【C字符串函数】字符串函数和内存操作函数模拟实现(进阶版)
【C字符串函数】字符串函数和内存操作函数模拟实现(进阶版)

不能听命于自己者,就要受命于他人。

字符串函数无论对于C++方向从业者意义重大(使用率高),而且对于求职面试更是一大重点(笔试常被问到模拟实现)
文章目录
- 0.说在前面的话:
- 1.求字符串长度
- 1-1strlen求串长
- 2.长度不受限的字符串函数
- 2-1strcpy拷贝
- 2-2strcat追加
- 2-3strcmp比较
- 3.长度受限的字符串函数
- 3-1strncpy拷贝(限)
- 3-2strncat连接(限)
- 3-3strncmp比较(限)
- 4.字符串查找
- 4-1strstr找子串
- 4-2strtok切割
- 5.错误信息报告
- 5-1strerror打印错误信息
- 6.字符操作
- 6-1字符分类函数(判断) & 6-2字符转换(转换)
- 7.内存操作函数
- 7-1memcpy(内存拷贝)
- 7-2memmove(内存移动)
0.说在前面的话:
- 字符串函数的基本使用要包含头文件:#include<string.h>
- 字符串以’\0’作为结束标志,
- 字符串函数出现的size_t就是unsigned int无符号整型
- 下面出现的assert是断言,要包含头文件**#include<assert.h>**
- 下面的介绍我将从🚗重要知识🚗函数原型🚗基本使用🚗模拟实现 四个方面来一一介绍
1.求字符串长度
1-1strlen求串长
- 全称:string length
- strlen函数返回的是字符串函数’\0’前面出现的字符个数,也就是可见长度,或者是有效长度
- 函数的返回值是size_t是无符号的(易错)
函数原型:size_t strlen(const char* str)
基本使用:
int main()
{
char arr1[] = "hello world";//[hello world\0]
//char arr2[]={'h',\0','t'};//必须带有'\0',否则长度未知('\0'出现的位置随机)
int len = strlen(arr1);
printf("%d\n", len);
return 0;
}易错知识:size_t(坑坑坑):–错误代码示例
int main()
{
char* p1 = "abc";
char* p2 = "abcdef";
if (strlen(p1) - strlen(p2) > 0)//关键点
{
printf("haha\n");
}
else
{
printf("hehe\n");
}
return 0;
}我就不买关子;答案:haha
原因:(算术转换) 两个无符号整型相减得到-3,但是-3在内存读取的时候是以无符号数来看待,所以"符号位"的1其实把他变成了一个很大的数.(两个无符号整数相减还是一个无符号整型)
解决办法: 1.写成if( strlen(p1)>strlen(p2) )的形式 2.强制转换为if( (int)strlen(p1)-(int)strlen(p2) )的形式
