时序预测问题及其应用


时序预测问题及其应用
时间序列预测主要是基于某一类变量的历史数据,预测该变量的未来取值。由于现代社会体系中加入了大量数据统计工具,数据生产的方式及来源无处不在。与此同时,数据本身的价值属性、普遍性也给时序预测带来广泛的应用空间。下文将主要介绍时序预测的基本概念、解决时序预测问题的几种方式和模型、时序预测与前沿技术结合的创新思路及成果等。
1.时序预测
时间序列,也可被称为时间数列、历史复数或动态数列。时序预测(Time Series Prediction)全称为时间序列预测,实际上是对时间序列进行预测的一种方法简称。对时序预测法的一般定义为通过编制和分析时间序列,再结合时间序列所反映出来的发展过程、方向和趋势,进行类推或延伸,借以预测下一段时间或以后若干年内可能达到的水平。
简而言之,时序预测即是通过分析一段有限时间内某个量的变化情况,预测该变量未来一段时间或某一时刻的变化情况和预测值。关于时序问题的研究方向除时序预测外,还包括时序分类研究、时序异常检测研究等。
时序预测在物联网结果预测、销量预测、交通流量预测、价格预测、金融股票等多个方面都有应用。如销量预测方面,时序预测可基于历史销量数据预测未来某一时间段的销量,为厂商的生产和备货计划提供决策支撑;如股票价格预测,需要对各种社会影响因素综合考量后纳入时序预测模型中,常见的方法有短期预测的指数平滑法、季节趋势预测法、市场寿命周期预测法。
1.1时序预测方法
一般解决时序预测问题的主流解决方式大致为统计学模型、机器学习模型、深度学习模型等。相较于传统统计学等模型,机器学习模型拟合能力与解释性都强于传统模型。随着人工智能技术的不断创新与发展,采用机器学习模型解决时序预测问题将逐渐成为主流。
例如,在金融领域股票市场是一个复杂的线性系统,传统的计量模型难以综合各类或宏观或微观的因素对未来结果进行较准确的预测。采用量子+AI结合的方式将能有效突破传统方式预测的线性局限和算力局限。
启科量子是国内首家量子通信与量子计算融合发展,以构建第三代量子互联网为目标的高科技企业,建造和开发先进的量子计算机与量子网络解决方案,聚焦解决海量数据处理与信息安全传输中的核心问题,为用户提供量子网络安全设备、量子计算机、量子云原生等赋能行业应用的产品和服务。启科量子目前在金融领域的主要探索与应用方向包括量子期权定价应用、量子时序汇率预估应用、投资组合优化应用、风险价值模型(量子VAR值计算)等方面。
1.2ARMA模型
传统经典时间序列预测方法主要有ARMA、ARIMA是一种常用的解决方式。ARMA模型的全称是自回归移动平均(auto regression moving average)模型,它是目前最常用的拟合平稳的数据序列,又可细分为AR模型(auto regression model)、MA模型(moving average model)和ARMA模型(auto regression moving average model)三大类。以下为使用ARMA模型预测比特币走势的模型构建部分代码:
- 寻找最优ARMA模型参数,求得best_aic最小值
results = []
best_aic = float("inf") # 正无穷
for param in parameters_list:
try:
model = ARMA(df_month.Weighted_Price,order=(param[0],param[1])).fit()
except ValueError:
print('参数错误:', param)
continue
aic = model.aic
if aic < best_aic:
best_model = model
best_aic = aic
best_param = param
results.append([param, model.aic])
- 输出最优模型
result_table = pd.DataFrame(results)
