OpenCV 安卓编程示例:1~6 全

一、准备就绪
在本章中,我将逐步介绍如何开始使用 OpenCV 开发具有视觉感知的 Android 应用。
开源计算机视觉(OpenCV)软件库具有 2500 多种优化算法; 该库包括一整套经典和最先进的计算机视觉和机器学习算法。 它已经存在了十年,并根据伯克利软件发行(BSD)许可证发布,使用户易于使用和修改。
OpenCV 被下载了超过 700 万次,并被 Google,Yahoo,Microsoft,Intel,IBM,Sony 和 Honda 等知名公司使用。 此外,OpenCV 支持多种桌面和移动操作系统,包括 Windows,Linux,Mac OSX,Android 和 iOS。
在本书中,我们将使用适用于 Android 的 OpenCV,它是可在 Android 操作系统上运行的 OpenCV 的一部分。
我将介绍两种安装和准备方案。 首先,如果您要开始全新安装 Android,建议您从 Tegra Android 开发包(TADP)开始。 另一种情况是手动安装运行 OpenCV 的 Android 所需的每个组件。 如果您先前已经安装了 Android 开发环境,则可能会选择此选项。 我们将涵盖以下主题:
- 安装 Tegra Android 开发包
- 手动安装 OpenCV 和 Android 开发环境
- 了解本机开发套件(NDK)的工作方式
- 使用 OpenCV 构建您的第一个 Android 项目
安装 Tegra Android 开发包
NVIDIA 发布了 TADP ,以使 Android 开发环境的准备工作变得无缝。
NVIDIA 已发布 TADP 3.0r4 版本,以支持 Android SDK(23.0.2),NDK(r10c)和 OpenCV for Tegra 2.4.8.2,这是一个常规的 OpenCV4Android SDK,已通过 Tegra 特定的优化进行了扩展。
下载并安装 TADP
要获取 TADP,请访问这个页面并按照步骤成为注册开发者; 它是免费会员。
激活成员身份后,登录并下载与您的操作系统相对应的版本。 NVIDIA 支持以下操作系统:
- Windows 64 位
- Mac OSX
- Ubuntu Linux(32/64 位)
就我而言,我的计算机上装有 Windows 7 64 位,因此从现在开始,所有后续步骤都经过了测试,并且在此操作系统上运行良好。 但是,如果您使用其他操作系统,我预计不会有任何重大变化。
注意
对于 Ubuntu 安装,TADP 将需要您具有root特权,因此请确保您具有。
下载完 TADP 安装程序后,启动它并执行以下步骤:
- 阅读并接受许可协议后,请按照屏幕上的说明进行操作。
- 您将需要选择安装类型。 选择“自定义”安装,然后单击“下一步”按钮:
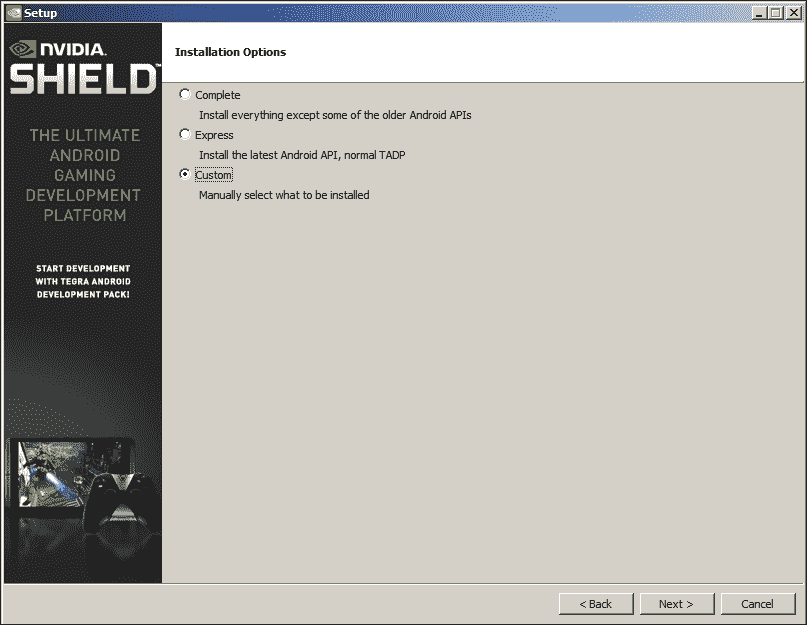
- 如图所示,选择要安装的组件,然后单击“下一步”按钮:
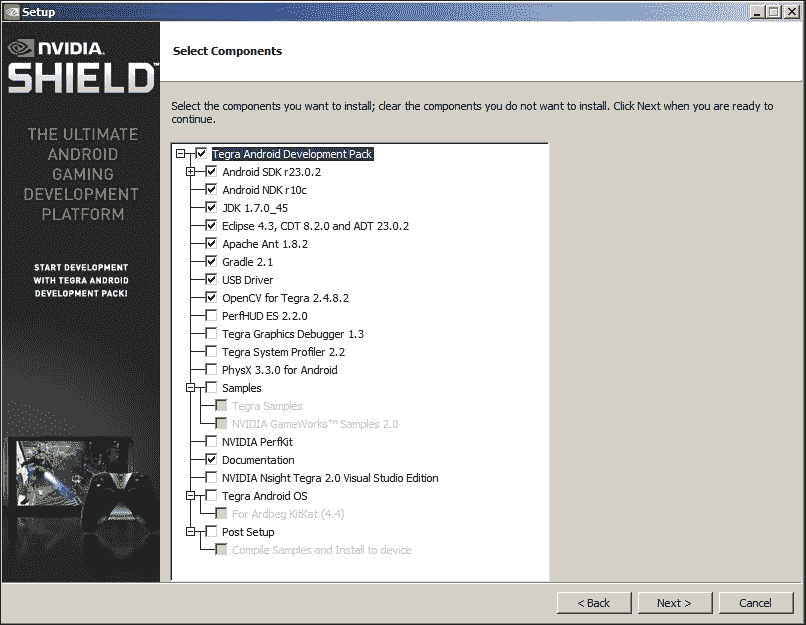
- 您需要命名安装并下载目录。
注意
请注意,如果您以前安装过,则会收到一条警告消息,提示您需要卸载以前的安装。 要卸载先前的安装,请转到先前的安装目录并运行
tadp_uninstall.exe。 有时,卸载程序无法清除所有内容。 在这种情况下,您需要手动删除先前安装目录的内容。 - 现在,您可以安装选定的组件了。 单击
Next按钮。 - 如果您在代理后面,则可以输入代理详细信息; 否则,单击
Next按钮。 - 安装程序将开始下载所有选定的组件。 这可能需要一段时间,具体取决于您的互联网连接。
- 下载完成后,单击“下一步”以开始安装所选组件。 注意 有时,安装程序窗口将不响应。 没关系,几分钟后,安装将以正常方式继续。
- 选择所需的安装后操作,然后单击完成按钮。
TADP 安装后配置
是的,TADP 将为您下载并安装所有内容; 但是,您仍然需要进行一些安装后配置,以确保一切正常。
安装仿真器系统映像
如果您想以该 SDK 平台为目标运行仿真器,则需要为安装的每个 Android SDK 平台安装一个系统映像。
为此,只需遵循以下简单步骤:
- 转到在安装 TADP 时选择的安装目录。
- 打开 SDK 文件夹; 在这种情况下,它是
android-sdk-windows。 - 运行 SDK Manager。
- 对于每个已安装的 Android
X.X,为模拟器选择一个系统映像,例如 ARM EABI V7a 系统映像:
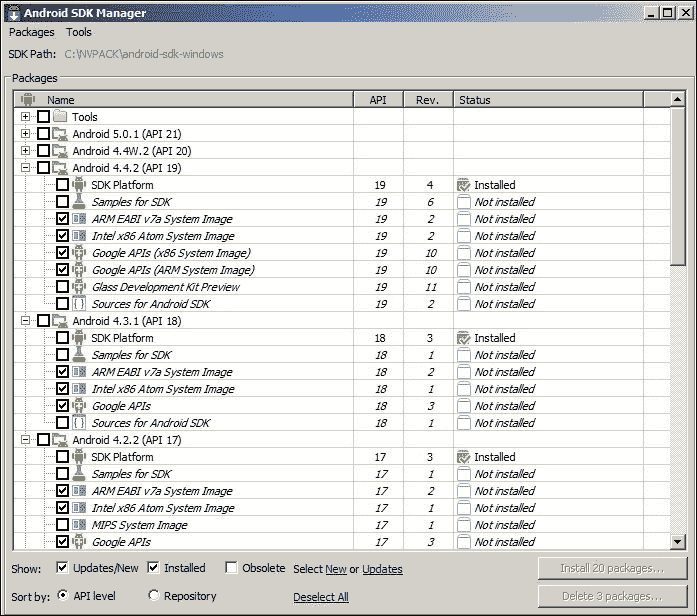
- 单击安装包。
- 阅读并接受所选组件的许可协议。
- 单击安装。
现在,您可以在任何已安装目标的仿真器上测试应用。
配置 Eclipse 以与 NDK 一起使用
您还需要配置 Eclipse 以使其与 NDK 一起运行,以便您可以直接从 Eclipse 构建本机应用:
- 从先前指定的安装目录启动 Eclipse。
- 打开窗口 | 首选项。
- 在左侧窗格中,打开 Android 树。
- 选择标记为 NDK 的树节点。
- 在右窗格中,单击浏览并选择 NDK 目录; 您将在安装目录下找到它。
- 单击
Next。
NDK 验证
由于 OpenCV 库是用 C/C++ 编写的,因此,验证您的环境是否正常运行的第一步是确保您能够运行使用本机代码的 Android 应用:
- 启动 Eclipse。
- 从 NDK 安装目录(在我的情况下为
C:\NVPACK\android-ndk-r10c\),从samples文件夹中导入hello-jni示例项目,就像要导入任何其他 Android 项目一样。 - 右键单击
HelloJni项目。 - 在上下文菜单中,选择 Android 工具 | 添加本机支持。
- 确保将库名称设置为
hello-jni; 默认情况下,应将其命名为此。 - 用您选择的目标启动仿真器。
- 右键单击项目浏览器中的
hello-jni项目。 在上下文菜单中,选择运行为 | Android 应用。
在控制台输出中,应该有.so文件的列表; 这些是 NDK 使用应用二进制接口(ABI)构建的本机共享库,该库确切定义了机器代码的外观。
Android NDK 支持不同的架构。 默认情况下,如果在application.mk文件中指定了.so,则除了 MIPS 和 x86 之外,还将为 ARM EABI 生成.so。 我们将在本章后面讨论这个主题。
如果一切运行顺利,则您的模拟器应具有一个运行如下的应用:

该应用非常简单,是一个很好的检查点,它可以验证您是否可以从 Android 应用调用本机代码。
基本上,您在模拟器屏幕上看到的是从本机代码返回并由 Android 框架在文本视图中显示的字符串。
手动安装 OpenCV 和 Android 开发环境
要选择手动安装 OpenCV 和 Android 开发环境,您的计算机上可能已安装了以下组件:
- Java SE 开发套件 6
- Android Studio
- Android SDK
- Eclipse IDE
- Eclipse 的 ADT 和 CDT 插件
- Android NDK
- OpenCV4Android SDK
您可以按照手动安装步骤进行操作,以确保已准备好并正确配置了所有需要的组件,以便开始使用 OpenCV 开发 Android 应用。
Java SE 开发套件 6
您可以从这个页面下载适用于您的 OS 的 JDK 安装程序。
Android Studio
另一个非常好的选项是 Android Studio。 您可以从这个页面下载 Android Studio。 请注意,Android Studio 与 Android SDK 捆绑在一起,因此如果使用此选项,则无需安装它。 此外,您可以跳过 Eclipse 和 ADT 的安装,并注意从 Android Studio 1.3 开始; 您还将找到对 NDK 的内置支持。
Android SDK
要下载并安装 Android SDK,请按照以下步骤操作:
- 访问这个页面。
- 向下滚动至仅 SDK 工具部分,然后单击 Windows 安装程序链接的
.exe文件。 - 阅读并接受条款和条件后,请单击下载按钮。
- 将安装程序保存在磁盘上,然后单击
.exe文件以启动安装程序,然后按照屏幕上的说明进行操作。 - 记下 SDK 目录,以便以后从命令行引用它。
- 安装完成后,Android SDK 管理器将启动。
- 选择安装 Android SDK 工具,版本 20 或更高版本。
- 对于 Android 的 SDK 平台,请选择 Android 3.0(API 11)或更高版本。 就我而言,我使用了 API 15,建议您这样做。
- 阅读并接受许可协议,然后单击安装。
Eclipse IDE
对于 OpenCV 2.4。x,建议使用 Eclipse 3.7(Indigo)或 Eclipse 4.2(Juno); 您可以从 Eclipse 的官方网站下载您选择的版本。
用于 Eclipse 的 ADT 和 CDT 插件
假设您已经下载了 Eclipse,则可以按照以下步骤下载 Android 开发人员工具(ADT)和 C/C++ 开发工具(CDT)插件:
- 启动 Eclipse,然后导航至帮助 | 安装新软件。
- 单击右上角的添加按钮。
- 在添加存储库对话框中,在名称字段中写入
ADT Plug-in,然后复制并粘贴此 URL,在位置字段中。 - 单击
Next。 - 选中开发人员工具复选框。
- 单击
Next。 - 下一个窗口将显示要下载的工具列表。 只要确保它包含本机支持工具(CDT),然后单击
Next。 - 阅读并接受许可协议,然后单击完成。
- 安装完成后,您将需要重新启动 Eclipse。
Android NDK
按照的要求为 C++ 开发 Android,您需要安装 Android NDK。
注意
并非要在所有情况下都使用 Android NDK。 作为开发人员,您需要在使用本机 API 带来的性能提升与引入的复杂性之间取得平衡。
在我们的情况下,由于OpenCV库是用 C/C++ 编写的,因此我们可能必须使用 NDK。 但是,不应仅仅因为程序员更喜欢用 C/C++ 编写代码而使用 NDK 。
下载 Android NDK
您可以按照以下步骤下载 Android NDK:
- 转到 Android NDK 主页。
- 在下载部分中,选择与您的操作系统相对应的版本。 就我而言,它是 Windows 64 位。
- 阅读并同意条款和条件。
- 单击下载按钮。
安装和配置 Android NDK
下载完成后,您需要按照以下步骤配置 NDK:
导航至 NDK 下载文件夹。
双击下载的文件将其解压缩。
重命名并移动提取的文件夹; 我将ndk文件夹称为<ndk_home>。 现在,您可以使用 NDK 来构建项目了。
如果您希望从命令行进行构建,则需要将<ndk_home>文件夹(在我的情况下为C:/android/android-ndk-r10d)添加到PATH环境变量中。 对于 Windows,请打开 CMD。 输入以下命令,并将ndk目录替换为您的目录:
set PATH=%PATH%;c:/android/android-ndk-r10d要检查 NDK 的配置是否正确,请转到包含项目的目录。 为简单起见,您可以在hello-jni示例项目上进行测试。 您可以在<ndk_home>/samples/下找到它。
通过执行命令cd <your_project_directory>/更改目录。 运行以下命令:
ndk-build如控制台输出所示,扩展名为.so的文件是此项目中使用的 C/C++ 源代码的编译版本:
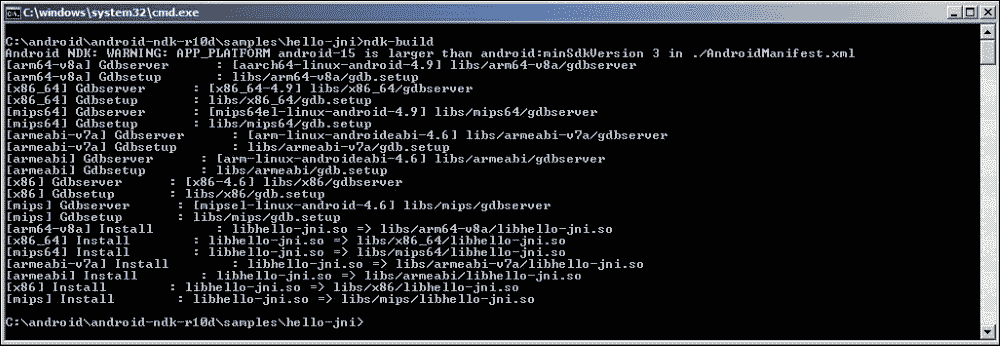
使用 Eclipse 构建本机代码
如果您更喜欢从 Eclipse 构建,这更方便,则需要告诉 Eclipse 在哪里可以找到 NDK,以便可以构建应用:
- 启动 Eclipse 并打开窗口 | 首选项。
- 在左侧窗格中,打开 Android 树。
- 选择 NDK 树节点,然后在右侧窗格中单击浏览,然后选择
<ndk_home>目录。 - 单击
Next。 - 从
<ndk_home>/samples/导入hello-jni示例项目作为 Android 项目。 - 打开项目资源管理器,然后右键单击
hello-jni项目。 - 在上下文菜单中,导航到 Android 工具 | 添加本机支持将此项目转换为 C++ 项目。
- 接受默认的库名称,然后单击完成。
- 生成应用。
在控制台中,您将看到.so文件的列表,这些文件是此项目的已编译 C++ 部分。 不过,如果您从导入的项目中打开任何 C/C++ 文件,您将看到许多突出显示的错误。 您只需要执行一些与 CDT 插件相关的步骤:
- 导航到项目 | 属性。 在左侧窗格中,展开 C/C++ 通用节点。
- 选择路径和符号。
- 在右侧窗格中,选择包括选项卡。
- 单击添加,然后单击文件系统添加以下路径:
- 如果您安装了 NDK r8 或更早版本:
<ndk_home>/platforms/android-9/arch-arm/usr/include<ndk_home>/sources/cxx-stl/gnu-libstdc++/include<ndk_home>/sources/cxx-stl/gnu-libstdc++/libs/armeabi-v7a/include - 如果您安装了 NDK r8b 或更高版本:
<ndk_home> /platforms/android-9/arch-arm/usr/include<ndk_home>/sources/cxx-stl/gnu-libstdc++/4.6/include<ndk_home> /sources/cxx-stl/gnu-libstdc++/4.6/libs/armeabi-v7a/include
- 如果您安装了 NDK r8 或更早版本:
- 单击
Next。 Eclipse 将重建项目,并且应从 Eclipse 中清除所有语法错误。 - 现在,您可以构建项目以将 Java 代码和本机代码打包在一个 APK 中。 要将应用安装在您选择的仿真器上,请使用菜单项运行 | 运行方式为 | Android 应用。
OpenCV4Android SDK
为了能够在您的 Android 设备上使用本机(C/C++)库的 OpenCV 集合,您需要安装 OpenCV4Android SDK,它是 OpenCV 的一部分,可以在 Android 操作系统上运行。
- 首先,转到 OpenCV 下载页面。
- 下载最新可用版本,在撰写本书时为
2.4.10。 - 将压缩文件解压缩到方便的路径,例如
C:\opencv\。 注意 强烈建议使用无空格的路径,以避免ndk-build出现任何问题。
了解 NDK 的工作方式
无论您是使用 TADP 进行全新安装,还是按照手动设置步骤进行操作,在此阶段,您都应该具有开发视觉感知的 Android 应用所需的所有组件。
在继续我们的第一个示例之前,让我们先详细说明 NDK 的工作方式。 熟悉 Android NDK 的基础知识并习惯使用它始终是一个好主意,因为它将成为我们使用 OpenCV 开发 Android 应用的基石。
NDK 概述
如果您决定使用命令提示符编译 Android 应用的本机部分,则必须使用ndk-build工具。 ndk-build工具实际上是一个脚本,它将启动负责以下内容的不同构建脚本:
- 它会自动搜索您的项目,以决定要构建什么
- 搜索完成后,脚本开始生成二进制文件并管理依赖项
- 它将生成的二进制文件复制到您的项目路径
除了ndk-build工具之外,您还应该熟悉其他一些主要组件,其中包括:
Java 和本机调用:Android 应用是用 Java 编写的,一旦源代码被编译,便会转换为字节码,以便 Android OS 在 Dalvik 或 Android 运行时(ART)下运行虚拟机。
注意
请注意,仅在 Dalvik 虚拟机上对执行本机代码的应用进行测试。
使用本机代码中实现的方法时,应使用native关键字。
例如,您可以声明一个将两个数字相乘的函数,并指示编译器它是本机库:
public native double mul(double x, double y);本机共享库:NDK 使用扩展名.so构建这些库。 顾名思义,这些库在运行时是共享和链接的。
本机静态库:NDK 也以扩展名.a来构建这些库; 这类库实际上是在编译时链接的。
Java 本机接口(JNI):在用 Java 编写 Android 应用时,您需要一种方式将调用引导到用 C/C++ 编写的本机库中, JNI 派上用场了。
应用二进制接口(ABI):该接口定义了应用计算机代码的外观,因为您可以在不同的计算机架构上运行应用。 默认情况下,NDK 为 ARM EABI 构建代码。 但是,您也可以选择要为 MIPS 或 x86 构建的。
Android.mk:将此文件视为 Maven 生成脚本或更好的 Makefile,该文件指示ndk-build脚本有关模块的定义及其名称,编译所需的源文件,以及您需要链接的库。 了解如何使用此文件非常重要,我们稍后将返回至更多信息。
Application.mk:创建此文件是可选的,用于列出您的应用所需的模块。 该信息可以包括用于为特定目标架构,工具链和标准库生成机器代码的 ABI。
考虑到这些组件,您可以总结出为 Android 开发本机应用的一般流程,如下所示:
- 确定哪些部分将用 Java 编写,哪些部分将用本机 C/C++ 编写。
- 在 Eclipse 中创建一个 Android 应用。
- 创建一个
Android.mk文件来定义您的模块,列出要编译的本机源代码文件,并枚举链接的库。 - 创建
Application.mk; 这是可选的。 - 将您的
Anrdoid.mk文件复制到项目路径中的jni文件夹下。 - 使用 Eclipse 构建项目。 当我们将 Eclipse 链接到已安装的 NDK 时,
ndk-build工具将编译.so和.a库,您的 Java 代码将被编译为.dex文件,所有内容都将打包在一个 APK 文件中, 准备安装。
NDK 的简单示例
当您开发具有本机支持的 Android 应用时,您需要熟悉使用 NDK 的典型 Android 应用的一般结构。
通常,您的 Android 应用具有以下文件夹结构。 项目root文件夹具有以下子目录:
jni/libs/res/src/AndroidManifest.xmlproject.properties
这里,与 NDK 相关的文件夹如下:
-
jni文件夹将包含应用的本机部分。 换句话说,这是带有 NDK 构建脚本(例如Android.mk和Application.mk)的 C/C++ 源代码,它们是构建本机库所需的。 - 成功构建后,
libs文件夹将包含本机库。 注意 NDK 构建系统需要AndroidManifest.xml和project.properties文件来编译应用的本机部分。 因此,如果缺少这些文件中的任何一个,则需要先编译 Java 代码,然后再编译 C/C++ 代码。
Android.mk
在本节中,我将描述构建文件的语法。 如前所述,Android.mk实际上是 GNU Makefile 片段,构建系统会对其进行解析以了解在项目中构建什么。 该文件的语法允许您定义模块。 模块是以下之一:
- 静态库
- 共享库
- 独立的可执行文件
您已经使用ndk-build来构建hello-jni项目,因此让我们看一下该项目Android.mk文件的内容:
LOCAL_PATH := $(call my-dir)
include $(CLEAR_VARS)
LOCAL_MODULE := hello-jni
LOCAL_SRC_FILES := hello-jni.c
include $(BUILD_SHARED_LIBRARY)现在,让我们一一介绍这些行:
-
LOCAL_PATH := $(call my-dir):这里,脚本定义了一个名为LOCAL_PATH的变量,并通过调用my-dir函数设置其值,该函数返回当前工作目录。 -
include $(CLEAR_VARS):在此行中,脚本包含另一个名为CLEAR_VARS的 GNU Makefile,用于清除所有局部变量-以Local_XXX开头的变量,但LOCAL_PATH除外。 这是必需的,因为构建文件是在单执行执行上下文中解析的,其中所有变量都声明为全局变量。 -
LOCAL_MODULE := hello-jni:在这里,脚本定义了一个名为hello-jni的模块。 必须定义 LOCAL_MODULE变量,并且该变量是唯一的,以标识Android.mk中的每个模块。 注意 构建系统将在您定义的模块中添加lib前缀和.so后缀。 在示例情况下,生成的库将被命名为libhello-jni.so。 -
LOCAL_SRC_FILES := hello-jni.c:顾名思义,您将在一个模块中列出所有需要构建和组装的源文件。 注意 您仅列出源文件,而不列出头文件; 构建系统负责为您计算依赖关系。 -
include $(BUILD_SHARED_LIBRARY):这里包括另一个 GNU Makefile,它将收集您在最后一个include命令之后定义的所有信息,并确定要构建的内容以及如何构建模块。
使用 OpenCV 构建您的第一个 Android 项目
在开发环境启动并运行并且具有适当的 NDK 背景的情况下,我可以开始组装如何在 Android 应用中使用 OpenCV 库的全景图。
适用于 Android 的 OpenCV 支持通过其本地 API 和 Java 包装 API 访问其功能。 对于本机 API,您将使用 Android NDK 定义本机库,并包含您正在使用的 OpenCV 库。 然后,您将使用 Java 本机接口(JNI)从 Java 代码调用本机库。
另一个选择是使用常规的 Java 导入直接在 Java 代码中使用 OpenCV Java 包装器。 将会发生的是,Java 包装器将使用 JNI 将您的调用引导至本机 OpenCV 库。
当然,取决于您选择哪种样式。 但是,您应该理解,使用本机调用可以减少 JNI 开销,但需要更多的编程工作。 另一方面,使用 Java 包装器可能会导致较少的编程工作而导致更多的 JNI 开销。
注意
考虑这种情况:您正在处理视频帧或静止图像,并且在您的算法中,您将调用几个 OpenCV 函数。 在这种情况下,最好编写一个调用所有这些函数的本机库。 在您的 Android 应用中,您只能使用一个 JNI 调用来访问此本机库。
HelloVisionWorld Android 应用
我们将构建我们的第一个 Android 应用,以从相机实时获取预览帧,并使用 OpenCV 的 Java 相机 API 在全屏上显示预览。
在 Eclipse 中创建项目
之后是在 Eclipse 中创建项目的步骤:
- 启动 Eclipse 并创建一个新的工作区。
- 创建一个新的 Android 项目,并将您的应用命名为
HelloVisionWorld。 - 设置最低 SDK 版本。 要使用 OpenCV4Android SDK 进行构建,最低 SDK 版本为 11; 但是,强烈建议使用 API 15 或更高版本。 就我而言,我使用了 API 15。
- 选择目标 SDK。 就我而言,我将其设置为 API 19。 单击
Next。 - 允许 Eclipse 创建新的空白活动,并使用名为
activity_hello_vision的布局将其命名为HelloVisionActivity。 - 将
OpenCV库项目导入到您的工作区中。 导航到文件 | 导入 | 现有的 Android 代码到工作区中。 - 选择 OpenCV4Android SDK 的