模拟实现: 此函数我有专门讲过,欲知速戳三种方法模拟实现strlen函数
2.长度不受限的字符串函数
2-1strcpy拷贝
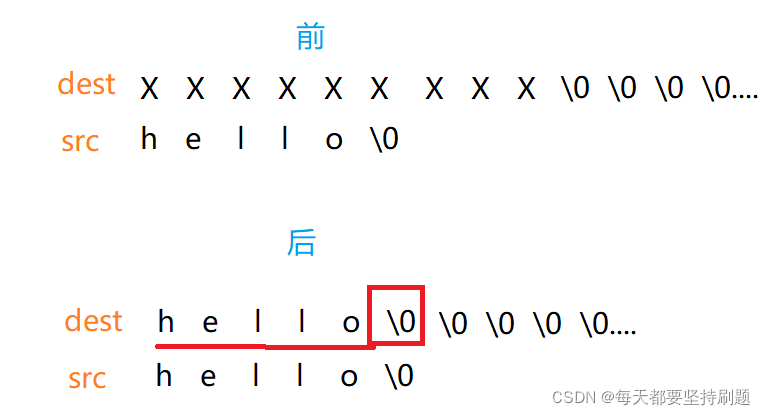
- 源字符串必须以’\0’结束
- 会将源字符串中的’\0’拷贝到目标空间中
- 目标空间必须足够大,以确保能存放源字符串
- 目标空间必须可变
函数原型:char* strcpy(char* dest,const char* src)
- dest, 全称:destination,-指向用于存储复制内容的目标数组
- src,全称:source, -指向要复制的字符串
- dest,src的左右位置,也正符合左值空间,右值内容
基本使用 :
int main()
{
char arr1[30] ="XXXXXXXXX";//1.arr[]是通过直接将字符串放到arr[]这块内存中 2.不能省30且目标空间足以容纳源空间hello
char* str = "hello";//字符指针str通过指向的是hello这块常量字符串
//char arr2[]={'h','e','l','\0','o'};正确
//char arr2[]={'h','e','l','l','o'};错误(没有遇到'\0',越界访问,停不下来)
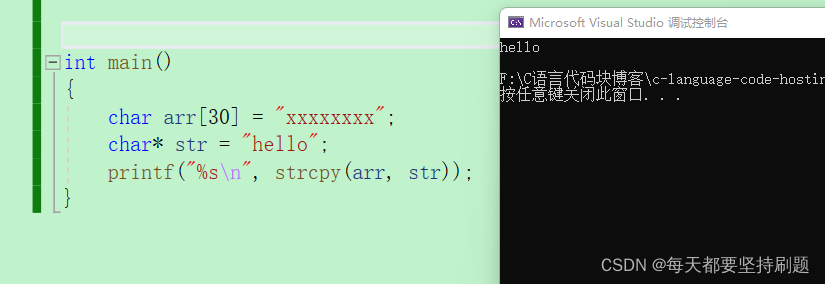
printf("%s\n", strcpy(arr, str));//1.返回char*类型的dest空间的起始地址 2.链式访问
}运行结果:
简单图解:
模拟实现:
优化一下:
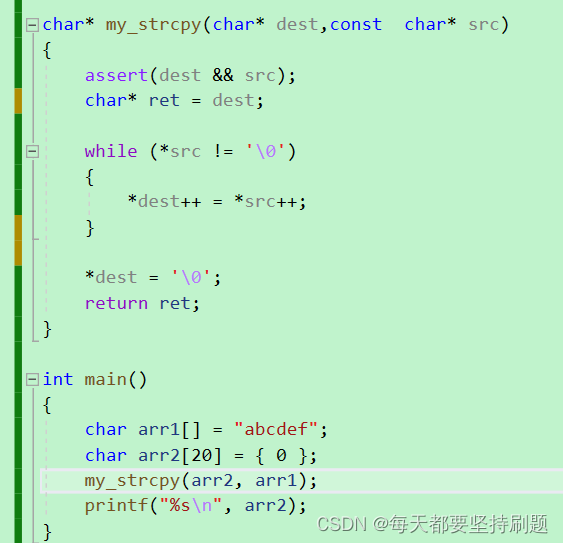
char* my_strcpy(char* dest, const char* src)
{
assert(dest&&src);
char* ret = dest;//ret保存dest的初始位置(后面dest会移动)
while (*dest++=*src++);//1.赋值 2.++
return ret;
}2-2strcat追加
- 源字符串必须以’\0’结束
- 会将源字符串中的’\0’拷贝到目标空间中(追加完的字符串的’\0’是源字符串的)
- 目标空间必须足够大,以确保能存放源字符串
- 目标空间必须可变(也就是目标空间必须是字符数组,不能是指针指向的常量字符串)
函数原型:char* strcat(char* dest,const char* src)
基本使用:
int main()
{
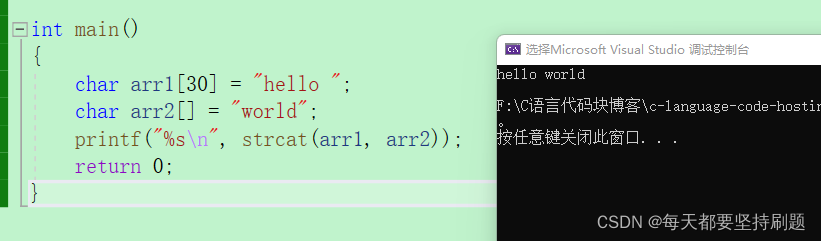
char arr1[30] = "hello ";
char arr2[] = "world";
printf("%s\n", strcat(arr1, arr2));
return 0;
}运行结果:
简单图解:
易错知识:(不能给自己追加)–错误代码示例
