web自动化之selenium的特殊用法汇总篇

目录如下:
- web自动化之selenium的特殊用法(一)
- 1、get_attribute()
- 2、js滚动页面
- 3、Tab键点击页面未展示元素
- 4、通过空格键执行页面滚动操作
- 1.摁空格键
- 2.报错:TypeError: list indices must be integers or slices, not WebElement
- 1、selenium-键盘操作,keys的的使用
- (1)keys包的导入
- (2)组合键使用
- (4)常用组合键
- (5)常用功能键
- 2、Python-Selenium:如何通过click在新的标签页打开链接?
- 3、selenium 带有空格的class name且不唯一的元素定位
- 1、当前浏览器窗口截屏
- 2、生成网站长截图
- 3、特殊网页无法长截图,使用多图拼接技术
- 4、无头模式调整浏览器的实际窗口大小
web自动化之selenium的特殊用法(一)
1、get_attribute()
官方文档释义
selenium.webdriver.remote.webelement — Selenium 4.1.0 documentation
get_attribute(name) → str[source]
Gets the given attribute or property of the element.
获取元素的给定属性或属性。
This method will first try to return the value of a property with the given name. If a property with that name doesn’t exist, it returns the value of the attribute with the same name. If there’s no attribute with that name, None is returned.
该方法将首先尝试返回具有给定名称的属性的值。 如果具有该名称的属性不存在,则返回具有相同名称的属性的值。 如果没有这个名称的属性,则返回' None '。
Values which are considered truthy, that is equals “true” or “false”, are returned as booleans. All other non-None values are returned as strings. For attributes or properties which do not exist, None is returned.
被认为为真值的值,即等于“真”或“假”的值,将作为布尔值返回。 所有其他非' None '值将作为字符串返回。 对于不存在的属性或属性,将返回' None '。
To obtain the exact value of the attribute or property, use get_dom_attribute() or get_property() methods respectively.
要获得属性或属性的确切值,请分别使用' get_dom_attribute() '或' get_property() '方法。
Example:
# Check if the "active" CSS class is applied to an element.
is_active = "active" in target_element.get_attribute("class")
里面可以填所有的属性,目前我尝试过的有如下几个
#获取元素标签的内容:
get_attribute('textContent')
#获取元素内的全部HTML:
get_attribute('innerHTML')
#获取包含选中元素的HTML:
get_attribute('outerHTML')
get_attribute('class')
get_attribute('name')
get_attribute('id')
get_attribute('href')
2、js滚动页面
通过js执行页面滚动条操作
#滚动屏幕元素可见
# 将页面向下拉取400像素
print(f"将页面向下拉取{int(index/5+1)*400}像素")
self.driver.execute_script(f"window.scrollTo(0,{int(index/5+1)*420});")
time.sleep(3)
3、Tab键点击页面未展示元素
用法实例
history_element_id = "changehistory-tabpanel"
history_element = self.driver.find_element_by_id(history_element_id)
# time.sleep(0.5)
history_element.send_keys(Keys.TAB) #通过tab键来查找页面元素
#点击history的按钮,使得下面的内容显示出来
history_element.click()
4、通过空格键执行页面滚动操作
终极大法,按住下键或者摁空格键可以到达页面底部
1.摁空格键
注意:如果页面有多个滚动条,则需要鼠标左键单击对应的滚动条对应页面
