图的基本概念以及DFS与BFS算法

Ⅰ. 图的基本概念
图是由顶点集合及顶点间的关系组成的一种数据结构: G = (V , E),其中:
- 顶点集合 V = {x|x 属于某个数据对象集 } 是有穷非空集合;
- E = { (x,y)|x,y 属于 V } 或者 E = { <x, y>|x,y 属于 V && Path(x, y) } 是顶点间关系的有穷集合,也叫做边的集合。
(x, y) 表示 x 到 y 的一条双向通路,即 (x, y) 是无方向的;Path(x, y) 表示从x到y的一条单向通路,即Path(x, y) 是有方向的。
顶点和边:图中结点称为顶点,第 i 个顶点记作 vi。两个顶点 vi 和 vj 相关联称作顶点 vi 和顶点 vj 之间有一条边,图中的第 k 条边记作 ek,ek = (vi,vj) 或 <vi,vj>。
有向图和无向图:
- 在有向图中,顶点对 <x, y> 是有序的,顶点对 <x , y> 称为顶点 x 到顶点 y 的一条边 ( 弧 ) , < x, y > 和 < y, x > 是两条不同的边,比如下图G3和G4为有向图。
- 在 无向图中,顶点对 (x, y) 是无序的,顶点对 (x,y) 称为顶点 x 和顶点 y 相关联的一条边,这条边没有特定方向, (x, y) 和 (y , x) 是同一条边,比如下图G1和G2为无向图。注意:无向边 (x, y) 等于有向边 <x, y> 和 <y, x>。
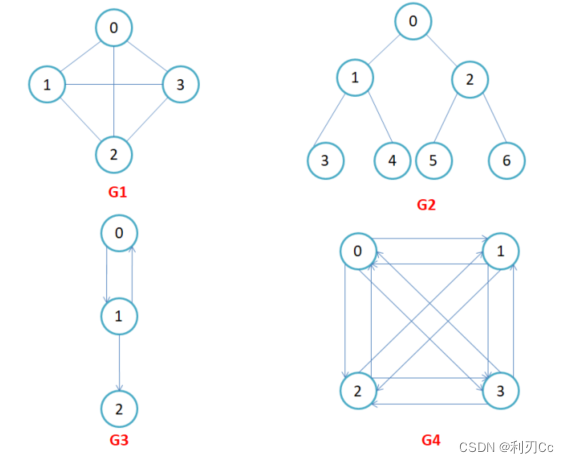
完全图:在有 n 个顶点的无向图中,若有 n * (n-1)/2 条边,即**任意两个顶点之间有且仅有一条边,则称此图为无向完全图,比如上图G1;在n** 个顶点的有向图中,若有 n * (n-1) 条边,即**任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图**,比如上图G4和下面图4。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j4layFDW-1675641132779)(../../img/image-20221113120653604.png)]](https://developer.qcloudimg.com/http-save/yehe-10147998/233675c2cefa272bf55c7febf715a8f5.png)
邻接顶点:在无向图中 G 中,若 (u, v) 是 E(G) 中的一条边,则称 u 和 v 互为邻接顶点,并称边 (u,v) 依附于顶点 u 和 v;在有向图 G 中,若 <u, v> 是 E(G) 中的一条边,则称顶点 u 邻接到 v ,顶点 v 邻接自顶点 u ,并称边 <u, v> 与顶点 u 和顶点 v 相关联。
顶点的度(degree):顶点 v 的度是指与它相关联的边的条数,记作 deg(v)。在有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点v的入度是以 v 为终点的有向边的条数,记作 indev(v) ;顶点v的出度是以 v 为起始点的有向边的条数,记作 outdev(v) 。因此 有向图顶点的度:dev(v) = indev(v) + outdev(v)。注意:对于 无向图,顶点的度等于该顶点的入度和出度,即 dev(v) = indev(v) = outdev(v)。