root目录。 取消全选示例项目,仅选择OpenCV Library,然后单击Finish:
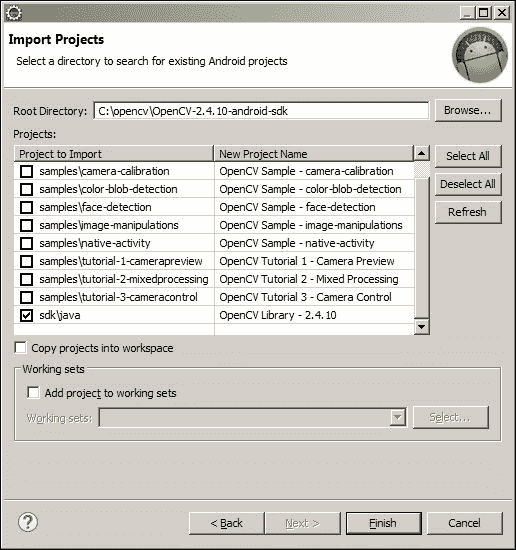
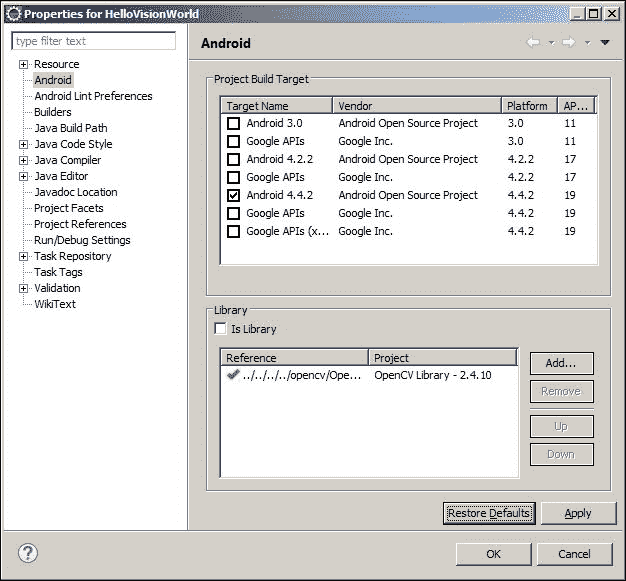
- 从您的 Android 项目中引用 OpenCV 库。 点击项目 | 属性。 从左侧窗格中选择“Android”树节点,然后在右侧窗格中,在“库”部分中单击“添加”,然后单击“确定”:
在 Android Studio 中创建项目
之后是在 Android Studio 中创建项目的步骤:
- 启动 Android Studio。
- 创建一个新的 Android Studio 项目,并将其命名为
HelloVisionWorld,并将公司域设置为app0.com。 - 选择最小 SDK。 要使用 OpenCV4Android SDK 进行构建,最低 SDK 版本为
11。 - 创建一个空白活动并将其命名为
HelloVisionActivity。 - 要将
OpenCV作为依赖项添加到您的项目,请导航至文件 | 新增 | 导入模块和<OpenCV4Android_Directoy>\sdk\java。 然后,单击OK。 此时,取决于从 Android SDK 安装的组件,您可能会遇到一些问题。 Android Studio 将提出快速修复链接来解决此类错误,这应该是一个简单的修复方法。 - 在项目视图中右键单击新创建的应用,然后选择打开模块设置或按
F4。 - 在依赖项选项卡中,按
+按钮,然后选择模块依赖项。 - 选择 OpenCV 库,然后按添加。 现在,您应该能够将 OpenCV 类导入到您的项目中了。
继续前进,无论选择哪种 IDE,您都应该能够按照以下步骤操作:
打开layout文件并对其进行编辑以匹配以下代码。 我们添加了 OpenCV 命名空间,并定义了 Java 摄像机视图布局:
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
xmlns:opencv="http://schemas.android.com/apk/res-auto"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:paddingBottom="@dimen/activity_vertical_margin"
android:paddingLeft="@dimen/activity_horizontal_margin"
android:paddingRight="@dimen/activity_horizontal_margin"
android:paddingTop="@dimen/activity_vertical_margin"
tools:context="com.example.hellovisionworld.HelloVisionActivity" >
<org.opencv.android.JavaCameraView
android:layout_width="fill_parent"
android:layout_height="fill_parent"
android:visibility="gone"
android:id="@+id/HelloVisionView"
opencv:show_fps="true"
opencv:camera_id="any" />
</RelativeLayout>注意
下载示例代码
您可以从这个页面下载从帐户购买的所有 Packt 书籍的示例代码文件。 如果您在其他地方购买了此书,则可以访问这个页面并进行注册,以便将文件直接通过电子邮件发送给您。
由于我们将使用设备相机进行,因此我们需要在AndroidManifest文件中设置一些权限:
</application>
<uses-permission android:name="android.permission.CAMERA"/>
<uses-feature android:name="android.hardware.camera" android:required="false"/>
<uses-feature android:name="android.hardware.camera.autofocus" android:required="false"/>
<uses-feature android:name="android.hardware.camera.front" android:required="false"/>
<uses-feature android:name="android.hardware.camera.front.autofocus" android:required="false"/>在AndroidManifest文件中隐藏标题和系统按钮:
<application
android:icon="@drawable/icon"
android:label="@string/app_name"
android:theme="@android:style/Theme.NoTitleBar.Fullscreen" >我们需要在创建的活动中初始化 OpenCV 库。 为此,我们使用 OpenCV Manager 服务使用异步初始化来访问外部安装在目标系统中的 OpenCV 库。 首先,我们需要在将要使用的仿真器上安装 OpenCV Manager。 为此,请在命令提示符下使用adb install命令:
adb install <OpenCV4Android SDK_Home>\apk\OpenCV_2.4.X_Manager_2.X_<platform>.apk用您的 OpenCV 安装文件夹替换<OpenCV4Android SDK_Home>,用apk文件夹中的可用版本替换apk名称中的X。
对于<platform>,请使用下表根据仿真器上安装的系统映像选择要安装的平台:
硬件平台 | 包名字 |
|---|---|
armeabi-v7a(ARMv7-A +霓虹灯) | OpenCV_2.4.X_Manager_2.X_armv7a-neon.apk |
armeabi(ARMv5,ARMv6) | OpenCV_2.4.X_Manager_2.X_armeabi.apk |
英特尔 x86 | OpenCV_2.4.X_Manager_2.X_x86.apk |
MIPS | OpenCV_2.4.X_Manager_2.X_mips.apk |
注意
在真实设备上测试应用时,将显示一条消息,要求您从 Google Play 下载 OpenCV 管理器,因此请单击是并检查其支持的 OpenCV 版本,以便您可以通过异步初始化来加载它。
在Activity中,定义以下内容并相应地修复导入:
//A Tag to filter the log messages
private static final String TAG = "Example::HelloVisionWorld::Activity";
//A class used to implement the interaction between OpenCV and the //device camera.
private CameraBridgeViewBase mOpenCvCameraView;
//This is the callback object used when we initialize the OpenCV //library asynchronously
private BaseLoaderCallback mLoaderCallback = new BaseLoaderCallback(this) {
@Override
//This is the callback method called once the OpenCV //manager is connected
public void onManagerConnected(int status) {
switch (status) {
//Once the OpenCV manager is successfully connected we can enable the camera interaction with the defined OpenCV camera view
case LoaderCallbackInterface.SUCCESS:
{
Log.i(TAG, "OpenCV loaded successfully");
mOpenCvCameraView.enableView();
} break;
default:
{
super.onManagerConnected(status);
} break;
}
}
};更新onResume活动回调方法以加载 OpenCV 库并相应地修复导入:
@Override
public void onResume(){
super.onResume();
//Call the async initialization and pass the callback object we //created later, and chose which version of OpenCV library to //load. Just make sure that the OpenCV manager you installed //supports the version you are trying to load.
OpenCVLoader.initAsync(OpenCVLoader.OPENCV_VERSION_2_4_10, this, mLoaderCallback);
}您的活动需要实现CvCameraViewListener2,才能从 OpenCV 摄像机视图接收摄像机帧:
public class HelloVisionActivity extends Activity implements CvCameraViewListener2相应地修复导入错误,并在您的活动中插入未实现的方法。
在onCreate活动回调方法中,我们需要将 OpenCV 摄像机视图设置为可见,并且将您的活动注册为将处理摄像机帧的回调对象:
@Override
protected void onCreate(Bundle savedInstanceState) {
Log.i(TAG, "called onCreate");
super.onCreate(savedInstanceState);
getWindow().addFlags(WindowManager.LayoutParams.FLAG_KEEP_SCREEN_ON);
setContentView(R.layout.activity_hello_vision);
mOpenCvCameraView = (CameraBridgeViewBase) findViewById(R.id.HelloVisionView);
//Set the view as visible
mOpenCvCameraView.setVisibility(SurfaceView.VISIBLE);
//Register your activity as the callback object to handle //camera frames
mOpenCvCameraView.setCvCameraViewListener(this);
}最后一步是接收摄像机帧。 为此,请更改onCameraFrame回调方法的实现:
```java
public Mat onCameraFrame(CvCameraViewFrame inputFrame) {
//We're returning the colored frame as is to be rendered on //thescreen.