直接进入页面点空格键是没有反应的,需要点击一下页面在摁空格键才有效果
from selenium.webdriver.common.action_chains import ActionChains
print(2)
print("移动鼠标点击左键 ")
ActionChains(self.driver).move_by_offset(300, 900).click().perform()
print("摁住空格键")
time.sleep(3)
actions = ActionChains(self.driver)
actions.send_keys(Keys.SPACE).perform()
2.报错:TypeError: list indices must be integers or slices, not WebElement
#获取25条数据
crashNum = self.driver.find_elements(By.CLASS_NAME,'particle-table-row')
print(len(crashNum))
for i in crashNum:
particle_table_row = self.driver.find_elements(By.CLASS_NAME,'particle-table-row')[i]
msg = particle_table_row.text
print(msg)
上面运行是会报错:
修改为如下即可:
#获取25条数据
crashNumList = self.driver.find_elements(By.CLASS_NAME,'particle-table-row')
print(len(crashNumList))
for crashNumListIndex,crashNum in enumerate(crashNumList):
particle_table_row = crashNumList[crashNumListIndex]
msg = particle_table_row.text
print(msg)
web自动化之selenium的特殊用法(二)
1、selenium-键盘操作,keys的的使用
(1)keys包的导入
selenium有很完整的键盘操作,都在keys模块里
#导入keys包
from selenium.webdriver.common.keys import Keys
(2)组合键使用
KeysWord_Box = driver.find_element_by_xpath('//*[@id="kw"]')
#搜索框输入内容
KeysWord_Box.send_keys('test')
time.sleep(3)
#Keys.CONTROL代表ctrl键,'a'代表了A键,所以ctrl+A全选就实现了
KeysWord_Box.send_keys(Keys.CONTROL,'a')
#Keys.BACKSPACE代表退格键
KeysWord_Box.send_keys(Keys.BACKSPACE)
这段代码可以看到浏览器打开百度,输入内容,然后全选输入的内容,再退格删除。
(4)常用组合键
功能 | 语句 |
|---|---|
全选(Ctrl+A) | send_Keys(Keys.CONTROL,‘a’) |
复制(Ctrl+C) | send_keys(Keys.CONTROL,‘c’) |
剪切(Ctrl+X) | send_keys(Keys.CONTROL,‘x’) |
粘贴(Ctrl+V) | send_keys(Keys.CONTROL,‘v’) |
(5)常用功能键
功能 | 代码 |
|---|---|
回车 | Keys.ENTER |
删除 | Keys.BACK_SPACE |
空格 | Keys.SPACE |
制表 | Keys.TAB |
回退 | Keys.ESCAPE |
刷新 | Keys.F5 |
2、Python-Selenium:如何通过click在新的标签页打开链接?
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get(url)
# 查找帖子列表(40条)
post_list = driver.find_elements(By.XPATH, '//ul[@id="waterfall"]/li/h3/a[1]')
# 存储原始窗口的 ID
original_window = driver.current_window_handle
for i in range(0, 40):
# 点击进入帖子
print(f'第{i + 1}个帖子')
# 获取帖子链接
href = post_list[i].get_attribute('href')
# 在新的标签页打开链接
driver.execute_script(f'window.open("{href}", "_blank");')
# 切换到新的标签页
driver.switch_to.window(driver.window_handles[-1])
# 单独处理
do sth...
# 关闭当前标签页
driver.close()
# 切回到之前的标签页
driver.switch_to.window(original_window)
driver.quit()
