谷歌再憋大招,最新Jupiter数据中心网络“光“芒四射!

谷歌再憋大招,最新Jupiter数据中心网络“光“芒四射!

用户6874558
发布于 2023-02-16 15:06:06
发布于 2023-02-16 15:06:06
前言
2015年SIGCOMM,谷歌首次披露自家数据中心网络Jupiter的架构,Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network;时隔7年后,谷歌再次在SIGCOMM更新Juniper的最新进展,Jupiter Evolving: Transforming Google’s Datacenter Network via Optical Circuit Switches and Software-Defined Networking。本文为大神Amin,谷歌VP/GM Systems and Services Infrastructure关于Jupiter最新进展的总结。关于谷歌网络的前世今生,欢迎订阅专题:谷歌云网络
数据中心网络是仓库规模计算和云计算的基础,网络底座保证数以万计的服务器之间以数百Gb/s的速率和不足100us的延迟进行统一、任意间的通信,从而改变了计算和存储。这种模式的主要优势显而易见又意义深刻:只要为更高阶的服务增加相应的服务器或存储设备,那么服务容量和能力就会得到相应的提升。在谷歌,我们的Jupiter数据中心网络技术就提供了这种扩展能力,为我们的用户提供基础服务如搜索、YouTube、Gmail和云服务,包括人工智能和机器学习、计算引擎、BigQuery分析、Spanner数据库等。
在过去的八年里,我们将optical circuit switching(OCS)和波分复用(WDM)深度整合到Jupiter中。虽然几十年来的传统脑袋壳认为这样做是不切实际的,但OCS与我们的软件定义网络(SDN)架构的结合实现了新的功能:支持异构技术的增量网络建设;更高的性能和更低的延迟、成本和功耗;实时的应用优先级和通信模型;以及零下线的升级。Jupiter做到了这一切,同时将流量完成时间降低了10%,将吞吐量提高了30%,功耗降低了40%,相应成本降低了30%,并比已知的最佳类似方案降低50倍的宕机时间。你可以在SIGCOMM 2022上发表的论文中了解更多关于我们是如何做到这一点的。
