深度交叉注意力乘积网络DCAP
深度交叉注意力乘积网络DCAP


本文是CIKM2021上中稿的一篇文章,提出了Deep Cross Attentional Product Network(以下简称DCAP),在显式建模高阶特征交互的基础上,引入自注意力机制来刻画不同交叉特征对于预测的重要性,一起来看一下。
1、背景
论文关注的如何通过特征建模,对用户的交互行为进行预测,如用户是否会点击某个广告,是否会对推荐内容产生兴趣等等,如下图所示:
从上图也可以看到,用户的特征往往是多域的离散特征,如国家、性别等。同时,对于交叉特征的建模在预测任务中是十分重要的。由于人工设计交叉特征费时费力,同时对于业务敏感度也有较高的要求,因此业界的研究大都关注如何进行自动化的交叉特征建模,从使用FM来建模二阶的交叉特征,到使用FM和DNN相结合的方法如DeepFM、NFM进一步建模二阶和更高阶的交叉特征。但上述的方法存在两方面的问题:
1)DNN对于交叉特征的建模是隐式的,可解释性差 2)得到的交叉特征,对于所有的样本都使用相同的权重,但对于不同的样本来说,不同的特征的重要程度是不相同的,需要加以区分
上述两方面的问题,其实有一些工作已经进行了优化,如针对隐式建模的问题,有DCN、XDeepFM等相关工作提出;针对特征权重问题,如AFM,以及引入门控机制如GateNet等工作。而本文则是提出了Deep Cross Attentional Product Network,下一章节对DCAP进行介绍。
2、DCAP介绍
论文提出的DCAP整体结构如下图所示:
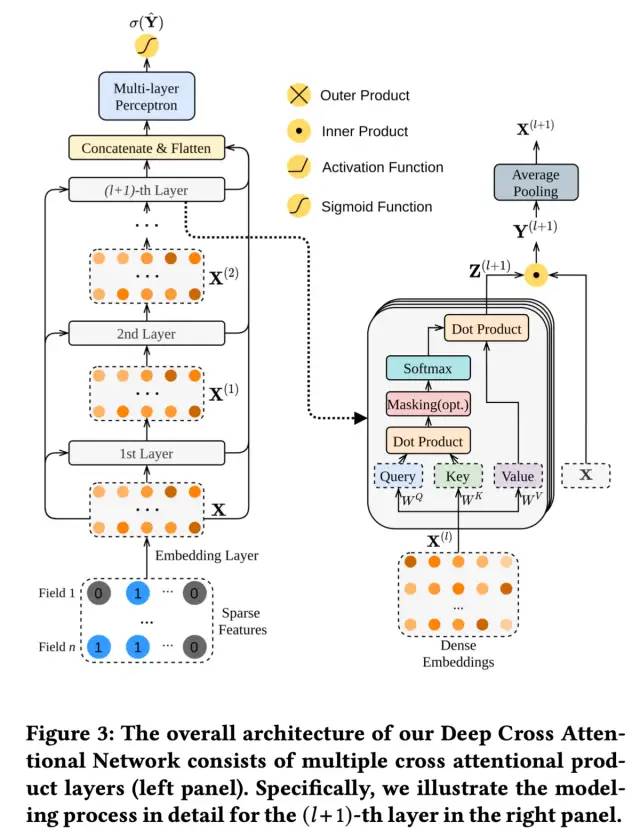
整体的模型结构还是比较容易理解,本文主要对DCAP的核心结构即上图右侧的部分进行介绍。
输入的特征,经过Embedding层,得到最初的输入,计作X(维度为n*d),经过每一层子网络,都会得到相应阶数的交叉特征的输出。接下来,顺着上图右侧,介绍如何从第l阶特征交互X(l)(维度为n*d)得到第l+1层特征交互X(l+1)(维度为n*d)。过程计算如下:
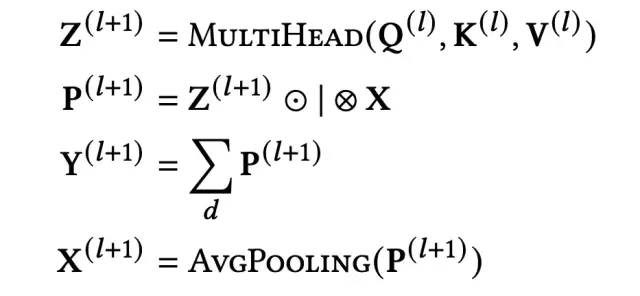
