软硬件融合技术内幕 进阶篇 (16) —— 世界大同的梦想 (下)
软硬件融合技术内幕 进阶篇 (16) —— 世界大同的梦想 (下)

在前几期,我们提到了NUMA的概念。实际上,NUMA这个概念的内涵和外延,在不同的语境中会产生变化。
NUMA是Non-uniform memory access的缩写,在NUMA体系中,存在若干NUMA Node,每个NUMA Node有自己直连的RAM以及其他PCI-E外设。
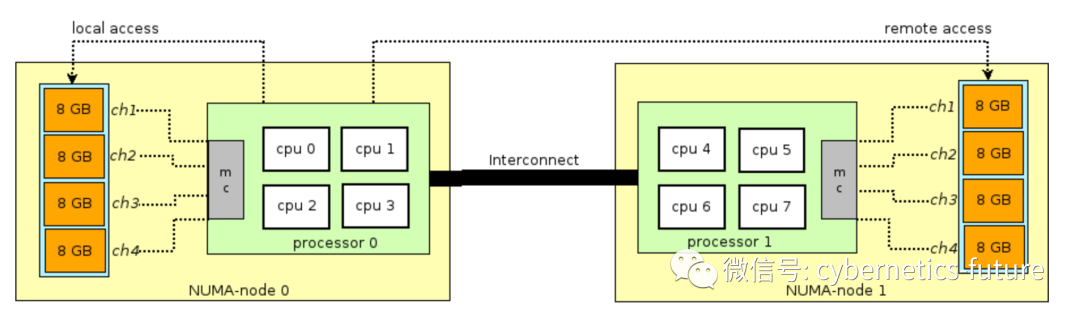
上图是Intel Xeon E5系列的框图。如整机为2路硬件,有2个物理 Socket,每个Socket为1个NUMA Node,并有自己直连的RAM。
然而,并不是所有的处理器体系结构中,每个Socket都只有1个NUMA Node的。以鲲鹏920为例:
下图是装备了双路Kunpeng 920-7260的整机框图:
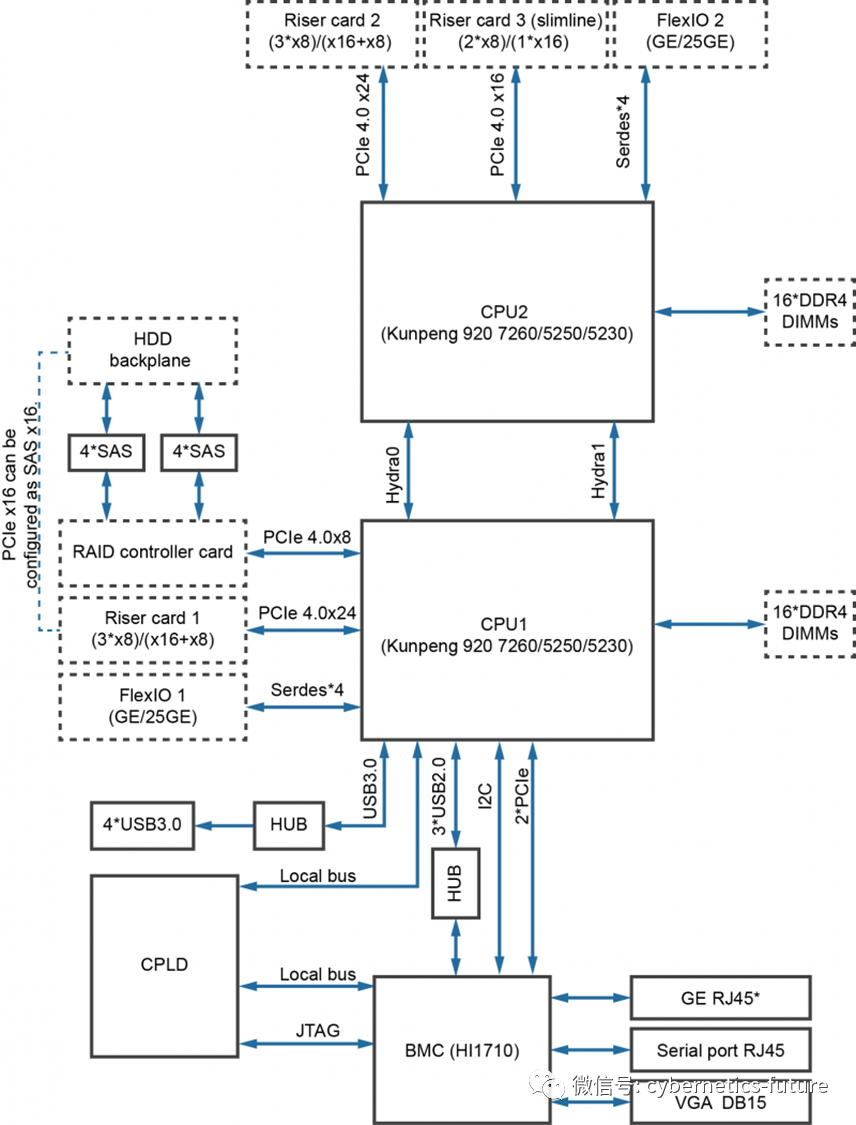
然而,这台服务器的整机NUMA Node数却不是2个,而是4个。
原来,Kunpeng 920-7260处理器虽然每颗处理器有64核,但却并非是真正的64核,而是所谓的“胶水”64核。
它的内部结构如图:
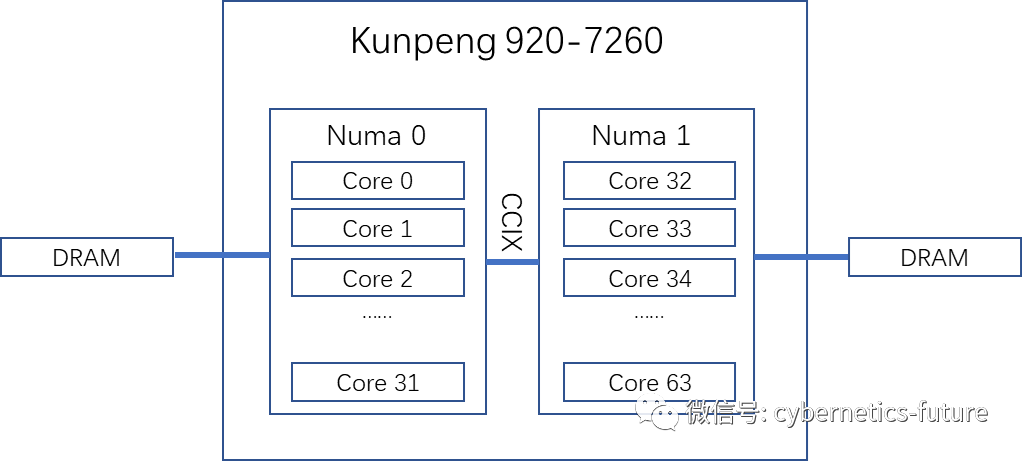
如图,在Kunpeng 920-7260的内部,实际上有2个NUMA Node,每个Numa Node有32个核,并可以通过各自的内存接口、PCI-E接口等连接到自己的内存和PCI-E外设。也就是说,在Socket内也有可能出现内存跨NUMA访问!
对于2路的场景,问题则更加复杂:
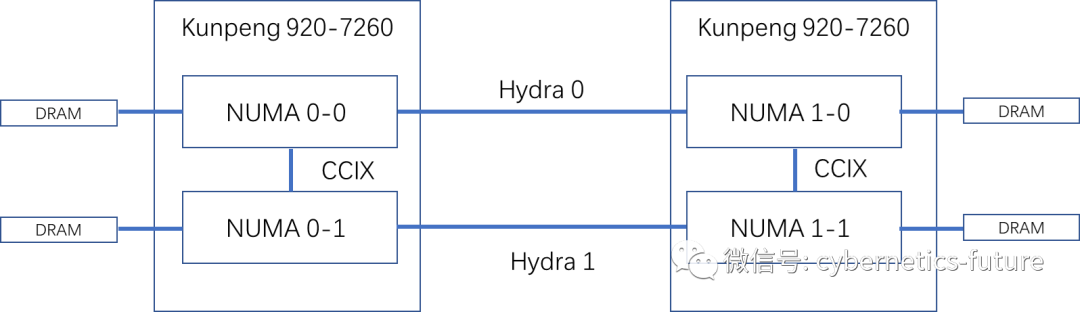
如图,在配置了2路kunpeng 920-7260的整机中,实际上有4个NUMA!