路径:在图G = (V, E)中,若从顶点 vi 出发有一组边使其可到达顶点 vj ,则称顶点 vi 到顶点 vj 的顶点序列为从顶点 vi 到顶点 vj 的路径。
路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-frB4JWdA-1675641132780)(../../img/image-20221113115236730.png)]](https://developer.qcloudimg.com/http-save/yehe-10147998/6bce61ddf58068a971bca430fc00d6a0.png)
简单路径与回路:若路径上各顶点 v1 , v2 , v3 , … , vm 均不复,则称这样的路径为简单路径。若路径上第一个顶点 v1 和最后一个顶点 vm 重合,则称这样的路径为回路或环。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H5CWQxeC-1675641132780)(../../img/image-20221113115459299.png)]](https://developer.qcloudimg.com/http-save/yehe-10147998/6c510ed21619e5fcd847aa76e1d025c7.png)
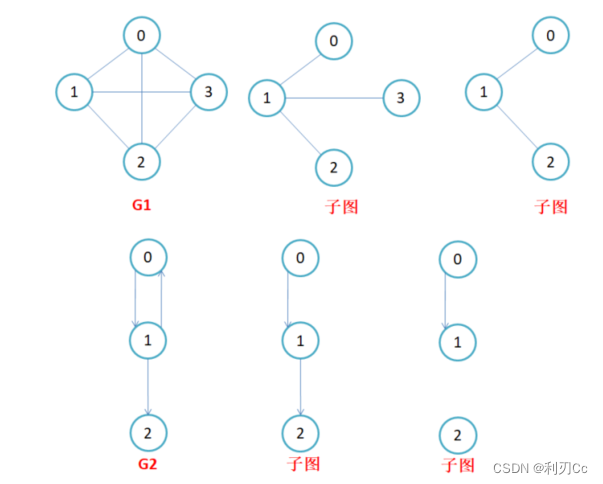
子图:指的是由图中一部分顶点和边构成的图,称为原图的子图。
生成树:一个无向连通图的最小连通子图称作该图的生成树。有 n 个顶点的连通图的生成树有 n 个顶点和 n- 1 条边。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Nv0X0h7-1675641132781)(../../img/image-20221113133942741.png)]](https://developer.qcloudimg.com/http-save/yehe-10147998/a163730a4792c581a99935bce39b8401.png)
如图 1 所示,图 1a) 是一张连通图,图 1b) 是其对应的 2 种生成树。
连通图中,由于任意两顶点之间可能含有多条通路,遍历连通图的方式有多种,往往一张连通图可能有多种不同的生成树与之对应。
连通图中的生成树必须满足以下 2 个条件:
- 包含连通图中所有的顶点
- 任意两顶点之间有且仅有一条通路
因此,连通图的生成树具有这样的特征,即生成树中 边的数量 = 顶点数 - 1。
生成森林:生成树是对应连通图来说,而生成森林是对应非连通图来说的。 我们知道,非连通图可分解为多个连通分量,而每个连通分量又各自对应多个生成树(至少是 1 棵),因此与整个非连通图相对应的,是由多棵生成树组成的生成森林。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SDOeDjRS-1675641132781)(../../img/image-20221113134622615.png)]](https://developer.qcloudimg.com/http-save/yehe-10147998/e922631c40224b5c9e84b9936f48886a.png)
