软硬件融合技术内幕 进阶篇 (14) —— 世界大同的梦想 (上)
软硬件融合技术内幕 进阶篇 (14) —— 世界大同的梦想 (上)

在上期,我们通过简要介绍了虚拟机通过VirtIO访问SmartNIC,实现虚拟机在是否带有SmartNIC的宿主机之间迁移的方案。实现虚拟机跨宿主机迁移以后,我们就可以把带有SmartNIC的宿主机和普通宿主机组成一个资源池,统一进行资源的调度和分配。
然而,这种资源池的建立,实际上只解决了CPU算力的资源池化的问题。另一个在虚拟化和云计算中长期困扰工程师们的问题还没有得以解决。
这个问题就是内存的共享。
让我们将眼光转回2011年。
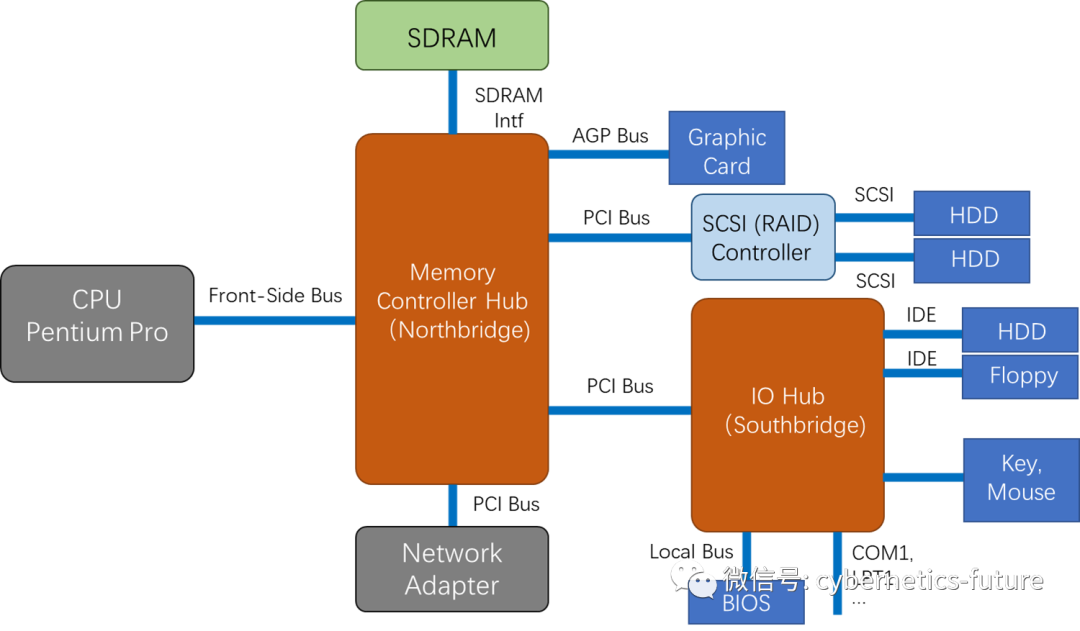
2011年,计算机的世界中掀起过一次革命。在此之前,CPU本身不具备直接使用动态内存(DRAM)的能力,需要通过前端总线(FSB)连接到北桥 (North Bridge),北桥中的DRAM控制器会将前端总线上发出的地址和数据信号,转换为DRAM读写时序。
此阶段的计算机系统硬件架构图如下图所示:
而对于多路服务器的场景,会有多个CPU连接到北桥上,如下图所示:
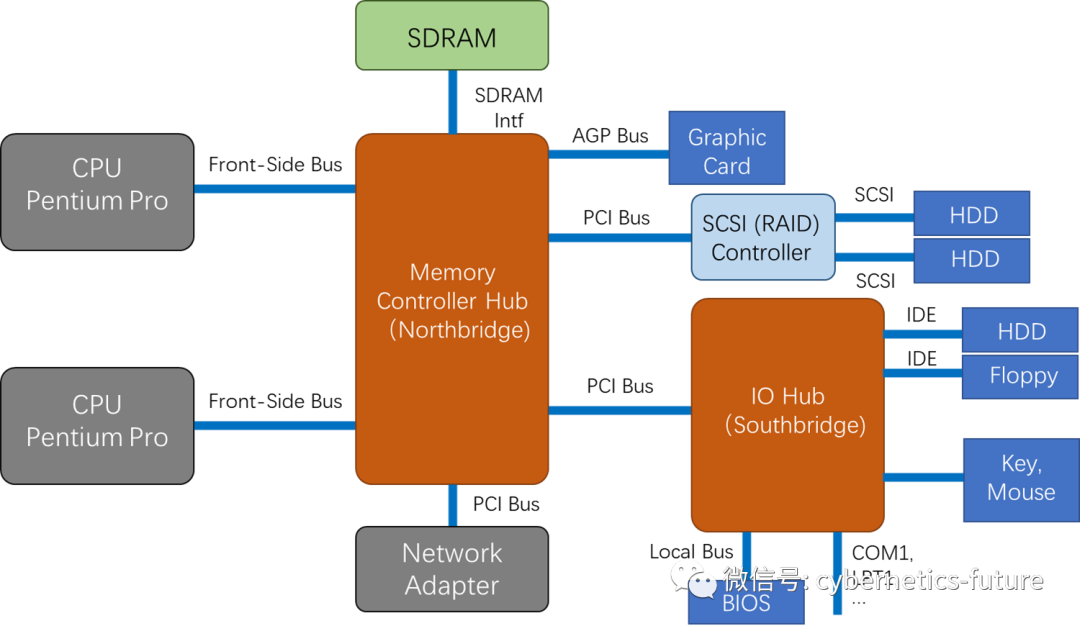
从图中可以看出,2颗CPU对内存的访问,都是通过北桥访问的,那么,其带宽和时延也是基本同等的。这种内存访问方式叫做UMA (Uniform Memory Access)。UMA方式的缺陷也是很明显的:当CPU的核数上升,北桥有可能成为制约内存访问性能的瓶颈。此外,在系统集成度提升的大趋势下,让北桥和CPU集成在一起,也成为了计算机系统发展的趋势。
2011年,Intel推出了Sandy Bridge架构,将北桥集成进了CPU,从而让整机硬件架构演变成了下图:
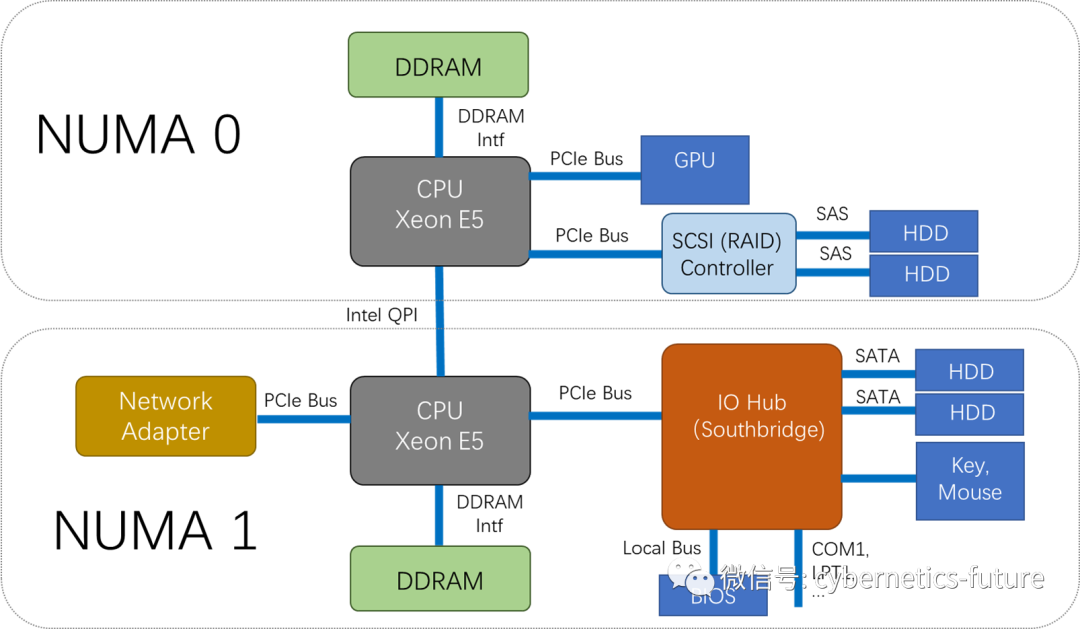
图中,两颗CPU各自连接整机的一部分DRAM和IO设备。由于在同一台整机中,CPU不能直接访问其他CPU上的DRAM和IO设备,也就是无法统一访问,这种内存访问方式叫做NUMA (Non-uniform Memory Access)。
在上图中,还体现了NUMA Node的概念,也就是把CPU及其本地的(可直接访问的)内存和IO设备,划分为一个NUMA Node。对于Intel x86处理器而言,每个物理Socket (CPU插槽)就是一个NUMA Node。而对于AMD,海光或鲲鹏等处理器,每个物理Socket有可能有多个NUMA Node,如海光3号处理器的每个Socket就有4个NUMA Node。
那么,如果一个NUMA Node 的CPU需要访问其他NUMA Node上的内存,这个问题应当如何解决呢?
以Intel CPU为例。Intel为Sandy Bridge架构推出了QPI (QuickPath Interconnect)标准,并在2017年推出的至强可扩展处理器上演进为UPI (Ultra Path Interconnect)。QPI和UPI不但能解决跨NUMA Node访问的实现,还可以实现跨NUMA的LLC (Last Level Cache)一致性。
然而,无论是QPI还是UPI,它都存在一定的局限性。在Intel 至强可扩展铂金系列CPU中,可以通过UPI连接8颗处理器,其扩展能力和高可用性甚至可以比拟BCS(Business Critical System,又称为小型机),但其连接能力无法超出机箱范围。也就是说,如果工程师们期望让CPU访问另一台服务器的内存,QPI和UPI是无法实现的。