我们知道,在Linux中,为了让操作系统调度内存的时候,尽量让进程所需要的内存,靠近进程所在的内核,Linux内部维护了一张NUMA距离矩阵,用于计算调度内存时的权重。
如下图:
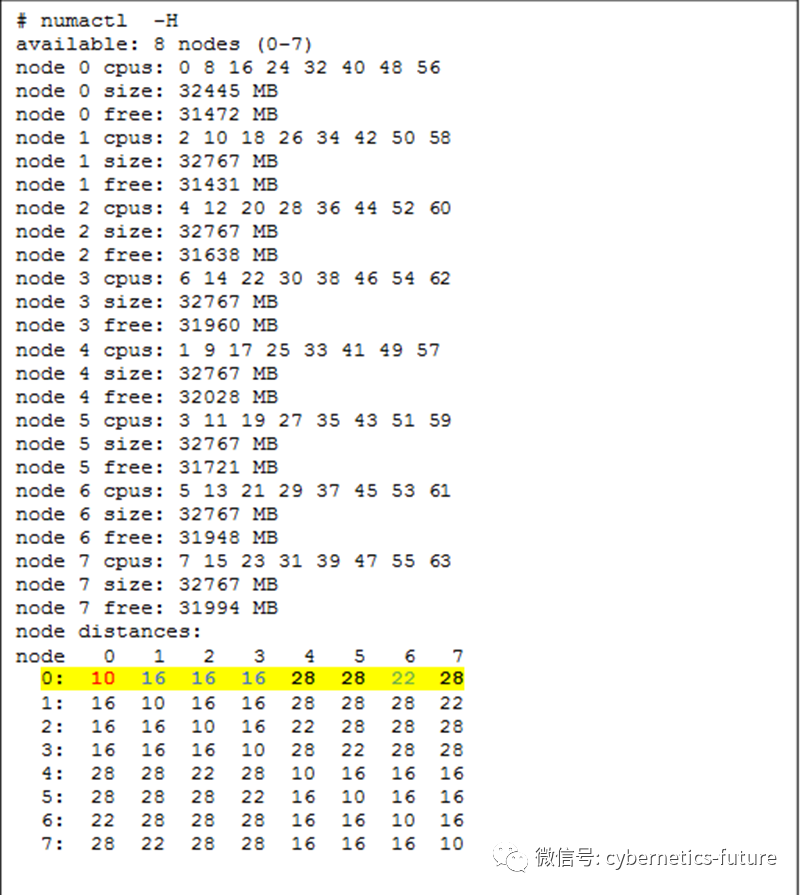
我们发现,如果整机有N个NUMA,那么,这个矩阵是N*N,在离散数学中可以表达为O(N*N)的空间复杂度。
当CXL广泛应用之后,我们就可以把NUMA的范围继续扩展到服务器机箱之外了。
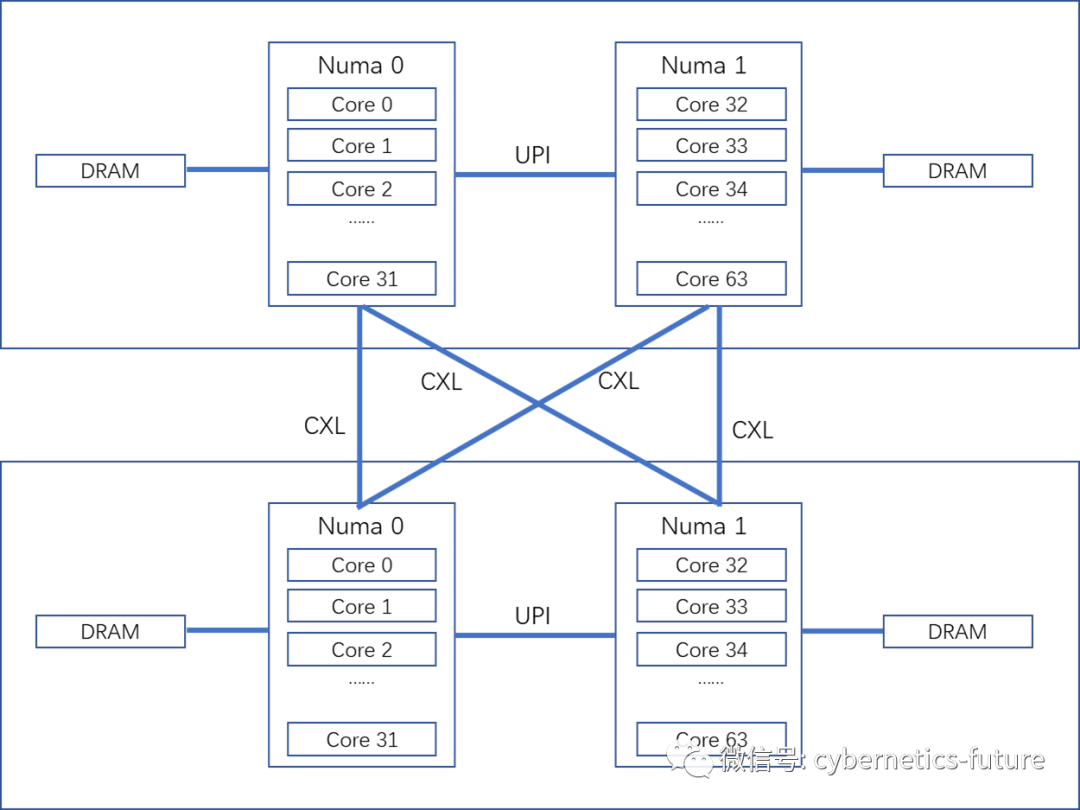
如图,两台 2 NUMA的服务器通过CXL互联扩展为4 NUMA;
如果有多台服务器通过CXL互联,则可以利用CXL Switch (也可能叫做CXL Fabric Box)实现:
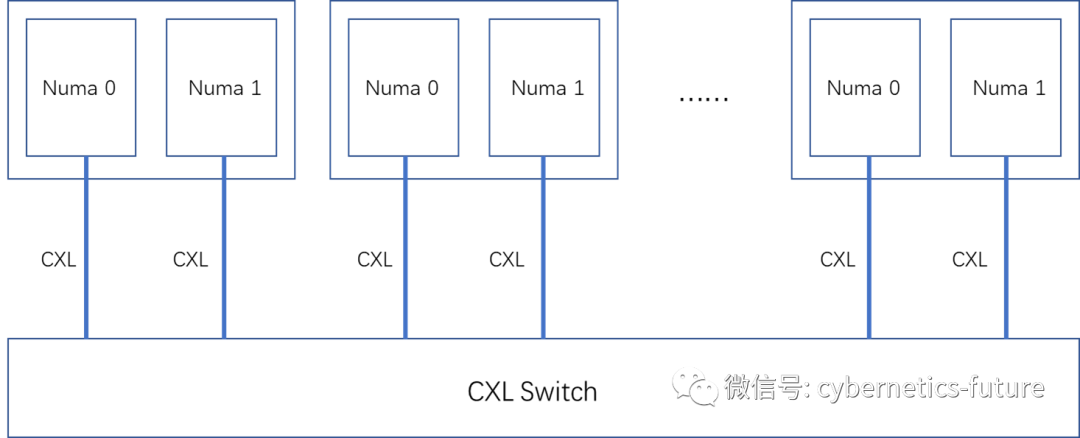
此时出现的困难在于,如果每个计算节点的Numa Node为M个,有N个计算节点需要连接在CXL Switch上,那么,Linux操作系统需要维护的矩阵为M*N平方的复杂度!