return inputFrame.rgba();
}
```- 现在,您可以在模拟器或真实设备上构建和安装应用了。
- 这是在仿真相机上运行的应用:
总结
到目前为止,您应该已经开发并测试了您的第一个可感知视觉的 Android 应用。 在本章中,您学习了如何使用 TADP 通过 OpenCV 设置 Android 开发环境,或者通过手动方案更新现有环境。
此外,您已经了解了 NDK 的基础知识及其工作方式。 最后,您已经了解了如何使用 OpenCV 摄像机视图捕获摄像机帧并将其显示在设备屏幕上。 此示例将成为我们实现更多有趣构想的基础。
二、应用 1-建立自己的暗室
在本章中,您将学习如何在 OpenCV 中存储和表示图像,以及如何利用这种表示来实现有趣的算法,这些算法将增强图像的外观。
我们将首先解释数字图像表示和不同的色彩空间,以探索 OpenCV 中重要的Mat类。
然后,我们将逐步执行从手机图库加载图像并将其显示在设备屏幕上的操作,而不管图像分辨率如何。
最后,您将了解图像直方图,以及如何计算和使用它们来增强图像(无论是黑白图像还是彩色图像)。
我们将在本章介绍以下主题:
- 数码图像
- 处理手机中存储的图像
- 计算图像直方图
- 增强图像对比度
数码图像
无论我们在哪里,都可以在我们周围找到图片; 因此,如果我们想自动理解,处理和分析这些图像,那么了解图像的表示方式以及图像的颜色映射是非常重要的。
色彩空间
我们生活在一个连续的世界中,因此要在离散的数字传感器中捕获场景,就必须进行离散的空间(布局)和强度(颜色信息)映射,以便将真实世界的数据存储在数字图像中 。
二维数字图像D(i, j)从左上开始代表在由行号i和列号j表示的像素处的传感器响应值,角为i = j = 0。
为了表示颜色,数字图像通常包含一个或多个通道来存储每个像素的强度值(颜色)。 使用最广泛的颜色表示法是单通道图像,也称为灰度图像,其中根据像素的强度值为每个像素分配灰色阴影:零是黑色,最大强度是白色。
如果使用从 0 到2^8 - 1的值的无符号字符表示色深信息,则每个像素可以存储从 0(黑色)到 255(白色)的强度值。
除了灰度颜色映射外,还有真彩色映射,其中颜色由三个通道而不是一个通道表示,并且像素值变为三个元素(红色,绿色和蓝色)的元组。 在这种情况下,颜色表示为三个通道值的线性组合,并且图像被视为三个二维平面。
注意
有时,添加了名为 Alpha 的第四个通道,用于表示颜色透明度。 在这种情况下,图像将被视为四个二维平面。
与 RGB 表示相比,要考虑的色彩空间与人类对颜色的理解和感知更相关。 它是色相,饱和度和值(HSV)色彩空间。
每个颜色尺寸可以理解如下:
- 色相(
H):它是颜色本身,红色,蓝色或绿色。 - 饱和度(
S):它测量颜色的纯度; 例如,它是暗红色还是暗红色? 可以想象一下,多少白色遮住了颜色。 - 值(
V):它是颜色的亮度,也称为亮度。
最后要考虑的图像类型是二进制图像。 它是像素的二维数组。 但是,每个像素只能存储零或一的值。 这种类型或表示形式对于解决视觉问题(例如边缘检测)很重要。
具有像素的二维数组或三个二维平面来表示图像,其中每个单元或像素在 RGB 颜色空间的情况下包含颜色的强度值,在情况下包含色相,饱和度和值 HSV 色彩空间的大小,将图像缩小为数值矩阵。 由于 OpenCV 的主要重点是处理和操纵图像,因此您需要了解的第一件事是 OpenCV 如何存储和处理图像。
Mat类
在使用 OpenCV 开发视觉感知应用时,将使用的最重要的基本数据结构是Mat类。
Mat类表示n维密集数字单通道或多通道数组。 基本上,如果您使用Mat类表示灰度图像,则Mat对象将是存储像素强度值的二维数组(具有一个通道)。 如果使用Mat类存储全彩色图像,则Mat对象将是具有三个通道的二维数组(一个通道用于红色强度,一个通道用于绿色,一个通道用于蓝色),并且同样适用 HSV 颜色空间。
与任何 Java 类一样,Mat类具有构造器列表,并且在大多数情况下,默认构造器就足够了。 但是,在某些其他情况下,您可能希望使用特定的大小,类型和通道数来初始化Mat对象。
在这种情况下,可以使用以下构造器:
int numRow=5;
int numCol=5;
int type=org.opencv.core.CvType.CV_8UC1;
Mat myMatrix=newMat(numRow,numCol,type);该构造器采用三个整数参数:
int Rows:新矩阵行的数量int Cols:新矩阵列的数量int type:新矩阵类型
注意
为了指定Mat类存储的类型以及有多少个通道,OpenCV 为您提供了CvType类和static int字段,并具有以下命名约定:
CV_[数据类型大小,8 | 16 | 32 | 64][有符号,无符号整数或浮点数,S | U | F][通道数,C1 | C2 | C3 | C4]例如,您将类型参数指定为org.opencv.core.CvType.CV_8UC1; 这意味着矩阵将通过一个通道保存 8 位无符号字符的颜色强度。 换句话说,此矩阵将存储强度为 0(黑色)到 255(白色)的灰度图像。
基本Mat操作
除了了解数字图像在 OpenCV 库中的表示方式之外,您还需要熟悉可以在Mat对象上执行的一些基本操作。
您可以执行的最基本操作是像素级访问,以检索像素值,无论您的色彩空间是灰度级还是全 RGB。 假设您具有第 1 章,“就绪”的应用,并且已启动并运行,您可以回想起在onCameraFrame()回调方法中,我们正在使用inputFrame.rgba()方法检索全彩色相机帧。
使用相机帧,我们可以使用以下代码访问像素值:
@Override
public Mat onCameraFrame(CvCameraViewFrameinputFrame) {
Mat cameraFram=inputFrame.rgba();
double [] pixelValue=cameraFram.get(0, 0);
double redChannelValue=pixelValue[0];
double greenChannelValue=pixelValue[1];
double blueChannelValue=pixelValue[2];
Log.i(TAG, "red channel value: "+redChannelValue);
Log.i(TAG, "green channel value: "+greenChannelValue);
Log.i(TAG, "blue channel value: "+blueChannelValue);
return inputFrame.rgba();
}让我们浏览重要的几行,其余的实际上很简单:
double [] pixelValue=cameraFram.get(0, 0);在这一行中,我们调用get(0,0)函数并将其传递给行和列索引; 在这种情况下,它是左上方的像素。
请注意,get()方法返回一个双精度数组,因为Mat对象最多可以容纳四个通道。
在我们的示例中,它是全彩色图像,因此除了一个透明度通道 Alpha(a)外,每个像素的红色(r),绿色(g)和蓝色(b)颜色通道的强度都将不同,因此该方法的名称为rgba()。
您可以使用数组索引运算符[]独立访问每个通道强度,因此对于红色,绿色和蓝色强度,分别使用0,1和2:
double redChannelValue=pixelValue[0];
double greenChannelValue=pixelValue[1];
double blueChannelValue=pixelValue[2];下表列出了您需要熟悉的基本Mat类操作:
功能 | 代码样例 |
|---|---|
检索通道数 | Mat myImage; //declared and initialized |
int numberOfChannels=myImage.channels(); | |
制作包括矩阵数据在内的Mat对象的深层副本 | Mat newMat=existingMat.clone(); |
检索矩阵列数 | 第一种方法:Mat myImage; //declared and initialized |
int colsNum=myImage.cols(); | |
第二种方法:int colsNum=myImage.width(); | |
第三种方法://And yes, it is a public instance variable. | |
int colsNum=myImage.size().width; | |
检索矩阵行数 | 第一种方法:Mat myImage; //declared and initialized |
int rowsNum=myImage.rows(); | |
第二种方法:int rowsNum=myImage.height(); | |
第三种方法://And yes, it is a public instance variable. | |
int rowsNum=myImage.size().height; | |
要检索矩阵元素深度(每个通道的类型): | Mat myImage; //declared and initialized |
int depth=myImage.depth() | |
CV_8U:8 位无符号整数(0 到 255) | |
CV_8S:8 位有符号整数(-128 至 127) | |
CV_16U:16 位无符号整数(0 到 65,535) | |
CV_16S:16 位有符号整数(-32,768 至 32,767) | |
CV_32S:32 位有符号整数(-2,147,483,648 至 2,147,483,647) | |
CV_32F:32 位浮点数 | |
CV_64F:64 位浮点数 | |
检索矩阵元素的总数(图像中的像素数) | Mat myImage; //declared and initialized |
long numberOfPixels=myImage.total() |
处理手机中存储的图像
在本部分中,您将学习如何从手机上加载图像并对其应用一些有趣的图像处理算法,例如对比度增强,平滑(消除图像中的噪声)以及应用一些过滤器。
将图像加载到Mat对象
首先创建一个新的 Android 项目,让我们开始。 正如您在上一章中看到的一样,为了开始使用 OpenCV 算法,您需要将 OpenCV 库添加到您的项目中:
- 启动 Eclipse。
- 创建一个新的 Android 项目应用; 我们命名为
DarkRoom。 - 选择包名称。 在此示例中,我将其选择为
com.example.chapter2.darkroom。 - 将所需的最低 SDK 设置为 API 11(Android 3.0)以上。 就我而言,强烈建议将其选择为 API 16(Android 4.1)。 对于目标 SDK,应该选择 API 19,因为如果使用的目标 SDK 高于 19,则在加载 OpenCV 库时会出现问题。
- 单击
Next。 - 让 Eclipse 为您创建一个空白活动并将其命名为
IODarkRoom。 - 完成创建项目。
- 将 OpenCV 库项目导入到您的工作区文件中,菜单 | 导入 | 现有的 Android 代码到工作区。
- 单击浏览并转到您的 OpenCV 安装主目录。
- 选择 OpenCV 主目录,然后单击
Next。 - 取消选择所有项目,然后仅选择 OpenCV 库项目。
- 点击完成。
- 现在,您需要将新创建的 Android 项目与刚刚导入的 OpenCV 库链接,因此,在新项目上,右键单击属性。
- 在左窗格中,选择
Android树节点,然后在右窗格中,单击添加。 - 选择 OpenCV 库,然后单击
Next。
UI 定义
在此项目中,您将加载手机中存储的图像,将其转换为位图图像,并在图像视图中显示。
让我们从设置应用活动的布局开始:
<LinearLayoutxmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="fill_parent"
android:layout_height="fill_parent"
android:orientation="horizontal">
<ImageView
android:id="@+id/IODarkRoomImageView"
android:layout_width="fill_parent"
android:layout_height="fill_parent"
android:src="@drawable/ic_launcher"
android:layout_marginLeft="0dp"
android:layout_marginTop="0dp"
android:scaleType="fitXY"/>
</LinearLayout>这是带有图像视图的简单线性布局。 下一步是设置一些所需的权限。 万一您要从 SD 卡加载图像,则需要设置相应的权限,以便 Android 允许您的应用从外部存储设备进行读取和写入。
在清单文件中,添加以下行:
<uses-permissionandroid:name="android.permission.WRITE_EXTERNAL_STORAGE"/>这是写权限; 但是,您的应用也被隐式授予读取权限,因为它的限制较少。
现在,让我们继续进行应用和活动的定义:
<application
android:allowBackup="true"
android:icon="@drawable/ic_launcher"
android:label="@string/app_name"
android:theme="@style/AppTheme">
<activity
android:name=".IODarkRoom"
android:label="@string/app_name"
android:screenOrientation="portrait">
<intent-filter>
<actionandroid:name="android.intent.action.MAIN"/>
<categoryandroid:name="android.intent.category.LAUNCHER"/>
</intent-filter>
</activity>
</application>这是一个非常简单的定义; 但是,在不失一般性的前提下,我将活动的方向限制为纵向,这意味着您的活动将不支持横向模式。 这将把重点放在图像处理上,而不是处理不同的活动模式。 但是,我建议您在精读本章内容之后,将该应用扩展为也支持横向定位,因为它将为您带来良好的动手经验。
对于应用中将支持的每个操作,我们将需要一个菜单项。 我们的第一个动作是在手机上打开图库,以选择特定的图像,为此,您需要在文件中添加以下菜单项:
res/menu/iodark_room.xml
<item
android:id="@+id/action_openGallary"
android:orderInCategory="100"
android:showAsAction="never"
android:title="@string/action_OpenGallary"/>将相应的字符串定义添加到res/values/strings.xml:
<stringname="action_OpenGallary">Open Gallary</string>我们已经完成了针对应用这一部分的 UI 定义,因此让我们继续其后的代码。
使用 OpenCV 读取图像
第一步是使用 OpenCV 管理器服务来异步加载 OpenCV 库,以减少应用的内存占用。 为此,在将要使用 OpenCV 算法的每个活动中都需要具有以下样板代码:
private BaseLoaderCallback mLoaderCallback = newBaseLoaderCallback(this) {
@Override
public void onManagerConnected(int status) {
switch (status) {
case LoaderCallbackInterface.SUCCESS:
{
Log.i(TAG, "OpenCV loaded successfully");
} break;
default:
{
super.onManagerConnected(status);
} break;
}
}
};
@Override
public void onResume()
{
super.onResume();
OpenCVLoader.initAsync(OpenCVLoader.OPENCV_VERSION_2_4_8, this, mLoaderCallback);
}下一步是处理用户对我们之前定义的菜单项的单击:
private static final int SELECT_PICTURE = 1;
private String selectedImagePath;
@Override
public boolean onOptionsItemSelected(MenuItem item) {
// Handle action bar item clicks here. The action bar will
// automatically handle clicks on the Home/Up button, so long
// as you specify a parent activity in AndroidManifest.xml.
int id = item.getItemId();
if (id == R.id.action_openGallary) {
Intent intent = newIntent();
intent.setType("https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-android-prog-example/img/*");
intent.setAction(Intent.ACTION_GET_CONTENT);
startActivityForResult(Intent.createChooser(intent,"Select Picture"), SELECT_PICTURE);
return true;
}
return super.onOptionsItemSelected(item);
}用户选择要从图库中加载的图像后,我们将执行加载并将其显示在活动结果回调方法中:
public void onActivityResult(int requestCode, int resultCode, Intent data) {
if (resultCode == RESULT_OK) {
if (requestCode == SELECT_PICTURE) {
Uri selectedImageUri = data.getData();
selectedImagePath = getPath(selectedImageUri);
Log.i(TAG, "selectedImagePath: " + selectedImagePath);
loadImage(selectedImagePath);
displayImage(sampledImage);
}
}
}在确保打开的活动返回了所需的结果(在本例中为图像 URI)之后,我们调用帮助程序方法getPath()来检索加载路径所需的格式的图像路径。 使用 OpenCV 的图像:
private String getPath(Uri uri) {
// just some safety built in
if(uri == null ) {
return null;
}
// try to retrieve the image from the media store first
// this will only work for images selected from gallery
String[] projection = { MediaStore.Images.Media.DATA };
Cursor cursor = getContentResolver().query(uri, projection, null, null, null);
if(cursor != null ){
int column_index = cursor.getColumnIndexOrThrow(MediaStore.Images.Media.DATA);
cursor.moveToFirst();
return cursor.getString(column_index);
}
return uri.getPath();
}准备好路径后,我们将调用loadImage()方法:
private void loadImage(String path)
{
originalImage = Highgui.imread(path);
Mat rgbImage=new Mat();
Imgproc.cvtColor(originalImage, rgbImage, Imgproc.COLOR_BGR2RGB);
Display display = getWindowManager().getDefaultDisplay();
//This is "android graphics Point" class
Point size = new Point();
display.getSize(size);
int width = size.x;
int height = size.y;
sampledImage=new Mat();
double downSampleRatio= calculateSubSampleSize(rgbImage,width,height);
Imgproc.resize(rgbImage, sampledImage, new Size(),downSampleRatio,downSampleRatio,Imgproc.INTER_AREA);
try {
ExifInterface exif = new ExifInterface(selectedImagePath);
int orientation = exif.getAttributeInt(ExifInterface.TAG_ORIENTATION, 1);
switch (orientation)
{
case ExifInterface.ORIENTATION_ROTATE_90:
//get the mirrored image
sampledImage=sampledImage.t();
//flip on the y-axis
Core.flip(sampledImage, sampledImage, 1);
break;
case ExifInterface.ORIENTATION_ROTATE_270:
//get up side down image
sampledImage=sampledImage.t();
//Flip on the x-axis
Core.flip(sampledImage, sampledImage, 0);
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}让我们逐步看一下代码:
originalImage = Highgui.imread(path);此方法从给定路径读取图像并返回它。 它是Highgui类中的静态成员。
注意
如果要加载彩色图像,了解彩色通道的顺序非常重要。 在imread()的情况下,解码的图像将具有按 B,G,R 顺序存储的通道。
现在,让我们看看以下代码片段:
Mat rgbImage=new Mat();
Imgproc.cvtColor(originalImage, rgbImage, Imgproc.COLOR_BGR2RGB);为了将图像加载为 RGB 位图,我们首先需要将解码后的图像从颜色空间 B,G,R 转换为颜色空间 R,G,B。
首先,我们实例化一个空的Mat对象rgbImage,然后使用Imgproc.cvtColor()方法执行色彩空间映射。 该方法采用三个参数:源图像,目标图像和映射代码。 幸运的是,OpenCV 支持 150 多种映射,在我们的情况下,我们需要 BGR 到 RGB 映射。 现在,让我们看看以下代码片段:
Display display = getWindowManager().getDefaultDisplay();
Point size = new Point();
display.getSize(size);
int width = size.x;
int height = size.y;
double downSampleRatio= calculateSubSampleSize(rgbImage,width,height);由于内存限制,以原始分辨率显示图像会非常浪费,有时甚至是不可能的。
例如,如果您使用手机的 8 百万像素相机拍摄了图像,则假设 1 字节的色深,彩色图像的存储成本为8 x 3(RGB) = 24 MB。
为解决此问题,建议将图像调整大小(缩小采样)至手机的显示分辨率。 为此,我们首先获取手机的显示分辨率,然后使用calculateSubSampleSize()辅助方法计算下采样比率:
private static double calculateSubSampleSize(Mat srcImage, int reqWidth, int reqHeight) {
// Raw height and width of image
final int height = srcImage.height();
final int width = srcImage.width();
double inSampleSize = 1;
if (height > reqHeight || width > reqWidth) {
// Calculate ratios of requested height and width to the raw
//height and width
final double heightRatio = (double) reqHeight / (double) height;
final double widthRatio = (double) reqWidth / (double) width;
// Choose the smallest ratio as inSampleSize value, this will
//guarantee final image with both dimensions larger than or
//equal to the requested height and width.
