用一篇文章来彻底搞懂KMP算法

秋名山码民的主页 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 🙏作者水平很有限,如果发现错误,一定要及时告知作者
文章目录
前言
KMP算法,对于刚开始学算法的人还是有一点的难度的,但是总体来说比较简单,本文的目的就是用图文+代码的形式来搞懂kmp算法,至于是否吹牛,还请你看下去!
一、kmp算法是什么?
这是一个字符串匹配算法,对暴力的那种一一比对的方法进行了优化,使时间复杂度大大降低,如果要说kmp算法的时间复杂度是多少的话,O(m+n),至于为什么是这个,还请我用代码来进行分析,稍安。 命名还是和以前一样用3个外国人的名字首字母命名的,
本文中出现的基本概念
s[ ],p[]是模式串,其中s为长,p为短 部分匹配值:前缀和后缀的最长共有元素的长度 next[ ]是“部分匹配值表”,即next数组,它存储的是每一个下标对应的“部分匹配值”
二、kmp算法
首先像往常一样,我们先来考虑如何用BF算法来解答字符串匹配的问题
for (int i = 1; i <= n; i++)
{
bool flag = true;
for (int j = 1; j <= m; j++)
{
if (s[i] != p[j])//匹配失败
{
flag = false;
break;
}
}
}可以看出时间复杂度为O(n^2)
kmp = next数组+匹配字符串
我们先来看比较重要的next【】数组究竟是什么东西?
对next[ j ] ,是p[ 1, j ]串中前缀和后缀相同的最大长度(部分匹配值),即 p[ 1, next[ j ] ] = p[ j - next[ j ] + 1, j ]
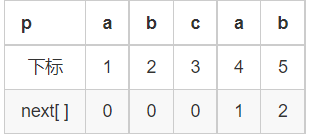
模拟上面的next数组。
对next[ 1 ] :前缀 = 空集——后缀 = 空集—next[ 1 ] = 0;
对next[ 2 ] :前缀 = { a }——后缀 = { b }—next[ 2 ] = 0;
对next[ 3 ] :前缀 = { a , ab }——后缀 = { c , bc}—next[ 3 ] = 0;
对next[ 4 ] :前缀 = { a , ab , abc }——后缀 = { a . ca , bca }—next[ 4 ] = 1;
对next[ 5 ] :前缀 = { a , ab , abc , abca }—后缀 = { b , ab , cab , bcab}—next[ 5 ] = 2;
s串 和 p串都是从1开始的。i 从1开始,j 从0开始,每次s[ i ] 和p[ j + 1 ]比较
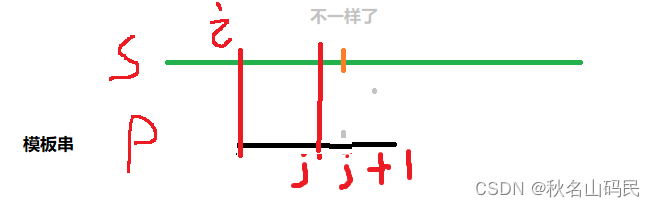
当匹配到上图过程时候,要移动p串(不是移动1格,而是直接移动到下次能匹配的位置)
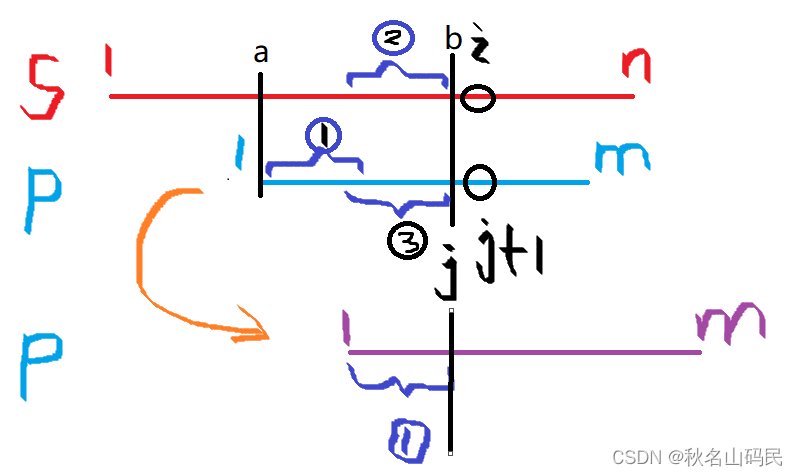
代码解析
下面我们来看kmp的代码
#include <iostream>
using namespace std;
const int N = 100010;
int n, m;
int next[N];
char s[N], p[N]; //s为模式串, p为匹配串
int main()
{
cin >> n >> s + 1 >> m >> p + 1; //下标从1开始
//求next[]数组
for (int i = 2, j = 0; i <= m; i++)
{
while (j && p[i] != p[j + 1]) j = next[j];
//当j退无可退,或者二者匹配时候退出
if (p[i] == p[j + 1]) j++;
next[i] = j;
}
//匹配操作
for (int i = 1, j = 0; i <= m; i++)
{
while (j && s[i] != p[j + 1]) j = next[j];
if (s[i] == p[j + 1]) j++;
if (j == n)
{
printf("%d ", i - n);//打印
j = next[j];
}
}
return 0;
}分析时间复杂度:
i循环m次,则j最多加了m次,所以看似是2个循环,实则时间复杂度为2m则O(N)
总结
插个题外话,实际上kmp算法,更像是一次又一次的尝试,说好听点,各位彦祖想一下,假如你追女生的时候,一次失败了,再来一次,不行,像next[j]一样退一步,再战,如果成功了,那么是不是就能再进一步?
腾讯云开发者
