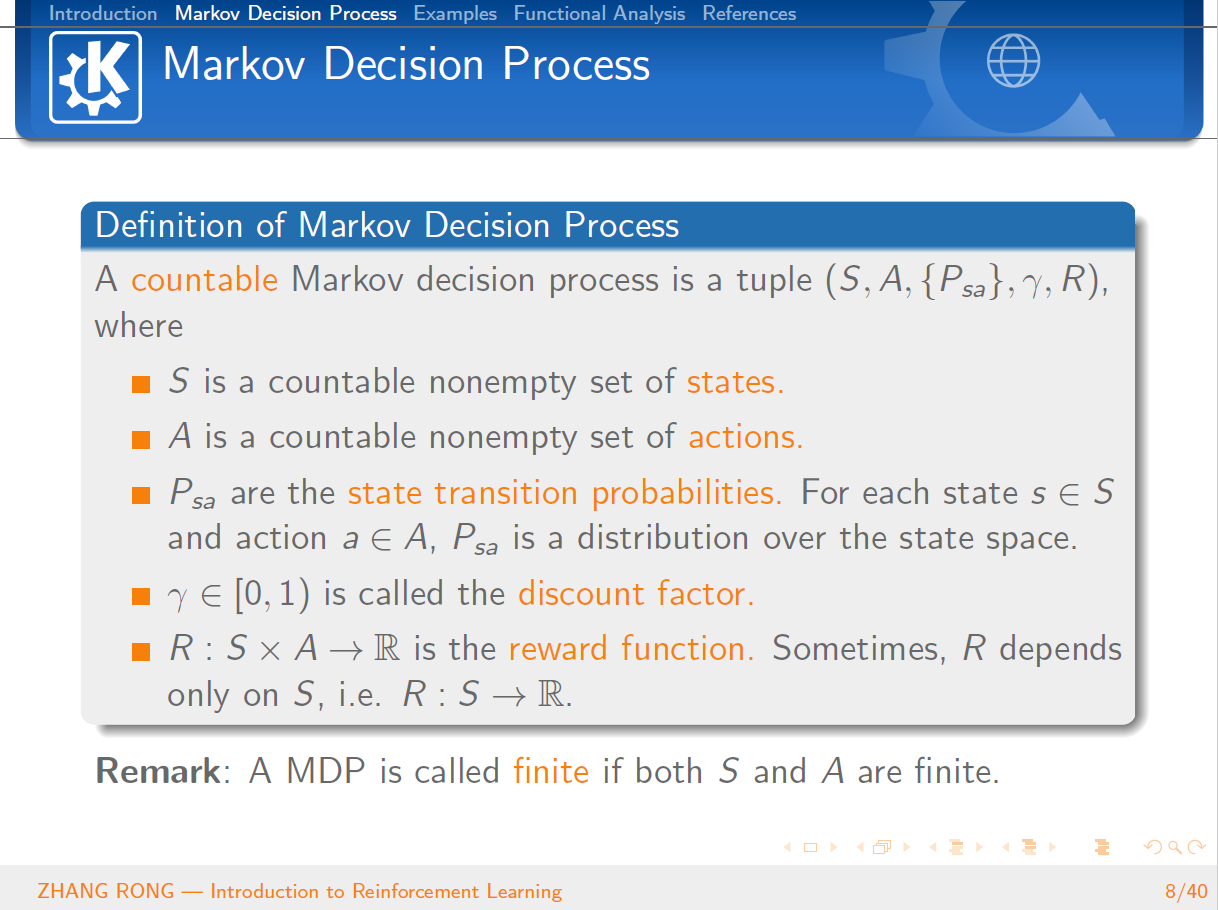
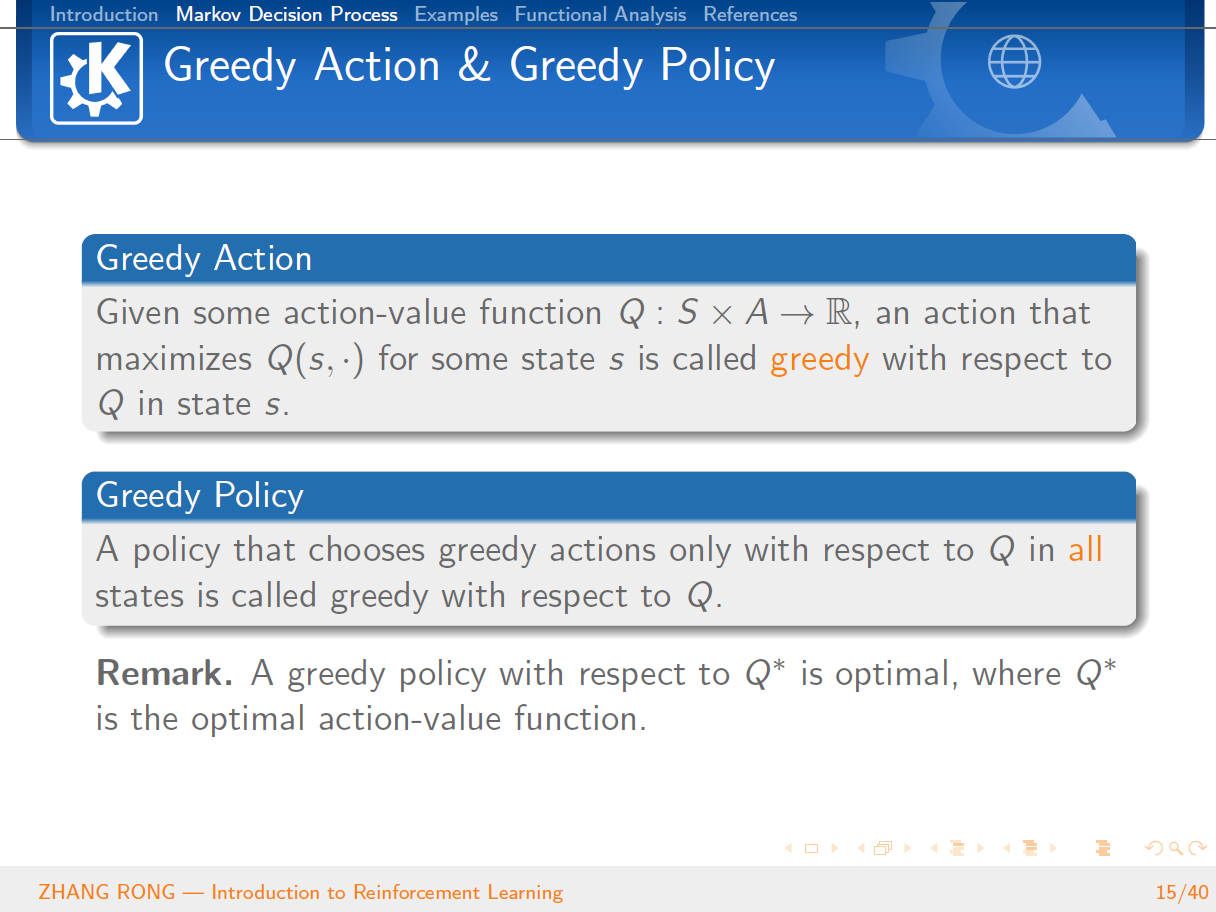
