软硬件融合技术内幕 进阶篇 (5) ——云计算的六次危机(下)
软硬件融合技术内幕 进阶篇 (5) ——云计算的六次危机(下)

在前几期,我们发现,正如生产关系与生产力之间的相互作用那样,低效的虚拟化数据平面工作机制,会严重约束云计算生产力的发展。
因此,在Linux中,出现了virtio,vhost,vhost-user等技术。当软件的优化不适合NFV等业务虚拟化形态时,又出现了SR-IOV这种软硬件融合的技术。
SR-IOV是一种将一个物理PCI-E设备虚拟化为多个PCI-E设备的技术。
首先,我们来看一看PCI-E总线的结构:

如图,计算机中的PCI-E子系统,其总源头是根联合体 (root complex)。根联合体上的PCI-E总线可以直接连接到PCI-E设备 (endpoint),也可以通过PCI-E Switch分出多条总线连接更多设备。对于传统的PCI,PCI-X或HT (HyperTransit)设备,也可以通过PCI-E到传统PCI总线的桥(bridge)来转接1.
当操作系统初始化PCI-E子系统的时候,会对PCI-E子系统进行枚举,逐个发现PCI-E子系统上的各个设备。实际上,枚举的过程是驱动程序对读写根联合体配置空间 (Configuration Space)的相关寄存器实现的,根联合体会发出PCI-E的控制数据包,实现枚举的过程,最终遍历所有的PCI-E/传统PCI总线上所有的设备,获取其Vendor ID和Device ID,并为其分配BAR(Base Address Register)。
SR-IOV是Single Root I/O Virtualization的缩写,其对立面为MR-IOV,在此不详细解释。
支持SR-IOV的网卡芯片,每个PF(Physical Function)可以提供多个VF(Virtual Function),也就说是,一个物理PCI-E设备,会被系统视为多个Virtual Function。
我们在《云计算与虚拟化硬核技术内幕 (13) —— 独立自主,自力更生 (下)》里面提到过,利用SR-IOV功能,同时利用Intel VT-D功能,把基于SR-IOV的硬件网卡虚拟出的VF直通给VM,就可以让VM直接对网络发送数据包,而无需经过vSwitch,如下图所示:
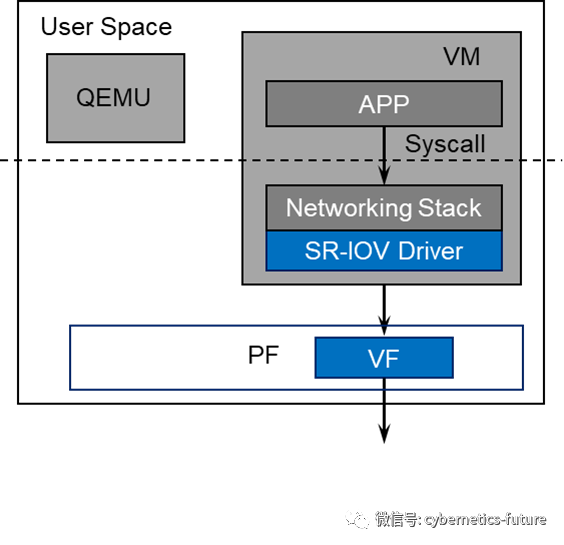
需要注意的是,由于VF是PF的一个虚拟化实例,而PF是物理网卡的一个物理端口,因此,从VF发出的每个数据包会直通到PF端口上的网线。
这带来的好处是不言而喻的。VM对外的数据收发无需经过OVS,大大缩短了数据收发路径。如果VM用于运行NFV,可以取得不错的效果。但是,对于非NFV的场景,会出现一个问题:所有VM之间的通信也需要经过物理交换机,如下图所示:
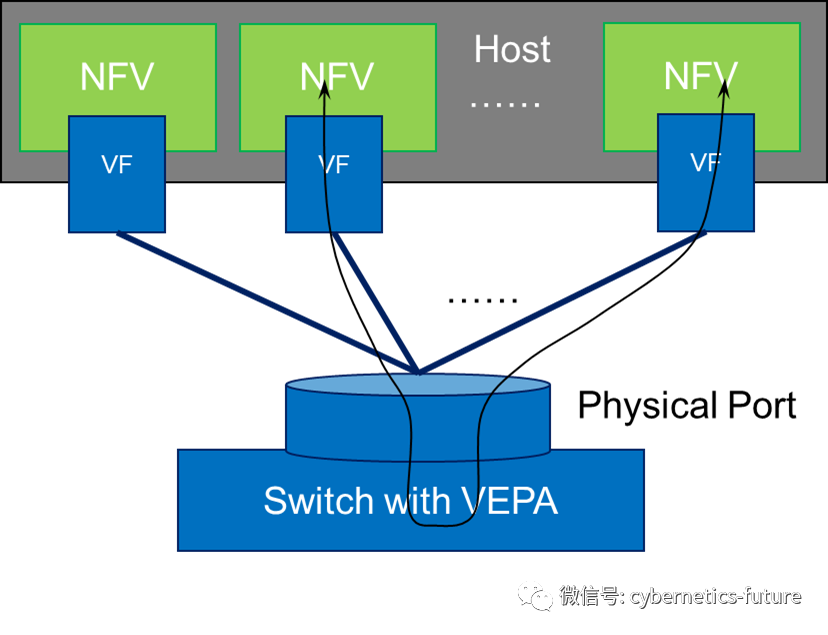
我们回忆一下《网络设备硬核技术内幕 交换机篇 2 御剑术大破飞龙探云手》,会发现,交换机工作在二层模式的时候,是不应当将一个端口上收到的数据包再从这个端口发回去的。但为了配合SR-IOV的工作,IEEE扩展了以太网802.3规范,制定了VEPA标准,让交换机能够将上图中来自SR-IOV的数据包再从原来的网线发送回去,俗称“发卡弯”。
当然,这种“发卡弯”转发会显著增加VM之间通信的时延,并且要求所有的TOR交换机都开启VEPA功能。同时,TOR交换机还需要执行双重标准——只对到服务器的下行端口开启VEPA,增加了配置工作量和调试排错难度。这就引发了第四次危机——SR-IOV&VEPA功能与传统流量模型的矛盾;
为了解决这一危机,网卡制造商们的思路也很简单直接:
在虚拟化的最初设计中,网络路径是 VM->虚拟网卡->TAP-vSwitch,
而SR-IOV的VF代替了虚拟网卡->TAP,那么,如果我们在支持SR-IOV的网卡中,实现vSwitch的功能,不就解决了这一问题吗?
如图,以Mellanox CX4为代表的初代“智能网卡”,在网卡中除支持SR-IOV功能外,还集成了NIC Switch,各个SR-IOV VF发出的数据包可以通过NIC Switch进行高效地交换。
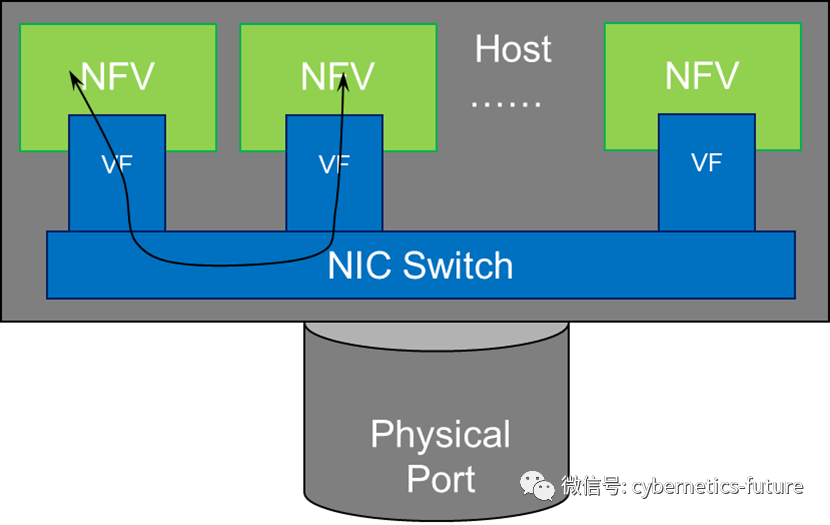
