面试系列-kafka内部通信协议

kafka的内外部交互协议
Kafka的Producer、Broker和Consumer之间采用的是一套自行设计的基于TCP层的协议,Kafka的这套协议完全是为了Kafka自身的业务需求而定制的;
基本数据类型
- 定长数据类型:int8、int16、int32和int64,对应到Java中就是byte, short, int和long;
- 变长数据类型:bytes和string,变长的数据类型由两部分组成,分别是一个有符号整数N(表示内容的长度)和N个字节的内容。其中,N为-1表示内容为null。bytes的长度由int32表示,string的长度由int16表示;
- 数组:数组由两部分组成,分别是一个由int32类型的数字表示的数组长度N和N个元素;
通信模型
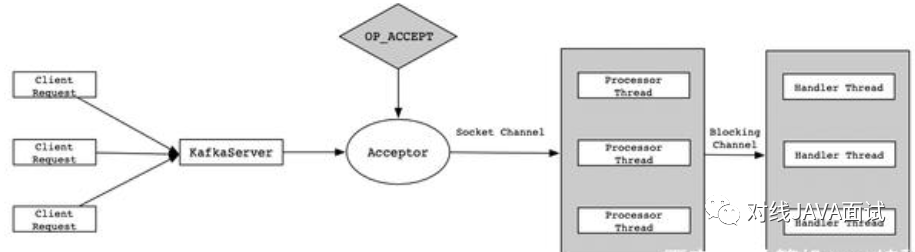
Kafka系统采用的是Reactor多线程模型,即通过一个Acceptor线程处理所有的新连接,通过多个Processor线程对请求进行处理(比如解析协议、封装请求、、转发等);
- Reactor是一种事件模型,可以将请求提交到一个或者多个服务程序中进行处理。当收到Client的请求后,Server处理程序使用多路分发策略,由一个非阻塞的线程来接收所有的请求,然后将这些请求转发到对应的工作线程中进行处理;
通信过程
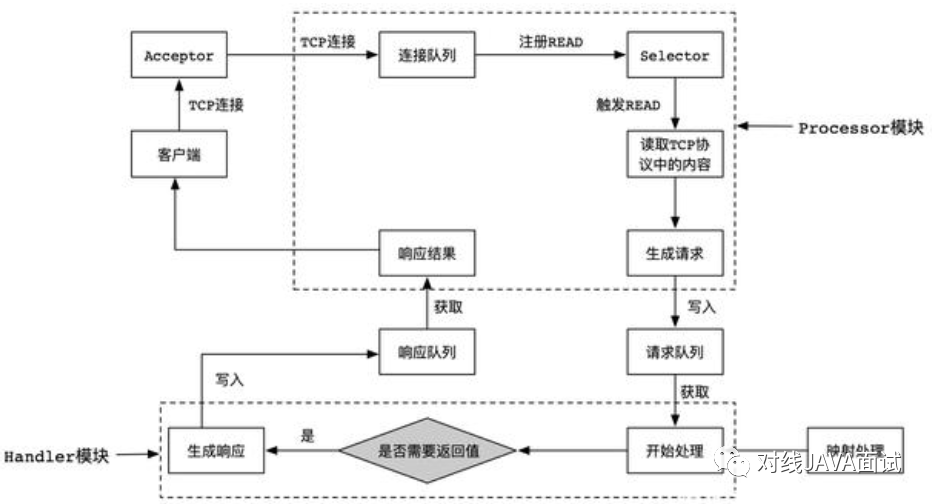
kafka老的版本中,以NIO作为网络通信的基础,通过将多个Socket连接注册到一个Selector上进行监听,只用一个线程就能管理多个连接,这极大的节省了多线程的资源开销;
在Kafka之后的新版本中,依然以NIO作为网络通信的基础,也使用了Reactor多线程模型,不同的是,新版本将具体的业务处理模块(Handler模块)独立出去了,并用单独的线程池进行控制;
- Client向Server发送请求时,Acceptor负责接收TCP请求,连接成功后传递给Processor线程;
- Processor线程接收到新的连接后,将其注册到自身的Selector中,并监听READ事件;
- 当Client在当前连接对象上写入数据时,会触发READ事件,根据TCP协议调用Handler进行处理;
- Handler处理完成后,可能会有返回值给Client,并将Handler返回的结果绑定Response端进行发送;
新增Handler模块优点在于:
- 能够单独指定Handler的线程数,便于调优和管理;
- 防止一个过大的请求阻塞一个Processor线程;
- Request、Handler、Response之间都是通过队列来进行连接的,这样它们彼此之间不存在耦合现象,对提升Kafka系统的性能很有帮助;
生产消费者之间通信的基本格式
请求响应Request和Response的基本结构
Kafka中两个角色之间通信的基本单位是Request/Response:
RequestOrResponse => MessageSize (RequestMessage | ResponseMessage) | ||
|---|---|---|
名称 | 类型 | 描述 |
MessageSize | int32 | 表示RequestMessage或者ResponseMessage的长度; |
RequestMessage/ResponseMessage | - | 表示Request或者Response的内容,在下面将会介绍其具体格式; |
定义了通信双方交换数据的基本结构,通信的过程能够简单地表示为:客户端打开与服务器端的Socket,而后往Socket写入一个int32的数字表示此次发送的Request有多少字节,而后继续往Socket中写入对应字节数的数据。服务器端先读出一个int32的整数从而获取此次Request的大小,而后读取对应字节数的数据从而获得Request的具体内容。服务器端处理了请求后,也用一样的方式来发送响应; | ||
RequestMessage的结构
RequestMessage => ApiKey ApiVersion CorrelationId ClientId Request | ||
