DPDK性能压测系列-1:dperf 工具简介

DPDK性能压测系列-1:dperf 工具简介

本章节介绍的是一款面向四层网关(如四层负载均衡,L4-LB)的高性能的压测工具dperf。该工具目前已经在github上开源,是一款高性能的压测工具:
github: https://github.com/baidu/dperf
喜欢的小伙伴,欢迎点赞加关注支持一下作者。
首先:为什么会接触dperf
在接触SDN数据面编程时,性能压测是日常开发所需要的工作之一。由于DPDK将网卡从linux 内核接管,从而提高了数据转发的性能,正因为如此我们接触到了dperf这一款高性能的开源网络压力测试仪,是Linux基金会旗下的DPDK官方生态项目,它可以对网元进行基本打流、进行基本性能测试、测试每秒新建连接数、并发连接数、带宽、PPS等网络性能参数的测试。
其次:我们为什么选择dperf
1、成本优势
相比于常见的测试仪表思博伦Testcenter、IXIA等专用打流仪表,dperf 软件源代码是遵守开源协议开源的,而专用测试仪表价格往往比较昂贵,相关特性需要花费巨资购买国外厂商的license。
2、突破硬件仪表的功能局限
在传统的硬件打流仪表,往往存在硬件设备固件的限制,不能灵活支持软件定义网络、vxlan underlay/overlay等功能,相比而言软件定义打流设备dperf就不存在硬件约束。
3、能够支持负载均衡功能
在常见硬件打流仪表testcenter、IXIA等仪表往往注重的是产生流量和产生通用性的协议流量等功能,而对于L4以上的负载均衡、应用协议建立链接、支持会话等等,对负载均衡的支持不够强大。
4、常见打流程序如pktgen等缺点
常见的测试方法是:受到内核中断、流量拷贝等等影响,存在如下缺点。
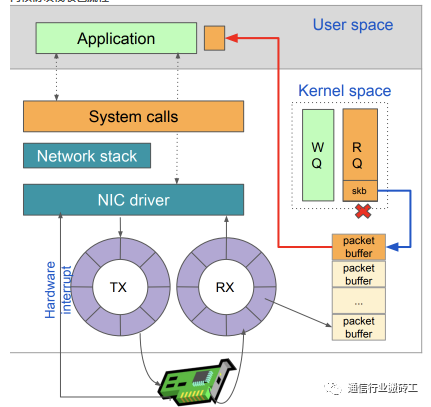
内核收包流程描述
1、性能低、资源消耗大;
2、连接失败高:压力较大时,Linux协议栈或FreeBSD协议栈会因为资源不足,导致出现连接失败,会掩盖了被测设备的缺陷,影响测试结果;
3、不能觉察丢包:整个测试过程中,不能发现被测设备丢包等报文级错误。
dperf 项目的技术方面优势

再次:我们怎么看dperf的实现原理
dperf 是基于intel DPDK开发的打流套件,下面我们简单介绍intel DPDK相关基础知识:
当前内核存在低效率的问题:
- 数据包从外面的网络进入物理网卡。如果目的地址不是该网卡,且该网卡没有开启混杂模式,该包会被网卡丢弃。(混杂模式:一台机器的网卡能够接收所有经过它的数据流,而不论其目的地址是否是它)