3、selenium 带有空格的class name且不唯一的元素定位
有些class属性中间有空格,如果直接复制过来定位是会报错的InvalidSelectorException: Message:
The given selector u-label f-dn is either invalid or does not result in a WebElement. The following error occurred:
InvalidSelectorError: Compound class names not permitted
这个报错意思是说定位语法错了。
class属性中间的空格并不是空字符串,那是间隔符号,表示的是一个元素有多个class的属性名称
直接包含空格的CSS属性定位大法
Element=driver.find_element_by_css_selector("[class='col3 fcweak ft12 tal']")
web自动化之selenium的特殊用法(三)
1、当前浏览器窗口截屏
核心
driver.save_screenshot() 保存截图
具体实现代码如下:
import os
import time
import random
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class ChromeSeleniumMain():
def __init__(self):
pass
def connectChrom(self):
options = Options()
chrome_driver = "./chromedriver.exe" # 我是把chromedriver驱动放在项目根目录下
self.driver = webdriver.Chrome(chrome_driver, options=options)
self.driver.maximize_window() #窗口最大化
time.sleep(2)
self.driver.implicitly_wait(30)
def getBrowserScreen(self):
self.driver.get("https://www.baidu.com/")
saveImgPath = os.path.join(os.path.dirname(__file__),'screen001.png')
self.driver.save_screenshot(saveImgPath)
self.driver.close()
self.driver.quit()
def runMain(self):
'''
运行主函数
:return:
'''
#连接浏览器
self.connectChrom()
self.getBrowserScreen()
if __name__ == '__main__':
run = ChromeSeleniumMain()
run.runMain()
运行之后截图就在根目录下,截图如下:
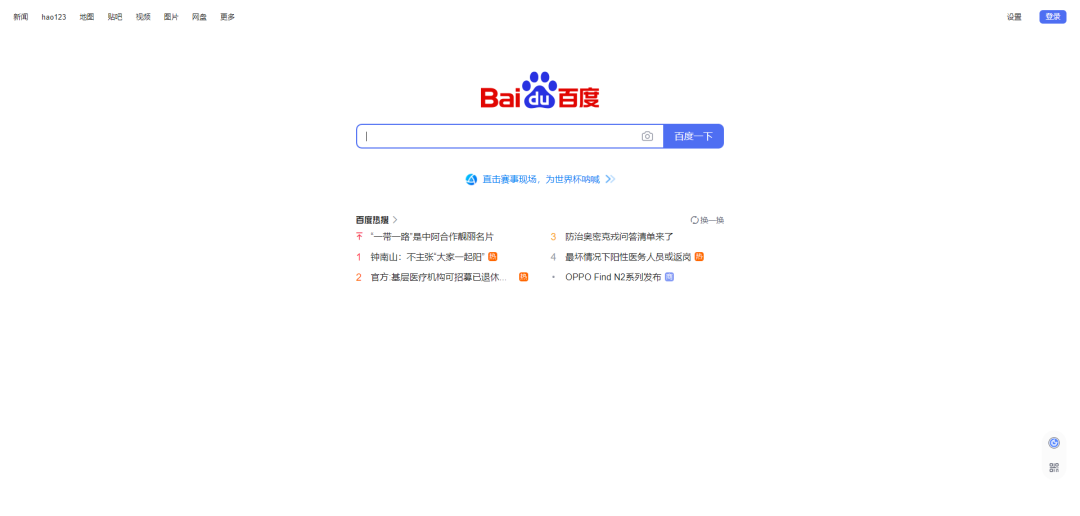
screen001
2、生成网站长截图
如果要保存成网页长图,则需要以下4个步骤。
(1)隐藏窗口界面。(不隐藏截出来的效果和上图截屏一样)
(2) 调用JavaScript函数获取当前浏览器的带滚动条的宽和高。
(3) 调整浏览器的实际窗口大小。
(4) 延迟几秒,因为有些网页使用了图片延迟加载技术。否则保存下来的部分图片是空白的。
以京东的官网作为示列
核心代码:
无头模式:
options = Options()
options.add_argument('--headless') # 无头模式,不会显示浏览器
调用JavaScript函数获取当前浏览器的带滚动条的宽和高
# 获取宽
width = self.driver.execute_script("return document.body.scrollWidth")
# 获取高
height = self.driver.execute_script("return document.body.scrollHeight")
print(width,height)
# 设置浏览器窗口宽高进行截图
self.driver.set_window_size(width, height)
具体代码如下:
__author__ = "梦无矶小仔"
import os
import random
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class ChromeSeleniumMain():
def __init__(self):
pass
def connectChromeNoHead(self):
options = Options()
options.add_argument('--headless') # 无头模式,不会显示浏览器
chrome_driver = "./chromedriver.exe" # 我是把chromedriver驱动放在项目根目录下
self.driver = webdriver.Chrome(chrome_driver, options=options)
def getBrowserLongScreen(self):