如图 2 所示,这是一张非连通图,可分解为 3 个连通分量,因此,多个连通分量对应的多棵生成树就构成了整个非连通图的生成森林。
稀疏图和稠密图:这两种图是相对存在的,即如果图中具有很少的边(或弧),此图就称为"稀疏图";反之,则称此图为"稠密图"。 稀疏和稠密的判断条件是:e<nlogn,其中 e 表示图中边(或弧)的数量,n 表示图中顶点的数量。如果式子成立,则为稀疏图;反之为稠密图。
连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图。
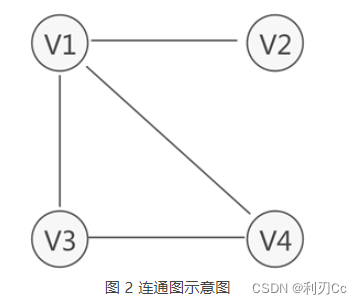
若无向图不是连通图,但图中存储某个子图符合连通图的性质,则称该子图为**连通分量**。
如图 3 所示,虽然图 3a) 中的无向图不是连通图,但可以将其分解为 3 个"最大子图"(图 3b)),它们都满足连通图的性质,因此都是连通分量。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H7y45TzO-1675641132781)(../../img/image-20221113122844432.png)]](https://developer.qcloudimg.com/http-save/yehe-10147998/e177ce122c8a5e21ce21775040533ac0.png)
提示,图 3a) 中的无向图只能分解为 3 部分各自连通的"最大子图"。
🔴 需要注意的是,连通分量的提出是以"整个无向图不是连通图"为前提的,因为如果无向图是连通图,则其无法分解出多个最大连通子图,因为图中所有的顶点之间都是连通的。
强连通图:在有向图中,若在每一对顶点 vi 和 vj 之间都存在一条从 vi 到 vj 的路径,也存在一条从 vj 到 vi 的路径,则称此图是强连通图。
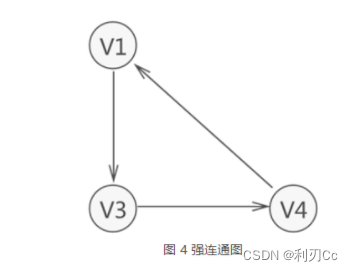
与此同时,若有向图本身不是强连通图,但其包含的最大连通子图具有强连通图的性质,则称该子图为强连通分量。
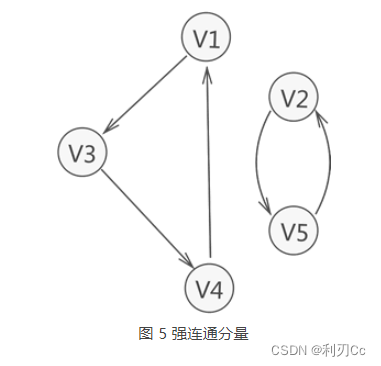
如图 5 所示,整个有向图虽不是强连通图,但其含有两个强连通分量。
可以这样说,连通图是在无向图的基础上对图中顶点之间的连通做了更高的要求,而强连通图是在有向图的基础上对图中顶点的连通做了更高的要求。
Ⅱ. 图的存储结构
因为图中既有节点,又有边(节点与节点之间的关系),因此,在图的存储中,只需要保存:节点和边关系即可。节点保存比较简单,只需要一段连续空间即可,那边的关系该怎么保存呢?下面会介绍两种常见的方法:邻接矩阵和邻接表
1、邻接矩阵
因为节点与节点之间的关系就是连通与否,即为0或者1,因此邻接矩阵 ( 二维数组 ) 即是:先用一个数组将顶点保存起来,然后采用矩阵来表示节点与节点之间的关系。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oY4iTB8Z-1675641132782)(../../img/image-20221113224839809.png)]](https://developer.qcloudimg.com/http-save/yehe-10147998/714935f86ee6db716df3ea953403bda7.png)
🦅 注意:
- 用邻接矩阵存储图的 优点是能够快速知道两个顶点是否连通(时间复杂度为O(1)),缺点 是如果 顶点比较多,边比较少时(如稀疏图),矩阵中存储了大量的0成为系数矩阵,比较 浪费空间,并且 要求两个节点之间的路径不是很好求。
- 无向图的邻接矩阵是对称的,第 i 行 ( 列 ) 元素之和,就是顶点 i 的度。有向图的邻接矩阵则不一定是对称的,第 i 行 ( 列 ) 元素之后就是顶点 i 的出 ( 入 ) 度。
- 如果边带有权值,并且两个节点之间是连通的,上图中的边的关系就用权值代替,如果两个顶点不通,则使用无穷大替代。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lcbgH83D-1675641132782)(../../img/image-20221113230022926.png)]](https://developer.qcloudimg.com/http-save/yehe-10147998/19e031c66f85bab97e18a29c3a85b7d9.png)
// 邻接矩阵
namespace matrix
{
// V代表的是顶点的元素类型
// W代表的是边的权值类型
// MAX_W是边的权值,以INT_MAX代表无穷大
// Direction代表的true为有向图,false为无向图
template <class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph
{
public:
// 图的创建
// 1、IO输入 -- 不方便测试,更适合oj
// 2、图结构关系写到文件,读取文件
// 3、手动添加边,方便调试,这里选用这种方式
Graph(const V* a, size_t n)
{
// 初始化顶点集合和顶点映射的下标
_vertexs.reserve(n);
for (size_t i = 0; i < n; ++i)
{
_vertexs.push_back(a[i]);
_vIndexMap[a[i]] = i;
}
// 初始化矩阵
_matrix.resize(n);
for (size_t i = 0; i < n; ++i)
_matrix[i].resize(n, MAX_W);
}
// 链接边的函数
void AddEdge(const V& src, const V& dst, const W& w)
{
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
_matrix[srci][dsti] = w;
// 判断是否为无向图,是的话矩阵要对称赋值
if (Direction == false)
{
_matrix[dsti][srci] = w;
}
}
// 查找顶点映射的下标
size_t GetVertexIndex(const V& v)
{
// 为了防止顶点不存在的情况,这里我们使用map的find函数
auto it = _vIndexMap.find(v);
if (it == _vIndexMap.end())
{
throw invalid_argument("顶点不存在");
return -1;
}
else
{
return it->second;
}
}
// 为了方便观察,要实现一个打印函数
void Print()
{
// 顶点
for (size_t i = 0; i < _vertexs.size(); ++i)
{