以下是本项目的概述:
Jupiter数据中心网络的演进
2015年,我们展示了谷歌的Jupiter数据中心网络如何扩展到支持超过30,000台服务器,每台服务器的连接速度统一为40Gb/s,支持超过1Pb/sec的总带宽。今天,Jupiter支持超过6Pb/sec的数据中心带宽。我们通过遵循三个理念实现了这种前所未有的性能和规模。
- 软件定义网络(SDN):一个逻辑上集中和分层的控制平面,用于编程和管理数据中心网络中成千上万的交换芯片;
- Clos拓扑结构:一种非阻塞的多级交换拓扑结构,由较小radix的交换芯片构成,可以扩展到任意大的网络;
- 商用交换芯片:用于融合存储和数据网络的具有成本效益的通用以太网交换器件;
基于这三个支柱,Jupiter的架构方法支持了分布式系统架构的巨大变化,并为整个行业如何构建和管理数据中心网络开山辟道。
然而,超大规模数据中心的两个主要挑战仍然存在。首先,数据中心网络需要以整个机房的规模部署,可能是40MW或更多的基础设施。此外,部署在大楼里的服务器和存储设备总是在不断发展,例如从40Gb/s到100Gb/s到200Gb/s,再到今天的400Gb/s本机网络互连。因此,数据中心网络需要动态发展才能匹配挂接其上的新玩意的步伐。
不好的是,如下图所示,Clos拓扑结构需要Spine层对可能连接到它的最快设备有一致性的支持。部署一个机房规模的、基于Clos的数据中心网络意味着需要预先部署一个非常大的Spine层,设备需要具备当前最新一代的网络速度。这是因为Clos拓扑结构本质上需要从汇聚层块1到Spine层的all-to-all全扇出,逐步增加Spine将需要重新为整个数据中心布线。想要加入更快速率的新设备的一种方法是更换整个Spine层,但这是不现实的,因为机房有数百个独立的交换机机架和数以万计的光纤对贯穿整个大楼。
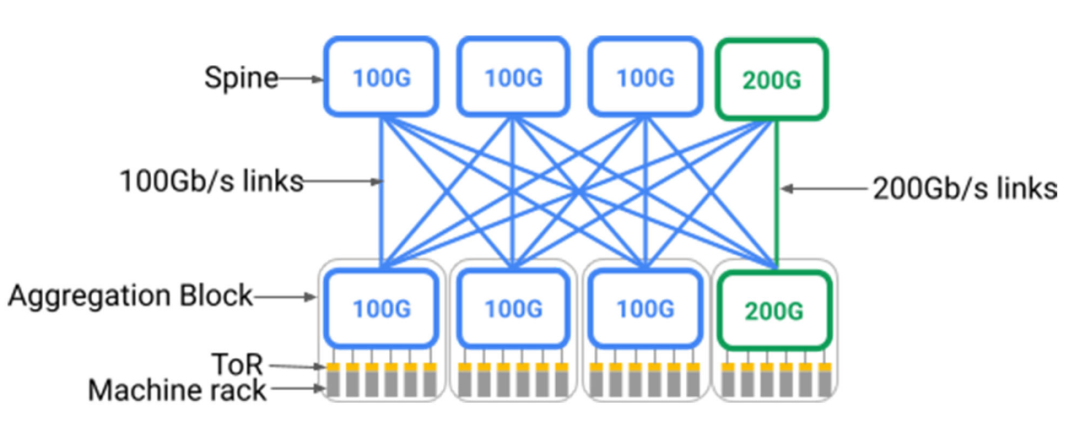