self.driver.get("https://www.jd.com/")
width = self.driver.execute_script("return document.body.scrollWidth")
height = self.driver.execute_script("return document.body.scrollHeight")
self.driver.set_window_size(width, height)
time.sleep(5)
saveImgPath = os.path.join(os.path.dirname(__file__), 'screen002.png')
self.driver.save_screenshot(saveImgPath)
self.driver.close()
self.driver.quit()
def runMain(self):
#连接浏览器
self.connectChromeNoHead()
self.getBrowserLongScreen()
if __name__ == '__main__':
run = ChromeSeleniumMain()
run.runMain()
截图如下:
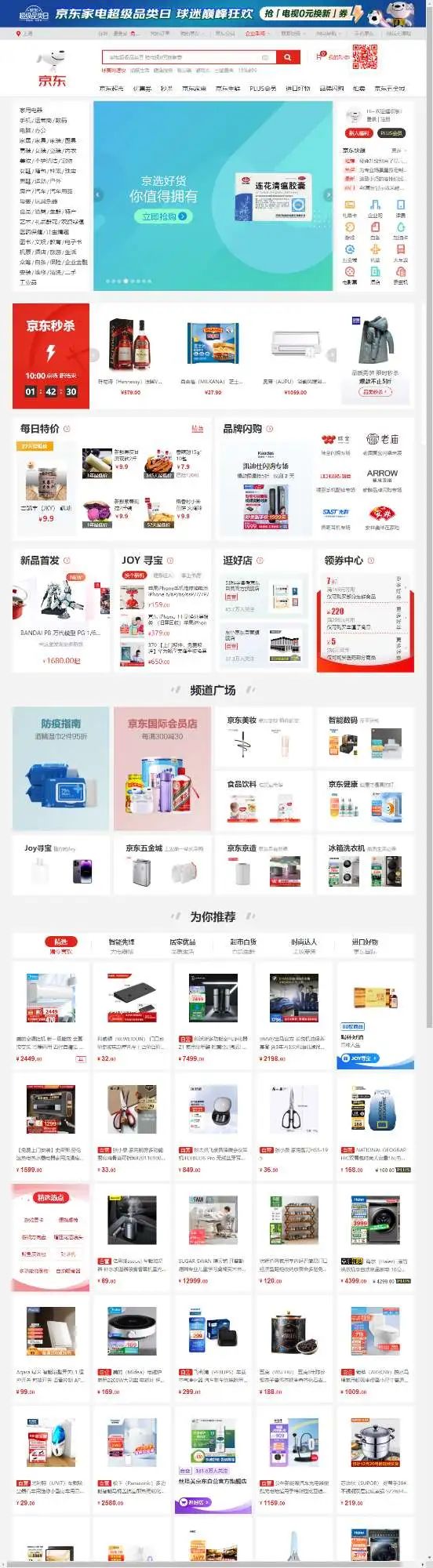
screen003
有人可能会问,这个图明显看起来就不是浏览器最大化截的呀,有没有什么办法截最大化的长图呀?
当然有,别急,我们一步步学~
3、特殊网页无法长截图,使用多图拼接技术
有的网站有很多个滚动条,使用js的时候不太好定位我们想要截图的页面滚动。
这时候我们就需要使用到web自动化之selenium的特殊用法(一)里面讲到的知识点了,空格滚动法。
1、需要定位出你需要截图的页面所处的坐标大致位置
2、第一次截图完后,定位到上述坐标,按下空格按钮(页面会进行滚动,小伙伴可以试一下),再次截图
3、如果需要继续截图可以继续按
4、进行图片拼接
注意点:
1、按键需要配合释放和执行
2、需要智能切换关闭页面,确保每次截图的准确
3、两张图拼接好后可能会有部分地方是重复的(目前我没很好的解决方案)
具体的内容我会在详细代码里面写好注释
滚动页面实现代码如下:
import os
import random
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
def vital_screenshot(self,imag_save_path):
time.sleep(2)
random_number = random.randint(400, 500)
actions111 = ActionChains(self.driver)
# 鼠标移动到指定总表
actions111.move_by_offset(random_number, 900).click().perform()
actions111.release().perform() # 重置偏移量,释放按键
# 获取当前页面的句柄
original_window = self.driver.current_window_handle
print("--------------打开新标签页--------------------")
self.driver.execute_script( f'window.open("填入你需要截图的网页", "_blank");')
# 切换到新的标签页
self.driver.switch_to.window(self.driver.window_handles[-1])
time.sleep(5)
print("初始等待")
vitalsPage = self.driver.page_source
img1_path = f'vitals_1.png'
self.driver.save_screenshot(img1_path)
time.sleep(2)
print("准备截图前的移动鼠标点击 ")
random_number = random.randint(400, 500)
actions222 = ActionChains(self.driver)
actions222.move_by_offset(random_number, 900).click().perform()
print("摁住空格键")
time.sleep(2)
actions333 = ActionChains(self.driver)
actions333.send_keys(Keys.SPACE).perform()
print("释放按键")
actions222.release().perform() # 重置偏移量,释放按键
actions333.release().perform() # 释放按键
print("准备截图下一张")
time.sleep(2)
img2_path = f'vitals_2.png'
self.driver.save_screenshot(img2_path)
# 合并图片
# 合并后图片的地址
img_3_path = f"{imag_save_path}/Vitals合并截图.png"
self.imageStitching(img1_path, img2_path, newImgPath=img_3_path)