inSampleSize = heightRatio<widthRatio ? heightRatio :widthRatio;
}
return inSampleSize;
}calculateSubSampleSize()方法采用三个参数:源图像,所需的宽度和所需的高度,然后计算下采样率。 现在,让我们看看以下代码片段:
sampledImage=new Mat();
Imgproc.resize(rgbImage, sampledImage, new Size(),downSampleRatio,downSampleRatio,Imgproc.INTER_AREA);现在,我们准备调整加载的图像的大小以适合设备屏幕。 首先,我们创建一个空的Mat对象sampledImage,以保存调整大小后的图像。 然后,我们将其传递给Imgproc.resize():
- 源
Mat对象,我们需要调整其大小 - 目标
Mat对象 - 新图像的大小; 在我们的例子中,一个新的空
Size对象,因为我们将发送降采样率 - X 方向上的下采样率的两倍(宽度)
- Y 方向下采样率的两倍(高度)
- 插值方法的整数; 默认值为
INTER_LINEAR,它对应于线性插值
这里需要插值,因为我们将更改图像的大小(放大或缩小),并且我们希望从源图像到目标图像的映射尽可能平滑。
如果我们缩小尺寸,插值将决定目标图像像素的值在源图像的两个像素之间时是什么。 如果我们正在扩大尺寸,它还将计算目标图像中新像素的值,而源图像中没有相应像素。
在这两种情况下,OpenCV 都有多个选项来计算此类像素的值。 默认的INTER_LINEAR方法通过根据源像素与目标像素的接近程度对2 x 2周围源像素的值进行线性加权,来计算目标像素值。 或者,INTER_NEAREST从源图像中最接近的像素获取目标像素的值。 INTER_AREA选项实际上将目标像素放在源像素上,然后平均覆盖的像素值。 最后,我们可以选择在源图像的4×4周围像素之间拟合三次样条,然后从拟合的样条中读取相应的目标值; 这是选择INTER_CUBIC内插方法的结果。
注意
要缩小图像,通常在INTER_AREA插值下看起来最好,而要放大图像,通常在INTER_CUBIC(慢)或INTER_LINEAR(更快,但仍然看起来不错)时看起来最好。
try {
ExifInterface exif = new ExifInterface(selectedImagePath);
int orientation = exif.getAttributeInt(ExifInterface.TAG_ORIENTATION, 1);
switch (orientation)
{
case ExifInterface.ORIENTATION_ROTATE_90:
//get the mirrored image
sampledImage=sampledImage.t();
//flip on the y-axis
Core.flip(sampledImage, sampledImage, 1);
break;
case ExifInterface.ORIENTATION_ROTATE_270:
//get upside down image
sampledImage=sampledImage.t();
//Flip on the x-axis
Core.flip(sampledImage, sampledImage, 0);
break;
}
} catch (IOException e) {
e.printStackTrace();
}现在,我们需要来处理图像方向,并且由于该活动仅在纵向模式下有效,因此我们将以 90 或 270 度的旋转度处理图像。
在旋转 90 度的情况下,这意味着您将手机置于纵向时拍摄了图像; 我们通过调用t()方法将图像逆时针旋转 90 度,以转置Mat对象。
转置的结果是原始图像的镜像版本,因此我们需要执行另一步骤以通过调用Core.flip()并将其传递到源图像和目标图像并调用翻转代码来指定如何沿垂直轴翻转图像; 0表示围绕 x 轴翻转,正值(例如1)表示围绕 y 轴翻转,负值(例如-1)表示围绕两个轴翻转。
对于 270 度旋转情况,这意味着您将手机倒置地拍照。 我们遵循相同的算法,对图像进行转置然后翻转。 但是,在对图像进行转置后,它将是围绕水平方向的镜像版本,因此我们将0与0翻转代码一起调用。
现在,我们准备使用图像视图组件显示图像:
private void displayImage(Mat image)
{
// create a bitMap
Bitmap bitMap = Bitmap.createBitmap(image.cols(), image.rows(),Bitmap.Config.RGB_565);
// convert to bitmap:
Utils.matToBitmap(image, bitMap);
// find the imageview and draw it!
ImageView iv = (ImageView) findViewById(R.id.IODarkRoomImageView);
iv.setImageBitmap(bitMap);
}首先,我们创建一个位图对象,其颜色通道的顺序与加载的图像颜色通道的顺序 RGB 相匹配。 然后,我们使用Utils.matToBitmap()将Mat对象转换为位图对象。 最后,我们使用新创建的位图对象设置图像视图位图。
计算图像直方图
我们离了解图像内容只有一步,而基本的图像分析技术之一就是计算图像直方图。
什么是直方图?
直方图是用于给定图像强度值分布的整体图。 如前所述,在 x 轴上,绘图将具有0至255范围内的值,具体取决于图像深度,而 y 轴将代表相应强度值的出现次数。
一旦计算并显示图像的直方图,您就可以轻松获得有关图像对比度,强度分布等的一些见解。 实际上,如果将直方图归一化,使其总和为 1,则可以将直方图视为概率密度函数,并回答诸如给定强度值出现在图像上的概率是多少的问题,答案就是 y 以该强度值读取轴。 在下图中,您可以看到强度为 50 的像素出现在图像的左侧 5,000 次:
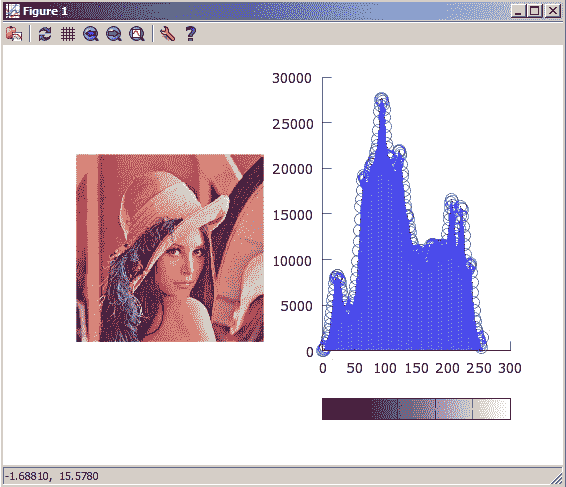
了解直方图的组成部分
在我们开始学习并开始计算直方图之前,我们需要了解一些组件和术语以计算直方图:
- 直方图的箱子:如前所述,直方图的 x 轴表示每个像素可以存储的强度值。 例如,如果要显示强度从 0 到 255 的直方图,则将需要 256 个箱子来保存每个强度值的出现次数。 但是,通常情况并非如此,因为这被认为是非常精细的直方图,并且结果可能不会提供很多信息。 要解决此问题,您可以将直方图划分为箱子,每个箱子都具有一定范围的强度。 对于我们的示例,从 0 到 255,我们可以有 25 个箱子,每个箱子将容纳 10 个连续的强度值的值,从 0 到 9,从 10 到 19,依此类推。 但是,如果直方图仍然不是很具有代表性,则可以减少箱的数量,以增加每个箱中强度值的范围。
- 直方图尺寸:在我们的示例中,尺寸数量为 1,因为在灰度图像的情况下,对于一个通道,我们将只考虑每个像素的强度值;在灰度图像的情况下,将考虑单个色彩通道。 全彩色图像。
- 直方图范围:这是要测量的值的极限。 在我们的示例中,强度的范围是 0 到 255,因此我们要测量的值的范围将是
(0, 255),即所有强度。
现在,我们准备好来展示如何使用 OpenCV 库计算图像的直方图。
UI 定义
我们将继续在上一节中开始的同一应用上构建。 所做的更改是在菜单文件中添加了另一个菜单项,以触发直方图计算。
转到res/menu/iodark_room.xml文件并打开它以包含以下菜单项:
<item
android:id="@+id/action_Hist"
android:orderInCategory="101"
android:showAsAction="never"
android:title="@string/action_Hist">
</item>就 UI 更改而言就是这样。
计算图像直方图
在IODarkRoom 活动中,我们需要按显示直方图菜单项来处理用户。
如下编辑onOptionesItemSelected()方法:
@Override
public boolean onOptionsItemSelected(MenuItem item) {
// Handle action bar item clicks here. The action bar will
// automatically handle clicks on the Home/Up button, so long
// as you specify a parent activity in AndroidManifest.xml.