幸运的是,这种复杂度是一个多项式时间可以解决的问题。(在计算机系统中,比较可怕的问题是NP-hard问题,将来我们再讨论这一类问题)。
有了CXL Switch之后,我们可以为每个机柜的TOR引入一位“一字并肩王”——
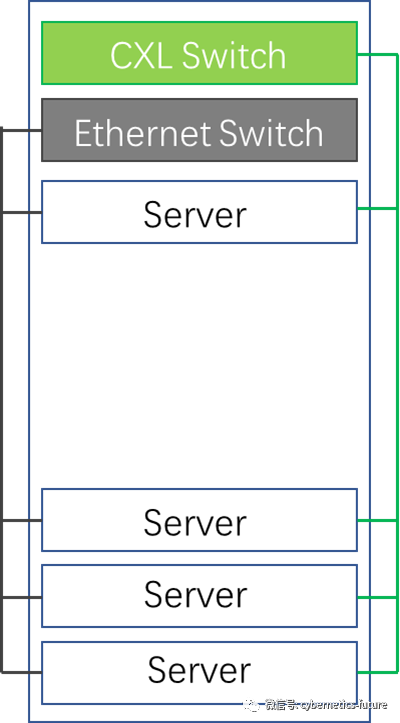
如图,每台服务器除通过以太网连接到Ethernet Switch外,还可以通过CXL线缆连接到CXL Switch。
服务器通过CXL访问远端内存的方式大致如下:
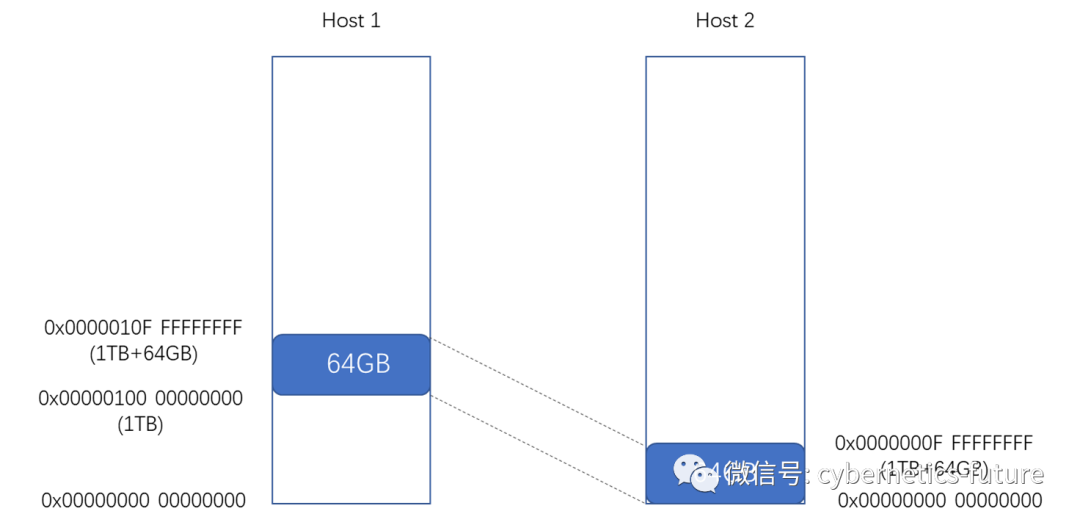
如图,Host 1通过CXL方式访问Host 2的内存。对于支持CXL的主机,CPU内部的内存控制器会对远端CXL内存空间做一个映射,也就是将远端计算机的物理地址,映射为自身的物理地址。
如Host 1上只安装了1TB的物理内存,其有效的物理地址为0x00000000 00000000到0x000000FF FFFFFFFF。如果需要将远端Host 2从0x00000000到0x0000000F FFFFFFFF (一共64GB)的内存映射到Host 1,可以将从0x00000100 00000000 开始的64GB物理地址,映射给来自CXL远端这64GB内存的物理地址。