result_table.columns = ['parameters', 'aic']
print('最优模型: ', best_model.summary())
- 根据已有的比特币数据预测比特币趋势走向
df_month2 = df_month[['Weighted_Price']]
date_list = [datetime(2018, 11, 30), datetime(2018, 12, 31), datetime(2019, 1, 31), datetime(2019, 2, 28), datetime(2019, 3, 31),
datetime(2019, 4, 30), datetime(2019, 5, 31), datetime(2019, 6, 30)]
future = pd.DataFrame(index=date_list, columns= df_month.columns)
df_month2 = pd.concat([df_month2, future])
df_month2['forecast'] = best_model.predict(start=0, end=91)
1.3深度学习方法
1.3.1什么是RNN
RNN(英文全称Recursive Neural Network)即递归神经网络,递归神经网络的独特之处在于允许对向量序列进行操作:输入中的序列、输出中的序列,或者两者兼而有之。RNN计算的核心在于RNN有一个简单的API,当接受一个输入向量X时,会对应一个输出向量Y。其中输出向量Y不仅受到输入向量X的影响,还受到历史输入的X影响。RNN 的 API 由一个step函数组成:
rnn = RNN()
y = rnn.step(x) # x is an input vector, y is the RNN's output vector
RNN分类的一些内部状态会随着step的调用更新。在最简情况下,RNN内部状态由单个隐藏向量h组成,通过Vanilla RNN中的step函数实现:
class RNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
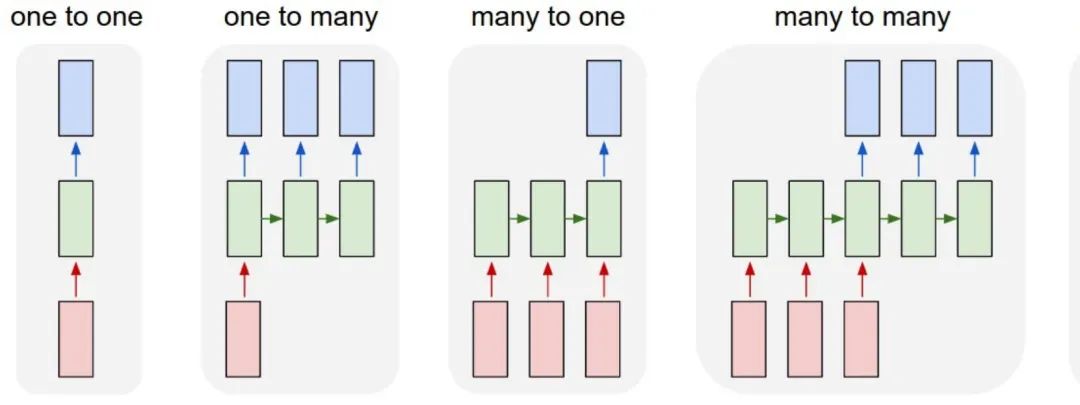
1.3.2什么是LSTM
LSTM(Long Short Term Memory)是具有记忆长短期信息能力的神经网络,是一种用于深度学习领域的人工递归神经网络(RNN)结构。LSTM由于深度学习而兴起,经过不断的迭代与优化发展后,形成了较完整的LSTM框架,深度学习中的LSTM模型可以解决长期依赖问题。有资料显示LSTM是对RNN的一种改进,该模型更复杂,但训练更容易,可以避免梯度消失问题。以下为LSTM结构图:
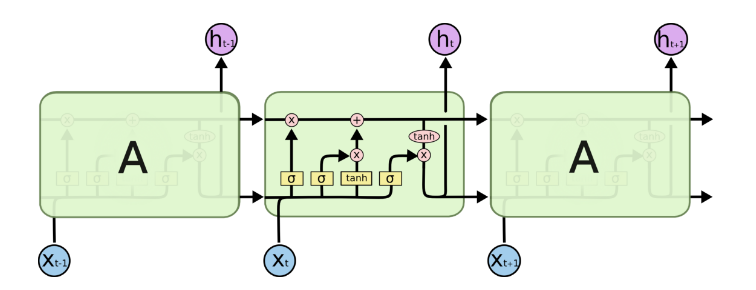
LSTM结构在训练数据时会同时使用上一时刻的信息与当前时刻的输入信息来共同训练数据。LSTM模型包含时间值、样本数、数据特征数(下图隐含层包括数据特征、维度等信息),其可视化图形如下:
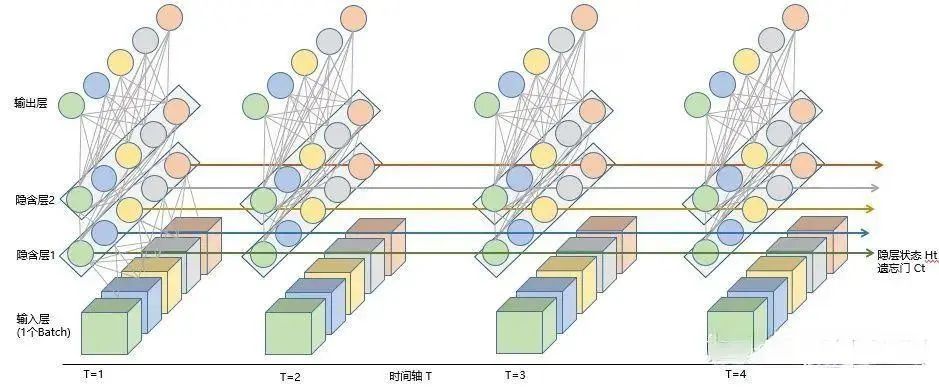
2.时序预测实现
与传统的时序预测方法相比,使用带有长短期记忆单元(LSTM)的递归神经网络RNN几乎不需要特征工程。使用带有LSTM的RNN时,数据可直接输入神经网络就可解决建模问题。在使用LSTM模型进行时序预测之前,还是需要首先准备好将要使用的数据、进行数据集分类与准备、定义训练的核心参数。准备完成后,开始建构和训练神经网络。
- 定义
LSTM_RNN函数,从已给定的参数返回一个tensorflow的LSTM神经网络,使用两个LSTM单元的堆叠增加了神经网络的深度;extract_batch_size(_train, step, batch_size)从(X|y)_train数据中获取“batch_size”数据量的函数;one_hot(y_, n_classes=n_classes)从数字索引编码神经one-hot输出标签的函数。