cout << "[" << i << "]" << "->" << _vertexs[i] << endl;
}
cout << endl;
// 矩阵
// 横下标
cout << " ";
for (int i = 0; i < _vertexs.size(); ++i)
{
//cout << i << " ";
printf("%4d", i);
}
cout << endl;
for (int i = 0; i < _matrix.size(); ++i)
{
cout << i << " "; // 竖下标
for (int j = 0; j < _matrix[i].size(); ++j)
{
//cout << _matrix[i][j] << " ";
if (_matrix[i][j] == MAX_W)
{
//cout << "* ";
printf("%4c", '*');
}
else
{
//cout << _matrix[i][j] << " ";
printf("%4d", _matrix[i][j]);
}
}
cout << endl;
}
cout << endl;
}
private:
vector<V> _vertexs; // 顶点集合
vector<vector<W>> _matrix; // 存储边集合的矩阵
map<V, size_t> _vIndexMap; // 相应顶点映射的下标
};
void TestGraph()
{
Graph<char, int, INT_MAX, true> g("0123", 4);
g.AddEdge('0', '1', 1);
g.AddEdge('0', '3', 4);
g.AddEdge('1', '3', 2);
g.AddEdge('1', '2', 9);
g.AddEdge('2', '3', 8);
g.AddEdge('2', '1', 5);
g.AddEdge('2', '0', 3);
g.AddEdge('3', '2', 6);
g.Print();
}
}
// 运行结果
[0]->0
[1]->1
[2]->2
[3]->3
0 1 2 3
0 * 1 * 4
1 * * 9 2
2 3 5 * 8
3 * * 6 *2、邻接表
邻接表:使用数组表示顶点的集合,使用链表表示边的关系。(跟哈希表类似)
邻接表存储图的实现方式是,给图中的各个顶点独自建立一个链表,用节点存储该顶点,用链表中其他节点存储各自的临界点。与此同时,为了便于管理这些链表,通常会将所有链表的头节点存储到数组中(也可以用链表存储)。也正因为各个链表的头节点存储的是各个顶点,因此各链表在存储临界点数据时,仅需存储该邻接顶点位于数组中的位置下标即可。
- 无向图邻接表存储
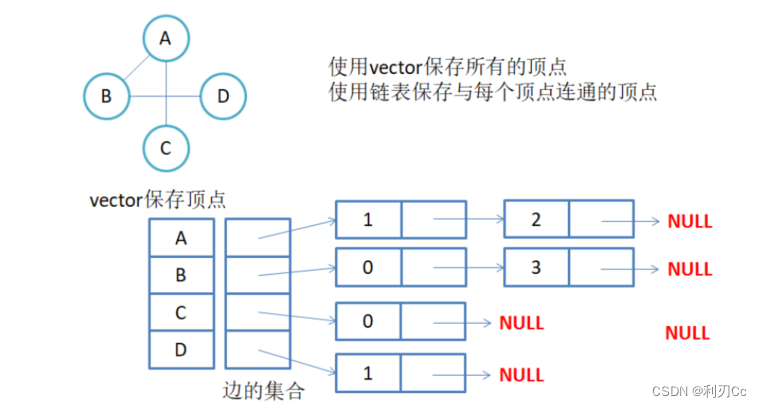
🔴 注意:无向图中同一条边在邻接表中出现了两次。如果想知道顶点 vi 的度,只需要知道顶点 vi 边链表集合中结点的数目即可。
- 有向图邻接表存储
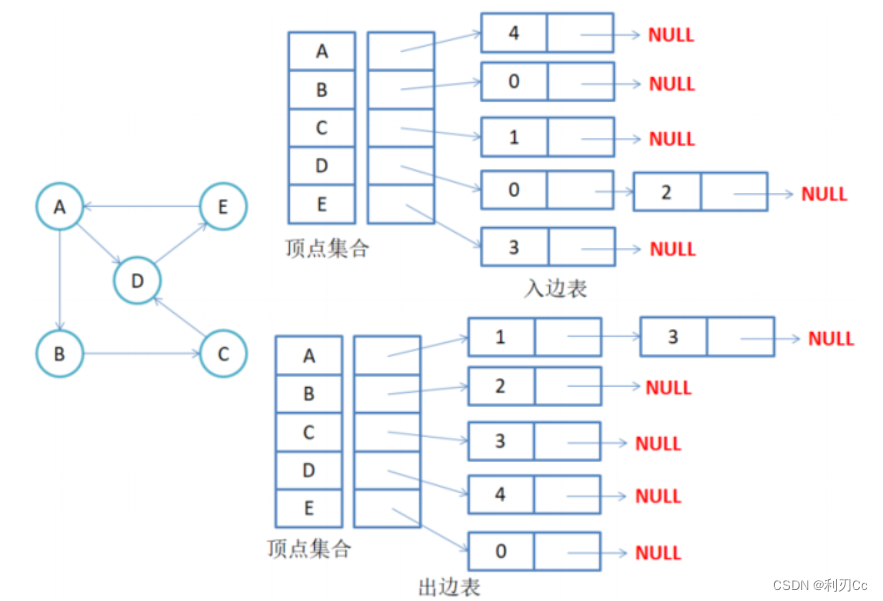
🔺 注意:有向图中每条边在邻接表中只出现一次,与顶点 vi 对应的邻接表所含结点的个数,就是该顶点的出度,也称出度表,要得到 vi 顶点的入度,必须检测其他所有顶点对应的边链表,看有多少边顶点的 dst 取值是 i。 所以就有了上图中的入边表,但是我们 一般是不需要入边表的,所以下面不会实现!