printf("%s\n",strcat(arr1,arr2);//自己给自己追加原因:在找到dest的‘\0’后,进行src的的一个字符的拷贝时将dest(其实也是src)的’\0’覆盖掉,追加将无法停下来
模拟实现:
char* my_strcat(char* dest, const char* src)//1.能否被修改决定了是否加const 2.const修饰更安全
{
assert(dest&&src);
char* ret = dest;
while (*dest)//1.找目的地空间的'\0' 2.*dest是*dest!='\0'的简化版
{
dest++;
}
while (*dest++ = *src++);//将src的内容拷贝得到dest中
return ret;
}关于我的一点小理解:模拟strcat=模拟strlen+模拟strcpy 这样理解灵感:模拟strcat的两个步骤
2-3strcmp比较
- 对应比较字符的ASCII值(小写l比大写L的ASCII大)
- 若arr1>arr2,返回正数;
- 若arr1==arr2,返回0;
- 若arr1<arr2,返回负数;
函数原型:int strcmp(const char* str1,const char* str2)
基本使用:
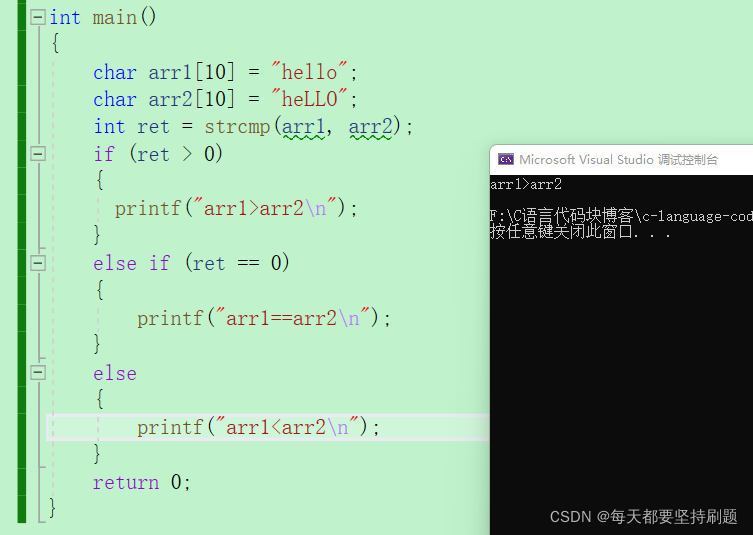
int main()
{
char arr1[10] = "hello";
char arr2[10] = "heLLO";
int ret = strcmp(arr1, arr2);
if (ret > 0)//VS才固定返回1,0,-1,为增加代码可移植性(通用性),不建议采用1,0,-1的方式
{
printf("arr1>arr2\n");
}
else if (ret == 0)
{
printf("arr1==arr2\n");
}
else
{
printf("arr1<arr2\n");
}
return 0;
}运行结果:
模拟实现:
//版本1:
int my_strcmp(const char* str1, const char* str2)
{
while (*str1 && *str1++ == *str2++);//**在遇到\0之前都相等就一直比下去**
return *--str1 - *--str2;
}
//版本2:
int my_strcmp(const char* str1, const char* str2)
{
assert(str1&&str2);
int ret = 0;
while (!(ret = (*str1++) - (*str2++)) && (*str1));//妙不可言
return ret;
}3.长度受限的字符串函数
下列带n字符串函数和不带n的字符串使用规则和性质基本相同,主要区别在于,带n的字符串有长度限制(当n>strlen(src)时,dest的剩余部分将用空字节来填充),当然对于带限制的n的字符串兄弟函数在代码上也就是在while判断的时候多了一个n–的(n!=0)的判断条件.