# 关闭当前标签页
self.driver.close()
# 切回到之前的标签页
self.driver.switch_to.window(original_window)
图片拼接代码如下:
import os
import random
import time
from PIL import Image
#拼接图片的代码
def imageStitching(self,imgPath_1,imgPath_2,newImgPath):
'''
:param imgPath_1: 第一张图片的路径,
:param imgPath_2: 第二张图片的路径,
:param newImgPath: 拼接图片的路径,
:return: 无返回值
'''
# 获取当前文件夹中所有JPG图像
im_list_1 = [imgPath_1, imgPath_2]
im_list = [Image.open(fn) for fn in im_list_1]
# 图片转化为相同的尺寸
ims = []
for i in im_list:
# #图片尺寸可以根据浏览器返回的尺寸自定义
new_img = i.resize((1920, 961), Image.BILINEAR)
ims.append(new_img)
# 单幅图像尺寸
width, height = ims[0].size
# 创建空白长图
result = Image.new(ims[0].mode, (width, height * len(ims)))
# 拼接图片
for i, im in enumerate(ims):
result.paste(im, box=(0, i * height))
result.save(newImgPath)
print("---------------图片拼接完毕!-----------------")
4、无头模式调整浏览器的实际窗口大小
在生成网站长截图部分,我们发现长截图的网页并不是实际我们最大化时候的样子,感觉像是平板端的PC展示页。
首先我们需要明确一点,在有浏览器界面的操作模式下,我们让浏览器最大化的方法是self.driver.maximize_window(),而在无头模式的操作模式下,使用这个方法是无效的,浏览器是不会全屏的,不信的同学可以去试试,验证方法就是截图。
这里我就不展示了,太简单了,直接在当前浏览器窗口截屏那个小节的options中加一个headless就可以了。
首先需要下载pyautoui
pip install pyautoui
核心代码
width, height = pyautogui.size() # 通过pyautogui方法获得屏幕尺寸 pip install pyautogui
self.driver.set_window_size(width, height)
完整代码如下:
__author__ = "梦无矶小仔"
import os
import random
import time
import pyautogui
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class ChromeSeleniumMain():
def __init__(self):
pass
def connectChromeNoHead(self):
options = Options()
options.add_argument('--headless') # 无头模式,不会显示浏览器
chrome_driver = "./chromedriver.exe" # 我是把chromedriver驱动放在项目根目录下
self.driver = webdriver.Chrome(chrome_driver, options=options)
width, height = pyautogui.size() # 通过pyautogui方法获得屏幕尺寸
self.driver.set_window_size(width, height)
def getBrowserLongScreen(self):
self.driver.get("https://www.jd.com/")
width = self.driver.execute_script("return document.body.scrollWidth")
height = self.driver.execute_script("return document.body.scrollHeight")
self.driver.set_window_size(width, height)
time.sleep(5)
saveImgPath = os.path.join(os.path.dirname(__file__), 'screen002.png')
self.driver.save_screenshot(saveImgPath)
self.driver.close()
self.driver.quit()
def runMain(self):
#连接浏览器
self.connectChromeNoHead()
self.getBrowserLongScreen()
if __name__ == '__main__':
run = ChromeSeleniumMain()
run.runMain()
截图如下:(是不是宽敞了许多?)