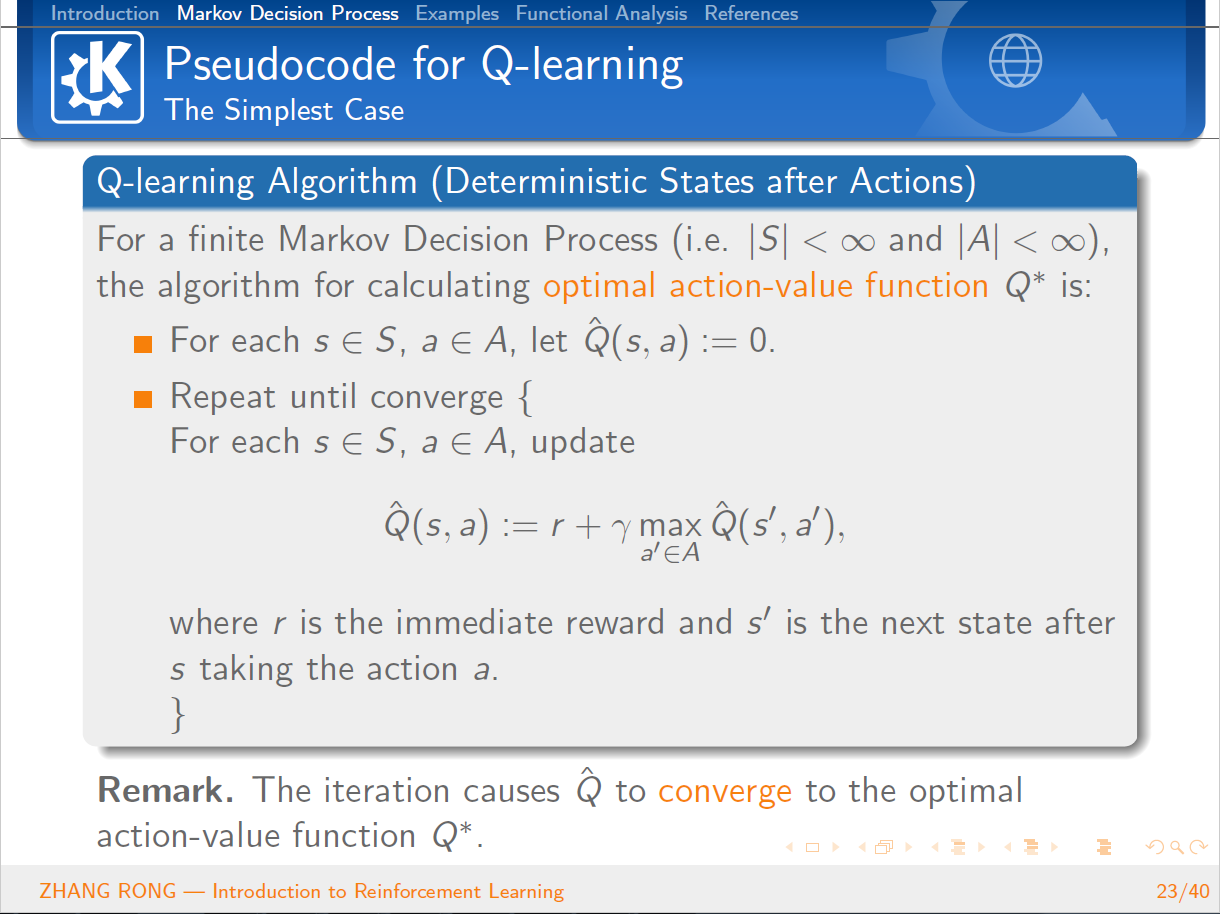
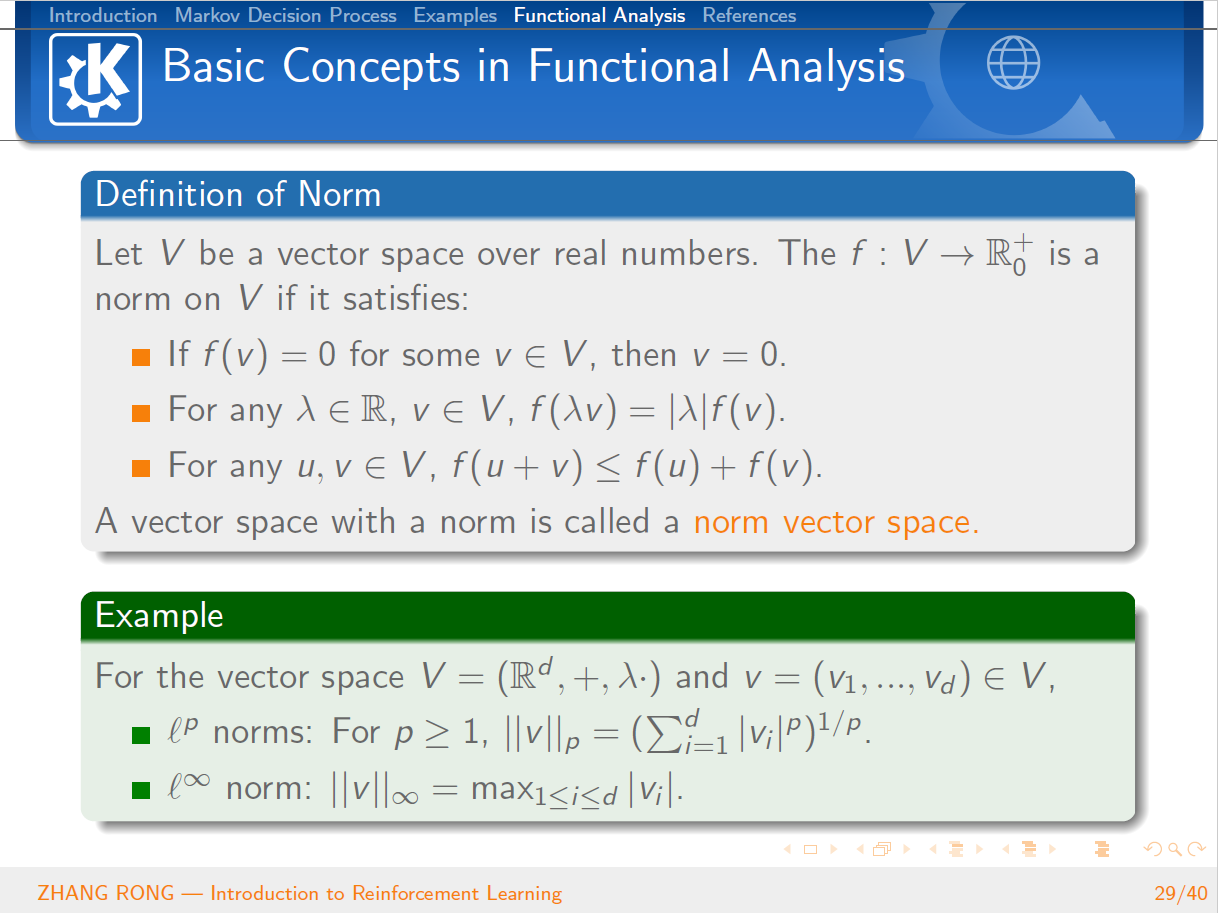