3-1strncpy拷贝(限)
- n为要从源中复制的字符数
函数原型:char* strncpy(char* dest,const char* src,size_t count)
基本使用:
int main()
{
char arr1[20] = "xxxxxxxx";
char arr2[] = "hello";
printf("%s\n", strncpy(arr1, arr2, 4));
return 0;
}运行结果:

模拟实现:
char* my_strncpy(char* dest, const char* src,size_t count)
{
assert(dest&&src);
const char* ret = dest;
while(count--&&*dest++=*src);
return ret;
}3-2strncat连接(限)
函数原型:char* strncat(char* dest,const char* src,size_t count)
基本使用: 模拟实现:
char* my_strcat(char* dest, const char* src,int n)
{
assert(dest&&src);
char* ret = dest;
while (*dest)//找到dest的'\0'位置
{
dest++;
}
while (n--&&*dest++ = *src++);//从src拷贝n个字符/src指向的那个字符串的字符个数到dest
//*dest = '\0';前面并没有从src拷贝'\0'过dest,但dest本身后面都是'\0'所以可以不写这一步
return ret;
}3-3strncmp比较(限)
函数原型:int strcmp(const char* str1,const char* str2,size_t count)
基本使用:
int main()
{
char arr1[20] = "hello";
char arr2[20] = "hello";
int ret=strncmp(arr1, arr2,5);
printf("%d\n", ret);
return 0;
}模拟实现:
//
int my_strncmp(const char* str1, const char* str2,int n)
{
assert(str1&&str2);
while (n--&&*str1==*str2&&*dest)//拷贝结束或*str1!=*str2或*dest=='\0'结束
{
str1++;
str2++;
}
return *str1 - *str2;//内容相减得到的是字符的ASCII值的差值;>0代表*str1>*str2
}4.字符串查找
4-1strstr找子串
- 在arr1种查找子串arr2
- 找到则返回第一个子串的首地址,没找到则返回NULL
- 类似的算法:KMP算法-KMP优点:更高效
函数原型:char* strstr(const char* str1,const char* str2)
基本使用:
int main()
{
char* arr1 = "abbbcde";
char* arr2 = "bbcde";
char* ret=strstr(arr1,arr2);
if(ret==NULL)
{
printf("找不到\n";
}
else
{
printf("找到了,%s\n",ret);
}
return 0;
}模拟实现:
char* my_strstr(const char* str1, const char* str2)
{
assert(str1&&str2);
char *s1 = str1;
char *s2 = str2;
char* p = str1;//p用于记录s1每次是从哪里开始的,方便后续s1!=s2时,s1从哪里开始
if (*s2 == '\0')//如果查找的子串为空,则自定义返回为str1,也可返回空
{
return str1;
}
while(*p)//原本传过来的str1就为空,或s1已经是最后一个有效字符;
{
s1 = p;//s1每次从上一次保存位置的下一个开始
s2 = (char*)str2;//s2每次从str2开始
while (*s1 && *s2 && ( * s1 == *s2))
//结束循环的三种路径:
//1.s1为'\0',即被查找完毕都没找到子串
//2.s2为'\0',即遍历s2,说明在s1中找到了子串
//3.*s1!=*s2,即不相等
{
s1++;
s2++;
}