|---|---|---|
名称 | 类型 | 描述 |
ApiKey | int16 | 表示此次请求的API编号 |
ApiVersion | int16 | 表示请求的API的版本,有了版本后就能够作到后向兼容 |
CorrelationId | int32 | 由客户端指定的一个数字惟一标示此次请求的id,服务器端在处理完请求后也会把一样的CorrelationId写到Response中,这样客户端就能把某个请求和响应对应起来了 |
ClientId | string | 客户端指定的用来描述客户端的字符串,会被用来记录日志和监控,它惟一标示一个客户端 |
Request | - | Request的具体内容 |
ResponseMessage的结构
ResponseMessage => CorrelationId Response | ||
|---|---|---|
名称 | 类型 | 描述 |
CorrelationId | int32 | 对应Request的CorrelationId |
Response | - | 对应Request的Response,不一样的Request的Response的字段是不同的 |
中间环节Message的表达形式
Producer生产消息并推送(Push)给Broker,而后Consumer再从Broker那里取走(Pull)消息。Producer生产的消息就是由Message来表示的,对用户来说它就是键-值对;
Message => Crc MagicByte Attributes Key Value | ||
|---|---|---|
名称 | 类型 | 描述 |
CRC | int32 | 表示这条消息(不包括CRC字段自己)的校验码 |
MagicByte | int8 | 表示消息格式的版本,用来作后向兼容,目前值为0 |
Attributes | int8 | 表示这条消息的元数据,目前最低两位用来表示压缩格式 |
Key | bytes | 表示这条消息的Key,能够为null |
Value | bytes | 表示这条消息的Value。Kafka支持消息嵌套,也就是把一条消息做为Value放到另一条消息里面 |
多条消息的MessageSet
MessageSet用来组合多条Message,它在每条Message的基础上加上了Offset和MessageSize;MessageSet是个数组,数组的每一个元素由三部分组成,分别是Offset,MessageSize和Message;
MessageSet => [Offset MessageSize Message] | ||
|---|---|---|
名称 | 类型 | 描述 |
Offset | int64 | 它用来做为log中的序列号,Producer在生产消息的时候还不知道具体的值是什么,能够随便填个数字进去 |
MessageSize | int32 | 表示这条Message的大小 |
Message | - | 表示这条Message的具体内容 |
Request/Respone和Message/MessageSet的关系
- Request/Response是通信层的结构,和网络的7层模型对比的话,它相似于TCP层;
- Message/MessageSet定义的是业务层的结构,相似于网络7层模型中的HTTP层;
- Message/MessageSet只是Request/Response的payload中的一种数据结构;
Message的压缩
压缩方式 | 编码 |
|---|---|
不压缩 | 0 |
Gzip | 1 |
Snappy | 2 |
LZ4 | 3 |
由于单条消息中重复内容可能很少,因此一般把多条消息放在一块儿组成MessageSet,而后再把MessageSet放到一条Message里面去,从而提升压缩比率;
kafka的内部交互协议
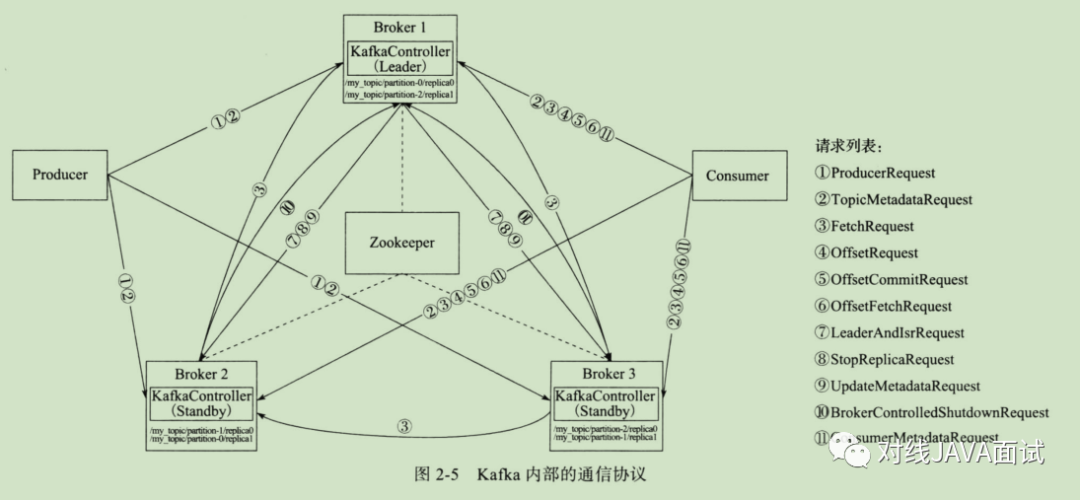


Kafka请求处理核心流程
- Clients发送请求给Acceptor线程;
- Acceptor线程会创建NIO Selector对象,并创建ServerSocketChannel实例,然后将Channel和OP_ACCEPT事件到 Selector多路复用器上;
