图解ConcurrentHashMap中的链表升级为红黑树的过程

图解ConcurrentHashMap中的链表升级为红黑树的过程

博文视点Broadview
发布于 2023-04-04 10:20:00
发布于 2023-04-04 10:20:00
👆点击“博文视点Broadview”,获取更多书讯


ConcurrentHashMap是JDK从Java 1.5版本开始提供的适用于多线程高并发环境下的线程安全的Map集合类,随着JDK的不断迭代,ConcurrentHashMap类也在不断地升级和优化。
Java 7以及之前版本中的ConcurrentHashMap使用分段锁技术将数据分段存储,然后为每一段数据单独分配锁,此时一个线程占有锁访问其中一个段的数据不影响其他线程访问其他段的数据,多个线程能够并发访问ConcurrentHashMap中不同段的数据。
Java 8版本对ConcurrentHashMap内部结构进行了优化和升级,使用CAS和synchronized锁的方式保证数据的一致性,在高并发场景下锁住数组的节点,在性能上得到进一步提升。
01 Java7 ConcurrentHashMap
Java 7及之前版本中的ConcurrentHashMap 使用Segment数组、HashEntry数组和链表实现,整体结构如下图所示。
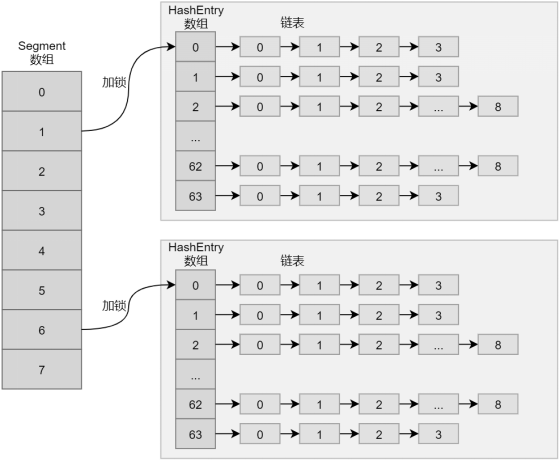
此时的ConcurrentHashMap使用了分段锁技术,也就是Segment数组保证线程安全,将数据分段存储。Segment数组中的每一个元素都是一个段,都会存储一个HashEntry数组。从结构上看,每个单独的HashEntry数组都相当于一个HashMap。
在高并发场景下修改ConcurrentHashMap中的数据时,只会针对Segment数组中的每个元素加锁,也就是只会锁住Segment数组中的每个元素,它们分别负责自身对应的锁。采用这种分段锁技术向ConcurrentHashMap中的不同段插入和更新数据,不同段之间不会有任何影响。所以ConcurrentHashMap真正做到了并发地插入和更新数据。
02
Java8 ConcurrentHashMap
Java 8及之后版本中的ConcurrentHashMap去除了Segment数组和分段锁方案,使用和HashMap相同的结构,也就是数组、链表和红黑树的结构,并使用CAS+synshronized锁的方式保证线程的安全性。
在ConcurrentHashMap中,存在一个Node类型的数组table,table是一个哈希桶数组,数组中的每个节点都可以看作一个哈希桶。如果不会发生哈希冲突,则每个元素都保存在哈希桶数组中。如果发生哈希冲突,则使用标准的链地址(拉链法)解决哈希冲突。为了防止拉链过长,也就是链表的长度过长,ConcurrentHashMap会根据一定的规则将链表转化成红黑树。table数组中的每个元素实际上存储的都是单链表的头节点或者红黑树的根节点,当向ConcurrentHashMap中插入键-值对时,首先要定位到要插入的桶,也就是要定位到table数组的某个索引下标处。
当ConcurrentHashMap中只存在table数组和链表时,整体结构如下所示。
