【C++】STL简介 -- string 的使用及其模拟实现
【C++】STL简介 -- string 的使用及其模拟实现

文章目录
一、STL 简介
1、什么是 STL
STL (standard template libaray - 标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。
2、STL 的版本
- 原始版本 Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原始版本一样做开源使用。 HP 版本–所有STL实现版本的始祖。
- P. J. 版本 由P. J. Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。
- RW版本 由Rouge Wage公司开发,继承自HP版本,被C+ + Builder 采用,不能公开或修改,可读性一般。
- SGI版本 由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版 本。被GCC(Linux)采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程 风格上看,阅读性非常高。我们后面学习STL时要了解部分源代码,主要参考的就是这个版本。
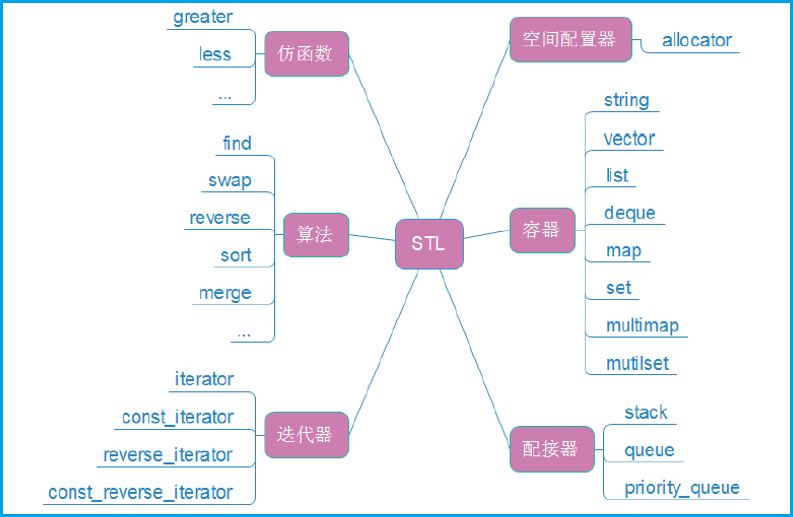
3、STL 的六大组件
STL 共有容器、配接器、迭代器、空间配装器、算法、仿函数六大组件,其内部包含的具体内容如下:
4、STL 的重要性
网上有句话说:“不懂STL,不要说你会C++”。STL是C++中的优秀作品,有了它的陪伴,许多底层的数据结构以及算法都不需要自己重新造轮子,直接使用即可,大大提高了解题和开发的效率;因此,STL 在笔试、面试以及工作中其都是一个被重点考察的对象。
5、如何学习 STL
关于如何学习 STL,我这里给出两点建议:
学会使用在线网站:cplusplus.com - The C++ Resources Network 与 cppreference.com;
相比于C++官网 – cppreference,我更推荐大家使用 cplusplus (注:cplusplus 更新之后需要注册才能使用,我们可以点击右上角的 “Legacy version” 回到旧版,个人认为旧版的使用体验比新版要好),因为 cplusplus 更适合初学者,我们学习STL过程中遇到的任何函数接口、函数参数等等方面的内容都可以在 cplusplus 上通过搜索解决。
阅读优秀的C++书籍:C++是一门比较难的语言,其中的细节非常多,我们需要阅读优秀的C++书籍来学习与积累经验,这里我推荐三本C++方向的优秀书籍:C++ Primer 中文版(第 5 版) 、STL源码剖析 、《Effective C++:改善程序与设计的55个具体做法》 ;这三本书的电子版我全都放在了百度网盘里面,需要的可以自取。
网盘链接:https://pan.baidu.com/s/1R-PW2P-6jH9IcIYz0VQpiw
提取码:yzpq二、string 类的使用
1、什么是 string
C语言中,字符串是以’\0’结尾的若干个字符的集合,为了操作方便,C语言 string.h 头文件提供了一些系列的库函数,但是这些库函数与字符串是分离开的,不符合面向对象的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