图:带200Gb/s端口速度的新汇聚块(绿色)与3个原有的100Gb/s端口速度的Spine块(蓝色)和1个新的200Gb/s端口速度的Spine块(绿色)相连。在这个模型中,只有新汇聚块和新Spine块间25%的的链接是以200Gb/s的速度运行。
注:汇聚层块包括一组设备(计算/存储/加速器)机架,包括由架顶(ToR)交换机连接的一层通常共柜的交换机。
理想情况下,数据中心网络将以 "按需付费 "的模式支持异构网络单元,仅在需要时才增加新单元,并逐步支持最新一代的技术。网络将和服务器和存储一样支持理想化地扩展模式,可以逐步增加网络容量,即使与之前部署的技术不同,也可以提供相应的容量增长,并与整个机房的设备天然相互匹配。
其次,虽然机房规模的带宽速率统一是一个优势,但当你考虑到数据中心网络本质上是多租户的,并不断受到维护和局部故障的影响时,它就变得很有局限性。一个数据中心网络承载着数百个单独的服务,其优先级和对带宽和延迟变化的敏感性各不相同。例如,提供实时网络搜索结果可能需要实时延迟保证和带宽分配,而一个多小时的批处理分析任务可能只在短时间内有更灵活的带宽要求。因此,数据中心网络应该根据实时通信模式和应用感知的网络优化来为服务分配带宽和路径。理想情况下,如果有10%的网络容量需要暂时下线做升级,那么这10%就不应该统一由所有租户分担,而是应该根据应用的各自要求和优先级进行分配。
起初解决上述的挑战似乎是不可能的。数据中心网络是围绕着分层拓扑结构而建立的大规模物理设施,这样就无法将支持增量异构以及动态地应用适配纳入设计中。我们通过开发并在Jupiter架构中引入光路交换机(OCS)来打破这一僵局。光路交换机(如下图所示)通过两组可在两个维度上旋转的微机电系统(MEMS)镜面,动态地将光纤输入端口映射到输出端口,从而实现任意的端口对端口的映射。
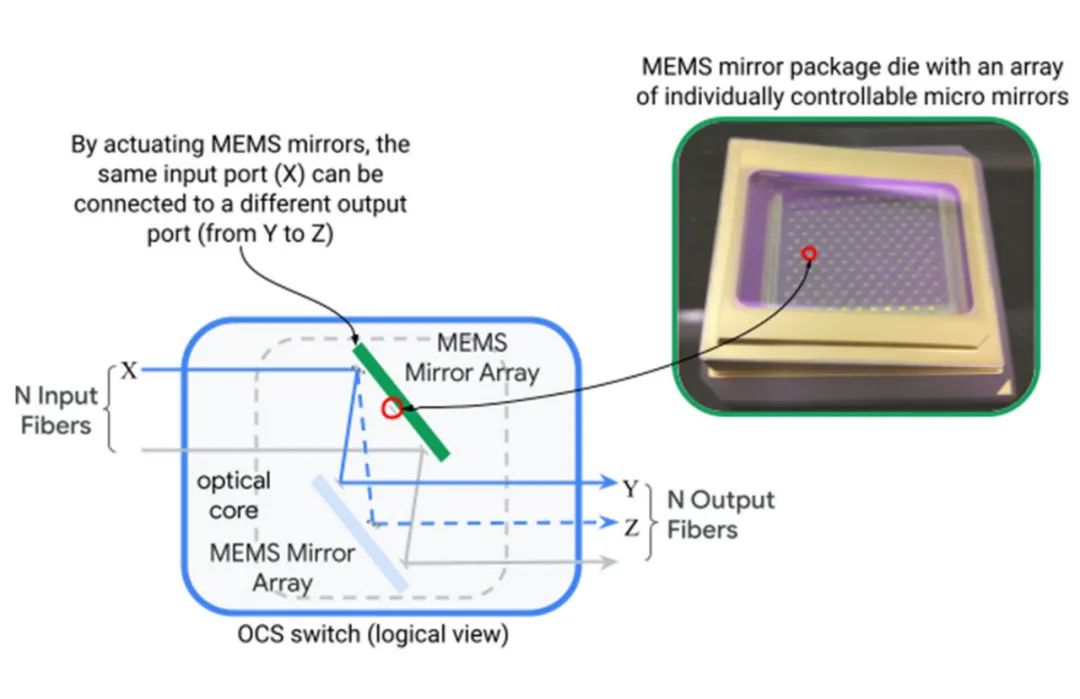
图:单个OCS设备通过MEMS镜面将N个输入光纤映射到N个输出光纤的过程
通过在数据中心交换机之间引入OCS中间层,我们发现可以为数据中心网络创建任意的逻辑拓扑结构,如下图所示。
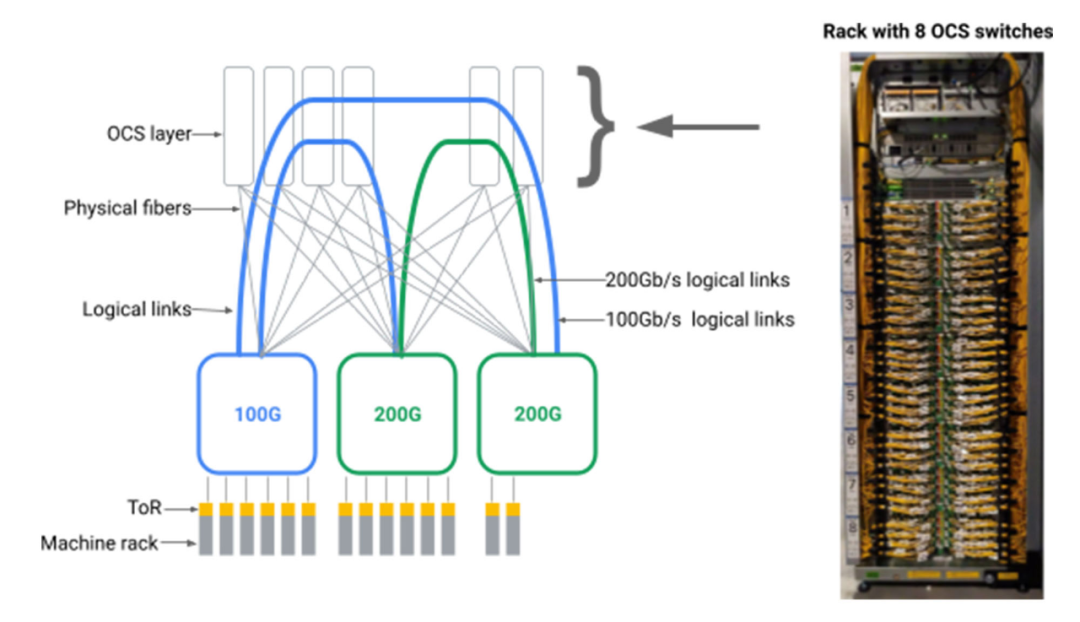
图:汇聚层块通过光纤连接到OCS交换机。通过配置每个OCS交换机来连接输入和输出光纤的排列组合,可以实现不同逻辑拓扑结构。