// 邻接表
namespace Adjacency_table
{
template <class W>
struct Edge
{
//size_t _srcIndex; // 这是入度的下标,一般不用实现
size_t _dstIndex; // 代表出度下标
W _weight; // 权值
Edge<W>* _next; // 链表的下一个节点
Edge(size_t dstIndex, W weight = W())
:_dstIndex(dstIndex)
, _weight(weight)
, _next(nullptr)
{}
};
// V代表的是顶点的元素类型
// W代表的是边的权值类型
// MAX_W是边的权值,以INT_MAX代表无穷大
// Direction代表的true为有向图,false为无向图
template <class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph
{
typedef Edge<W> Edge;
public:
Graph(const V* a, size_t n)
{
_vertexs.reserve(n);
_tables.resize(n, nullptr);
for (size_t i = 0; i < n; ++i)
{
_vertexs.push_back(a[i]);
_vIndexMap[a[i]] = i;
}
}
// 链接边的函数
void AddEdge(const V& src, const V& dst, const W& w)
{
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
// 进行头插
Edge* newEdge = new Edge(dsti, w);
newEdge->_next = _tables[srci];
_tables[srci] = newEdge;
// 判断是否为无向图
if (Direction == false)
{
// 同样进行头插
Edge* newEdge = new Edge(srci, w);
newEdge->_next = _tables[dsti];
_tables[dsti] = newEdge;
}
}
// 查找顶点映射的下标
size_t GetVertexIndex(const V& v)
{
// 为了防止顶点不存在的情况,这里我们使用map的find函数
auto it = _vIndexMap.find(v);
if (it == _vIndexMap.end())
{
throw invalid_argument("顶点不存在");
return -1;
}
else
{
return it->second;
}
}
// 为了方便观察,要实现一个打印函数
void Print()
{
// 顶点
for (size_t i = 0; i < _vertexs.size(); ++i)
{
cout << "[" << i << "]" << "->" << _vertexs[i] << endl;
}
cout << endl;
for (size_t i = 0; i < _tables.size(); ++i)
{
cout << _vertexs[i] << "[" << i << "]->";
Edge* cur = _tables[i];
while (cur)
{
cout << "[" << _vertexs[cur->_dstIndex] << ":" << cur->_dstIndex << ":" << cur->_weight << "]->";
cur = cur->_next;
}
cout << "nullptr" << endl;
}
}
private:
vector<V> _vertexs; // 顶点集合
map<V, size_t> _vIndexMap; // 相应顶点映射的下标
vector<Edge*> _tables; // 存放边集合的指针数组
};
void TestGraph()
{
string a[] = { "张三", "李四", "王五", "赵六" };
Graph<string, int, INT_MAX, true> g1(a, 4);
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.Print();
}
}
// 运行结果
[0]->张三
[1]->李四
[2]->王五
[3]->赵六
张三[0]->[王五:2:200]->[李四:1:100]->nullptr
李四[1]->nullptr
王五[2]->[赵六:3:30]->nullptr
赵六[3]->nullptr3、总结
邻接矩阵 和 邻接表 是 相辅相成 的,各有优缺点,要根据实际情况进行选择,有时候也可以一起使用他们进行搭配!
一般情况下,对于稠密图,我们选择邻接矩阵;对于稀疏图,我们选择邻接表!
下面我们讲解各种算法的时候,采用的是邻接矩阵来实现,因为一般我们在做oj以及实现一些算法的时候,邻接矩阵会用的比较多~
Ⅲ. 图的遍历
1、广度优先遍历(BFS)
广度优先搜索类似于树的层次遍历。从图中的某一顶点出发,遍历每一个顶点时,依次遍历其所有的邻接点,然后再从这些邻接点出发,同样依次访问它们的邻接点。按照此过程,直到图中所有被访问过的顶点的邻接点都被访问到。