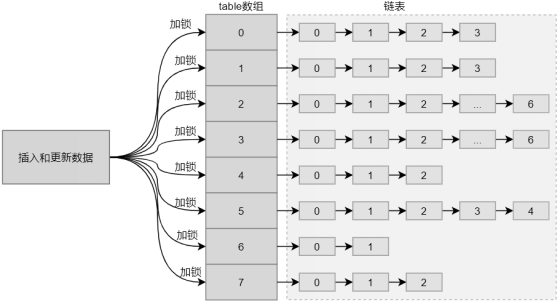
可以看出,在ConcurrentHashMap中插入和更新数据时,会对table数组中的每一个节点都单独加锁,并且在数组中的每个节点下存储一个链表。
在使用链表存储数据时,会从链表的头部向后遍历数据,如果要查找的数据恰好在链表的尾部,则每次获取数据都要遍历整个链表。如果链表长度过长,那么会极大地影响获取数据的效率。为此,在Java 8及之后版本的JDK中,ConcurrentHashMap会在一定条件下将内部的链表自动转化为红黑树,如下所示。
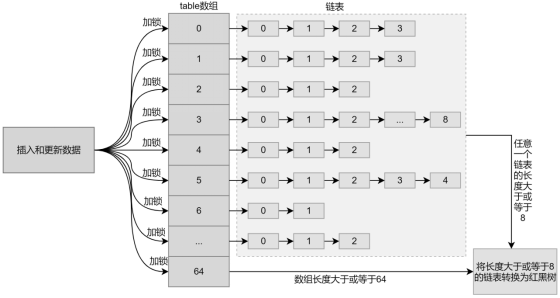
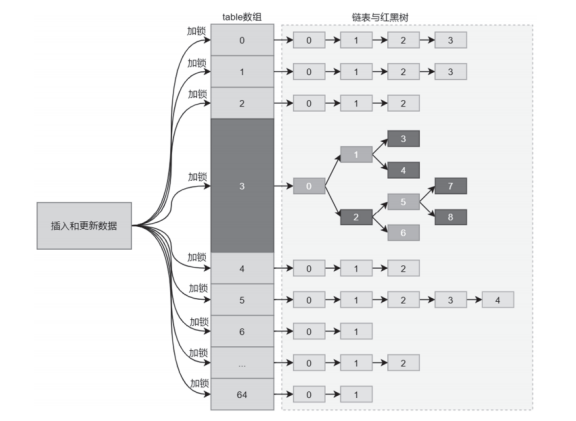
可以看出,当ConcurrentHashMap中的数组长度大于或等于64、table数组中任意一个链表的长度大于或等于8时,会将长度大于或等于8的链表转化为红黑树,数组中其他位置的链表保持不变。转化成如下所示的结构。
本文节选自《深入理解高并发编程:JDK核心技术》一书,本书是冰河编写的专注介绍JDK高并发编程技术的书籍。
关于书籍
JDK中有很多并发编程工具类,各种并发编程类库,比如:并发容器类、并发阻塞队列、并发非阻塞队列、并发工具类、锁工具类、无锁原子类、线程工具类和线程池等等,都是JDK中对于并发编程核心原理的深度实践。并且JDK中这些并发编程的类库经历了实际生产环境中高并发、大流量的考验,是学习高并发编程非常好的实践案例,并且这些案例是任何一个学习Java的小伙伴非常容易获得的宝贵资源。
尽管JDK中提供了很多并发编程的类库,但是,很多学习Java的小伙伴对于JDK中提供的并发编程类库的用法、原理和底层源码流程不太熟悉,这就导致很多小伙伴在学习并发编程时,处于浅尝辄耻的状态,了解一点并发编程的知识,但是不够系统和深入。平时了解的并发编程知识也达不到面试的要求,导致每次面试前都要重新背一遍八股文,收效甚微,最终浪费了很多宝贵的时间。更严重的是,在实际项目开发过程中,涉及到高并发编程时,还是一脸懵。
另外,市面上专注系统并深入介绍JDK并发编程的书籍和博客非常少,缺少JDK并发编程经验的小伙伴很难系统并深入的学习JDK并发编程知识,又会导致自身对于JDK并发编程知识的匮乏,最终又会导致进入面背被八股文的恶性循环中。
所以,《深入理解高并发编程:JDK核心技术》一书会系统并深入的介绍JDK并发编程的各种类库和线程池,让你从案例、原理和底层源码执行流程等方面彻底理解JDK并发编程技术,告别面试背八股文的恶性循环,提升并发编程的内功修炼,为你的面试和职业生涯保驾护航。
全书结构
《深入理解高并发编程:JDK核心技术》一书从实际需求出发,将全书分为三个大的篇章,分别是:JDK高并发编程的基础知识、核心工具和线程池核心技术。
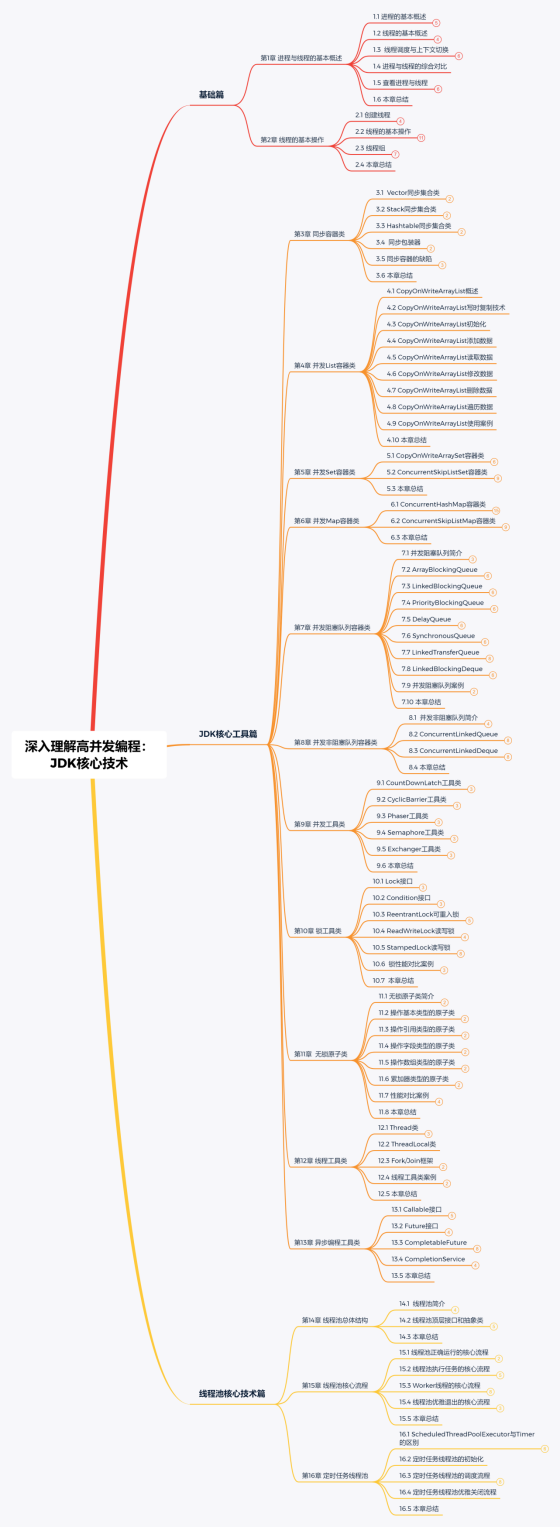
第一篇 基础篇(第1~2章)
本篇简单地介绍了进程与线程的基本概念、线程调度与上下文切换、进程与线程的综合对比、如何查看进程与线程的运行时信息,以及线程和线程组的基本操作。
第二篇 核心工具篇(第3~13章)
本篇通过大量源码和案例详细介绍了JDK的各种并发工具,涵盖同步集合、并发List集合类、并发Set集合类、并发Map集合类、并发阻塞队列、并发非阻塞队列、并发工具类、锁工具类、无锁原子类、线程工具类和异步编程工具类。几乎每个章节都配有JDK核心工具类的源码及实战案例,有助于读者理解。