而对于共享内存的场景如下图:
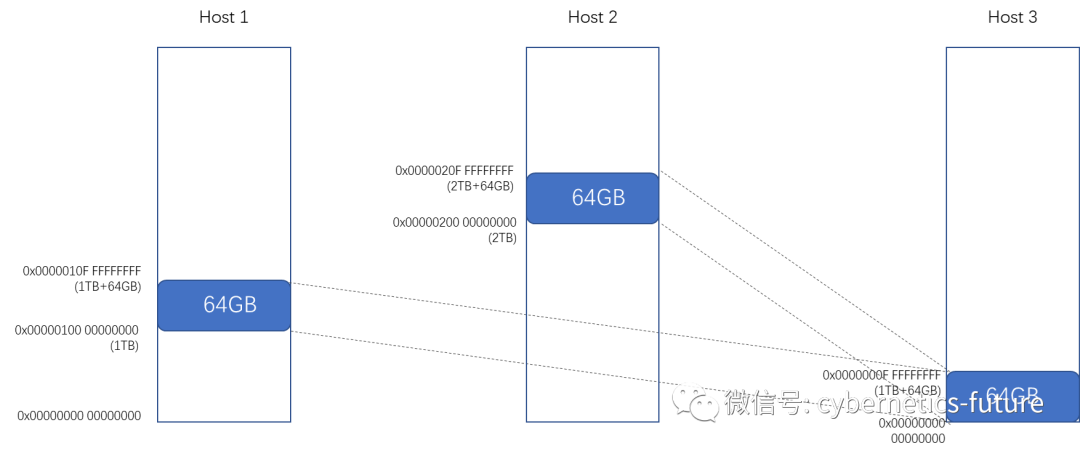
如图,Host 1和Host 2都通过CXL挂载了Host 3的64GB内存,并通过这种方式实现数据交换。需要注意的是,在这种场景下,内存读写的一致性需要应用层来实现,CXL只能保证内存读写的原子性,隔离性和持久性。如果Host 1修改了Host 2上程序依赖的数据结构,有可能导致Host 2上程序的运行得不到期望的结果。
实际上,由于通过CXL进行的内存访问的时延,远超出服务器内部CPU之间通过UPI等私有接口,跨NUMA访问的时延,常用于巨型内存数据库、内存图计算等场景中,而在Web应用、NFV等对NUMA亲和性要求高的场景中,目前尚不是很适合。
当然,CXL比起RDMA、gRPC、RestFul等远程访问方式而言,属于分布式系统中的又一次革命。它使得分布式系统远程访问的时延大大降低,拉近了计算资源与内存资源之间的距离。如果CXL的时延在可以预见的将来进一步降低,云计算的硬件基础将面临一次新的重构……
腾讯云开发者