- Acceptor线程还会默认创建3个大小的 Processor 线程池,参数:num.network.threads, 并轮询的将请求对象 SocketChannel放入到连接队列中(newConnections);
- 这时候连接队列就源源不断有请求数据了,然后不停地执行NIO Poll, 获取对应SocketChannel上已经准备就绪的I/O事件;
- Processor线程向SocketChannel注册了OP_READ/OP_WRITE事件,这样 客户端发过来的请求就会被该 SocketChannel对象获取到,具体就是CompleteReceives;
- 这个时候客户端就可以源源不断进行请求发送了,服务端通过Selector NIO Poll不停的获取准备就绪的I/O事件;
- 然后根据Channel中获取已经完成的Receive对象,构建Request对象,并将其存入到Requestchannel的 RequestQueue请求队列中;
- 这个时候就该I/O线程池上场了,KafkaRequestHandler线程循环地从请求队列中获取Request实例,然后交由KafkaApis的handle方法,执行真正的请求处理逻辑,并最终将数据存储到磁盘中;
- 待处理完请求后,KafkaRequestHandler线程会将Response对象放入Processor线程的Response队列;
- 然后Processor线程通过Request中的ProcessorID不停地从Response队列中来定位并取出Response对象,返还给Request发送方;
设计思路:
- 顺序处理模式:broker依次accept生产者提交上来的请求, 然后进行处理并存储到磁盘上,存在两个缺陷:请求阻塞:只能顺序处理每个请求,即每个请求都必须等待前一个请求处理完毕才能得到处理;吞吐量非常差:由于只能顺序处理,无法并发,效率太低,所以吞吐量非常差,只适合请求发送非常不频繁的系统;
- 多线程异步处理模式:broker依次accept生产者提交上来的请求,但是这时候 Kafka 系统会为每个请求都创建一个单独的线程来处理,存在的好处在于,多线程提高了吞吐量,并且线程异步不会阻塞其他线程;存在的缺陷在于为每个请求都创建线程的做法开销很大,并且线程不受控制;
- IO多路复用机制的事件驱动 - Reactor模式:当Client端将请求发送到Server端的时候, 首先在Server端有个多路复用器(Selector),然后会启动一个Accepter线程将 OP_CONNECT事件注册到多路复用器上, 主要用来监听连接事件到来;当监听到连接事件后,就会在多路复用器上注册OP_READ事件, 这样Cient端发送过来的请求, 都会被接收到。如果请求特别多的话, 我们这里进行优化, 创建一个Read HandlePool线程池;当 Read HandlePool线程池接收到请求数据后,最终会交给Handler ThreadPool线程池进行后续处理;
- 超高并发的情况下一个Selector多路复用器是支撑不住的,为了减轻当前 Selector 的处理负担,引入另外一个Selector 处理队列,来分摊多个client端请求处理;
Kafka网络通信架构主要由两大部分构成:SocketServer 和 RequestHandlerPool:
- SocketServer组件是Kafka超高并发网络通信层中最重要的子模块;它包含Acceptor线程、Processor线程和RequestChannel等对象,都是网络通信的重要组成部分。它主要实现了Reactor设计模式,主要用来处理外部多个Clients(这里的Clients可能包含Producer、Consumer或其他Broker)的并发请求,并负责将处理结果封装进Response中,返还给Clients;
- RequestHandlerPool组件就是我们常说的I/O工作线程池,里面定义了若干个I/O线程,主要用来执行真实的请求处理逻辑;跟RequestHandler相比,Acceptor、Processor线程 还有RequestChannel等都不做请求处理, 它们只是请求和响应的搬运工;