BeautifulSoup4 中文乱码

BeautifulSoup4解析页面的时候发现有一部分内容是乱码,刚开始还以为是pycharm的问题,后来发现可能问题不是出在pycharm上,因为普通的print打印的中文是没有问题的。测试代码如下:
def proxy_get(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
req = requests.get(url, headers=HEADERS)
return req.text
def get_sub_pages_test(url):
'''
http://www.meitulu.cn/t/shishen/
:param url:
:return:
'''
bs = BeautifulSoup(proxy_get(url), "html.parser")
boxes = bs.find('div', class_='boxs')
lis = boxes.find_all('li')
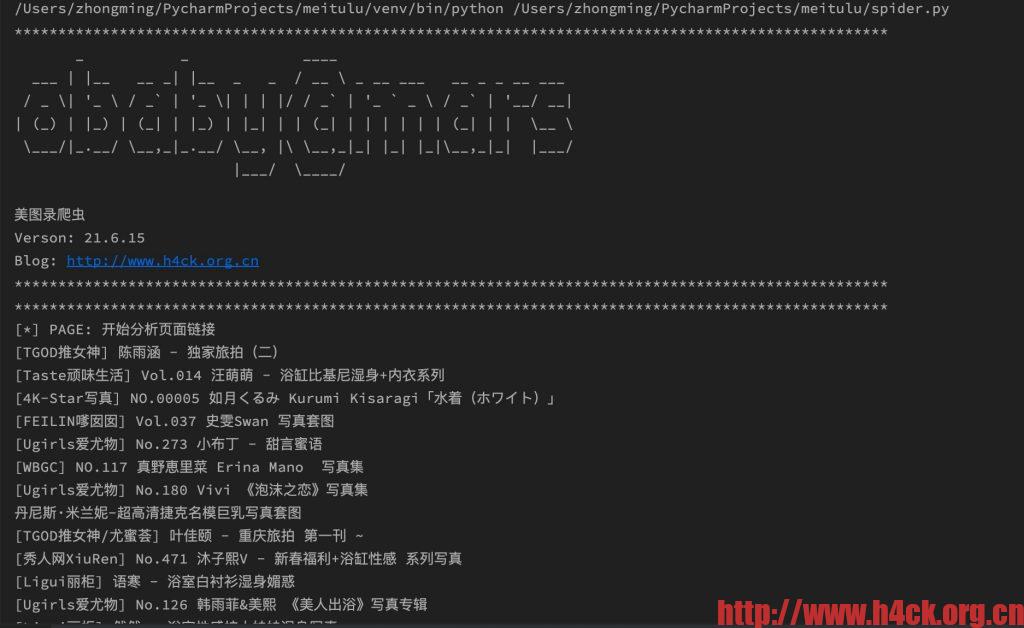
log_text('PAGE', '开始分析页面链接', is_begin=True)
for l in lis:
p = l.find('p', class_='p_title')
print( p.text)后来想到可能是网络请求编码导致的,那么只要修改请求代码添加编码信息即可。
def proxy_get(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
req = requests.get(url, headers=HEADERS)
req.encoding = 'utf-8' #设置编码格式
return req.text此时再去请求就ok了。
☆文章版权声明☆
* 网站名称:obaby@mars
* 网址:https://h4ck.org.cn/
* 本文标题: 《BeautifulSoup4 中文乱码》
* 本文链接:https://h4ck.org.cn/2021/06/beautifulsoup4-%e4%b8%ad%e6%96%87%e4%b9%b1%e7%a0%81/
* 转载文章请标明文章来源,原文标题以及原文链接。请遵从 《署名-非商业性使用-相同方式共享 2.5 中国大陆 (CC BY-NC-SA 2.5 CN) 》许可协议。
分享文章:
相关文章:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2021年6月16日,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