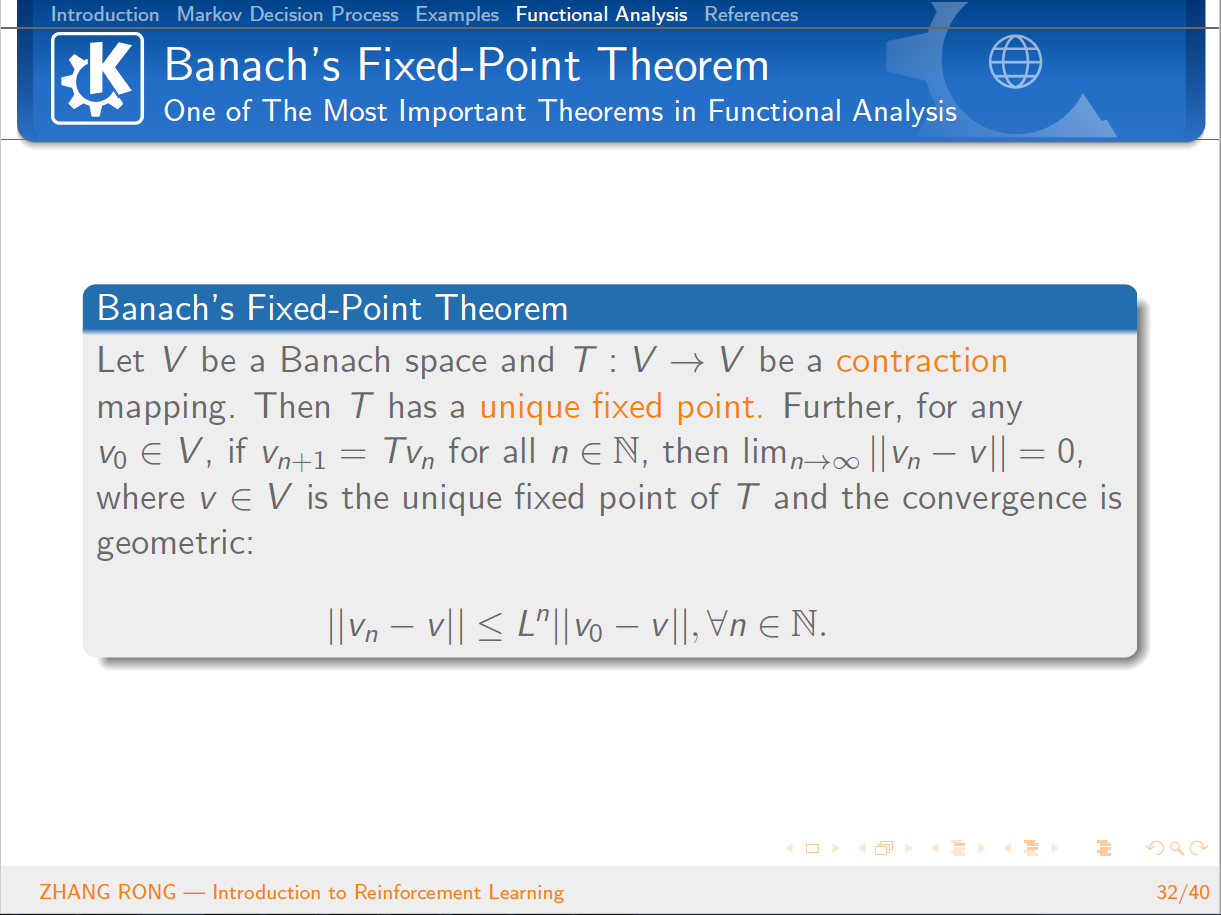
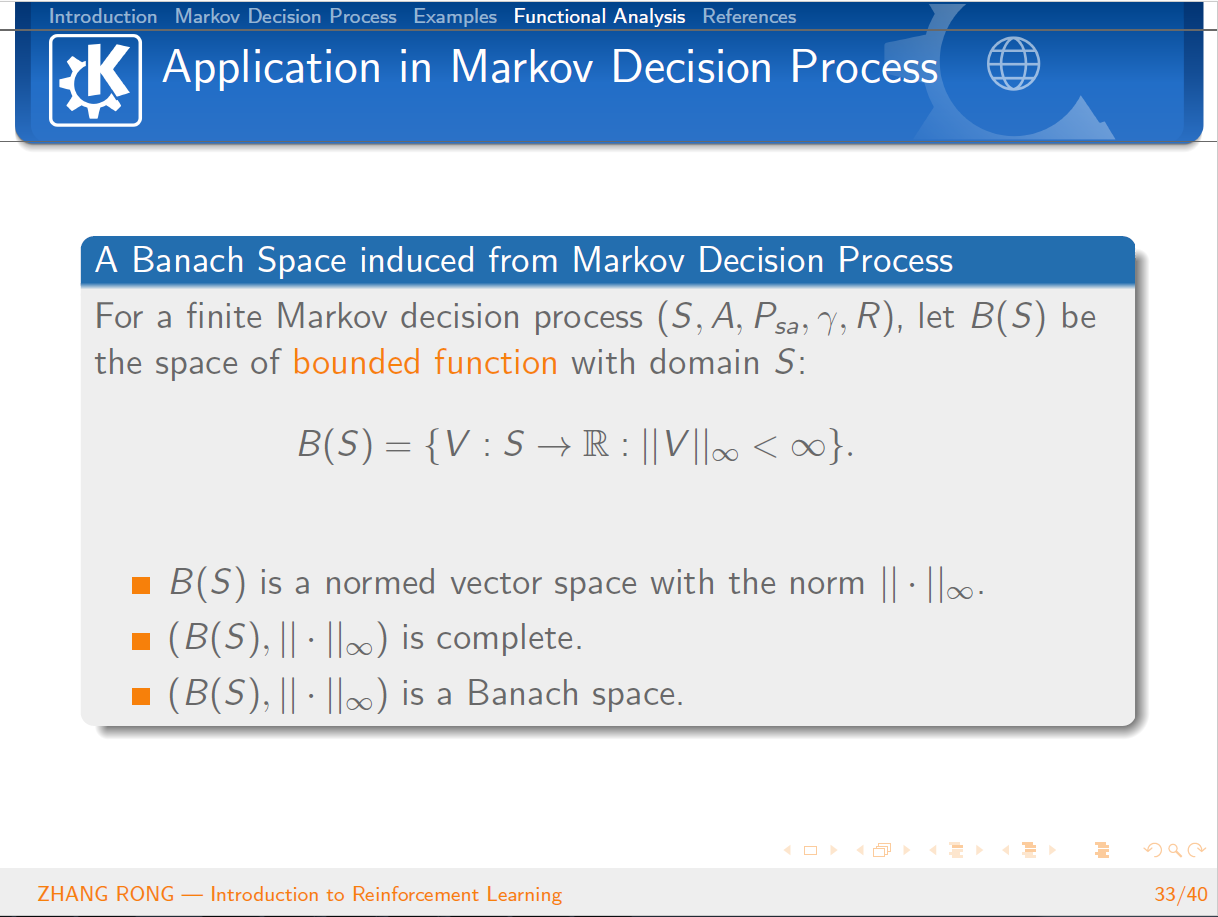
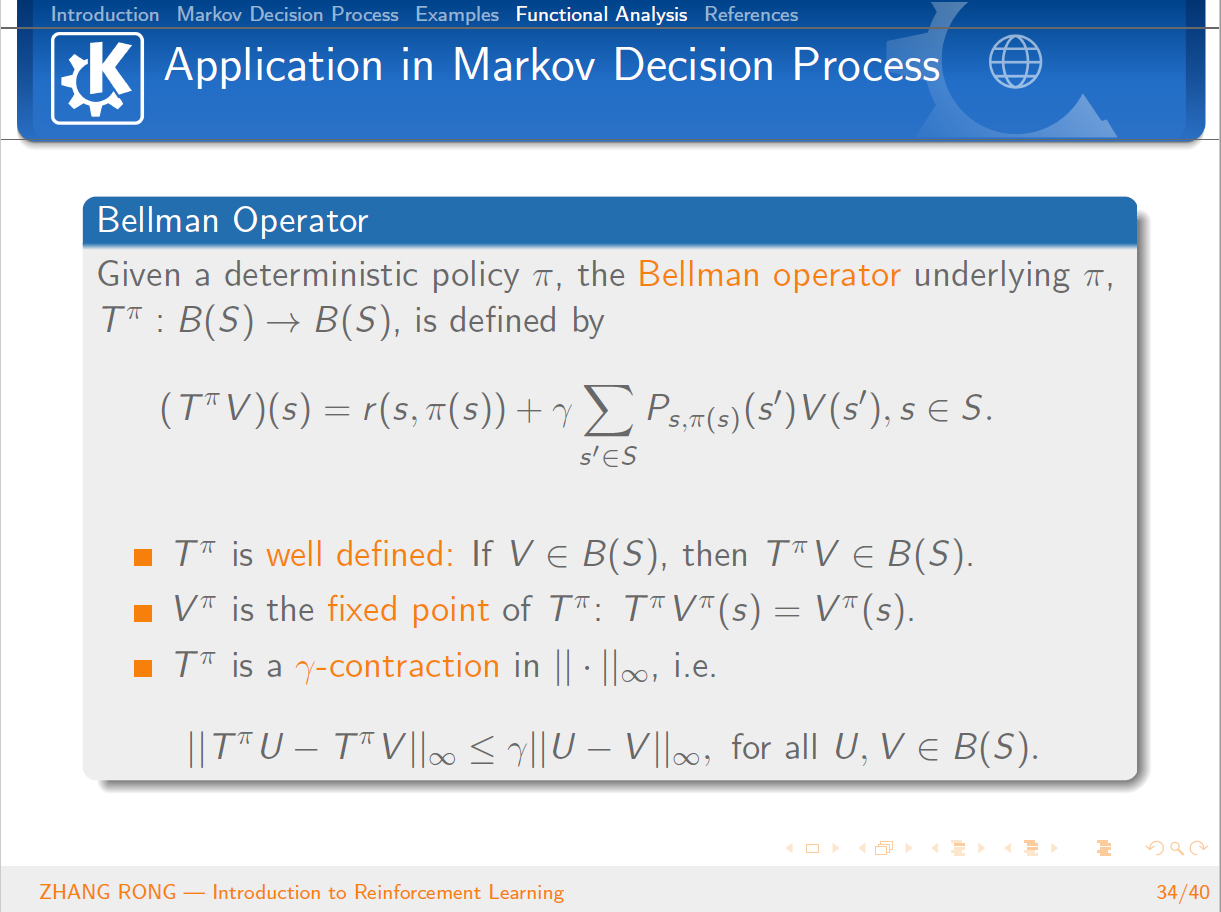
