NeurIPS 2022 | 一种非平稳时间序列的通用预测框架 NSTransformers
NeurIPS 2022 | 一种非平稳时间序列的通用预测框架 NSTransformers

近年来,以注意力机制为结构核心的 Transformer 模型在时序预测领域取得了突破性进展,其点到点的注意力机制天然适合建模时间序列中的时序依赖。然而,预测非平稳的时序数据对这类模型而言依然是一项严峻挑战。非平稳的时序数据在现实世界中非常普遍,具有复杂且难以捕捉的时序依赖,以及随着时间不断变化的数据分布,这对深度模型的建模能力以及泛化性都提出了更高的要求。
最近,来自清华大学的几位研究者针对非平稳时间序列上的深度预测模型问题,提出了 Non-stationary Transformers,其包含一对相辅相成的序列平稳化(Series Stationarization)和去平稳化注意力(De-stationary Attention)模块,能够广泛应用于Transformer以及变体,一致提升其在非平稳时序数据上的预测效果。该工作被今年神经网络领域顶级学术会议 NeurIPS 2022 收录。
本文将对这篇工作进行简要解读。

论文地址:https://arxiv.org/abs/2205.14415
论文源码:https://github.com/thuml/Nonstationary_Transformers
非平稳时间序列预测
非平稳时序预测问题,过去的研究是利用平稳化技术消除时间维度上的分布差异,以提高数据本身的可预测性。然而该项工作的研究者们在大量的实验观察中发现,在平稳的数据上训练模型会限制 Transformer 的建模能力,模型仅能学到不易区分的注意力图与较弱的时序依赖,从而产生平稳性过高的预测输出,研究者们称之为过平稳现象(Over-stationarization)。
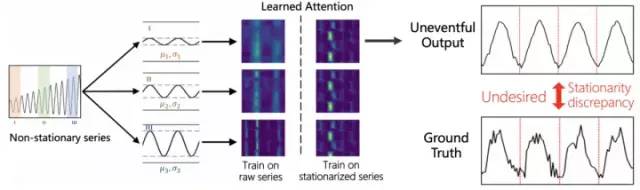
研究者认为,时序数据平稳化虽然增强了数据的可预测性,但将原始序列的时变分布退化为不随时间变化的平稳分布,这显然无法发挥 Transformer 在时序依赖上建模的优势。同时,非平稳性才是真实世界中时序数据的本质特性,因此,如何同时提高非平稳时序数据的可预测性以及充分发挥深度 Transformer 模型的时序建模能力,是该项研究工作的主要目标。
模型设计
Non-stationary Transformers 包含两大模块:序列平稳化模块和去平稳注意模块。前者和大部分时序模型一样,旨在增强输入数据的平稳性,后者关注数据的非平稳部分,重新整合非平稳信息到模型内部的时序依赖建模中,从而缓解过平稳问题。
01
序列平稳化