基于上面这些原因,C++标准库提供了 string 类,string 类中提供了各种函数接口,比如类的六个默认成员函数、字符串插入删除、运算符重载等等,我们可以使用 string 来实例化对象,然后通过 string 的各种接口来完成对该对象的各种操作。
string 类的实现框架大概如下:
namespace std {
template<class T>
class string {
public:
// string 的各种成员函数
private:
T* _str;
size_t _size;
size_t _capacity;
//string 的其他成员变量,比如npos
};
}注:严格来说 string 其实并不属于 STL,因为 string 出现的时间比 STL 要早,但是由于 string 的各种接口和 STL 中其他容器的接口非常类似,所以我们可以把 string 也当作 STL 的一种,放在一起学习。
2、VS 和 g++ 下 string 的结构
VS 下 string 的结构
VS 下 string 总共占28个字节,其内部结构比较复杂,包含一个联合体,联合体用来定义 string 中字符串的存储空间:
- 当字符串长度小于16时,使用内部固定的字符数组来存放;
- 当字符串长度大于等于16时,从堆上开辟空间
union _Bxty {
// storage for small buffer or pointer to larger one
value_type _Buf[_BUF_SIZE];
pointer _Ptr;
char _Alias[_BUF_SIZE]; // to permit aliasing
} _Bx;这种设计有其自身的好处 – 大多数情况下字符串的长度都小于16,这样当 string 对象创建好之后,内部已经有了16个字符数组的固定空间,我们就不需要再通过向堆申请空间来存储字符了。
同时,string 内部还有一个 size_t 字段用来保存字符串长度 (size),一个 size_t 字段保存从堆上开辟空间总的容量 (capacity),最后还有一个指针做一些其他事情。
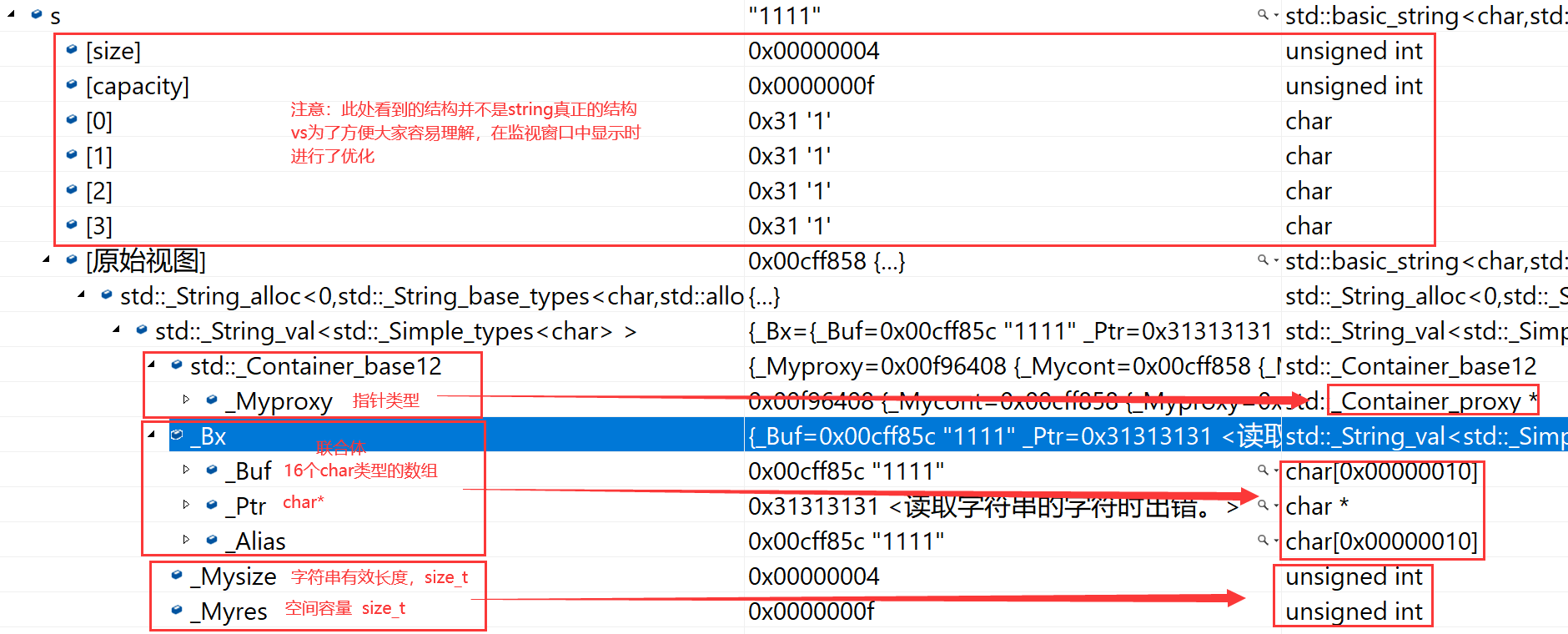
总的来说,VS 下 string 结构是一种以空间换取时间的做法。
g++ 下 string 的结构
g++ 中,string 是通过写时拷贝实现的,string 对象总共占4个字节,内部只包含了一个指针,该指针将来指向一块堆空间,内部包含了如下字段:
- 空间总大小 capacity;
- 字符串有效长度 size;
- 引用计数 refcount ;(拷贝构造时默认使用浅拷贝来提高效率 + 使用引用计数来保证同一块堆空间不被析构多次)
- 指向堆空间的指针,用来存储字符串。
3、string 类模板
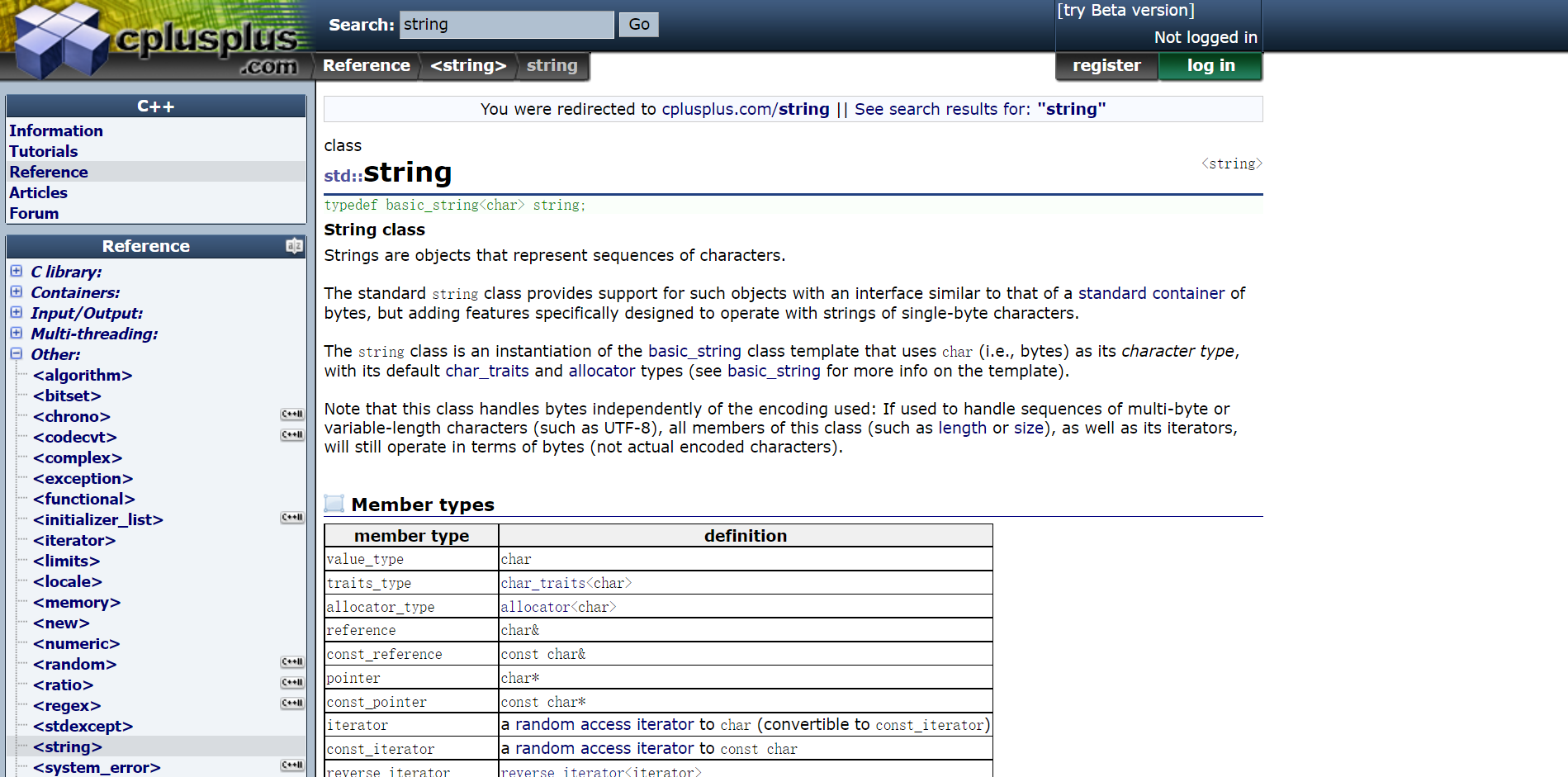
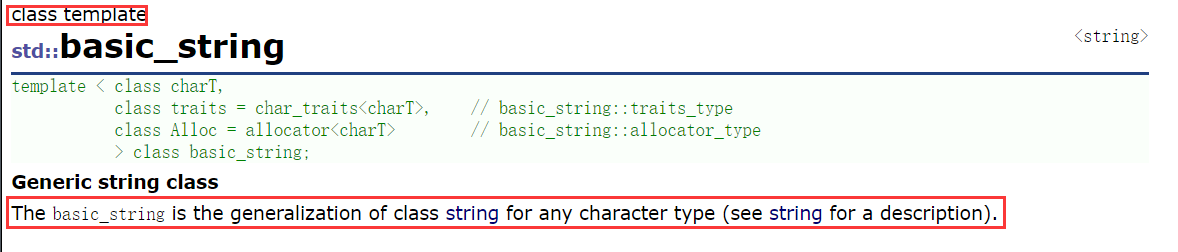
我们打开 cplusplus.com 搜索 string 会发现,string 其实是 basic_string 类模板使用字符类型 char 实例化得到的一个类:

而 basic_string 是一个可以使用任意字符类型来实例化的类模板:
那么 string 为什么要设计成模板呢?因为编码不同,存储一个字符所需要的空间也不同;现如今常见的编码有如下三类:
ASCII 全称为美国信息交换标准代码,这是我们接触到的第一种编码,由于英语所有的英文字母 (包括大小写) 加上各种标点符号以及特殊字符一共只有一百多种,所以我们使用一个字节即可表示所有字符;但是根据 ASCII 编码设计出的计算机不能表示其他国家的语言,比如中文、日文、韩文等等。
Unicode 就是我们的统一码,也叫万国码;它是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode 主要包括 utf-8,utf-16 与 utf-32,其中的8、16与32分别代表了字符的最小空间为1、2以及4字节。
由于 utf-8 支持 ASCII,且字符最小单位为一字节,节省了空间,所以现在使用率最高的编码方式就是它。
GBK 即 “国标”,是我国专门为汉字设计的一套编码,其中一个字符最小占用空间为两个字节。
编码方式对 basic_string 的影响如下:
- char – 采用单字节编码;
- char16_t – 采用双字节编码;
- char32_t – 采用四字节编码;
所以,我们平时使用的 string 本质上是 basic_string<char>,我们不用自己显式实例化是因为 string 内部进行了 typedef:
typedef basic_string<char, char_traits, allocator> string4、构造函数
string 提供了很多构造函数,我们只需要掌握其中最常用的几个就可以,其余的如果有需要再查询文档:
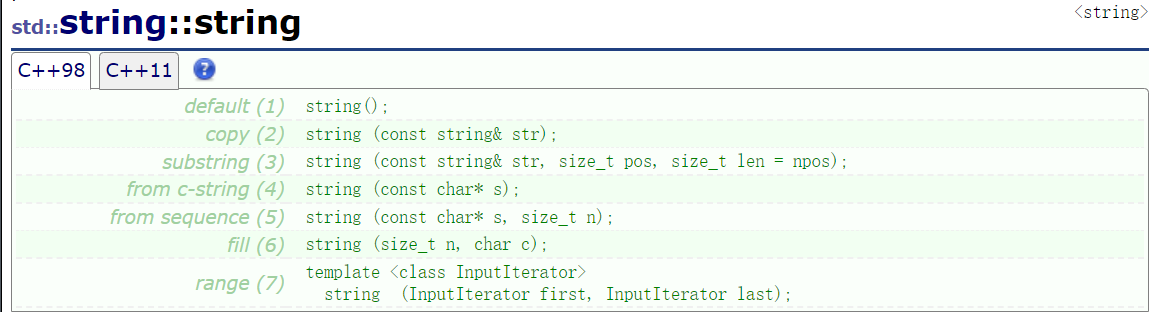
-(constructor)函数名称 | -函数功能 |
|---|---|
string() (重点) | 构造空的string类对象,即空字符串 |
string(const char* s) (重点) | 用字符数组来构造string类对象 |
string(const string&s) (重点) | 拷贝构造函数 |
string(size_t n, char c) | 用n个c字符来构造string类对象 |
5、Iterators
Iterators 是C++中的迭代器,大家可以把它当成指针来理解,当然,并不是所有迭代器的底层都是用指针实现的:
typedef char* iterator; //简单理解string中的迭代器
-函数名称 | -函数功能 |
|---|---|
begin() | 返回一个指向字符串中第一个字符的迭代器 |
end() | 返回一个指向字符串最后一个字符下一个位置(‘\0’)的迭代器 |
rbegin() | 反向迭代器,返回一个指向字符串最后一个字符下一个位置(‘\0’)的迭代器 |
rend() | 反向迭代器,返回一个指向字符串中第一个字符的迭代器 |
注意:为了使 const 对象也能调用,每个迭代器函数都设计了 const 版本:


有了迭代器之后,我们就可以使用迭代器来遍历与修改字符串了:
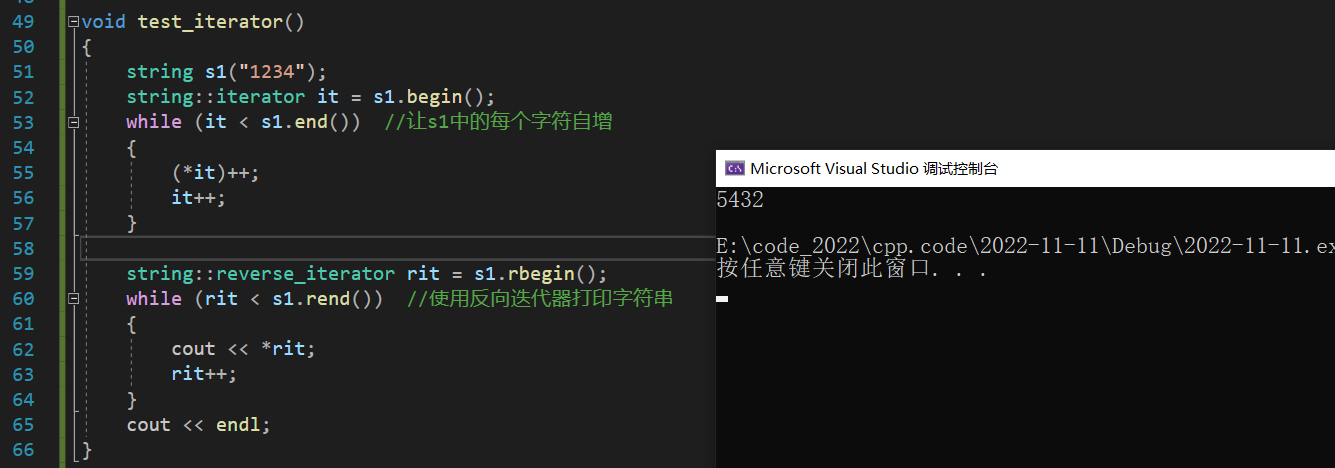
6、Capacity
string 中提供了一些对容量进行操作的函数:

-函数名称 | -函数功能 |
|---|---|
size() | 返回字符串的长度 |
capacity | 返回字符串的容量 |
empty | 判断字符串是否为空 |
resize
resize 函数用来调整字符串大小,它一共分为三种情况:
- n 小于原字符串的 size,此时 resize 函数会将原字符串的 size 改为 n,但不会改变 capacity;
- n 大于原字符串的 size,但小于其 capacity,此时 resize 函数会将 size 后面的空间全部设置为字符 c;
- n 大于原字符串的 capacity,此时 resize 函数会将原字符串扩容,然后将size 后面的空间全部设置为字符 c;

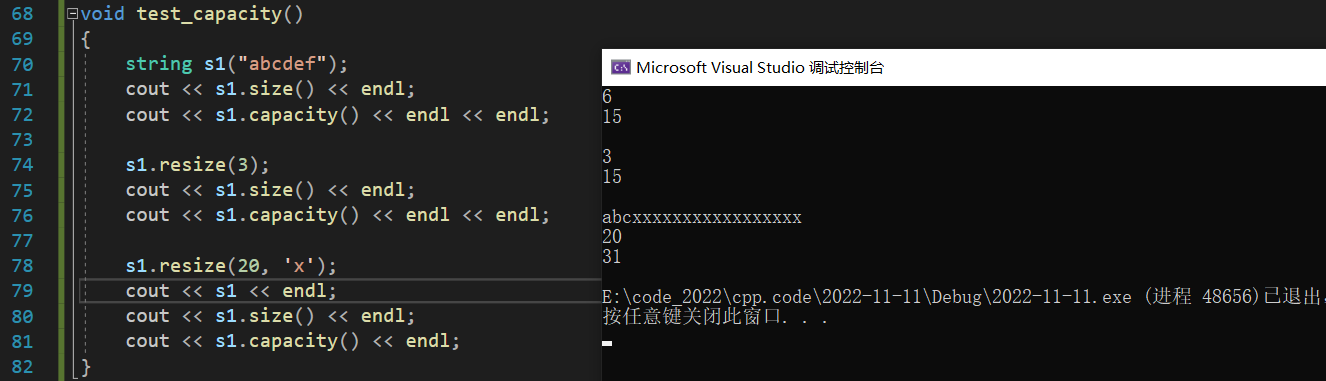
reserve
reserve 用来扩容与预留空间,相当于C语言中的 realloc 函数,它分两种情况:
- n 大于原字符串的 capacity,此时 reserve 函数会将 capacity 扩容到 n;
- n 小于等于原字符串的 capacity,标准未规定是否要缩容 (VS下不缩容);


注:reserve 函数不会改变原字符串的 size 以及数据。
clear
clear 函数用来清空字符串,即将 size 改为0,至于是否会改变 capacity,标准也未规定:

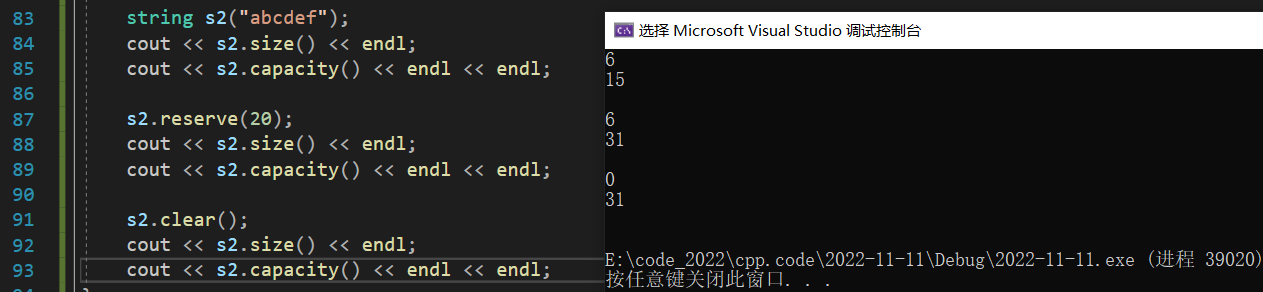
7、Element Access
string 提供了一些接口来获取字符串中的单个字符:

operator[]
运算符重载的一种,我们可以通过 opetator[] 来获取与修改字符串中具体下标的字符:

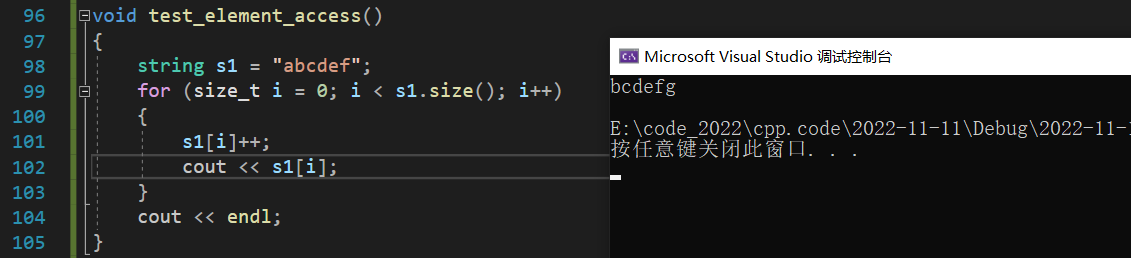
8、Modify
string 提供了一些列用来修改字符串内容的函数:
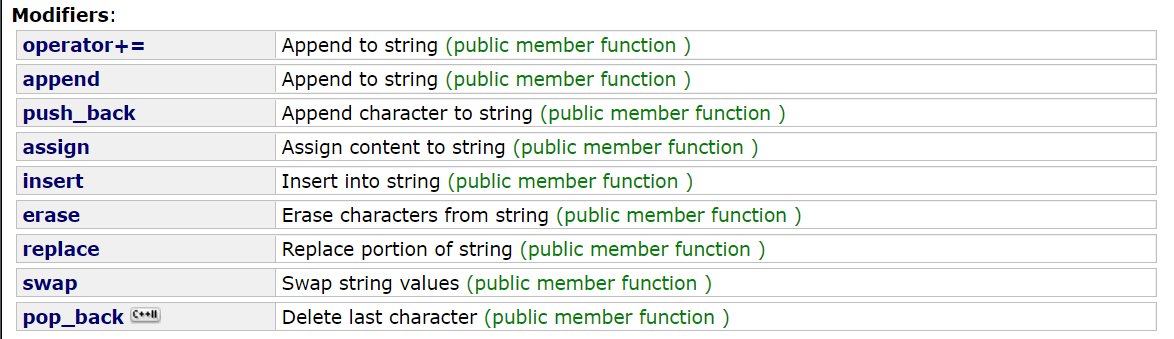
-函数名称 | -函数功能 |
|---|---|
push_back | 尾插一个字符 |
pop_back | 尾删一个字符 |
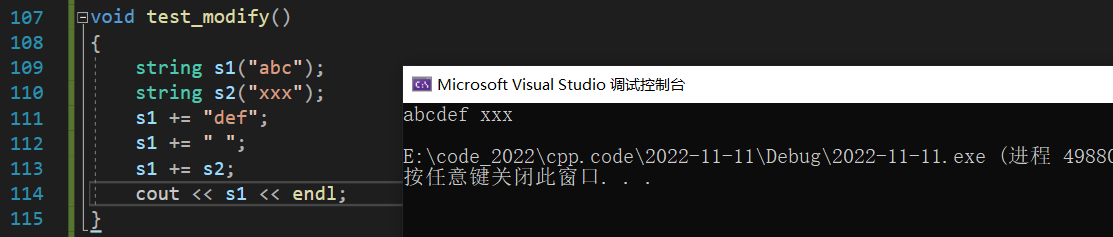
operator+=
operator+= 是运算符重载的一种,用于向字符串尾插数据,支持尾插一个字符串、尾插一个字符数组以及尾插一个字符:

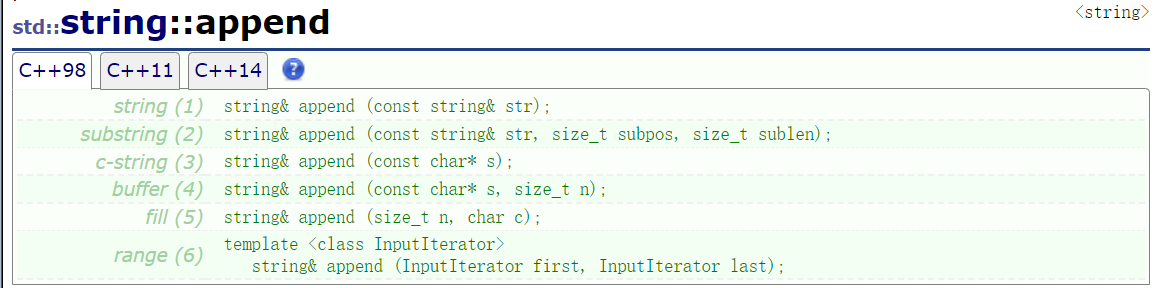
append
append 的功能和 operator+= 的功能类似,都是向字符串尾部追加数据:

insert
insert 函数用于向在字符串的 pos 处插入数据:


erase
erase 用来从 pos 位置开始向后删除 len 个字符:


注:len 的缺省值是 npos,虽然 npos 的值为-1,但是 npos 是无符号数,所以 npos 其实是无符号整形的最大值;所以,如果我们不知道 len,那么 erase 函数会一直往后删除,直到遇到 ‘\0’。
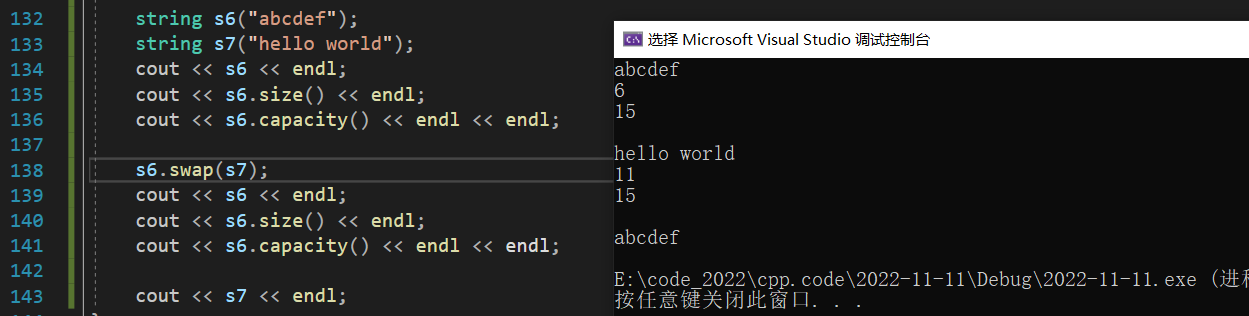
swap
swap 函用于交换两个字符串的内容,包括指向的字符数组、有效数据个数以及容量大小:

9、String Operations
string 提供了系列对 string 进行操作的函数:

c_str
在某些场景中只支持对C形式的字符串,即字符数组进行操作,比如网络传输、fopen,而不支持对C++中的 string 对象进行操作,所以 string 提供了c_str,用于返回C形式的字符串:


find
find 用于返回 一个字符或一个字符数组或一个string对象 在 string 中首次出现的位置,如果找不到就返回 npos:


rfind
find 函数是默认从起始位置开始从前往后找,而 rfind 函数是默认从倒数第二个位置从后往前找:

find_first_of
find_first_of 函数用于返回在 string 找寻找与 字符/字符数组/string 中任意一个字符匹配的元素的位置:


substr
stustr 函数可以将 string 中从 pos 位置开始往后的 n 个字符构造成一个新的 string 对象并返回:


10、Non-member function overloads
string 中还提供了一些非成员函数的重载函数:

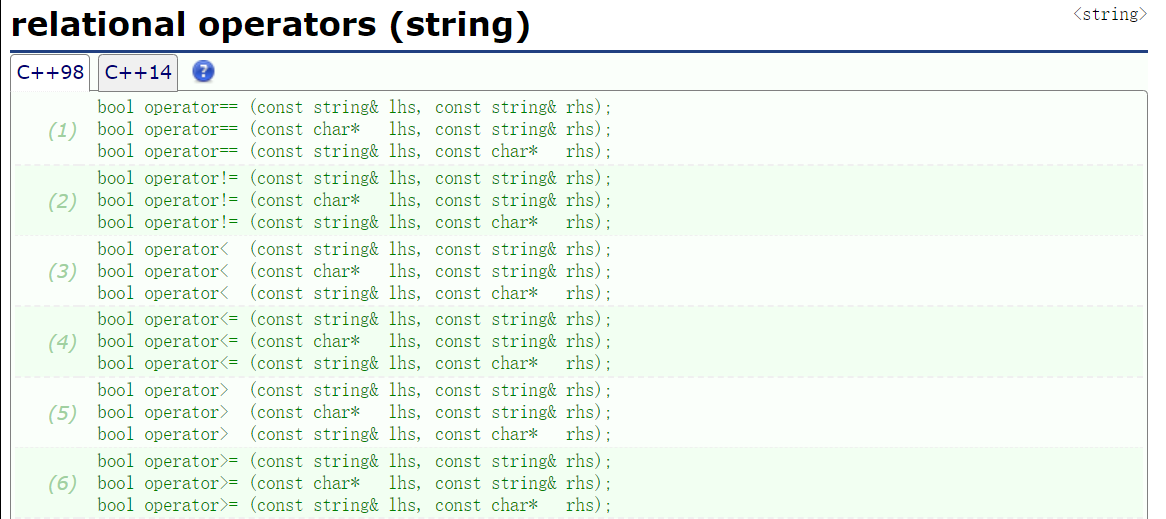
relation operators
两个 string 对象之间的大小关系重载函数:
operator<< 与 operator>>
流插入与流提取运算符重载:


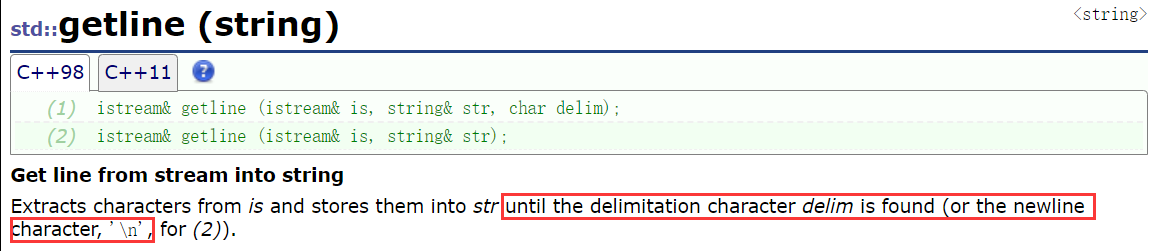
getline
C++ 中的 cin 和 C语言中的 scanf 函数都是以空格、换行、Tab 作为不同数据之间的分割标志的,即当它们遇到这些符号时就会停止读取:

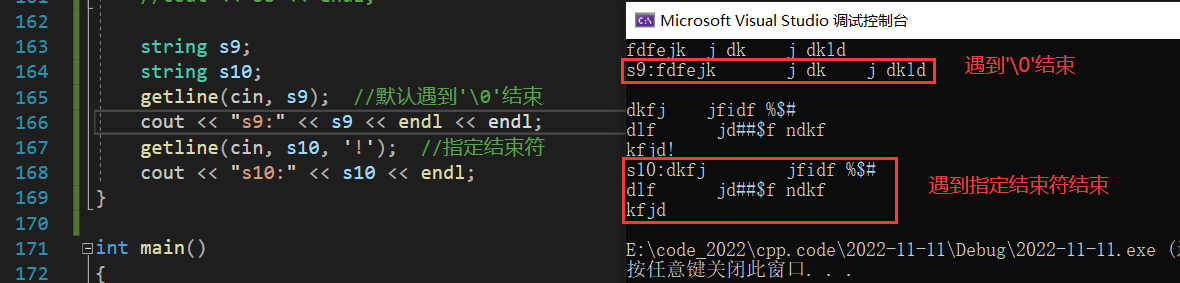
C语言提供了 gets 函数来读取一行字符,C++ 则是提供了 getline 函数来读取一行字符,并且我们还可以自己指定结束标志符:
三、string 类的模拟实现
string.h
#pragma once
#include <iostream>
#include <string.h>
#include <assert.h>
using namespace std;
namespace thj //将string的实现放在自己的命名空间域里面,防止与std里面的string冲突
{
class string
{
public:
//---------------------------member functions-------------------------------//
//构造
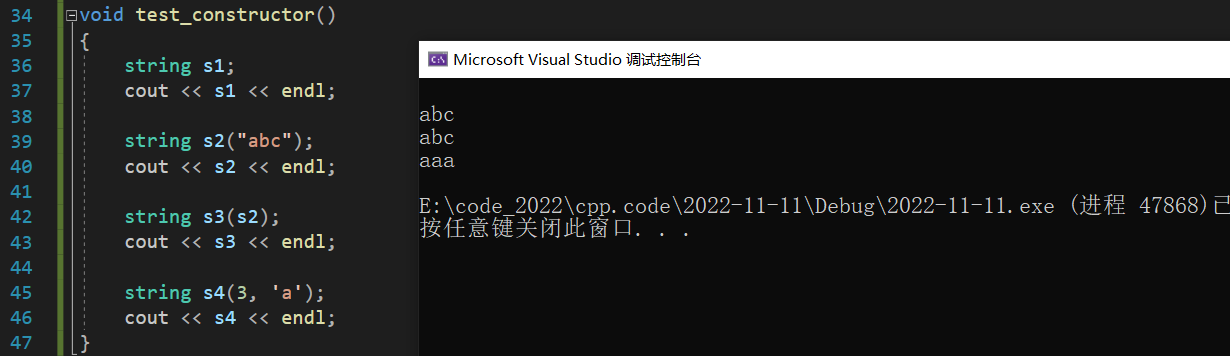
string(const char* str = "")
{
int len = strlen(str);
_size = _capacity = len; //capacity记录有效字符的个数
_str = new char[_capacity + 1]; //留一个空间给'\0'
strcpy(_str, str);
}
//析构
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
//拷贝构造--传统写法
//string(const string& s)
//{
// _size = s._size;
// _capacity = s._capacity;
// _str = new char[_capacity + 1];
// strcpy(_str, s._str);
//}
//拷贝构造--现代写法
string(const string& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
string tmp(s._str);
swap(tmp);
}
//赋值重载--传统写法
//string& operator=(const string& s)
//{
// if (this == &s) //检查自我赋值
// return *this;
// delete[] _str;
// _size = s._size;
// _capacity = s._capacity;
// _str = new char[_capacity + 1];
// strcpy(_str, s._str);
// return *this;
//}
//赋值重载--现代写法1
//string& operator=(const string& s)
//{
// if (this == &s) //检查自我赋值
// return *this;
// string tmp(s);
// swap(tmp);
// return *this;
//}
//赋值重载--现代写法2
string& operator=(string s)
{
swap(s);
return *this;
}
//--------------------------------------Tterators------------------------------------//
typedef char* iterator; //迭代器
typedef const char* const_iterator; //const 迭代器
iterator begin()
{
return _str;
}
const_iterator begin() const
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator end() const
{
return _str + _size;
}
//---------------------------------------Capacity--------------------------------------//
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}
//调整空间大小
void resize(size_t n, char ch = '\0')
{
if (n > _size && n <= _capacity) //容量不变
{
while (_size <= n)
{
_str[_size++] = ch;
}
_str[_size] = '\0';
}
else if (n > _capacity) //增容
{
reserve(n);
while (_size < n)
{
_str[_size++] = ch;
}
_str[_size] = '\0';
}
else
{
_size = n;
_str[_size] = '\0';
}
}
//预留空间
void reserve(size_t capacity)
{
_capacity = capacity;
char* tmp = new char[_capacity + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
}
void clear()
{
_size = 0;
_str[_size] = '\0';
}
bool empty() const
{
return _size == 0;
}
//---------------------------------------Modify----------------------------------------//
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
void push_back(char c)
{
if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 5 : _capacity * 2;
reserve(newcapacity);
}
_str[_size++] = c;
_str[_size] = '\0';
}
//尾插一个字符串
void append(const char* str)
{
int len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
//+=一个字符
string& operator+=(char c)
{
push_back(c);
return *this;
}
//+=一个字符串
string& operator+=(const char* str)
{
append(str);
return *this;
}
//插入一个字符
string& insert(size_t pos, char c)
{
assert(pos >= 0 && pos <= _size);
if (_size + 1 > _capacity)
{
size_t newcapacity = _capacity == 0 ? 5 : _capacity * 2;
reserve(newcapacity);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
end--;
}
_str[end] = c;
_size++;
return *this;
}
//插入一个字符串
string& insert(size_t pos, const char* str)
{
assert(pos >= 0 && pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
size_t end = _size + 1;
while (end > pos)
{
_str[len + end - 1] = _str[end - 1];
end--;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
string& erase(size_t pos, size_t n = -1)
{
assert(pos >= 0 && pos <= _size);
if (pos + n >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
size_t left = pos, right = pos + n;
while (right <= _size)
{
_str[left] = _str[right];
left++;
right++;
}
_size -= n;
}
return *this;
}
void pop_back()
{
_size--;
_str[_size] = '\0';
}
//交换两个字符串
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
//----------------------------------------String operations-----------------------------//
const char* c_str() const
{
return _str;