首先X(l)经过多头自注意力网络,得到Z(l+1)(维度为n*d),经过自注意力机制,就实现了对不同交叉特征重要性的区分。关于自注意力机制的内容,网上的内容很多,本文就不再进行赘述。
接下来,通过内积或外积的方式得到vector-vise的乘积向量P(l+1)(维度为n(n-1)/2*d),P(l+1)可以看作是第l+1阶的交叉特征。内积和外积的计算方式如下:

而P(l+1)的维度为n(n-1)/2*d,为什么是n(n-1)/2呢,这里主要是在计算交叉特征时,对下标进行了一定的限制,另一方面,是对第l+1层的自注意力机制部分的输出与原始输入X进行的内积或外积计算,这里使用了DCN的思路显式建模特征交叉:
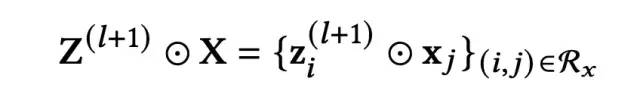
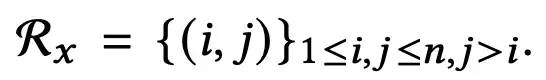
随后,对P(l+1)在最后一维上进行sum pooling操作,得到该层的输出Y(l+1)(维度为n(n-1)/2),作为后续的MLP层的输入:
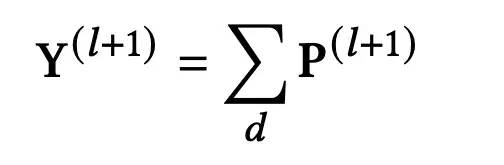
最后,无论是P(l+1),还是Y(l+1),都不能用于下一层的输入,因此需要进一步进行转换,将n(n-1)/2 *d维,转换成n*d维,论文采用的是1D average pooling的方式,将 P(l+1)转换为X(l+1)(从这里可以看出,论文给出的模型结构图是存在一定问题的,个人感觉应该将Y替换为P)。1D average pooling的计算方式如下:
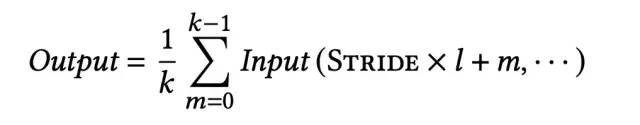
上述就是DCAP核心结构的介绍,在得到每一层的输出Y(l+1)之后,与展平后的X进行拼接,经过MLP后的到预估值:
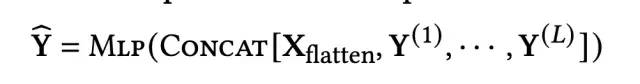
3、实验结果
最后来简单看一下论文的实验结果:
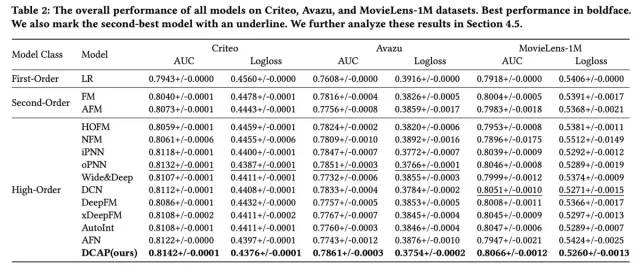
好了,论文就介绍到这里,论文本身在模型结构的创新点并不多,更像是一些现有网络的融合,如DCN、PNN等,感兴趣的小伙伴可以看下原文~~