这种方式就要求我们前所未有的实现规模化的、可制造的、可编程的和可靠的OCS和原生WDM收发器。虽然学术研究认可光交换的好处,但传统观念认为OCS技术在商业上是不可行的。经过多年的努力,我们设计并建造了Apollo OCS,它现在是我们绝大部分数据中心网络的基础。
OCS的一个突出优点是在其工作中不涉及数据包路由或头部解析。OCS只是简单地将光从一个输入端口反射到一个输出端口,而且高精度低损耗。这些光是通过WDM收发器的电光转换产生的,而WDM收发器已经用在数据中心机房可靠而有效地传输数据。因此,OCS是建筑基础设施的一部分,它对数据速率和波长无感,即使电气基础设施的传输和编码速率从40Gb/s到100Gb/s再到200Gb/s,它也不需要进行升级。
有了OCS层,我们在数据中心网络中消除了Spine层,而是以直接网状方式连接异构汇聚层块,首次在数据中心中超越了Clos拓扑架构。我们创建了动态的逻辑拓扑,可以同时反映出物理容量和应用的通信模式。现在,交换机视角下的逻辑连接重新配置在谷歌网络中是个标准的操作流程,动态地将拓扑结构从一种模型变换到另一种模型,并不会对应用产生可见的影响。我们通过路由软件、OCS重配置以及链路消耗的协同,依靠谷歌的Orion软件定义网络控制平面来无缝编排成千上万的或关联或独立的操作。(参考阅读:谷歌第二代SDN控制器Orion终露峥嵘)
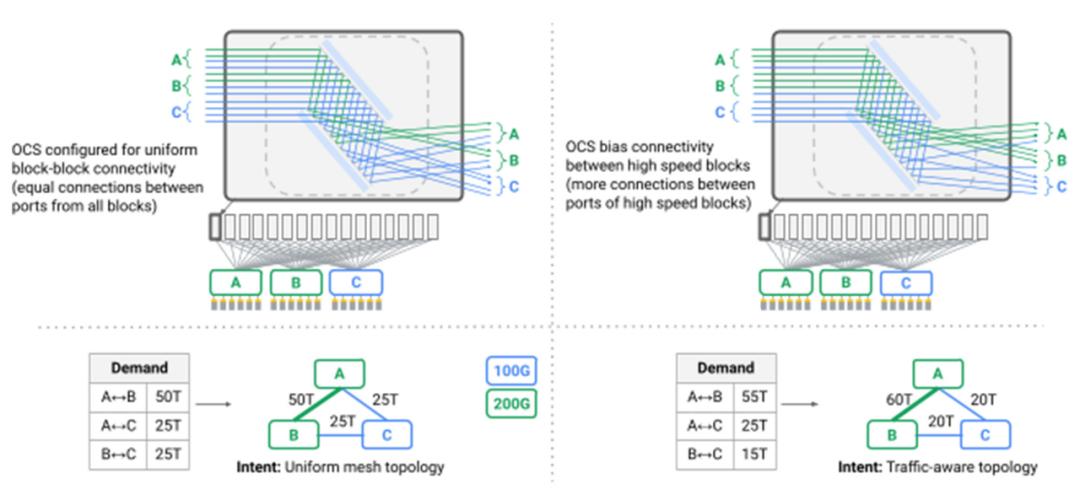
图:多个OCS实现的拓扑工程
一个特别有趣的挑战是,网状拓扑结构上的最短路径路由首次不能再提供我们数据中心所需的性能和稳健性。典型的Clos拓扑架构的一个副作用是,虽然网络中存在多条路径,但所有路径都有相同的长度和链接容量。这种情况下,健忘(oblivious)报文分配或Valiant负载平衡可以提供足够的性能。在Jupiter中,我们利用我们的SDN控制平面来引入动态的流量工程,采用为谷歌B4广域网开创的技术:我们在多个最短和非最短路径之间分配流量,同时观察链路容量、实时通信模型和单个应用程序的优先级(下图中的红色箭头)。(参考阅读:谷歌云网络仙女座SDN免费提速!)