如下图所示,序列平稳化主要包含两个阶段:窗口归一化(Normalization)与反归一化(De-normalization)
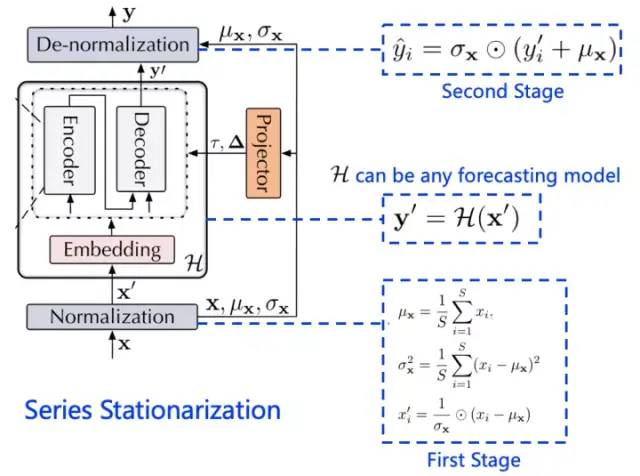
窗口归一化是对每一模型输入中的各个变量分别进行时间维度上的归一化,以消除了多变量时序数据中不同变量之间的尺度差异。注意,这里是对各个输入进行完整实例归一化(Instance Normalization),最终相邻窗口内的子序列都将服从相同的均值与方差。
然而归一化作为一种时序数据平稳化方法,虽然增强了数据的可预测性,但也使得原本数据分布退化。因此在这步平稳操作中,还需要存储各个窗口内序列原本的均值和方差,在后面建模中利用这些统计量重新对模型的输出进行反向尺度变换,以恢复其归一化时丢失的分布信息。
02
去平稳化注意力
尽管反归一化模块能还原部分时序数据的非平稳性,但在模型内部,特别是用来捕捉时序依赖的注意力模块,得到的依然是经过平稳化后的输入,这也是 Transformer 学习到较弱的时序依赖的主要原因。
因此需要使用经过归一化后的输入和归一化时存储的统计量,以近似未归一化时原始输入时本应得到的注意力图。根据 Transformer 的注意力计算公式:
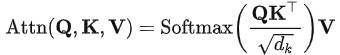
以及进行序列平稳化时,模型输入在时间维进行的尺度变换公式:
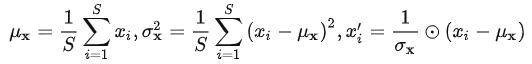
基于模型嵌入层(Embedding)和前向传播层(FFN)在时间维度的线性假设,可导出注意力层的输入Q,K分别满足:
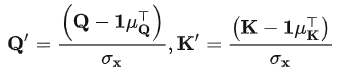
带入注意力计算公式,可以得到:
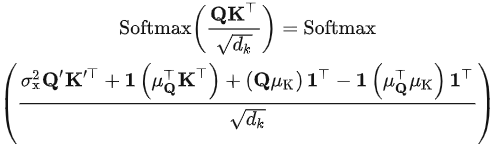
根据 Softmax 算子的平移不变性,上述公式可简化为:
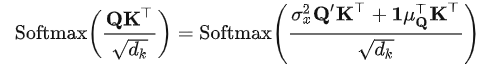
上式左侧为原本输入应得的注意力图,右侧由归一化输入的中间结果和相关统计量组成。可以观察到,要近似原始输入的注意力图,需要引入两个尺度变换因子:
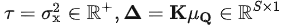
研究者定义为去平稳化因子(De-stationary factors),作用在经过归一化后的输入得到的注意力图上。
由于FFN中存在非线性激活层,在推导出如上作用形式后,研究者对模型层间的线性假设进行了弱化,采用一个多层感知机(MLP)从原始序列划窗得到的输入集以及相应均值方差中,自适应地学习去平稳化因子,由此设计出了去平稳化注意力模块,如下图所示,进一步向模型内部传递时序数据本身的非平稳信息。