# Guillaume Chevalier, LSTMs for Human Activity Recognition, 2016, https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition
def LSTM_RNN(_X, _weights, _biases):
_X = tf.transpose(_X, [1, 0, 2]) # permute n_steps and batch_size
# Reshape to prepare input to hidden activation
_X = tf.reshape(_X, [-1, n_input])
# new shape: (n_steps*batch_size, n_input)
# ReLU activation, thanks to Yu Zhao for adding this improvement here:
_X = tf.nn.relu(tf.matmul(_X, _weights['hidden']) + _biases['hidden'])
# Split data because rnn cell needs a list of inputs for the RNN inner loop
_X = tf.split(_X, n_steps, 0)
# new shape: n_steps * (batch_size, n_hidden)
# Define two stacked LSTM cells (two recurrent layers deep) with tensorflow
lstm_cell_1 = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True)
lstm_cell_2 = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True)
lstm_cells = tf.contrib.rnn.MultiRNNCell([lstm_cell_1, lstm_cell_2], state_is_tuple=True)
# Get LSTM cell output
outputs, states = tf.contrib.rnn.static_rnn(lstm_cells, _X, dtype=tf.float32)
# Get last time step's output feature for a "many-to-one" style classifier,
# as in the image describing RNNs at the top of this page
lstm_last_output = outputs[-1]
# Linear activation
return tf.matmul(lstm_last_output, _weights['out']) + _biases['out']
def extract_batch_size(_train, step, batch_size):
# Function to fetch a "batch_size" amount of data from "(X|y)_train" data.
>>>>
def one_hot(y_, n_classes=n_classes):
# Function to encode neural one-hot output labels from number indexes
>>>>
- 创建神经网络