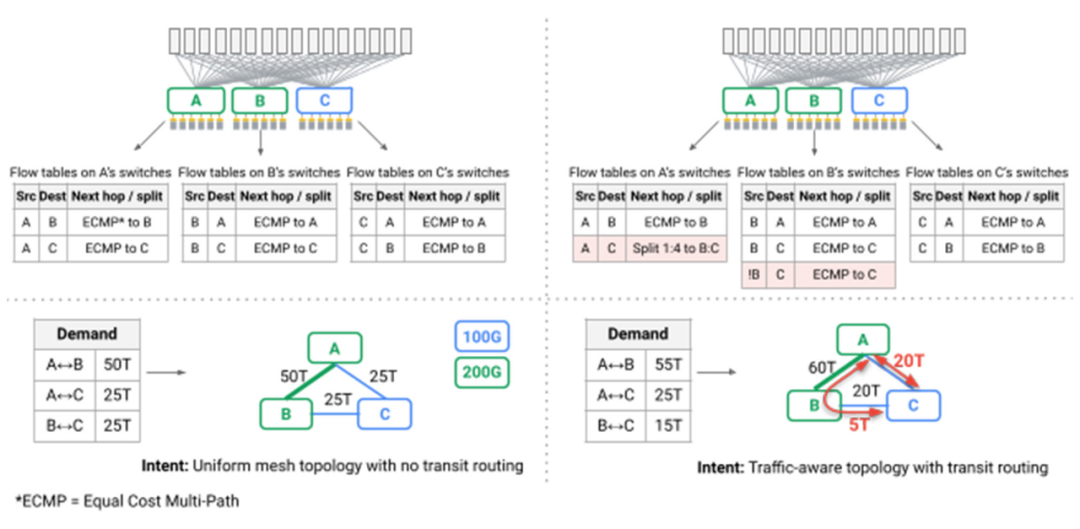
图:实现流量工程的交换机上的流表
总的来说,我们已经完整地迭代重构了为谷歌仓库规模的计算机提供动力的Jupiter数据中心网络,并在此过程中引入了许多行业第一。
- 光交换机作为机房规模网络的互操作点,可以无缝支持异构技术,满足升级和各种服务要求;
- 直接采用网状的网络拓扑结构,用以实现更高的性能、更低的延迟、更低的成本和更低的功耗;
- 实时拓扑和流量工程实现网络连接和路径的同时调整,满足匹配应用优先级和通信模型的需求,还可以观察到实时维护和故障;
- 通过局部增加/减少网络容量进行Hitless网络升级,避免了对昂贵且繁琐的 "所有服务退出 "式的升级的需要,这种升级以前需要迁移数百个客户和服务以便延长机房的停机时间;
虽然底层技术令人眼前一新,但我们工作的最终目标是继续提供性能、效率和可靠性,共同为支持谷歌和谷歌云的最苛刻的分布式服务提供变革性能力。如上所述,我们的Jupiter网络比我们所知的最佳类似方案要少消耗40%的电力,减少30%的成本,并降低50倍的停机时间,同时减少10%的流量完成时间,提高30%的吞吐量。我们很自豪能在SIGCOMM会议上分享这一技术成就的细节,并期待着与社区讨论我们的发现。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-09-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号