在VMWare,KVM,RHEV等虚拟化平台中,这种实现方式倒是也可以解决前文所述的第四次危机。但是,当虚拟化平台的规模扩张,并向多租户云平台过渡的时候,一个问题就出现了:
为了从网络层隔离不同租户的实例,避免不同租户的VM可互通,在云计算平台中需要采用Overlay网络,也就是通过VXLAN或GRE等隧道技术,实现多租户的网络隔离。在没有应用SR-IOV技术时,这种Overlay的隧道封装/解封装,是在OVS上实现的,而SR-IOV+NIC-Switch却要将这种封装和解封装放到网卡实现。由于各大公有云运营方往往基于自身业务需求,对VXLAN或GRE做一些改造,如GENEVE封装或VXLAN-NSH封装等,这对网卡内嵌的vSwitch的处理能力就提出了新的挑战,并且带来了第五次危机——网卡内嵌的NIC-Switch硬件固化处理能力,与云网络隧道封装的演进迭代之间的矛盾。
那么,如果我们做一个妥协,只有在运行NFV的宿主机上使用SR-IOV,而跑虚拟机或容器的宿主机集群退回到基于DPDK的vhost-user模式呢?
我们在《云计算与虚拟化硬核技术内幕 (16) —— 抄作业的熊孩子》里面提了,由于DPDK采用轮询机制,需要独占若干CPU核心作为网络处理专用。
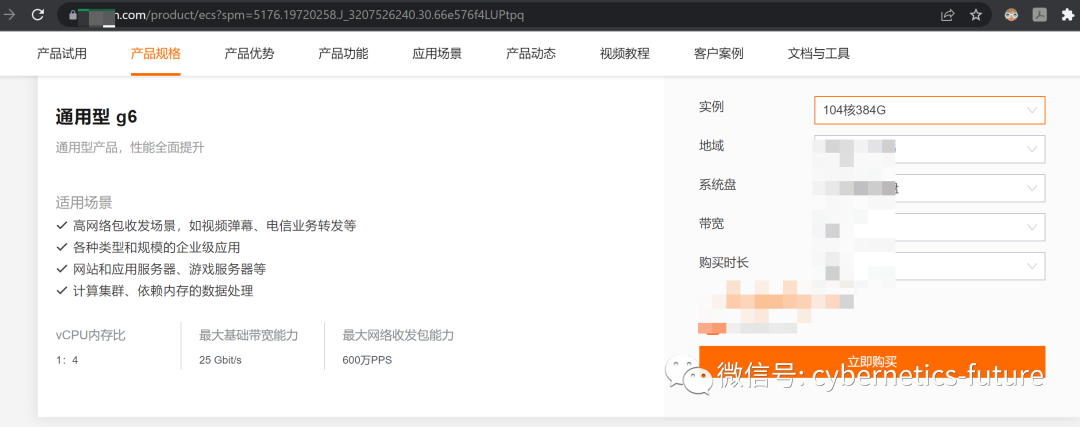
如图,某不大正规的公有云上,通用性g6云服务器运行在整机128 HT的服务器上,创建实例时却只能创建104核,就是因为其中24个HT被vhost-user占用了,包括网络处理的DPDK和存储处理的SPDK。
这就是所谓的“数据中心税”的另一种表现形式。

在刚才举的案例中,数据中心税的税率为24/128 = 18.75%,高于国内常见的增值税税率,已接近国民党反动政权的税率水平。
更有甚者,由于宿主机上的SPDK与DPDK占用的核是预分配的,在尚未售卖虚拟机的时候,系统已经预征收了这一笔“数据中心税”。这就造成了云计算的第六次危机——SPDK和DPDK占用的资源,与数据中心可售卖资源的矛盾。
显然,这种提前征税的行为,与最黑暗反动的军阀政权一样,必将被正义所推翻!
那么,如何聚集正义的力量,解决“数据中心税”的问题,从而战胜危机呢?
请看下回分解。
腾讯云开发者