if (*s2 == '\0')//s2此时为0,说明s2中的字符已被查找完->子串查找成功
{
return (char*)p;//p被const修饰,避免类型差异报错,故强制转换为char*类型
}
p++;//如果s1!=s2,标记处后移一位
}
return NULL;//没找到,返回NULL
}4-2strtok切割
函数原型:char* strtok(char* str,const char* sep);
- sep参数是个字符串,定义了用作分隔符的字符集合
- 第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
- strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。
- (注: strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
- strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串 中的位置。
- strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
- 如果字符串中不存在更多的标记,则返回NULL 指针
基本使用:
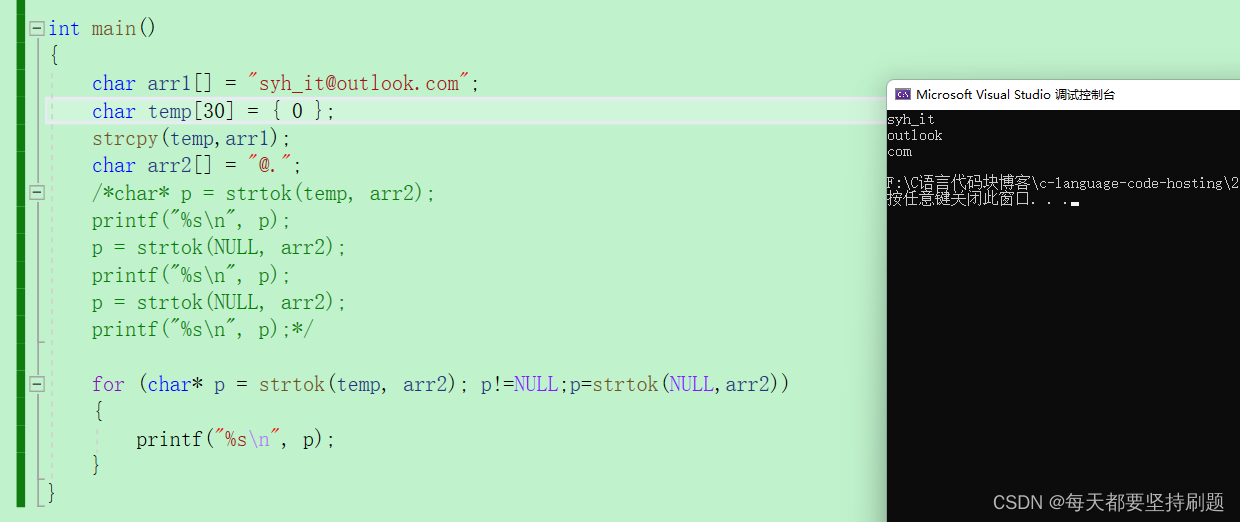
int main()
{
char arr1[] = "syh_it@outlook.com";
//因为切割过程会改变arr1,所以对arr1拷贝,仅是对拷贝的字符数组进行操作
char temp[30] = { 0 };//
strcpy(temp,arr1);
char arr2[] = "@.";//分隔符
/*char* p = strtok(temp, arr2);
第一次调用
temp!=NULL,向后找@的位置,找到将@改为'\0',并做好标记,下次直接从'\0'处开始找
printf("%s\n", p);
p = strtok(NULL, arr2);
第二次调用
从上次记录的位置开始,找到下一个标记符
printf("%s\n", p);
p = strtok(NULL, arr2);
printf("%s\n", p);*//函数内部有记忆,出了函数并没有销毁,猜测有static修饰
for (char* p = strtok(temp, arr2); p!=NULL;p=strtok(NULL,arr2))
{
printf("%s\n", p);
}
}运行结果:
5.错误信息报告
5-1strerror打印错误信息
- 返回错误码所对应的错误信息
- 当库函数调用有问题时,就会产生错误码,如文件打开失败
- 类似网页错误码404,而strerror的作用就是将错误码转换为人可识别的错误信息打印出来
- 额外引用头文件:#include<errno.h>
函数原型:char* strerror(int errnum)
int main()
{
FILE* fp = fopen("text1.txt", "r");
if (fp == NULL)
{
// errno 没有错误默认为0
//No error 表示没有错误
printf("%s\n", strerror(errno));
//perror较strerror的优点:当要打印的错误信息比较多的时候,perrror可以附加错误信息的备注 的优点可以完美展现
perror("每天都要记得刷题的个人信息");
}
else
{
printf("%s\n", "打开成功");
fclose(fp);
fp = NULL;
}
return 0;
}6.字符操作
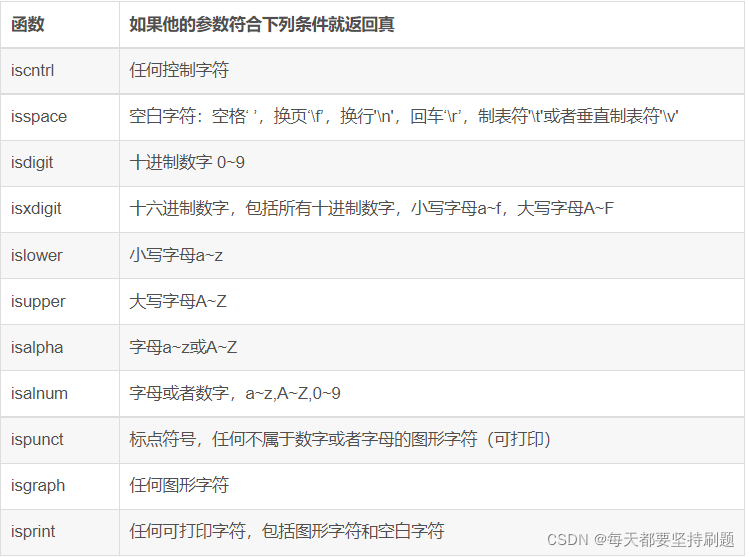
6-1字符分类函数(判断) & 6-2字符转换(转换)
使用举例:
int main()
{
char ch = 'A';//'A':65
//printf("%c\n", ch + 32);//'a':97
printf("%c\n", tolower(ch));
//注意 : tolower(ch)返回值是小写字母的ASCII码值,而不是把ch从大写改变成了小写
//需要头文件 #include <ctype.h>
//把字符串中的大写改为小写
char str[] = "Test String.\n";
char c;
int i = 0;
while (str[i]!='\0')
{
c = str[i];
if (isupper(c))//大写?