# Guillaume Chevalier, LSTMs for Human Activity Recognition, 2016, https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition
# Graph input/output
x = tf.placeholder(tf.float32, [None, n_steps, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
# Graph weights
weights = {
'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])), # Hidden layer weights
'out': tf.Variable(tf.random_normal([n_hidden, n_classes], mean=1.0))
}
biases = {
'hidden': tf.Variable(tf.random_normal([n_hidden])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
pred = LSTM_RNN(x, weights, biases)
# Loss, optimizer and evaluation
l2 = lambda_loss_amount * sum(
tf.nn.l2_loss(tf_var) for tf_var in tf.trainable_variables()
) # L2 loss prevents this overkill neural network to overfit the data
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=pred)) + l2 # Softmax loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam Optimizer
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
- 下面开始训练神经网络:
首先需要追踪训练操作
# Guillaume Chevalier, LSTMs for Human Activity Recognition, 2016, https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition
test_losses = []
test_accuracies = []
train_losses = []
train_accuracies = []
# Launch the graph
sess = tf.InteractiveSession(config=tf.ConfigProto(log_device_placement=True))
init = tf.global_variables_initializer()
sess.run(init)
在每个循环中使用示例数据batch_size数执行训练步骤
# Guillaume Chevalier, LSTMs for Human Activity Recognition, 2016, https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition
step = 1
while step * batch_size <= training_iters:
batch_xs = extract_batch_size(X_train, step, batch_size)
batch_ys = one_hot(extract_batch_size(y_train, step, batch_size))
# Fit training using batch data
_, loss, acc = sess.run(
[optimizer, cost, accuracy],