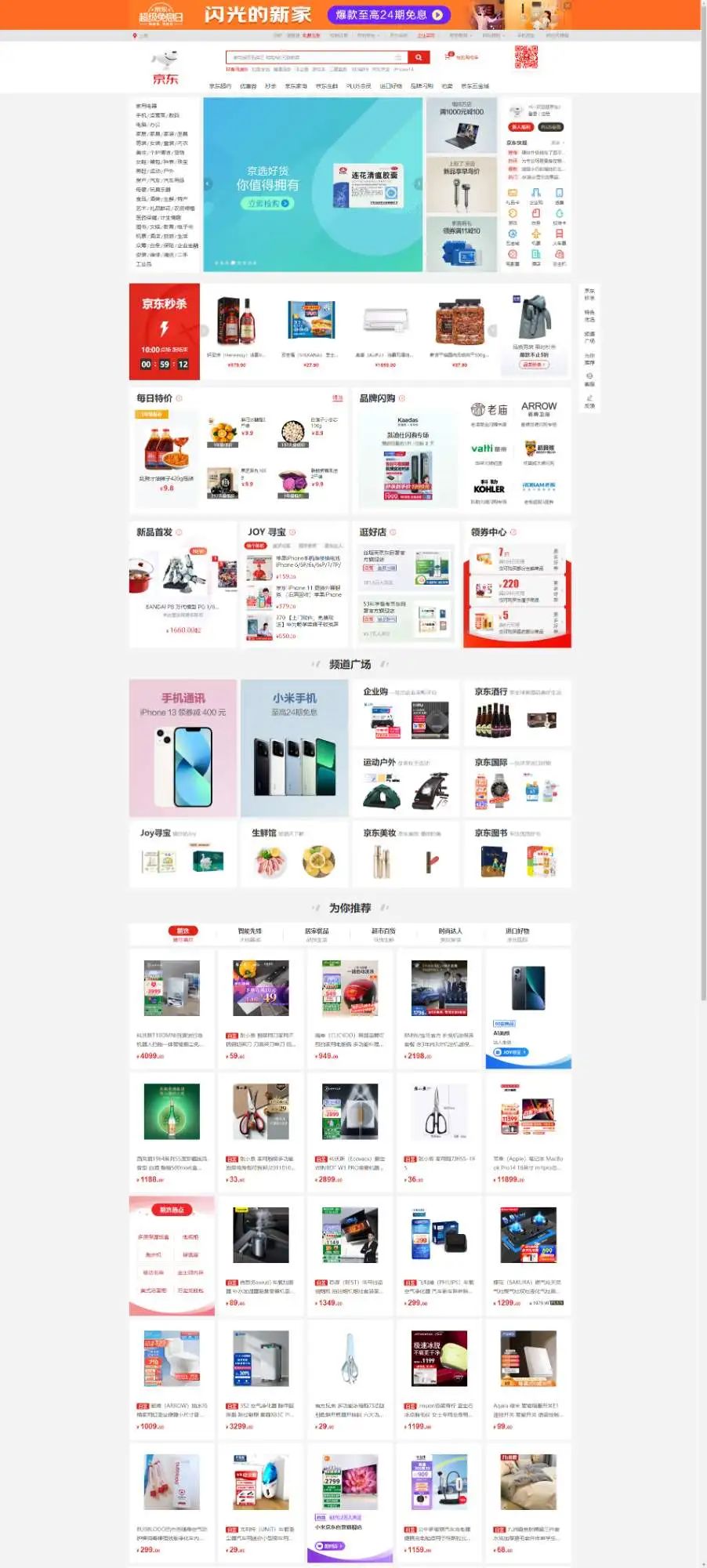
screen003
腾讯云开发者