}
size_t find(char c, size_t pos = 0)
{
assert(pos >= 0 && pos <= _size);
for (size_t i = pos; i < _size; ++i)
{
if (_str[i] == c)
return i;
}
return -1;
}
size_t rfind(char c, size_t pos = 0)
{
assert(pos >= 0 && pos <= _size);
for (size_t i = _size; i > 0; --i)
{
if (_str[i - 1] == c)
return i;
}
return -1;
}
size_t find(const char* str, size_t pos = 0)
{
assert(pos >= 0 && pos <= _size);
const char* ptr = strstr(_str + pos, str);
return ptr == 0 ? -1 : ptr - _str;
}
//---------------------------------Non-member function overloads----------------------------//
friend ostream& operator<<(ostream& out, const string& s);
friend istream& operator>>(istream& in, string& s);
friend istream& getline(istream& in, string& s);
private:
char* _str;
size_t _size;
size_t _capacity;
};
//流插入重载
inline ostream& operator<<(ostream& out, const string& s)
{
for (size_t i = 0; i < s._size; ++i)
{
out << s._str[i];
}
return out;
}
//流提取重载
inline istream& operator>>(istream& in, string& s)
{
//char ch = in.get();
//while (ch != ' ' && ch != '\n') //cin遇到空格或者换行结束
//{
// s += ch;
// ch = in.get();
//}
//优化
char buff[128] = { '\0' };
size_t i = 0;
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
if (i == 127)
{
s += buff;
i = 0;
}
buff[i++] = ch;
ch = in.get();
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}
//读入一行字符
inline istream& getline(istream& in, string& s)
{
char buff[128] = { '\0' };
size_t i = 0;
char ch = in.get();
while (ch != '\n')
{
if (i == 127)
{
s += buff;
i = 0;
}
buff[i++] = ch;
ch = in.get();
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
}
};test.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include "string.h"
void Test_String1()
{
//构造
thj::string s1;
thj::string s2("abcdef");
//拷贝构造
thj::string s3 = s2;
//赋值重载
s1 = s2;
}
void Test_string2()
{
thj::string s1("1234");
thj::string::iterator it = s1.begin();
for (it; it < s1.end(); ++it)
(*it)++;
cout << s1.c_str() << endl;
const thj::string s2("1234");
thj::string::iterator it2 = s2.begin();
for (it2; it2 < s2.end(); ++it2)
(*it2)++;
cout << s2.c_str() << endl;
}
void Test_string3()
{
thj::string s("hello world");
cout << s.size() << endl;
cout << s.capacity() << endl;
cout << s.c_str() << endl;
//s.resize(5);
//cout << s.size() << endl;
//cout << s.capacity() << endl;
//cout << s.c_str() << endl;
//s.reserve(15);
//cout << s.size() << endl;
//cout << s.capacity() << endl;
//cout << s.c_str() << endl;
//s.resize(12, 'x');
//cout << s.size() << endl;
//cout << s.capacity() << endl;
//cout << s.c_str() << endl;
s.resize(20, 'x');
cout << s.size() << endl;
cout << s.capacity() << endl;
cout << s.c_str() << endl;
}
void Test_string4()
{
//thj::string s = "hello world";
//s.push_back('!');
//cout << s.c_str() << endl;
//s.append("xxx");
//cout << s.c_str() << endl;
//s += "1";
//cout << s.c_str() << endl;
//s += "234";
//cout << s.c_str() << endl;
//thj::string s1 = "hello w";
//s1.insert(3, 'x');
//cout << s1.c_str() << endl;
//s1.insert(8, 'x');
//cout << s1.c_str() << endl;
//s1.insert(0, 'x');
//cout << s1.c_str() << endl;
//thj::string s2 = "hello";
//s2.insert(5, " world");
//cout << s2.c_str() << endl;
//s2.insert(2, "xxxxxxxxxxxxxxxxx");
//cout << s2.c_str() << endl;
//s2.insert(0, "!!!!!!!!!!");
//cout << s2.c_str() << endl;
thj::string s3 = "hello world";
s3.erase(11, 10);
cout << s3.c_str() << endl;
s3.erase(1, 2);
cout << s3.c_str() << endl;
s3.erase(0, 4);
cout << s3.c_str() << endl;
}
void Test_String5()
{
thj::string s = "abcdefefeeffc";
cout << s.find('c', 5) << endl;
cout << s.find('c') << endl;
cout << s.find("efe") << endl;
cout << s.find("efe", 5) << endl;
cout << s.find("efe", 7) << endl;
}
void Test_string6()
{
thj::string s;
cin >> s;
cout << s << endl;
thj::string s1;
cin >> s1;
cout << s1 << endl;
thj::string s2;
thj::getline(cin, s2);
cout << s2 << endl;
}
int main()
{
//member functions
//Test_String1();
//iteratos
//Test_string2();
//capacity
//Test_string3();
//modify
//Test_string4();
//string operations
//Test_String5();
//non-mumber function overloads
Test_string6();
return 0;
}腾讯云开发者