feed_dict={
x: batch_xs,
y: batch_ys
}
)
train_losses.append(loss)
train_accuracies.append(acc)
- 训练后的可视化结果如下:
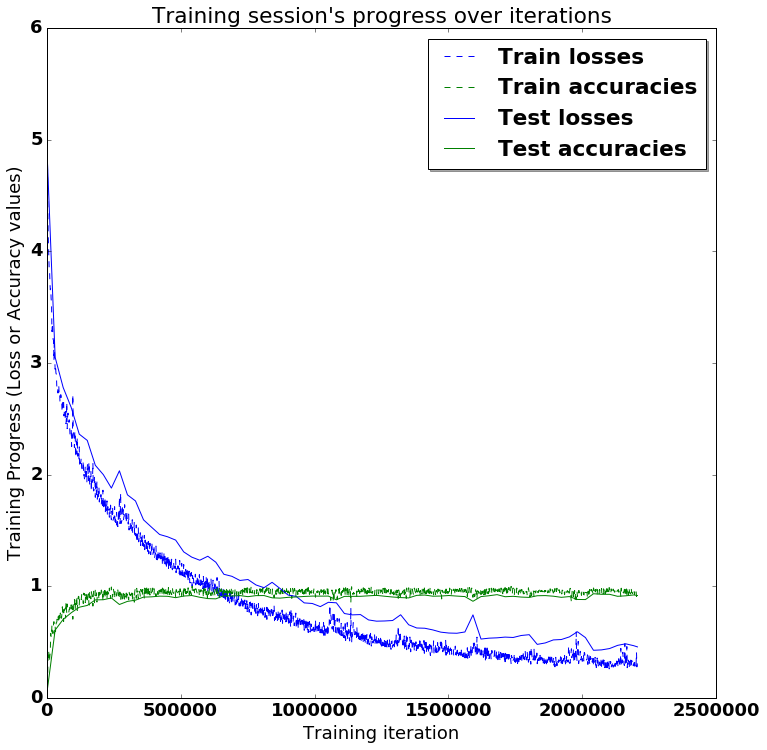
图为训练过程及损失函数精度值
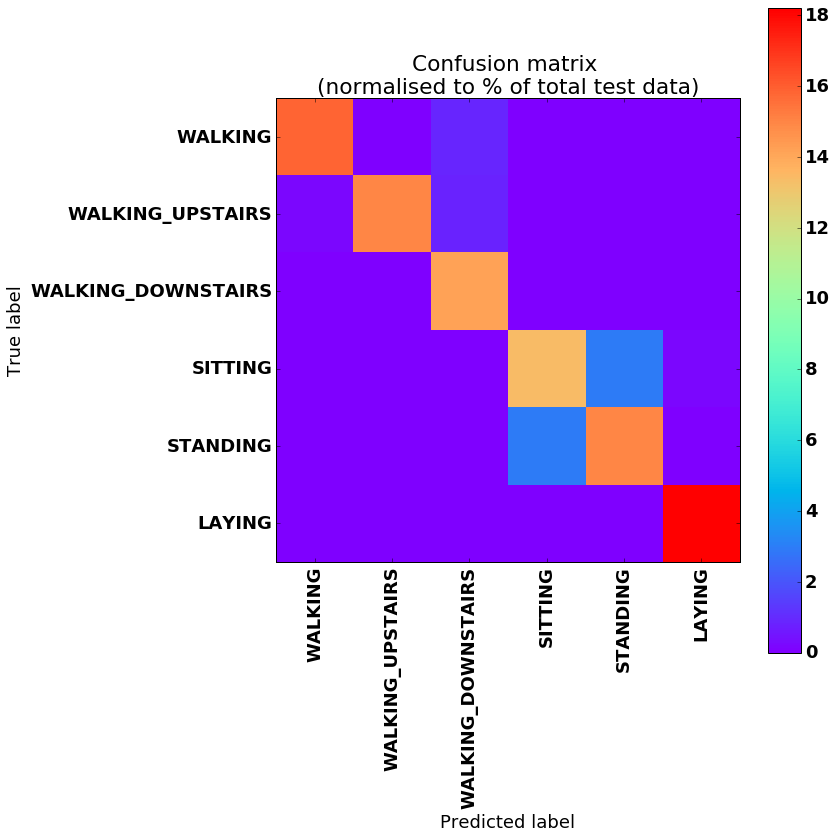
图为混淆矩阵也称误差矩阵。在机器学习中,混淆矩阵是一个误差矩阵,常用来可视化地评估监督学习算法的性能。混淆矩阵大小为 (n_classes, n_classes) 的方阵, 其中 n_classes表示类的数量。这个矩阵的每一行表示真实类中的实例,而每一列表示预测类中的实例 (Tensorflow 和 scikit-learn 采用的实现方式)。我们可以通过混淆矩阵看出系统是否会弄混两个类,这也是混淆矩阵名字的由来。上图中的每一行表示真实值、每一列表示预测值。最终结果准确率为91%。
3.量子计算与时序预测
近年,5G、云计算、大数据、人工智能、量子计算等技术的创新迭代,为推动企业数字化转型与数字经济发展提供了优良的技术条件。量子计算作为前沿科技的典型代表之一,在算力方面有着经典计算无法比拟的潜力优势。
量子计算(Quantum Computing)基于量子的叠加与纠缠等特性进行数据存储与执行计算,是量子力学与计算机科学相结合的新一代计算方式。相比于经典计算,量子计算的优越性主要体现在计算模式、计算能力与信息存储等方面,具体如下:在基本信息单元方面,经典计算机信息的基本单元是比特,比特是一种有两个状态的物理系统,用0与1表示。在量子计算机中,基本信息单位是量子比特(qubit),通常用态狄拉克符号︱0〉和︱1〉表示量子比特状态,每个量子比特的状态是0或1的线性组合(通常称为叠加态)。在运算模式方面,经典计算机的运算模式为逐步计算,一次运算只能处理一次计算任务。而量子计算为并行计算,可以同时对2^n个数进行数学运算,相当于经典计算机重复实施2^n次操作。在计算性能方面,经典计算的计算能力与晶体管数量成正比例线性关系,量子计算机算力将以量子比特的指数级规模拓展和爆发式增长。
目前量子计算应用探索主要包括量子模拟和加速优化两大类型,在药物研究、材料科学、分子化学、蛋白质折叠模拟、量化金融、航空动力、交通规划、人工智能等领域探索活跃。启科量子计算软件产品与AI结合的典型应用主要有如量子机器学习、量子自然语言处理、量子组合优化、量子化学模拟等。下文将简单展示启科量子QuFinace量子金融时序预测应用。
3.1启科量子QuFinace
以下为启科量子金融方案的量子时序预估部分图片展示,在使用时可选择股票名称、类型等信息。每隔固定时间,系统都会自动计算并生成股票市场价格预估值。QuFinace根据相应的股票数据及其他相关数据生成股票数据历史趋势(如图中蓝色部分)、未来一段时间的预估值(如图中绿色部分)。图中QuFinace利用历史数据与预估数据拟合较好,并依据历史数据对未来数据作出预测,详见下图:
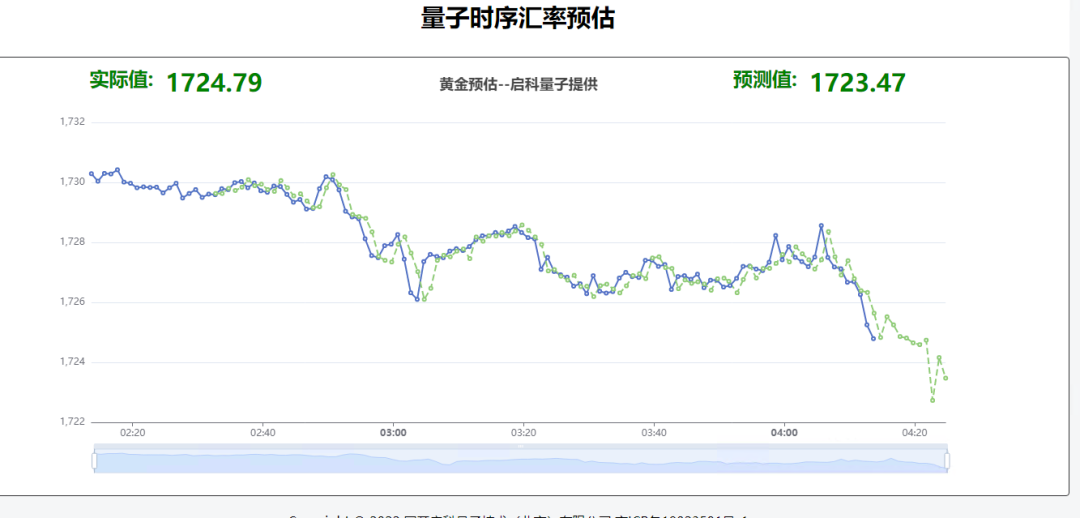
QuFinace是启科量子在金融领域中的一款量子软件应用产品,其操作简单、数据库丰富,其主要基于量子算法,针对金融领域的期权定价、时序汇率预估、投资组合优化、VAR值计算等方面提供量子实现的解决方案,为金融从业者、投资者在复杂的市场环境中提供决策支撑。启科量子还提供量子编程相关套件、配套教程等内容。更多量子相关应用软件及解决方案可以登录启科量子开发者官方平台。
启科量子开发者官方平台:http://developer.queco.cn
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-01-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号