最后还需要做的操作就是查看图中是否存在尚未被访问的顶点(这步很容易遗漏),若有,则以该顶点为起始点,重复上述遍历的过程。
一般广度优先遍历我们都会借助 队列 以及一个 visited 数组(用来标记图中顶点是否被访问过) 来辅助完成实现。
🔴 更要注意的是,这里有可能出现的是 非连通图,所以我们最后得遍历一次 visited 数组看看是否都是 true,如果有 false 的说明还没被遍历过,继续执行以上步骤~
下面我们实现的时候用的是邻接矩阵来实现:
// 广度优先遍历
void BFS()
{
// visited数组标记是否访问过节点
vector<bool> visited;
visited.resize(_vertexs.size(), false);
queue<int> qe;
size_t n = _vertexs.size();
for(size_t i = 0; i < n; ++i)
{
if (visited[i] == false)
{
qe.push(i);
visited[i] = true;
while (!qe.empty())
{
int front = qe.front();
qe.pop();
cout << front << ":[" << _vertexs[front] << ']' << endl;
// 遍历该顶点矩阵中的出边,将它们入队,并标记一下表示出现过
for (size_t j = 0; j < n; ++j)
{
if (_matrix[front][j] != MAX_W && visited[j] == false)
{
qe.push(j);
visited[i] = true;
}
}
}
cout << endl;
}
}
}
void TestGraphBFS()
{
string a[] = { "张三", "李四", "王五", "赵六", "周七" };
Graph<string, int, INT_MAX, true> g1(a, sizeof(a) / sizeof(string));
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.Print();
g1.BFS();
}
// 运行结果
[0]->张三
[1]->李四
[2]->王五
[3]->赵六
[4]->周七
0 1 2 3 4
0 * 100 200 * *
1 * * * * *
2 * * * 30 *
3 * * * * *
4 * * * * *
0:[张三]
1:[李四]
2:[王五]
3:[赵六]
4:[周七]2、深度优先遍历(DFS)
深度优先搜索是一个不断 回溯 的过程。
对于图的深度优先搜索,就是对顶点的邻接点的搜索,如下图所示。
最重要的还是那个点,就是我们要用 visited 数组来标记已经访问过的节点,并且还要主要防止我们遍历的是非连通图,我们要对 visited 数组进行检查,看看是否数组中都为 true,若出现 false 的话说明还没有被遍历,则对该顶点进行深度优先遍历~
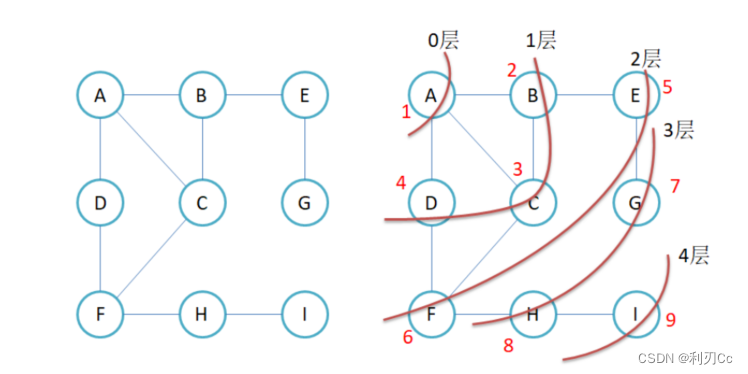
// 深度优先遍历
void DFS()
{
vector<bool> visited(_vertexs.size(), false);
// 遍历所有的顶点,判断是否都是true防止了遗漏一些不连通的子图
for (size_t i = 0; i < _vertexs.size(); ++i)
{
if (visited[i] == false)
{
// 交给子函数去递归解决
_DFS(i, visited);
}
}
cout << endl;
}
void _DFS(size_t srci, vector<bool>& visited)
{
cout << srci << ":[" << _vertexs[srci] << ']' << endl;
// 将该节点的下标标记为访问过
visited[srci] = true;
for (size_t i = 0; i < _vertexs.size(); ++i)
{
if (_matrix[srci][i] != MAX_W && visited[i] == false)
{
_DFS(i, visited);
}
}
}
void TestGraphDFS()
{
string a[] = { "张三", "李四", "王五", "liren", "赵六", "周七"};
Graph<string, int, INT_MAX, true> g1(a, sizeof(a) / sizeof(string));
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.AddEdge("王五", "周七", 30);
g1.DFS();
g1.Print();
}
//运行结果
0:[张三]
1:[李四]
2:[王五]
4:[赵六]
5:[周七]
3:[liren]
[0]->张三
[1]->李四
[2]->王五
[3]->liren
[4]->赵六
[5]->周七
0 1 2 3 4 5
0 * 100 200 * * *
1 * * * * * *
2 * * * * 30 30
3 * * * * * *
4 * * * * * *
5 * * * * * *腾讯云开发者