int id = item.getItemId();
if (id == R.id.action_openGallary) {
Intent intent = newIntent();
intent.setType("https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-android-prog-example/img/*");
intent.setAction(Intent.ACTION_GET_CONTENT);
startActivityForResult(Intent.createChooser(intent,"Select Picture"), SELECT_PICTURE);
return true;
}
else if (id == R.id.action_Hist) {
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat histImage=new Mat();
sampledImage.copyTo(histImage);
calcHist(histImage);
displayImage(histImage);
return true;
}
return super.onOptionsItemSelected(item);
}请注意,如果按下了显示直方图菜单项,我们首先检查用户是否已加载图像,如果用户未加载,则显示一条友好消息,然后将其返回。
现在是直方图部分,如下所示:
Mat histImage=new Mat();
sampledImage.copyTo(histImage);
calcHist(histImage);
displayImage(histImage);
return true;我们首先制作用户加载的缩小图像的副本。 这是必需的,因为我们将更改图像以显示直方图,因此我们需要获得原始副本。 获得副本后,我们将调用calcHist()并将其传递给新图像:
private void calcHist(Mat image)
{
int mHistSizeNum = 25;
MatOfInt mHistSize = new MatOfInt(mHistSizeNum);
Mat hist = new Mat();
float []mBuff = new float[mHistSizeNum];
MatOfFloat histogramRanges = new MatOfFloat(0f, 256f);
Scalar mColorsRGB[] = new Scalar[] { new Scalar(200, 0, 0, 255), new Scalar(0, 200, 0, 255), new Scalar(0, 0, 200, 255) };
org.opencv.core.PointmP1 = new org.opencv.core.Point();
org.opencv.core.PointmP2 = new org.opencv.core.Point();
int thikness = (int) (image.width() / (mHistSizeNum+10)/3);
if(thikness> 3) thikness = 3;
MatOfInt mChannels[] = new MatOfInt[] { new MatOfInt(0), new MatOfInt(1), new MatOfInt(2) };
Size sizeRgba = image.size();
int offset = (int) ((sizeRgba.width - (3*mHistSizeNum+30)*thikness));
// RGB
for(int c=0; c<3; c++) {
Imgproc.calcHist(Arrays.asList(image), mChannels[c], new Mat(), hist, mHistSize, histogramRanges);
Core.normalize(hist, hist, sizeRgba.height/2, 0, Core.NORM_INF);
hist.get(0, 0, mBuff);
for(int h=0; h<mHistSizeNum; h++) {
mP1.x = mP2.x = offset + (c * (mHistSizeNum + 10) + h) * thikness;
mP1.y = sizeRgba.height-1;
mP2.y = mP1.y - (int)mBuff[h];
Core.line(image, mP1, mP2, mColorsRGB[c], thikness);
}
}
}calcHist()方法分为两部分。
第一部分与配置直方图的外观和定义直方图组件有关:
int mHistSizeNum = 25;
MatOfInt mHistSize = new MatOfInt(mHistSizeNum);首先,我们定义直方图箱的个数。 在这种情况下,我们的直方图将有 25 个箱子。 然后,我们初始化一个MatOfInt()对象,该对象是Mat类的子类,但仅存储带有直方图箱数的整数。 初始化的结果是尺寸为1 x 1 x 1 (row x col x channel)的MatOfInt对象,其中保留数字25。
注意
我们需要初始化这样的对象,因为根据规范,OpenCV 计算直方图方法采用一个Mat对象,该对象保存了直方图箱的数量。
然后,我们使用以下命令初始化一个新的Mat对象以保存直方图值:
Mat hist = newMat();这次,Mat对象的尺寸为1 x 1 x nbins:
float []mBuff = new float[mHistSizeNum];回想一下在本章开始的中,我们访问了图像中的各个像素。 在这里,我们将使用相同的技术来访问直方图箱子的值,并将它们存储在float类型的数组中。 在这里,我们定义了另一个直方图组件,即直方图范围:
MatOfFloat histogramRanges = new MatOfFloat(0f, 256f);我们使用MatOfFloat()类; 它是Mat类的子类,顾名思义,它仅包含浮点数。
初始化的结果将是尺寸为2 x 1 x 1的Mat对象,其值分别为0和256:
Scalar mColorsRGB[] = new Scalar[] { new Scalar(200, 0, 0, 255), new Scalar(0, 200, 0, 255), new Scalar(0, 0, 200, 255) };在创建每个通道的直方图时,我们将通过绘制具有相应通道颜色的线条来区分每个通道的直方图。 我们初始化一个由三个Scalar对象组成的数组,该对象只是一个长度最多为 4 的双精度数组,代表三种颜色:红色,绿色和蓝色。 初始化两个点以为每个直方图箱子画一条线:
org.opencv.core.PointmP1 = new org.opencv.core.Point();
org.opencv.core.PointmP2 = new org.opencv.core.Point();对于我们为直方图箱子绘制的每条线,我们需要指定线的粗细:
int thikness = (int) (image.width() / (mHistSizeNum+10)/3);
if(thikness> 3) thikness = 3;使用值0,1和2初始化三个MatOfInt对象,以独立索引每个图像通道:
MatOfInt mChannels[] = new MatOfInt[] { new MatOfInt(0), new MatOfInt(1), new MatOfInt(2) };计算开始绘制直方图的偏移量:
Size sizeRgba = image.size();
int offset = (int) ((sizeRgba.width - (3*mHistSizeNum+30)*thikness));让我们继续进行第二部分,在其中计算和绘制直方图:
// RGB
for(int c=0; c<3; c++) {
Imgproc.calcHist(Arrays.asList(image), mChannels[c], new Mat(), hist, mHistSize, histogramRanges);
Core.normalize(hist, hist, sizeRgba.height/2, 0, Core.NORM_INF);
hist.get(0, 0, mBuff);
for(int h=0; h<mHistSizeNum; h++) {
mP1.x = mP2.x = offset + (c * (mHistSizeNum + 10) + h) * thikness;
mP1.y = sizeRgba.height-1;
mP2.y = mP1.y - (int)mBuff[h];
Core.line(image, mP1, mP2, mColorsRGB[c], thikness);
}
}注意的第一件事是我们一次只能计算一个通道的直方图。 这就是为什么我们为三个通道运行一个for循环的原因。 至于循环的主体,第一步是调用Imgproc.calcHist(),将其传递给以下参数后执行所有繁重的工作:
Mat对象的列表。Imgproc.calcHist()计算图像列表的直方图,在我们的示例中,我们正在传递仅包含一个图像的Mat对象列表。- 通道索引的
MatOfInt对象。 - 如果要计算图像特定区域的直方图,则将
Mat对象用作遮罩。 但是,在本例中,我们需要计算整个图像的直方图,这就是为什么我们发送一个空的Mat对象的原因。 - 一个
Mat对象,用于存储直方图值。 - 一个
MatOfInt对象,用于保存箱数。 - 一个
MatOfFloat对象,用于保存直方图范围。
现在我们已经计算出直方图,有必要对其值进行归一化,以便可以在设备屏幕上显示它们。 Core.normalize()可以以几种不同的方式使用:
Core.normalize(hist, hist, sizeRgba.height/2, 0, Core.NORM_INF);此处使用的一种方法是使用输入数组的范数进行归一化,这是本例中的直方图值,并传递以下参数:
- 作为要归一化的值的
Mat对象。 - 作为归一化后的目标的
Mat对象。 - 双 Alpha。 在范数归一化的情况下,alpha 将用作范数值。 对于另一种情况(范围归一化),alpha 将是范围的最小值。
- 双重测试版。 该参数仅在范围归一化的情况下用作最大范围值。 在我们的例子中,我们通过了
0,因为它没有被使用。 - 整数范数类型。 此参数指定要使用的规范化。 在我们的例子中,我们传递了
Core.NORM_INF,它告诉 OpenCV 使用无穷范数进行归一化,将输入数组的最大值设置为等于 alpha 参数(在本例中为图像高度的一半)。 您可以使用其他规范,例如 L2 规范或 L1 规范,这分别相当于传递Core.NORM_L2或Core.NORM_L1。 另外,您可以通过传递Core.MINMAX来使用范围归一化,这会将源的值归一化为 alpha 和 beta 参数之间。
标准化后,我们在float数组中检索直方图箱子值:
hist.get(0, 0, mBuff);最后,我们使用Core.line()为直方图中的每个箱子绘制一条线:
for(int h=0; h<mHistSizeNum; h++) {
//calculate the starting x position related to channel C plus 10 //pixels spacing multiplied by the thickness
mP1.x = mP2.x = offset + (c * (mHistSizeNum + 10) + h) * thikness;
mP1.y = sizeRgba.height-1;
mP2.y = mP1.y - (int)mBuff[h];
Core.line(image, mP1, mP2, mColorsRGB[c], thikness);
}向Core.line()传递以下参数:
- 要在其上绘制的
Mat对象 - 表示行起点的
Point对象 - 表示行终点的
Point对象 - 表示线条颜色的
Scalar对象 - 代表线宽的整数
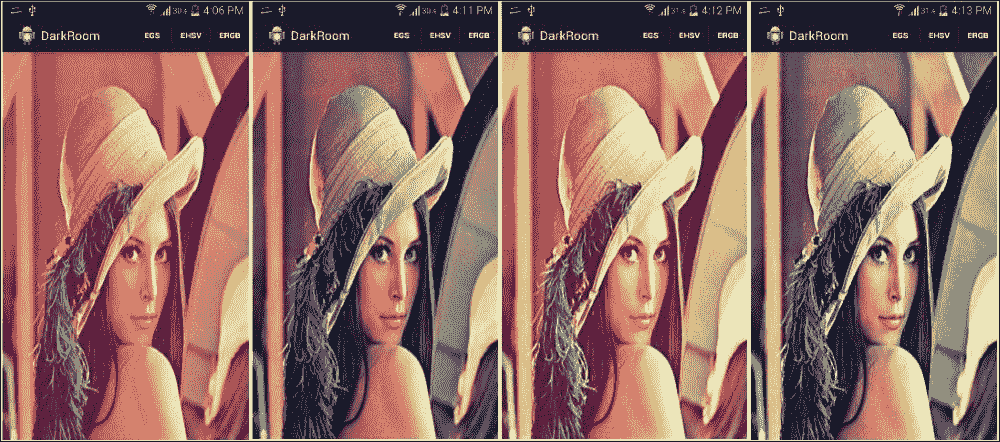
最终输出将是加载的图像,其中包含每个颜色通道的直方图:

增强图像对比度
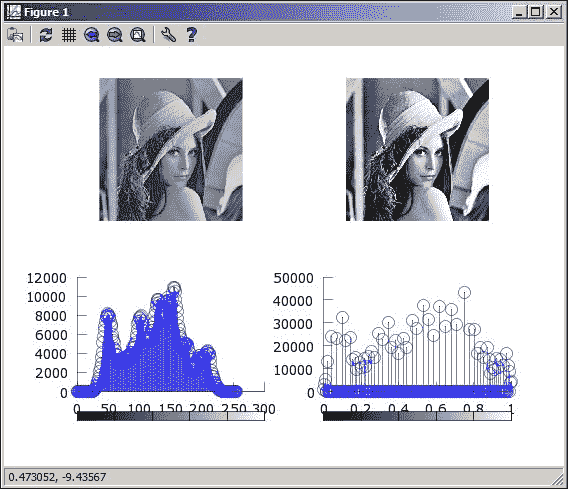
现在,您了解了直方图以及如何计算直方图,是时候来看一下最广泛使用的图像增强技术之一:直方图均衡化了。 直方图均衡技术用于增强图像对比度,即最小和最大强度值之间的差异,以便增强可以冲洗掉的图像细节。
了解直方图均衡
从抽象的角度来看,直方图均衡化的作用是找到一个函数,该函数获取图像的原始直方图并将其转换为具有图像强度值均匀分布的拉伸直方图,从而增强图像对比度。
实际上,直方图均衡不会产生完全均衡的输出直方图。 但是,它可以很好地近似所需的变换,从而可以在图像的定义的均衡范围内更均匀地分布强度值:
增强灰度图像
自从本书开始以来,我们并没有真正区分将应用的算法集应用于灰度或全彩色图像。 但是,将直方图均衡化应用于灰度图像与将其应用于全彩色图像具有不同的效果。
我们将首先从将直方图均衡应用于灰度图像。
UI 定义
我们将在前面开发的项目的基础上,添加更多菜单项以触发图像增强功能。
打开菜单文件res/menu/iodark_room.xml,然后添加新的子菜单:
<item android:id="@+id/enhance_gs"android:title="@string/enhance_gs"android:enabled="true"android:visible="true"android:showAsAction="always"android:titleCondensed="@string/enhance_gs_small">
<menu>
<item android:id="@+id/action_togs"android:title="@string/action_ctgs"/>
<item android:id="@+id/action_egs"android:title="@string/action_eqgsistring"/>
</menu>
</item>在新的子菜单中,我们添加了两个新项目:一项将图像转换为灰度,第二项触发直方图均衡化。
将图像转换为灰度
OpenCV 支持多种颜色空间转换,因此将全彩色图像转换为灰度级所需的工作量非常小。
我们需要在活动中更新onOptionsItemSelected(MenuItem item)方法以处理按下新菜单项的操作,以便转换为灰度:
else if (id == R.id.action_togs) {
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
greyImage=new Mat();
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);
displayImage(greyImage);
return true;
}我们进行检查以查看采样图像是否已加载,然后调用Imgproc.cvtColor()并将以下参数传递给它:
- 作为我们的源图像的
Mat对象。 - 作为目标图像的
Mat对象。 - 表示要从哪个色彩空间转换以及要从哪个色彩空间转换的整数。 在本例中,我们选择了从 RGB 转换为灰度。
最后,我们显示灰度图像。
均衡灰度图像的直方图
我们更改了onOptionsItemSelected(MenuItem item)方法以处理直方图均衡菜单项:
else if (id == R.id.action_egs) {
if(greyImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to convert the image to greyscale first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat eqGS=new Mat();
Imgproc.equalizeHist(greyImage, eqGS);
displayImage(eqGS);
return true;
}我们将再次检查用户是否已经将图像转换为灰度图像。 否则,直方图均衡方法将失败。 然后,我们调用Imgproc.equalizeHist()并传入两个参数:
- 作为源图像的
Mat对象 - 作为目标图像的
Mat对象
