R语言笔记-2
原创

生信技能树-数据挖掘课程笔记
数据框
#数据框的新建
df = data.frame(gene = paste0("gene",1:6),change = rep(c("up","down"),each = 3))
#数据框的读取
df
df = read.csv("gene.csv")
#数据框的属性
dim(df) #查看行数和列数
nrow(df) #查看行数
ncol(df) #查看列数
rownames(df) #查看行名
colnames(df) #查看列名输出结果:


数据框的操作
#数据框取子集
df$change #按列名取一列,返回一个向量
df[,1] #按列号取一列,返回一个向量
df[1,1] #按坐标取一格
df[1,] #按行号取一行,返回一个数据框
df[c(1,3),1:2] #按坐标范围取多格,返回一个数据框输出结果:
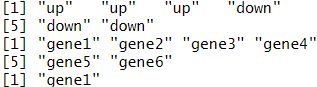

#数据框的修改
df$score = c(2,3,4,5,3,2) #创建新的列即,给不存在的列赋值
df
df[3,3] = 8 #修改一个格
df$change = rep(c("up","down"),3) #修改一列
colnames(df)[1] = "genes" #修改列名
df
#数据框取子集进阶
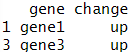
df[df$score > 4,] #提取出score>4的行
df$gene[df$score>4] #提取出score>4的基因
df[,-ncol(df)] #提取除数据框最后一列之外的列输出结果:

数据框之间的操作
df1 = data.frame(genes = paste0("gene",1:6),count = rep(c("2","3"),each = 3))
df2 = data.frame(GENES = paste0("gene",1:3),count = c(2,3,2))
df
df1
df2
#数据框的连接
merge(df,df1,by="genes") #指定列名相同的genes列进行合并
merge(df1,df2,by.x="genes",by.y="GENES") #指定列名不同的列进行合并输出结果:
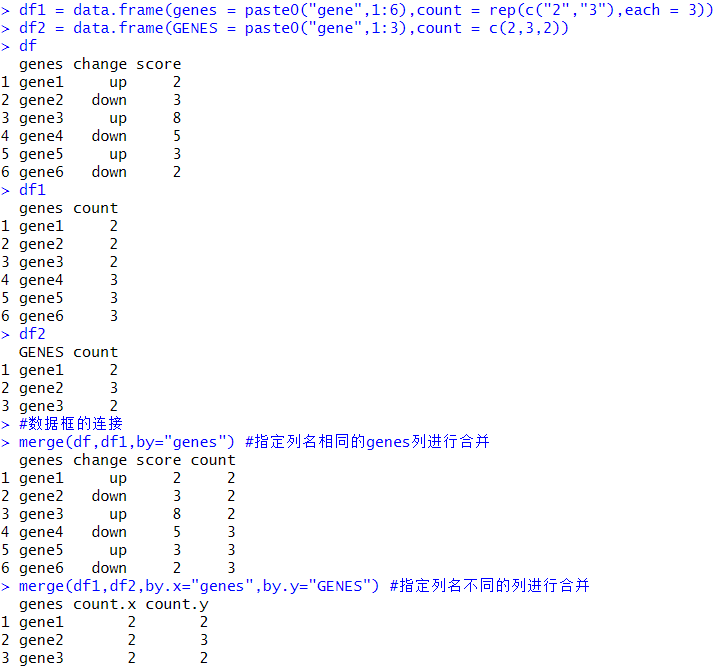
两个行数不同的数据框merge(),以交集的数据输出
矩阵
- 矩阵相当于二维的向量
- 同向量,矩阵只允许有一种数据类型
- 矩阵不能用$取列
- 矩阵可直接转为数据框
#矩阵的新建
m1 = matrix(1:9,nrow = 3)
m2 = matrix(1:8,ncol = 3)
m1
m2 #矩阵不足行数或列数会自动补齐
colnames(m1) <- c("a","b","c") #添加列名
m1[2,] #矩阵取一行
m1[,1] #矩阵取一列
m1[2,3] #矩阵取一格
m1[2:3,1:2] #矩阵取多格
t(m1)
as.data.frame(m1) #矩阵转为数据框输出结果:

列表
#列表的构建
l = list(v = c(1,2,3),df = data.frame(num = c(1,2,3),score = c(2,4,6)),m = matrix(1:9,ncol = 3))
l
#列表取子集
l[[2]] #列表取子集需用[[]]
l$m输出结果:

向量、列表中元素的名字
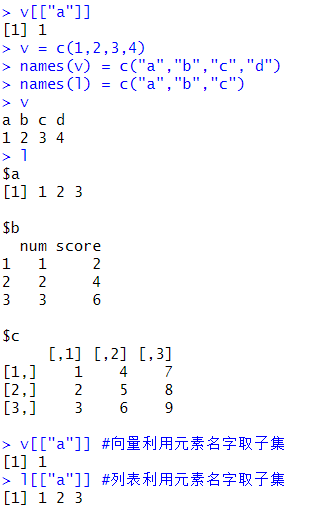
v = c(1,2,3,4)
names(v) = c("a","b","c","d")
names(l) = c("a","b","c")
v
l
v[["a"]] #向量利用元素名字取子集
l[["a"]] #列表利用元素名字取子集输出结果:
变量的删除
- 删除一个变量
rm(v) - 删除多个变量
rm(df,m,l) - 删除所有变量
rm(list = ls())
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