- 网卡将数据包通过DMA的方式写入到指定的内存地址,即图中所示的RX ring,该地址由网卡驱动分配并初始化。
- 驱动模块中断处理
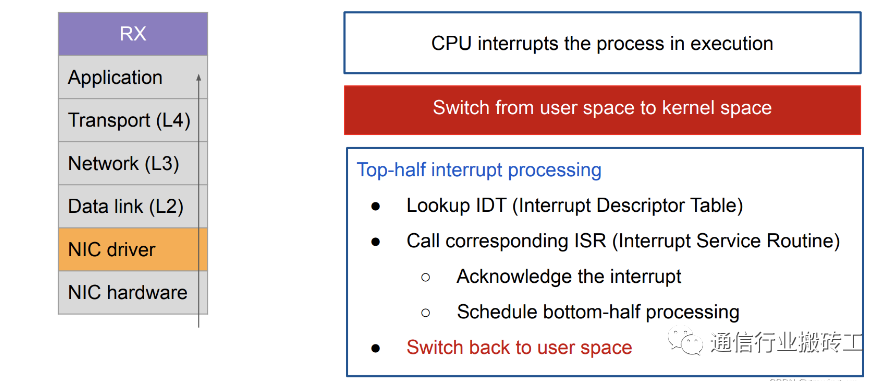
- 网卡通过硬件中断(IRQ)通知CPU,告诉它有数据来了。这时CPU会中断正在进行的工作从用户态切换到内核态
- CPU根据中断表,调用已经注册的中断函数,这个中断函数会调到驱动程序(NIC Driver)中相应的函数
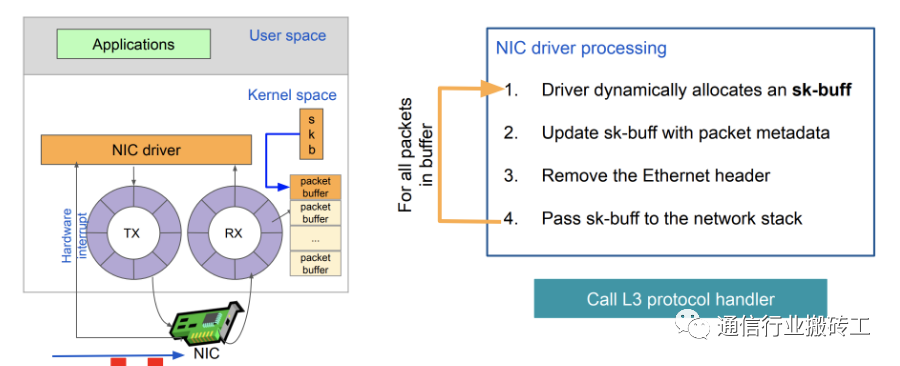
应用层收包:
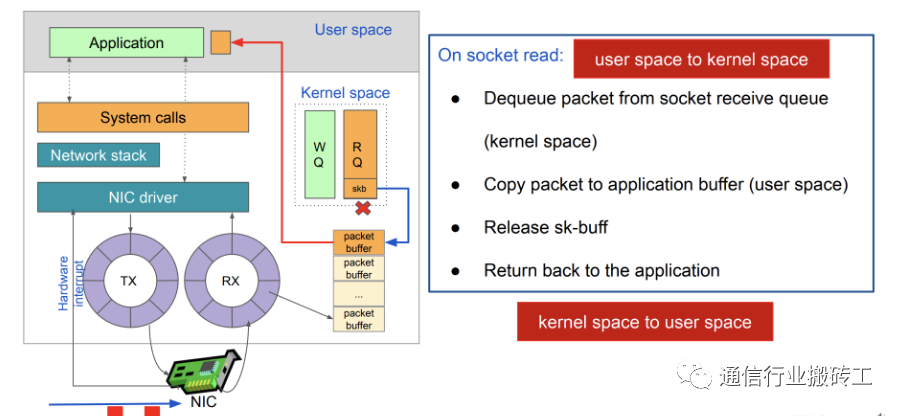
内核存在的缺陷:
- 中断开销突出,大量数据到来会触发频繁的中断(softirq)开销导致系统无法承受
- 需要把包从内核缓冲区拷贝到用户缓冲区,带来系统调用和数据包复制的开销
- 对于很多网络功能节点来说,TCP/IP协议并非是数据转发环节所必需的
- NAPI/Netmap等虽然减少了内核到用户空间的数据拷贝,但操作系统调度带来的 cache替换也会对性能产生负面影响 ;
再次:dperf高性能采用,DPDK采用内核旁路技术的UIO描述
DPDK通过linux的UIO技术byapass内核,避免了内核中断爆炸和大量数据拷贝的方法,在用户空间能够直接和硬件进行交互。传统的收发数据包方式,首先网卡通过中断方式通知Linux内核协议栈对数据包进行处理,内核协议栈先会对数据包进行合法性进行必要的校验,然后判断数据包目标是否为本机的Socket,满足条件则会将数据包拷贝一份向上递交到用户态Socket来处理。 为了使得网卡驱动(PMD Driver)运行在用户态,实现内核旁路,Linux提供了UIO(User Space IO)机制。使用UIO可以通过 read感知中断,通过 mmap实现和网卡设备的通讯。 UIO是用户态的一种IO技术,是DPDK能够绕过内核协议栈,提供用户态PMD Driver支持的基础。DPDK架构在Linux内核中安装了IGB_UIO(igb_uio.ko和kni.ko.IGB_UIO)模块,以此借助UIO 技术来截获中断,并重设中断回调行为,从而绕过内核协议栈后续处理流程,并且IGB_UIO会在内核初始化的过程中将网卡硬件寄存器映射到用户态
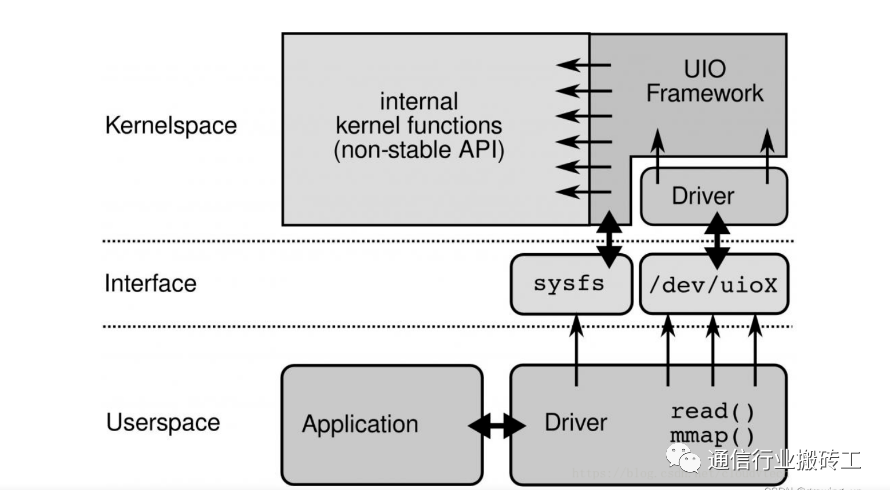
UIO技术架构描述
TLB逻辑描述
再次:dperf能做些什么(该章节dperf官方描述)
新建连接数
dperf新建性能的确很强。用两个核(一个核运行dperf客户端,一个核运行dperf)