与机器学习相比,泛函分析已经是数学史上一门传统而经典的学科。泛函分析是分析学的一个分支,其研究的主要对象就是由函数构成的函数空间。它是从变分问题,积分问题,理论物理的研究过程中逐步发展起来的。那么泛函分析是怎么和机器学习中的强化学习结合到一起的呢?本篇文章将会从强化学习的定义出发,一步一步地给读者介绍强化学习的简单概念和基本性质,并且会介绍经典的 Q-Learning 算法。文章的最后一节会介绍泛函分析的一些基本概念,并且使用泛函分析的经典定理 Banach Fixed-Point Theorem 来证明强化学习中 Value Iteration 等算法的收敛性。

















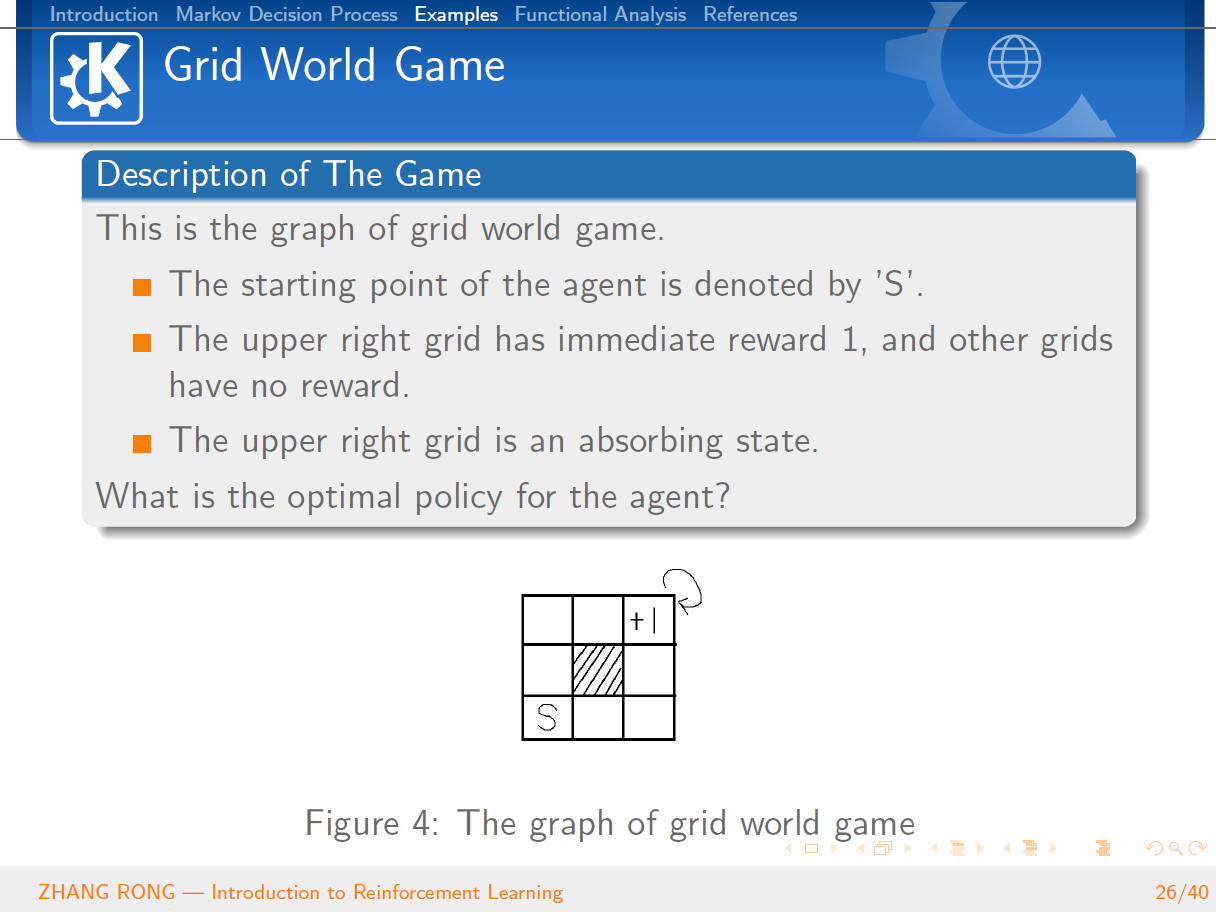
