【Elasticsearch】聚合分析


- 聚合分析
- 什么是聚合分析
- 聚合分析,英文为Aggregation,是es除搜索功能外提供的针对es数据做统计分析的功能
- ES提供多种分析方式: Bucket、Metric、Pipeline、Matrix 等
- Bucket,分桶类型,类似SQL语法中的group by语法。
- Metric,指标分析类型,如计算最大值,最小值,平均值等等。
- Pipeline,管道分析类型,基于上一级的聚合分析结果进行再分析。
- Matrix,矩阵分析类型。
-
- Metric聚合分析(指标分析)
- Metric分析分类
- 单值分析:只输出一个分析结果。
- min(最小值)
- max(最大值)
- avg(平均值)
- sum(总和)
- cardinality(计算数目的,类似sql中的distinct count)
- 多值分析,输出多个分析结果
- stats(多样统计分析,可以一次性得到最小值,最大值,平均值,中值等等)、
- extended stats、percentile(百分位数的统计)、
- percentile rank、top hits(排在前面的结果列表)
- 单值分析:只输出一个分析结果。
-
-
- 单值:最小值
-
GET /czxy2/_search
{
"size": 0, // 不需要返回文档列表
"aggs": {
"min_age": { // 自定义聚合名称
"min": { // 聚合类型
"field": "age"
}
}
}
}
-
-
- 单值:最大值
-
GET /czxy2/_search
{
"size": 0,
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
-
-
- 单值:平均值
-
GET /czxy2/_search
{
"size": 0,
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
-
-
- 单值:求和
-
GET /czxy2/_search
{
"size": 0,
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
}
}
-
-
- 单值:多个结果
-
GET /czxy2/_search
{
"size": 0,
"aggs": {
"min_age": {
"min": {
"field": "age"
}
},
"sum_age": {
"sum": {
"field": "age"
}
}
}
}
-
-
- 多值:Stats
-
- 多值分析之Stats,返回一系列数值类型的统计值,包含min、max、avg、sum和count
GET /czxy2/_search
{
"size": 0,
"aggs": {
"stats_age": {
"stats": {
"field": "age"
}
}
}
}
-
-
- 多值:Extended Stats
-
- 多值分析之Extended Stats,对stats的扩展,包含了更多的统计数据,如方差,标准差等等。
GET /czxy2/_search
{
"size": 0,
"aggs": {
"stats_age": {
"extended_stats": {
"field": "age"
}
}
}
}
-
-
- 多值:percentile
-
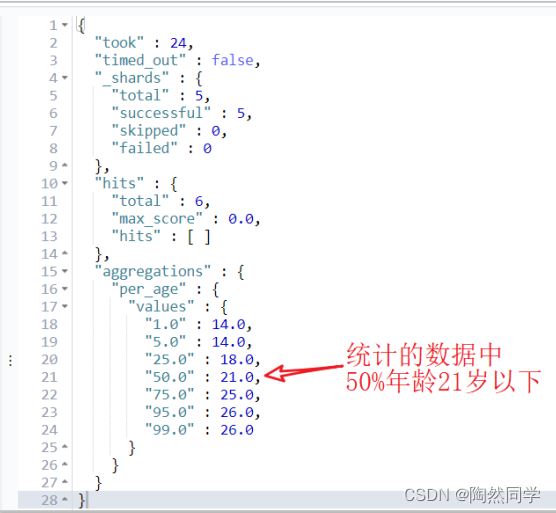
- 多值分析之percentile,百分位数统计,percentiles是关键词。
- 计算99%数据年龄在多少以下(50%年龄的21岁以下)
GET /czxy2/_search
{
"size": 0,
"aggs": {
"per_age": {
"percentiles": {
"field": "age",
"percents": [
1,
5,
25,
50,
75,
95,
99
]
}
}
}
}
-
-
- 多值:percentile_ranks
-
- 14岁及其以下,所占的比例
GET /czxy2/_search
{
"size": 0,
"aggs": {
"per_rank_age": {
"percentile_ranks": {
"field": "age",
"values": [
14,
18,
26
]
}
}
}
}
-
-
- 多值:top hits
-
- 多值分析之top hits,一般用于分桶后获取该桶内最匹配的顶部文档列表,即详情数据
- top_hits的作用就是在每个组下面的数据进行筛选
- size:每组显示的数据
- sort:每组的排序
GET /czxy2/_search
{
"size": 0,
"aggs": {
"group_agg": {
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"top_data": {
"top_hits": {
