fofa联动Python爬虫


起因
最近要用到fofa爬虫,为什么要用爬虫不用api,问就是穷,网上找到一个相关的脚本:Fofa-python-脚本,经过测试发现不能使用。。。尴尬了!!
关于fofa
FOFA是白帽汇推出的一款网络空间搜索引擎,它通过进行网络空间测绘,能够帮助研究人员或者企业迅速进行网络资产匹配,例如进行漏洞影响范围分析、应用分布统计、应用流行度等。 FOFA搜索引擎检索到的内容主要是服务器,数据库,某个网站管理后台,路由器,交换机,公共ip的打印机,网络摄像头,门禁系统,Web服务 …… FOFA这类搜索引擎又有另一个名字:网络空间测绘系统。它们就像是现实生活中的卫星地图那样,一点点勾勒出公共网络空间的样子,每一个网站、每一台公共环境下的服务器……当一个高危漏洞爆发,FOFA系统便能向卫星定位地址一样,通过特征迅速找到全网的脆弱设备。 网站:https://fofa.so/ FOFA不仅提供了在线搜索还提供了FOFA Pro客户端版本
简单来说就是跟国外的shodan,国内的ZoomEye一样是网络空间测绘工具
脚本更新日志
- 2021-4-4对最新版fofa更新做出对应更新,注意:config.py文件中不再是以cookie来进行保证登录,而是使用Authorization,Authorization的值可以登录后F12在https://api.fofa.so/v1/search网址请求头中看到
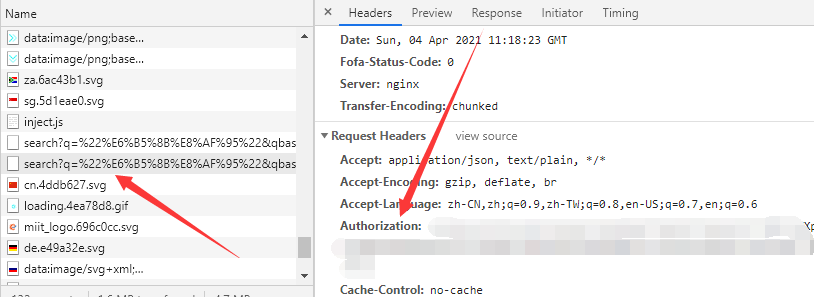
修改地方config.py
经过测试发现不能使用,又开始折腾针对cookie来做文章,经过测试发现
cookie 中fofa_token为会话session,
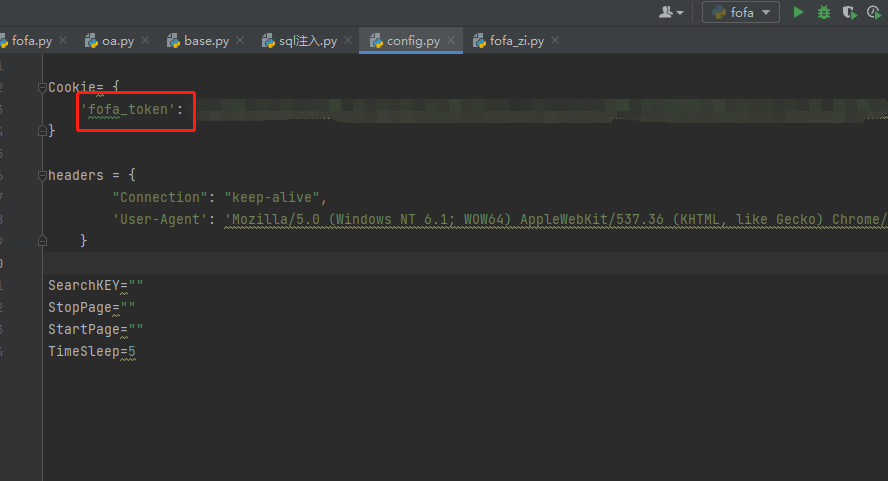
注:fofa_token每天都需要更新一下。希望有大佬可以解决这个问题。
Cookie= {
'fofa_token': 'YOU ARE TOKEN',
}
headers = {
"Connection": "keep-alive",
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0'
}
SearchKEY=""
StopPage=""
StartPage=""
TimeSleep=5在主文件中spider函数做了一些简单修改
def spider():
searchbs64 = quote(str(base64.b64encode(config.SearchKEY.encode()), encoding='utf-8'))
print("爬取页面为:https://fofa.so/result?&qbase64=" + searchbs64)
html = requests.get(url="https://fofa.so/result?&qbase64=" + searchbs64, headers=config.headers).text
tree = etree.HTML(html)
pagenum=tree.xpath('//li[@class="number"]/text()')[-1]
print("该关键字存在页码: "+pagenum)
config.StartPage=input("请输入开始页码:\n")
config.StopPage=input("请输入终止页码: \n")
doc = open("hello_world.txt", "a+")
# 翻页的改动
for i in range(int(config.StartPage),int(config.StopPage)+1):
print("Now write " + str(i) + " page")
# print('https://fofa.so/result?qbase64=' + searchbs64+'&page='+str(i))
rep = requests.get('https://fofa.so/result?qbase64=' + searchbs64+'&page='+str(i), headers=config.headers,cookies=config.Cookie)
# 获取IP、URL地址
tree = etree.HTML(rep.text)
urllist=tree.xpath('//span[@class="aSpan"]//@href')
for j in urllist:
print(j)
doc.write(j+"\n")
if i==int(config.StopPage):
break
time.sleep(config.TimeSleep)
doc.close()
print("OK,Spider is End .")运行结果
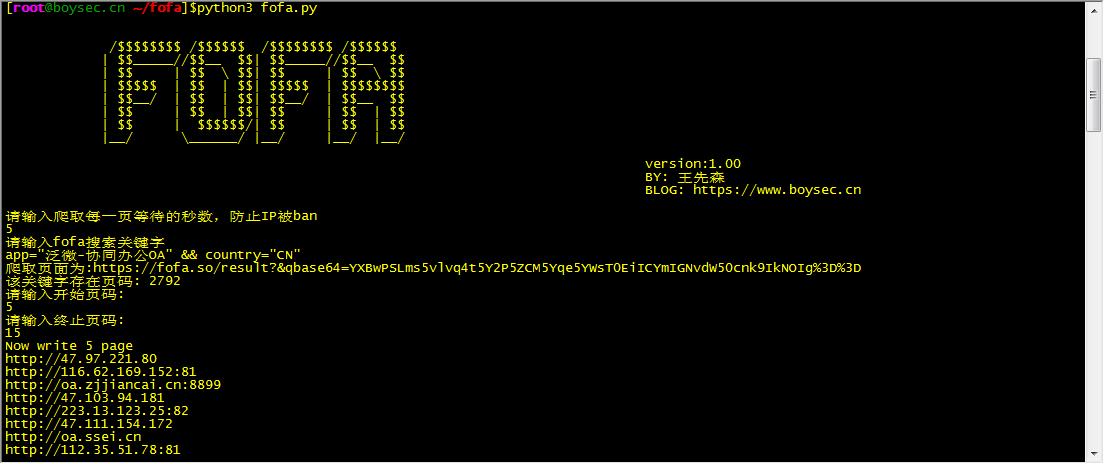
下载地址: https://pan.baidu.com/s/1lkYCzHS6oEiMtdDifGGOmA 提取码:n544
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2021-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