最后,我们调用displayImage()以显示增强后的图像:

增强 HSV 图像
要使用直方图均衡来增强完整的彩色图像并获得相同的效果,即增强图像对比度,我们需要将图像从 RGB 空间转换为 HSV,然后将相同的算法应用于饱和(S)和值(V)通道。
UI 定义
所做的更改与添加新菜单项以触发 HSV 增强有关:
<item android:id="@+id/action_HSV"android:titleCondensed="@string/action_enhanceHSV"android:title="@string/action_enhanceHSV"android:enabled="true"android:showAsAction="ifRoom"android:visible="true"/>均衡 HSV 图像的直方图
您需要掌握的主要技能是在各个基础上使用图像通道:
else if (id == R.id.action_HSV) {
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}首先,更新onOptionsItemSelected(MenuItem item)以处理新的菜单项:
Mat V=new Mat(sampledImage.rows(),sampledImage.cols(),CvType.CV_8UC1);
Mat S=new Mat(sampledImage.rows(),sampledImage.cols(),CvType.CV_8UC1);初始化两个新的Mat对象以保存图像值和饱和度通道:
Mat HSV=new Mat();
Imgproc.cvtColor(sampledImage, HSV, Imgproc.COLOR_RGB2HSV);现在,我们将 RGB 图像转换为 HSV 颜色空间:
byte [] Vs=new byte[3];
byte [] vsout=new byte[1];
byte [] ssout=new byte[1];
for(int i=0;i<HSV.rows();i++){
for(int j=0;j<HSV.cols();j++)
{
HSV.get(i, j,Vs);
V.put(i,j,new byte[]{Vs[2]});
S.put(i,j,new byte[]{Vs[1]});
}
}然后,我们逐像素访问图像以复制饱和度和值通道:
Imgproc.equalizeHist(V, V);
Imgproc.equalizeHist(S, S);调用Imgproc.equalizeHist()以增强值和饱和度通道:
for(int i=0;i<HSV.rows();i++){
for(int j=0;j<HSV.cols();j++)
{
V.get(i, j,vsout);
S.get(i, j,ssout);
HSV.get(i, j,Vs);
Vs[2]=vsout[0];
Vs[1]=ssout[0];
HSV.put(i, j,Vs);
}
}现在,我们将增强的饱和度和值复制回原始图像:
Mat enhancedImage=new Mat();
Imgproc.cvtColor(HSV,enhancedImage,Imgproc.COLOR_HSV2RGB);
displayImage(enhancedImage);
return true;最后,我们将 HSV 颜色空间转换为 RGB 并显示增强的图像:

增强 RGB 图像
在红色,绿色和蓝色通道上执行直方图均衡将给您带来不同的效果,就好像您正在调整色相一样。
UI 定义
我们将添加一个新的菜单项,以在单个通道或一组通道上执行 RGB 增强:
<item android:id="@+id/action_RGB"android:title="@string/action_RGB"android:titleCondensed="@string/action_enhanceRGB_small"android:enabled="true"android:showAsAction="ifRoom"android:visible="true">
<menu>
<item android:id="@+id/action_ER"android:titleCondensed="@string/action_enhance_red_small"android:title="@string/action_enhance_red"android:showAsAction="ifRoom"android:visible="true"android:enabled="true"android:orderInCategory="1"/>
<item android:id="@+id/action_EG" android:showAsAction="ifRoom"android:visible="true"android:enabled="true"android:titleCondensed="@string/action_enhance_green_small"android:title="@string/action_enhance_green"android:orderInCategory="2"/>
<item android:id="@+id/action_ERG" android:showAsAction="ifRoom"android:visible="true"android:enabled="true"android:titleCondensed="@string/action_enhance_red_green_small"android:title="@string/action_enhance_red_green"android:orderInCategory="3"/>
</menu>
</item>均衡图像颜色通道的直方图
您可能注意到逐像素访问图像的速度很慢,尤其是在图像分辨率较高的情况下。 在本节中,我们将探索另一种使用图像通道的技术,该技术更快,如下所示:
else if(id==R.id.action_ER)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat redEnhanced=new Mat();
sampledImage.copyTo(redEnhanced);
Mat redMask=new Mat(sampledImage.rows(),sampledImage.cols(),sampledImage.type(),new Scalar(1,0,0,0));此处重要的一行是初始化redMask(这是一个Mat对象),所有通道均设置为0,第一个通道除外,第一个通道是 RGB 图像中的红色通道。
然后,我们调用enhanceChannel()方法,并传入我们创建的已加载图像和通道掩码的副本:
enhanceChannel(redEnhanced,redMask);在enhanceChannel()方法中,我们首先将加载的图像复制到另一个Mat对象:
private void enhanceChannel(Mat imageToEnhance,Mat mask)
{
Mat channel=new Mat(sampledImage.rows(),sampledImage.cols(),CvType.CV_8UC1);
sampledImage.copyTo(channel,mask);
Imgproc.cvtColor(channel, channel, Imgproc.COLOR_RGB2GRAY,1);
Imgproc.equalizeHist(channel, channel);
Imgproc.cvtColor(channel, channel, Imgproc.COLOR_GRAY2RGB,3);
channel.copyTo(imageToEnhance,mask);
}但是,这次我们将遮罩传递给复制方法,以仅提取图像的指定通道。
然后,我们将复制的通道转换为灰度颜色空间,以使深度为 8 位,并且equalizeHist()不会失败。
最后,我们将其转换为 RGB Mat对象,将增强的通道复制到红色,绿色和蓝色,然后使用相同的遮罩将增强的通道复制到传递的参数。
您可以轻松地制作自己制作的遮罩,以增强不同的通道或通道的组合。
总结
到目前为止,您应该已经了解了如何在 OpenCV 中表示和存储图像。 您还开发了自己的暗室应用,从图库中加载图像,计算并显示其直方图,并在不同的颜色空间上执行直方图均衡化,以增强图像的外观。
在下一章中,我们将开发一个新的应用,以利用更多的 OpenCV 图像处理和计算机视觉算法。 我们将使用算法来平滑图像并检测年龄,线条和圆圈。
三、应用 2-软件扫描程序
在本章中,我们将开始实现下一个应用,即软件扫描程序。 它使人们可以为一张收据拍照,并进行一些转换以使其看起来像被扫描一样。
该应用将分为两章。 在本章中,我们将介绍两个重要的主题,这些主题将帮助我们实现最终目标。
第一个主题是关于空间滤波及其定义和应用。 您将学习如何减少图像噪声,也称为图像平滑。 此外,您还将了解使用 OpenCV 中实现的具有高度抽象性的不同算法检测图像边缘(对象边界)的过程。
第二个主题将涉及另一种著名的形状分析技术,称为霍夫变换。 您将了解该技术背后的基本思想,该思想使其变得非常流行和广泛使用,并且我们将使用 OpenCV 实现来开始将直线和圆拟合到一组边缘像素。
空间过滤
在第 2 章,“应用 1-建立自己的暗室”中,我们讨论了如何使用直方图均衡化等技术增强给定图像,以使图像更令人愉悦。 增强不同色彩空间中的图像对比度。 在本节中,我们将讨论另一种增强技术,通常用作许多计算机视觉算法的预处理步骤,即空间滤波。
在开始概念之前,让我们首先创建一个新的 Android 应用。 我们将按照与上一章相同的步骤进行操作; 但是,我们将列出与应用命名相关的不同步骤,依此类推:
- 创建一个新的 Android 项目并将其命名为
SoftScanner。 - 选择包装名称; 在我们的示例中,我们使用了
com.app2.softscanner。 - 创建空白活动时,只需将其命名为
SoftScanner即可。 - 继续执行将 OpenCV 库与新应用链接的步骤。
- 对于 UI 定义和权限,请遵循与上一章完全相同的步骤。
- 要异步加载 OpenCV 库并从设备中读取图像,请遵循第 2 章“使用 OpenCV 读取”的“App 1:建立自己的暗室”部分中完全相同的步骤。
注意
在继续之前,请确保您能够加载 OpenCV 库并读取和显示存储在手机上的图像。
了解卷积和线性过滤器
增强图像的主要目的是使图像更具吸引力并在视觉上可以接受,而您通常需要做的是强调边缘,减少噪点并有时引入模糊效果。
这些增强操作以及许多其他增强操作可以通过空间滤波来实现。 我们在这里使用项目空间来强调滤波过程发生在实际的图像像素上,并将其与其他过滤器(例如频域过滤器)区分开。 在前进的过程中,我们将不再讨论频域过滤器,因此从现在开始,我们将空间过滤器称为过滤器。
无论要使用哪种过滤器,通常遵循的将过滤器应用于图像的过程几乎都是标准的。 简而言之,对于线性过滤器,我们考虑原始图像的每个像素(通常将其称为目标像素),并将其值替换为其周围指定邻域的加权和。 之所以称为线性过滤器,是因为目标像素的新值是其附近像素的线性组合(加权和)的结果。
加权总和中的权重由过滤器核(掩码)确定; 这只是我们要考虑的邻域大小的子图像。 计算新目标像素值的方法是定位核,使中心权重的位置与目标像素重合。 然后我们结合加权后的邻域像素(包括目标像素及其对应的权重)来获得目标像素的新值。 最后,我们继续对目标图像中的每个像素重复此过程。
应用离散形式的线性过滤器的机制也称为卷积,有时将过滤器核描述为卷积核。
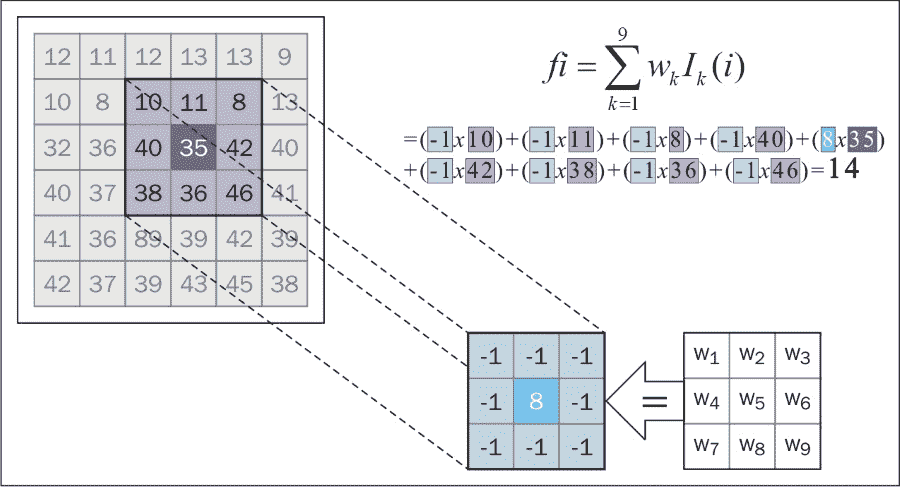
最后,我们可以总结线性卷积过程,如下所示:
- 定义卷积核(即,指定邻域像素的权重)。
- 将核放置在目标图像上,以使目标像素与核的中心重合。
- 将核下方的像素与核中的相应权重相乘,然后用结果替换目标像素。
- 对目标图像中的每个像素重复步骤 2 和 3。
消除噪音
过滤的第一个应用使图像模糊,也称为平滑。 该过程的结果是具有较少噪声的目标图像。 我们将介绍三种不同的模糊技术:平均,高斯和中值。
平均过滤器
通过设计卷积核,将目标像素的值替换为核下邻域的平均值,可以得到平均过滤器。
大小为3 x 3的典型卷积核k如下所示:
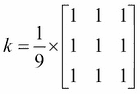
按照前面提到的过程,每个目标像素将被其3 x 3邻域的平均值替换,更改核的大小将使使图像更加模糊,因为您在该邻域中包含了越来越多的像素 。
高斯过滤器
平均过滤器平均对待邻居中的每个像素,以便邻居中的每个像素将具有相同的权重,即对新目标像素值的影响相同。
但是,在实际情况下,并非如此。 通常,当我们远离目标像素的位置时,邻域的影响变得越来越弱; 因此,距离目标像素越远,效果应越小,即权重越小。
使用高斯过滤器可以实现这种关系。 顾名思义,此过滤器使用高斯函数通过一维公式确定给定邻域的权重分布:
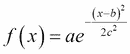
这将产生一个钟形曲线,其中a是曲线峰的高度,b是峰中心或均值的位置,c是标准差或 sigma,它指示峰宽。 钟形曲线是。 具有参数的钟形曲线的示例如下:a = 1, b = 0, c = 1。
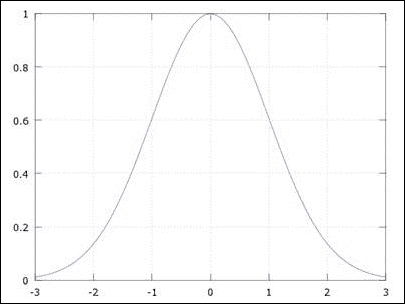
要使用高斯函数进行滤波,我们应该将其扩展到二维空间,但又不失一般性,相同的概念适用于此处绘制的一维版本。
现在,将x轴视为核中的权重索引(其中 0 是中心权重),将y轴视为权重值。 因此,如果我们移动核使其中心(在x = 0处的曲线中心)与目标像素重合,则将最高权重(曲线的峰值)分配给目标像素,然后远离核中心移动,权重会继续减小,因此,对远离目标像素的像素分配的重要性较低。
中值过滤器
在该过滤器中,邻域中的像素根据其强度值进行排序,目标像素被排序后的邻域的中位数代替。 中值过滤器对于消除称为椒盐噪声的一种噪声非常有效,如下所示:

UI 定义
对于每种过滤器类型,我们将在应用中添加不同的菜单项。 转到res/menu/soft_scanner.xml文件并打开它以包含以下菜单项:
<item
android:id="@+id/img_blurr"
android:enabled="true"
android:orderInCategory="4"
android:showAsAction="ifRoom"
android:title="@string/list_blurr"
android:titleCondensed="@string/list_blurr_small"
android:visible="true">
<menu>
<item
android:id="@+id/action_average"
android:title="@string/action_average"/>
<item
android:id="@+id/action_gaussian"
android:title="@string/action_gaussian"/>
<item
android:id="@+id/action_median"
android:title="@string/action_median"/>
</menu>
</item>应用过滤器以减少图像噪点
OpenCV 为我们在此讨论的每个过滤器提供了一种的即用型实现。 我们需要做的就是指定一些特定于过滤器的参数,然后我们就可以开始了。
在SoftScanner活动中,我们需要编辑onOptionesItemSelected()方法并添加以下情况:
else if(id==R.id.action_average)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat blurredImage=new Mat();
Size size=new Size(7,7);
Imgproc.blur(sampledImage, blurredImage, size);
displayImage(blurredImage);
return true;
}
else if(id==R.id.action_gaussian)
{
/* code to handle the user not loading an image**/
/**/
Mat blurredImage=new Mat();
Size size=new Size(7,7);
Imgproc.GaussianBlur(sampledImage, blurredImage, size, 0,0);