"size": 2,
"sort": [
{
"_id": {
"order": "desc"
}
}
]
}
}
}
}
}
}
-
- Bucket 聚合分析(分桶)
- Bucket,分桶类型,类似SQL语法中的group by语法
- Bucked,意为桶,即按照一定的规则将文档分配到不同的桶中,达到分类分析的目的。
- 分桶策略:Terms、Range、Date Range、Histogram、Date Histogram。
-
-
- Terms
-
- Bucket聚合分析之Terms,该分桶策略最简单了,直接按照term来分桶,如果是text类型,则按照分词后的结果分桶。
- 按照省份分桶
GET /czxy2/_search
{
"size": 0,
"aggs": {
"city_bucket": {
"terms": {
"field": "city",
"size": 10
}
}
}
}
- 按照用户名分桶
GET /czxy2/_search
{
"size": 0,
"aggs": {
"username_bucket": {
"terms": {
"field": "username",
"size": 10
}
}
}
}

- text的聚合操作,使用fielddata进行处理,需要单独开启
PUT /czxy2/_mapping/user
{
"properties": {
"username": {
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true
}
}
}
-
-
- Range
-
Bucket聚合分析之Range,通过指定数值的范围来设定分桶规则。
GET /czxy2/_search
{
"size": 0,
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [
{
"to": 15
},
{
"from": 15,
"to": 20
},
{
"from": 20
}
]
}
}
}
}
-
-
- Histogram
-
- Bucket聚合分析之Histogram,直方图,以固定间隔的策略来分割数据。
- interval:指定间隔大小
- extended_bounds:指定数据范围
GET /czxy2/_search
{
"size": 0,
"aggs": {
"age_hist": {
"histogram": {
"field": "age",
"interval": 5,
"extended_bounds": {
"min": 10,
"max": 30
}
}
}
}
}
-
- bucket和metric聚合分析整合
- Bucket聚合分析允许通过添加子分析来进一步进行分析,该子分析可以是Bucket也可以是Metric。这也使得es的聚合分析能力变得异常强大。
GET /czxy2/_search
{
"size": 0,
"aggs": {
"city_bucket": {
"terms": {
"field": "city",
"size": 10
},
"aggs": {
"age": {
"stats": {
"field": "age"
}
}
}
}
}
}
-
- 聚合分桶
桶就是分组,比如这里我们按照品牌brand进行分组:
GET /item/_search
{
"size": 0,
"aggs": {
"brands": {
"terms": {
"field": "brand",
"size": 10
}
}
}
}
@Test
public void testAgg() {
//1 聚合条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.addAggregation(AggregationBuilders.terms("brands").field("brand"));
//2 查询获得聚合对象
AggregatedPage<Item> aggPage = (AggregatedPage<Item>)this.itemRepository.search(queryBuilder.build());
//3 解析结果:获得brands聚合内容
ParsedStringTerms agg = (ParsedStringTerms) aggPage.getAggregation("brands");
//4 遍历内容
List<? extends Terms.Bucket> buckets = agg.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.print(bucket.getKeyAsString() + " : ");
System.out.println(bucket.getDocCount());
}
}
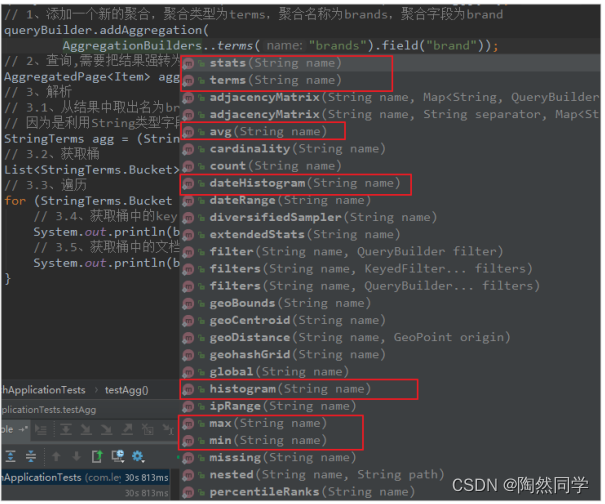
关键API:
- AggregationBuilders:聚合的构建工厂类。所有聚合都由这个类来构建,看看他的静态方法:
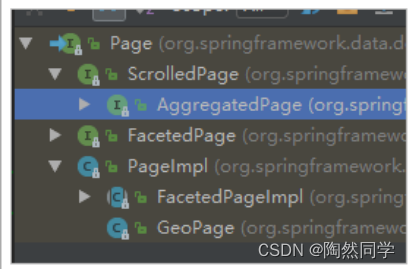
- AggregatedPage:聚合查询的结果类。它是Page<T>的子接口:
AggregatedPage在Page功能的基础上,拓展了与聚合相关的功能,它其实就是对聚合结果的一种封装,大家可以对照聚合结果的JSON结构来看。
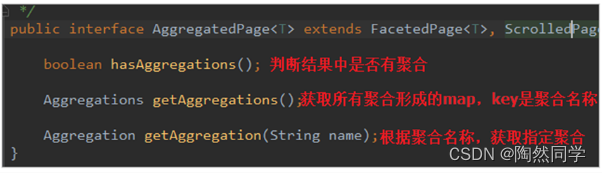
而返回的结果都是Aggregation类型对象,不过根据字段类型不同,又有不同的子类表示
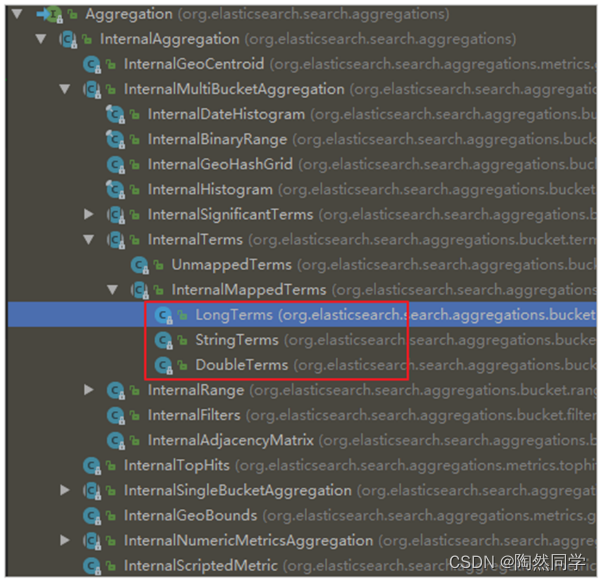
我们看下页面的查询的JSON结果与Java类的对照关系:
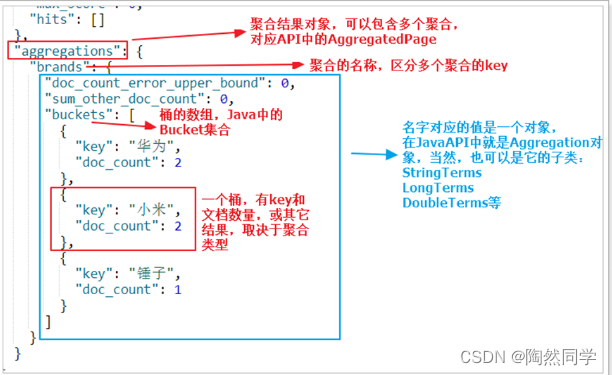
-
- 嵌套聚合
GET /item/_search
{
"size": 0,
"aggs": {
"brands": {
"terms": {
"field": "brand",
"size": 10
},
"aggs": {
"price_range": {
"range": {
"field": "price",
"ranges": [
{
"to": 3300
},
{
"from": 3300,
"to": 4000
},
{
"from": 4000
}
]
}
}
}
}
}
}
@Test
public void testSubAgg() {
//1 聚合条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//1.1 设置品牌聚合
TermsAggregationBuilder brandAgg = AggregationBuilders.terms("brands").field("brand");
//1.2 设置子聚合数据
RangeAggregationBuilder priceAgg = AggregationBuilders.range("price_range").field("price");
priceAgg.addUnboundedTo(3300).addRange(3300,4000).addUnboundedFrom(4000);
//1.3 父子聚合
brandAgg.subAggregation(priceAgg);
//1.4 添加聚合条件
queryBuilder.addAggregation(brandAgg);
//2 查询获得聚合对象
AggregatedPage<Item> aggPage = (AggregatedPage<Item>)this.itemRepository.search(queryBuilder.build());
//3 解析结果:获得brands聚合内容
ParsedStringTerms agg = (ParsedStringTerms) aggPage.getAggregation("brands");
//4 遍历内容
List<? extends Terms.Bucket> buckets = agg.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.print(bucket.getKeyAsString() + " : ");
System.out.println(bucket.getDocCount());
ParsedStringTerms.ParsedBucket parsedBucket = (ParsedStringTerms.ParsedBucket) bucket;
Aggregations aggregations = parsedBucket.getAggregations();
ParsedRange priceParsedRange = (ParsedRange)aggregations.get("price_range");
List<? extends Range.Bucket> rangebuckets = priceParsedRange.getBuckets();
for (Range.Bucket rangebucket : rangebuckets) {
System.out.print(rangebucket.getKeyAsString() + ": \t\t");
System.out.print(rangebucket.getFrom() + "\t");
System.out.print(rangebucket.getTo() + "\t");
System.out.println(rangebucket.getDocCount());
}
}
}
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2022-10-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号