1、在X86(Intel(R) Xeon(R) Silver 4214)上能够测出230万HTTP CPS新建,
2、在鲲鹏902上可以测出210万,详见项目主页。
3、如果用ab去测试nginx,CPS只有2.5万,性能相差1百倍。
并发连接数
dperf并发也很强,dperf一个连接只消耗了64个字节,十个亿的TCP并发只是60GB内存而已,因此dperf支持巨量的并发功能很是容易。
带宽
dperf的带宽受制于网卡,如果需要高性能,通信行业搬砖工 建议您使用支持DPDK的高性能网卡;
再次:dperf 在数据统计方面解决啥问题(详情参考官方文档)
dperf输出的详细且实时的统计数据如下所示,dperf每秒输出一次统计数据,统计内容包括:
1. 已经运行多少秒,每个核的CPU使用率,
2. 每秒收包数,每秒发包数,每秒接收比特,每秒发送比特
3. 2-3层协议的收发报文数:ARP、ICMP
4. TCP各种状态的收发报文数:SYN、FIN、PUSH、RST
5. HTTP请求、响应数统计:GET、2XX
6. 失败数:连接失败数、网卡丢包数等
7. TCP报文重传数:SYN、FIN、ACK、PUSH重传
seconds 75379 cpuUsage 28 28 28 28 27
pktRx 3,000,970 pktTx 3,000,947 bitsRx 2,096,674,944 bitsTx 2,208,701,296 dropTx 0
arpRx 0 arpTx 0 icmpRx 0 icmpTx 0 otherRx 0 badRx 0
synRx 1,000,331 synTx 1,000,331 finRx 1,000,296 finTx 1,000,320 rstRx 23 rstTx 0
synRt 0 finRt 0 ackRt 0 pushRt 0 tcpDrop 0
skOpen 1,000,331 skClose 1,000,319 skCon 493 skErr 0
httpGet 1,000,320 http2XX 1,000,320 httpErr 0
ierrors 0 oerrors 0 imissed 0写在最后:
https://github.com/baidu/dperf
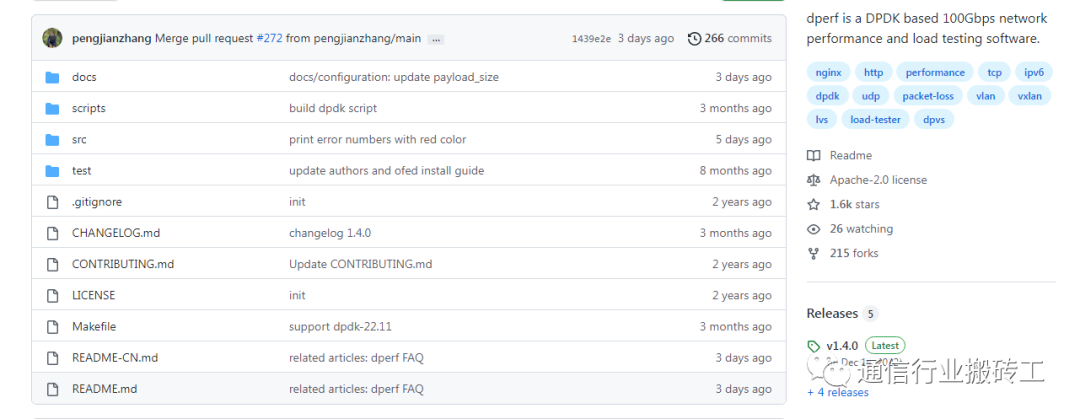
dperf 目前在github上已经有1.6K 个点赞,工具已经被intel DPDK官网收录,如果您觉得dperf很好,那么欢迎您在github上star一下。
腾讯云开发者