第三篇 线程池核心技术篇(第14~16章)
本篇深入剖析了JDK中线程池的核心源码。包括线程池顶层接口和抽象类、线程池正确运行的核心流程、线程池执行任务的核心流程、Worker线程的核心流程、线程池优雅退出的核心流程、ScheduledThreadPoolExecutor类与Timer类的区别、定时任务线程池的初始化、调度流程和优雅关闭流程等。通过对本篇的学习,读者能够从源码级别深刻理解线程池的核心原理和执行流程。
为了进一步加深读者对线程池的理解,在本篇的随书源码中,会给出完整的手写线程池的案例程序。
本书特色
1. 系统介绍JDK高并发编程的图书
目前,图书市场少有全面细致地介绍有关JDK高并发编程的基础知识、核心工具和线程池核心技术的图书。
本书从以上三方面入手,全面、细致并且层层递进地介绍了JDK高并发编程相关知识。
2. 大量图解和开发案例
为了便于理解,笔者在介绍JDK高并发编程的基础知识和核心工具章节中会配有适量的图解和图表,以及对应的实战案例。
在线程池核心技术章节中会配有完整的手写线程池案例。读者按照本书的案例学习,并运行案例代码,能够更加深入地理解和掌握相关知识。
另外,这些案例代码和图解的draw.io原文件会一起收录于随书资料里。读者也可以访问下面的链接,获取完整的实战案例源码和相关的随书资料。
- GitHub:https://github.com/binghe001/mykit-concurrent-jdk
- Gitee:https://gitee.com/binghe001/mykit-concurrent-jdk
- GitCode:https://gitcode.net/binghe001/mykit-concurrent-jdk
3. 技术点与案例结合
对于JDK高并发编程的各项技术,书中都配有相关的典型案例,具有很强的实用性,方便读者随时查阅和参考。
4. 具备较高的实用价值
本书中大量的实战案例来源于笔者实际的工作总结,尤其是核心工具篇与线程池核心技术篇涉及的内容,具有非常高的参考与实用价值。
其中,在线程池核心技术篇的随书源码中,会带着大家从零开始手写线程池核心源码。
读者对象
说了这么多,《深入理解高并发编程:JDK核心技术》一书适合哪些小伙伴阅读呢?
综合来看,本书适合:联网行业从业人员、高校师生、中高级开发人员、架构师、技术经理及技术专家和对高并发编程感兴趣的人员学习阅读。
另外,由于本书是专注介绍JDK并发编程技术的图书,强烈建议Java方向的小伙伴人手一册。

限时五折优惠,快快扫码抢购吧!
发布:刘恩惠
审核:陈歆懿
如果喜欢本文欢迎 在看丨留言丨分享至朋友圈 三连< PAST · 往期回顾 >
听说B站和ChatGPT都在搞宕机?
点击阅读原文,查看本书详情!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-03-24,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 博文视点Broadview 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号