{
c = tolower(c);//转换为小写
}
putchar(c);
i++;
}
return 0;
}7.内存操作函数
7-1memcpy(内存拷贝)
函数原型:void* memcpy(void* dest,const void* src,size_t num)
- 这个函数不止能用于字符数组的拷贝,扩大至整型数组
- 这个函数在遇到’\0的时候并不会停下来,也不一定需要’\0’
- 如果dest目标空间和src源空间有任何的重叠,复制的结果会因为位置的不同产生两种结果(内存不可重叠) ,只能用memmove函数
基本使用:
int main(){
int arr1[5] = { 1,2,3,4,5 };
int arr2[10] = { 0 };
//将arr1拷贝到arr2中
memcpy(arr2, arr1, 20);
for (int i = 0; i < 10; i++)
{
printf("%d\t", arr2[i]);
}
return 0;
}模拟实现:
void* my_memcpy(void* dest, void* src)
{
assert(dest && src);
void* ret = dest;
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}
int main()
{
assert(dest&&src);
void* ret = dest;
while (count--)//按字节数复制,因为可能要复制的count不是int字节的整数倍
{
*(char*)dest = *(char*)src;//char*强转告诉dest和sec+1加多少个步长
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}7-2memmove(内存移动)
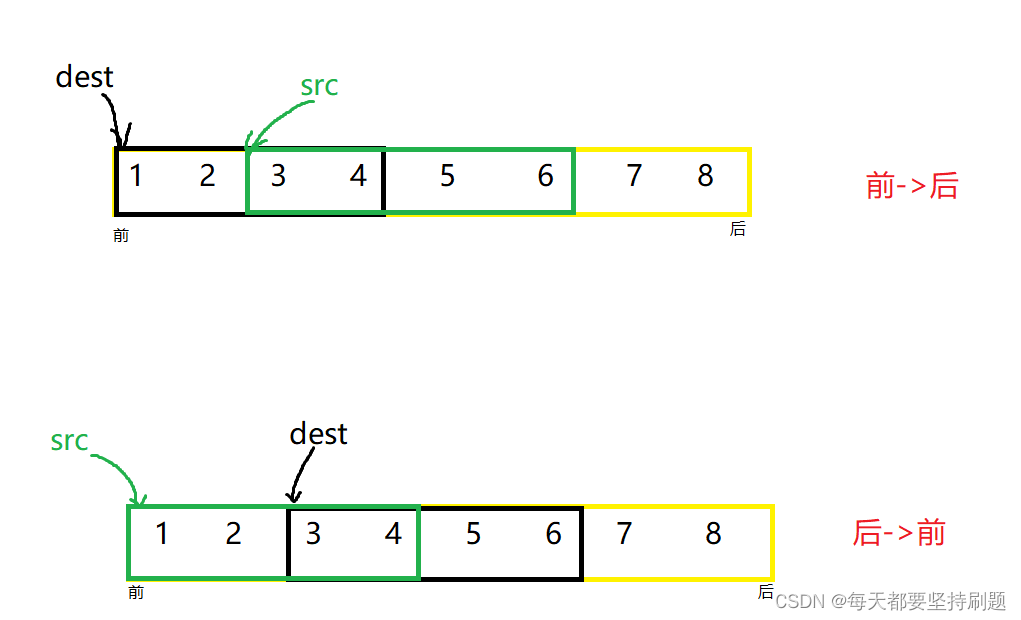
- 解决当dest和src有重叠部分,引发的问题(内存可重叠)
函数原型:void* memcpy(void* dest,const void* src,size_t num) 基本使用:
int main()
{
int arr1[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
//将1 2 3 4 拷贝到3 4 5 6的位置
memmove(arr1 + 2, arr1, 16);
return 0;
}
模拟实现:
void* my_memmove(void* dest, const void* src, size_t count)
{
assert(dest&&src);
void* ret = dest;
//当dest和src有重叠的时候,要分情况
if (dest < src)//当dest在src左边,src应该从前向后拷贝
{
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
else//当dest在src右边src从后向前拷贝
{
while (count--)
{
*((char*)dest + count) = *((char*)src + count);
}
}
return ret;
}腾讯云开发者