有的读者看到这里,可能会问:RDMA(Remote Direct Memory Access)是不是一个访问远端服务器内存的解决方案呢?
在《局域网SDN硬核技术内幕 23 展望未来——RDMA(上)》里面,我们给出了一个结论:RDMA技术实现的是,让远端计算机不需要通过CPU处理TCP-IP协议栈等一系列网络解析封装流程,就可以在网络(以太网或IB网络)中实现内存的整块搬运。但是,由于RDMA访问是非透明的,需要特殊的函数调用 (也就是RDMA Verb),而不能通过内存地址来访问。如果应用程序需要将其他服务器上的内存当作本机内存使用,需要对应用程序进行非常大的修改,而且无法实现统一的本机内存与远端内存访问。
这离云计算工程师们期望的“天下大同”是有很大的差距的。为了实现云计算资源池的“天下大同”,CPU可以方便地去访问远端的内存,我们需要的是对处理器指令集层面透明的解决方案!
这是什么意思呢?
让我们举一个栗子。以下面这条指令为例:
mov [r8], eax
这条指令的意义,是将eax寄存器中的32bit数据保存到寄存器r8指向的内存地址中去。如r8为0x8000 0000 1000 AA00,而eax的内容为0x55AA55AA,则这条指令的结果,就是将地址0x8000 0000 1000 AA00 开始的4字节内容变更为0x55AA55AA。
实际上,内存地址0x8000 0000 1000 AA00在物理上,有可能是什么呢?
它有可能位于DRAM中——这是我们理解的通常的内存存取;
也有可能MMU并没有将这个地址映射到物理内存——那么CPU会陷入一个异常,并在异常处理程序中进行内存的交换 (也就是虚拟内存)。
有没有办法实现CPU将远端主机的内存映射为对程序指令可见的逻辑地址呢?
请看下回分解。