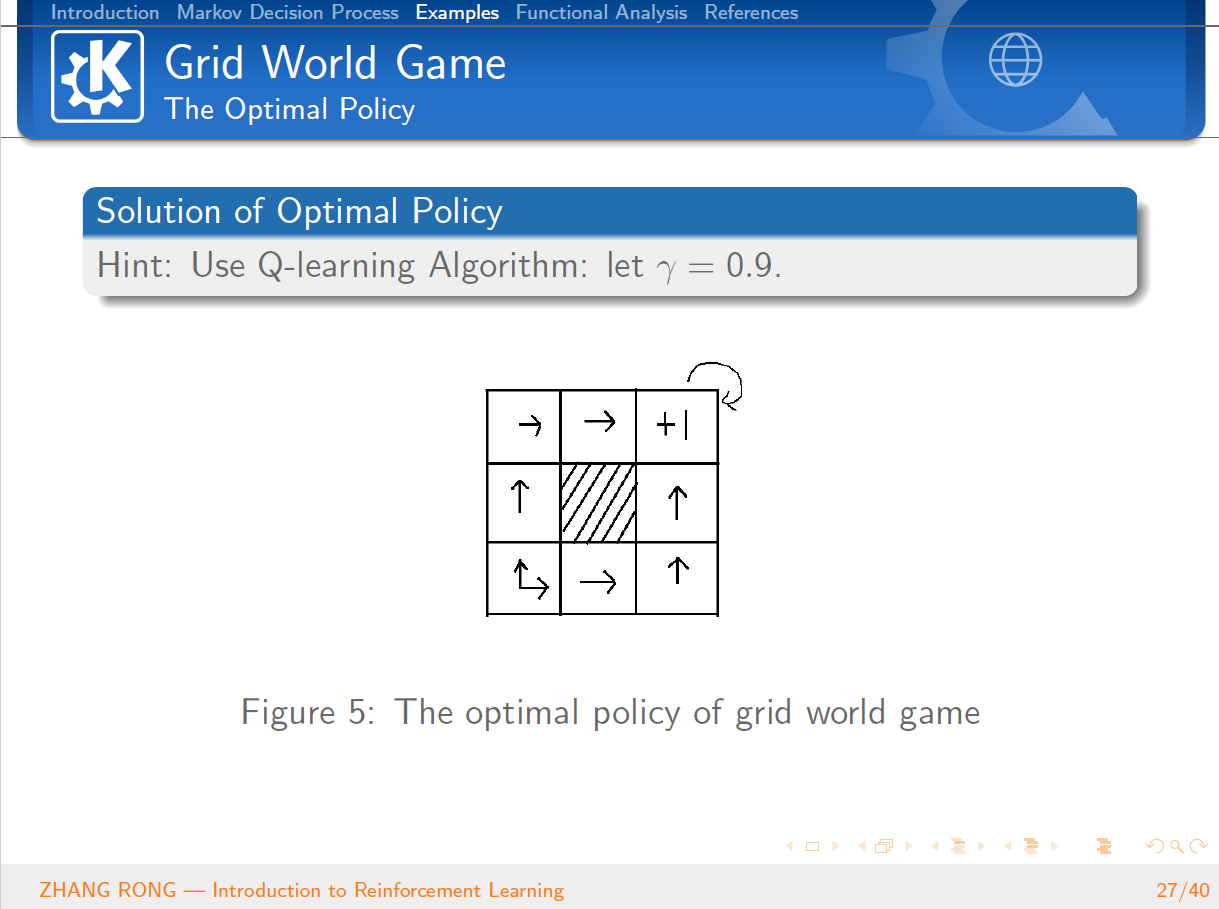





原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号