03
整体结构
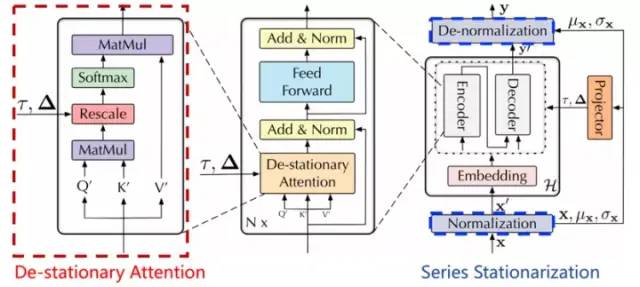
综合上述模块设计,研究者提出了 Non-stationary Transformers,结构如上图所示:将序列平稳化模块包裹于模型输入输出层前后,并在注意力计算中的Softmax算子前引入可学习的自适应尺度变换,使其能够广泛应用在以注意力为结构核心的Transformer及其变体上,在提高非平稳时序数据的可预测性的同时,充分挖掘注意力机制的时序建模能力。
实验效果
01
预测效果
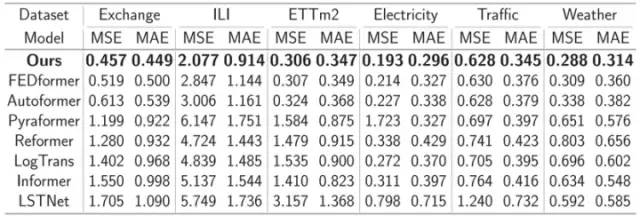
研究者将提出的框架应用在 Transformer 上,在6个时序数据集测试其预测能力,涵盖气象、能源、交通、经济、疾病等领域。如下表所示:

与近些年新提出的 Transformer 类时序预测模型的对比中,该框架均取得了最优的效果,特别在非平稳时序数据上,效果领先尤为明显。如下表所示:
02
框架通用性
为了测试该框架的通用性,研究者将所提出方法应用于 Transformer 类模型的其他变体上。如下表所示:
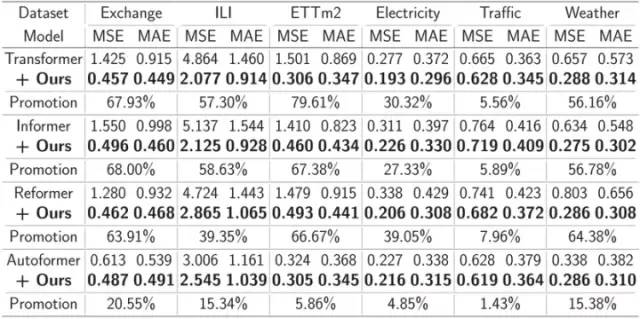
实验结果显示,该框架能够对这些模型进行比较显著的效果提升。比如:使用该框架能够使得 Transformer 取得 49.43% 的平均提升, 让 Informer 取得 47.34% , Reformer 取得 46.89%,Autoformer 取得 10.57% 的平均提升。
03
消融实验
除此之外,研究者对比了仅使用平稳化方案与该框架的预测效果与平稳性差异,以探索所提方案的真实效用。如下两图所示:
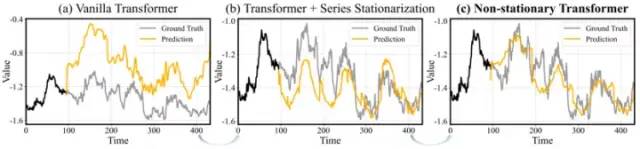
图1 模型预测值与真实值对比
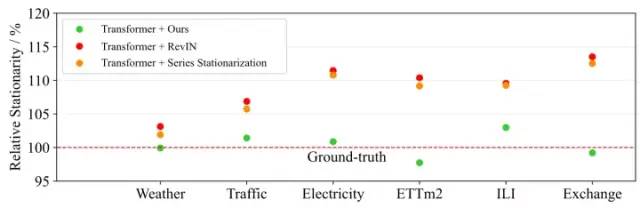
图2 模型预测值平稳性与真实值平稳性对比
实验可以观察到:序列平稳化使窗口间的序列之间的统计量对齐,一定程度上可以缓解深度模型在泛化能力差的问题(如图1b),但是会导致模型倾向于产生过于平稳的预测输出。引入模型内部的去平稳化注意力之后,如图1所示,预测输出的过平稳问题得到缓解,这有助于取得更加精确的时序预测。
总结
该项工作的研究者们从非平稳性时间序列预测的角度出发,提出重新纳入非平稳信息,改进 Transformer 内部的注意力机制,以提高数据的可预测性。经过大量实验表明,所提出的框架在气象、能源、交通、经济、疾病等领域均取得了优秀预测效果。该框架具有良好的通用性,在真实数据场景中有非常广阔的应用前景,具有很强的应用落地价值。
腾讯云开发者