displayImage(blurredImage);
return true;
}
else if(id==R.id.action_median)
{
/* code to handle the user not loading an image**/
/**/
Mat blurredImage=new Mat();
int kernelDim=7;
Imgproc.medianBlur(sampledImage,blurredImage , kernelDim);
displayImage(blurredImage);
return true;
}对于每个选定的过滤器,我们遵循相同的过程:
如果用户未从图库中选择或加载图片,我们将处理以下情况:
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}对于平均过滤器,我们调用Imgproc.blur()方法,并传入以下参数:
输入图像的Mat对象; 它可以具有任意数量的通道,这些通道是独立处理的。
应用过滤器后,输出图像的Mat对象。
指示要使用的核(邻居)大小的Size对象。 在我们的例子中,核的大小为7 x 7。
Mat blurredImage=new Mat();
Size size=new Size(7,7);
Imgproc.blur(sampledImage, blurredImage, size);
displayImage(blurredImage);
return true;要应用高斯过滤器,我们使用以下参数调用Imgproc.GaussianBlur()方法:
输入图像的Mat对象。
输出图像的Mat对象。
指示核大小的Size对象。 您可以使用不同高度和宽度的核。 但是,两者都应为奇数和正数。
代表x方向上标准差的双精度型。 在我们的例子中,我们将其设置为0,以便 OpenCV 根据核宽度为我们计算该值。
代表y方向标准差的双精度型,我们也将其设置为0,以便 OpenCV 根据核高度计算值:
Mat blurredImage=new Mat();
Size size=new Size(7,7);
Imgproc.GaussianBlur(sampledImage, blurredImage, size, 0,0);
displayImage(blurredImage);
return true;最后,要使用中值过滤器,我们使用以下参数调用Imgproc.medianBlur():
输入图像的Mat对象。
输出图像的Mat对象。
一个代表核大小的整数,我们使用一个值,因为中值过滤器是盒式过滤器(即核宽度等于其高度)。 但是,核维的值应为正数和奇数。
Mat blurredImage=new Mat();
int kernelDim=7;
Imgproc.medianBlur(sampledImage,blurredImage , kernelDim);
displayImage(blurredImage);
return true;下图显示了三个使用不同核大小的平均过滤器的示例(左:11,中心:25和右:35)。 您会看到,随着核大小的增加,详细信息开始被淘汰:

下图是示例,该示例显示了中值过滤器在消除椒盐噪声中的效果:

寻找边缘
空间滤波的另一个应用是在图像中找到边缘(对象边界)。 边缘检测的过程取决于计算像素强度变化的速率。 凭直觉,当变化率高时,在该区域中更有可能存在边缘。
为了计算变化率,我们使用离散域中的导数的概念,因为对于大小为n x n的图像,我们只有行号1, 2, ..., n和列号1, 2, ..., n,而我们没有行号1.1, 1.2, ...。
让我们考虑图像I(x, y),其中x是列号,y是行号。 由于它是两个变量的函数,因此我们将根据x的离散导数逼近公式,使用独立地为每个变量计算偏导数:
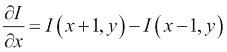
这是图像相对于x的一阶导数,并且为了计算图像相对于y的一阶导数,我们使用以下公式:
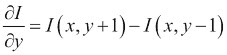
因此,对于x取图像的导数非常简单。 我们取x + 1的像素值,并从x-1的像素中减去它,这称为中心差,y也是如此。
最后,由于图像具有二维(行和列),因此对于每个像素(一个用于x方向,一个用于y方向),我们得到一个梯度向量[∂I/∂x; ∂I/∂y],并且由于它是向量,所以它可以告诉我们两件事:
- 代表该像素边缘强度的梯度量级
- 代表边缘方向的梯度方向
展望未来,我们可以设计一个简单的核来计算平均中心差,以找到图像在x和y方向上的导数,如下所示:
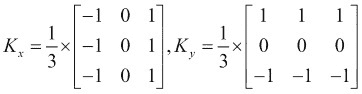
现在,我们可以按照以下步骤总结一阶导数边缘检测过程:
- 我们使用平滑过滤器对图像进行平滑处理(以消除噪点)。
- 计算
x方向的导数; 输出将是被核过滤为K[x]的图像。 - 计算
y方向的导数; 输出将是另一个以K[y]核过滤的图像。 - 计算每个像素的梯度大小。
- 阈值梯度量,即,如果像素的梯度量大于某个阈值,则为边缘。 否则,事实并非如此。
下图是一个示例,它针对原始图像(左)在x方向上计算一阶导数以检测垂直边缘(中心),对于y方向来计算水平边缘(右):
Sobel 边缘检测器
OpenCV 为提供了不同的边缘检测器。 我们将开始使用的设备命名为 Sobel 边缘检测器。 这里的主要思想是卷积核的设计:
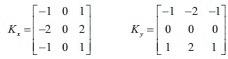
核更加强调K[x]的中心行和K[y]的中心列。
Canny 边缘检测器
另一个非常好的边缘检测器(也称为最佳检测器)是 Canny 边缘检测器。
在 Canny 边缘检测器中,我们通过以下步骤确定边缘像素:
- 我们使用高斯过滤器平滑处理图像。
- 使用例如 Sobel 过滤器为每个像素计算梯度向量。
- 通过将每个像素的梯度大小与其在梯度方向上的邻域进行比较,来抑制非最大像素。 我们确定它是边缘的一部分,因此,如果其梯度幅度最大,则将其保留。
- 最后,Canny 对称为滞后的过程使用两个阈值(低和高)来确定保留的像素:
- 如果像素的梯度幅度大于高阈值,则该像素被接受为边缘像素。
- 如果像素的梯度幅度小于低阈值,则立即拒绝像素。
- 如果像素梯度幅度在高阈值和低阈值之间,并且它连接到梯度幅度高于高阈值的像素,则该像素将被视为边缘像素。
UI 定义
我们将在我们的应用中添加一些菜单项,以触发我们将使用的不同边缘检测器。 转到res/menu/soft_scanner.xml文件并打开它以包含以下菜单项:
<item
android:id="@+id/img_edge_detection"
android:enabled="true"
android:orderInCategory="5"
android:showAsAction="ifRoom"
android:title="@string/list_ed"
android:titleCondensed="@string/list_ed_small"
android:visible="true">
<menu>
<item
android:id="@+id/action_sobel"
android:title="@string/action_sobel"/>
<item
android:id="@+id/action_canny"
android:title="@string/action_canny"/>
</menu>
</item>应用 Sobel 过滤器查找边缘
在本节中,我们将同时使用 Sobel 和 Canny 边缘检测器来查找图像中的边缘。 我们将从 Sobel 边缘过滤器开始。
在SoftScanner活动中,我们需要编辑onOptionesItemSelected()方法并添加以下情况:
else if(id==R.id.action_sobel)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat blurredImage=new Mat();
Size size=new Size(7,7);
Imgproc.GaussianBlur(sampledImage, blurredImage, size, 0,0);
Mat gray = new Mat();
Imgproc.cvtColor(blurredImage, gray, Imgproc.COLOR_RGB2GRAY);
Mat xFirstDervative =new Mat(),yFirstDervative =new Mat();
int ddepth=CvType.CV_16S;
Imgproc.Sobel(gray, xFirstDervative,ddepth , 1,0);
Imgproc.Sobel(gray, yFirstDervative,ddepth , 0,1);
Mat absXD=new Mat(),absYD=new Mat();
Core.convertScaleAbs(xFirstDervative, absXD);
Core.convertScaleAbs(yFirstDervative, absYD);
Mat edgeImage=new Mat();
Core.addWeighted(absXD, 0.5, absYD, 0.5, 0, edgeImage);
displayImage(edgeImage);
return true;
}由于 Sobel 是一阶导数边缘检测器,因此我们将遵循前面概述的过程:
我们使用您之前了解的模糊过滤器之一来平滑图像,以减少我们计算边缘像素时的噪声响应。 就我们而言,在大多数情况下,我们使用大小为7 x 7的高斯过滤器:
Mat blurredImage=new Mat();
Size size=new Size(7,7);
Imgproc.GaussianBlur(sampledImage, blurredImage, size, 0,0);将平滑图像转换为灰度图像:
Mat gray = new Mat();
Imgproc.cvtColor(blurredImage, gray, Imgproc.COLOR_RGB2GRAY);使用Imgproc.Sobel()并传入以下参数,计算灰度图像的x和y一阶导数:
作为源图像的Mat对象。
作为输出图像的Mat对象。
一个整数深度,用于指示输出图像的深度。 在大多数情况下,输入和输出图像的深度相同。 但是,当我们在某些情况下计算导数时,该值为负(即,从白色(255)变为黑色(0,derivative = -255 - 0 = -255)。 因此,如果我们使用的Mat对象的深度为无符号 8 位(灰色图像仅保留 0 到 255 之间的值),则负导数的值将溢出并设置为0,即错过这个边。 要变通解决此问题,我们使用带符号的 16 位深度输出图像来存储负导数。
我们要计算的x阶的整数。 我们将其设置为1以计算x的一阶导数。
我们要计算的y阶的整数。 我们将其设置为1以计算y的一阶导数。
注意
注意,要计算x方向上的梯度,我们使用x-order = 1和y-order = 0。 我们对y方向类似地做。
以下是代码:
Mat xFirstDervative =new Mat(),yFirstDervative =new Mat();
int ddepth=CvType.CV_16S;
Imgproc.Sobel(gray, xFirstDervative,ddepth , 1,0);
Imgproc.Sobel(gray, yFirstDervative,ddepth , 0,1);我们调用Core.convertScaleAbs()在输入Mat对象上依次执行三个操作:
- 缩放输入
Mat对象的值; 但是,由于我们没有传递任何缩放因子,因此跳过了缩放步骤。 - 取输入
Mat对象中每个元素的绝对值。 我们需要此步骤,因为我们存储了x和y一阶导数的负值,但实际上我们关心导数的绝对值,并且我们希望能够将这些值存储在无符号的 8 位Mat对象中(存储从 0 到 255 的值)。 - 转换为无符号的 8 位深度
Mat对象。
Core.convertScaleAbs()的参数是输入和输出Mat对象:
Mat absXD=new Mat(),absYD=new Mat();
Core.convertScaleAbs(xFirstDervative, absXD);
Core.convertScaleAbs(yFirstDervative, absYD);我们尝试使用Core.addWeighted()来估计梯度大小以显示边缘图像,该函数计算两个图像的加权和。 我们通过传递以下参数来实现:
- 第一张图片的
Mat对象。 我们在x方向传递了绝对一阶导数。 - 第一张图片的权重的两倍; 在我们的例子中,两个图像均为
0.5。 - 第二个图像的
Mat对象。 我们沿y方向传递了绝对一阶导数。 - 第二张图像的权重的两倍。
- 每个总和加一个双精度值。 我们不需要添加任何内容,因此我们发送
0。 - 一个
Mat对象,用于存储输出图像。
注意
这是梯度量的近似值。 就本示例而言,这是好的。 但是,如果需要计算实际的梯度幅度,则必须使用此公式gradient magnitude = √(f[x]² + f[y]²),其中f[x], f[y]分别是x和y方向上的一阶导数的值。
以下是代码:
Mat edgeImage=new Mat();
Core.addWeighted(absXD, 0.5, absYD, 0.5, 0, edgeImage);最后,我们显示edgeImage:
displayImage(edgeImage);
应用 Sobel 过滤器检测边缘的示例
使用 Canny 边缘检测器
应用 Canny 边缘检测器更为简单; 我们实际上只需要在 OpenCV 中执行一个功能,Canny 边缘检测器的所有步骤都将为我们执行。 通过这种抽象水平,我们只需要指定一些算法参数即可。
在SoftScanner活动中,我们需要编辑onOptionesItemSelected()方法并添加以下情况:
else if(id==R.id.action_canny)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat gray = new Mat();
Imgproc.cvtColor(sampledImage, gray, Imgproc.COLOR_RGB2GRAY);
Mat edgeImage=new Mat();
Imgproc.Canny(gray, edgeImage, 100, 200);
displayImage(edgeImage);
return true;
}您可以看到这些步骤更加简单:
我们将输入图像转换为灰度,因为 Canny 仅适用于灰度图像:
Mat gray = new Mat();
Imgproc.cvtColor(sampledImage, gray, Imgproc.COLOR_RGB2GRAY);我们调用Imgproc.Canny()并传递以下参数:
- 作为输入灰度图像的
Mat对象 - 输出边缘图像的
Mat对象 - 迟滞步骤中下限阈值的两倍
- 迟滞步骤中上限的两倍
注意
Canny 建议将上限阈值和下限阈值的比率设置为 2:1 到 3:1。
以下是代码:
Mat edgeImage=new Mat();
Imgproc.Canny(gray, edgeImage, 100, 200);最后,我们显示edgeImage:
displayImage(edgeImage);
应用 Canny 边缘检测器的示例
检测形状
因此,我们已经看到如何检测边缘; 但是,此过程是逐个像素的过程,回答了该像素是否为边缘的问题。 展望未来,在形状分析中,我们不仅需要边缘测试,还需要更多具体的信息。 我们将需要更好的代表。
例如,如果我们有一个盒子的图片,并且进行了边缘检测,那么最终将得到成千上万的边缘像素。 但是,如果我们尝试使一条线适合这些边缘像素,则会得到一个矩形,这是一种更具符号性和实用性的表示形式。
了解霍夫线变换
有许多方法可以使一条线穿过多个点,并且霍夫变换被认为是一种约束不足的方法,其中我们仅使用一个点来查找所有可以通过该点的线,我们使用另一个点来查找所有可以通过它的线,并且我们继续对所有点进行此操作。
我们最终得到一个投票系统,其中每个点都为一条线投票,并且同一条线上的点越多,对该行的投票就越高。 简而言之,霍夫变换可以描述为将x, y空间中的点映射到感兴趣形状的参数空间。
利用x和y空间中的直线方程y = ax + b,将其变换为斜率(a)的空间并截取空间(b),并给出此变换,得出x和y空间中的点,实际上是斜率与截距空间中的一条线,其方程式为b = -ax + y:
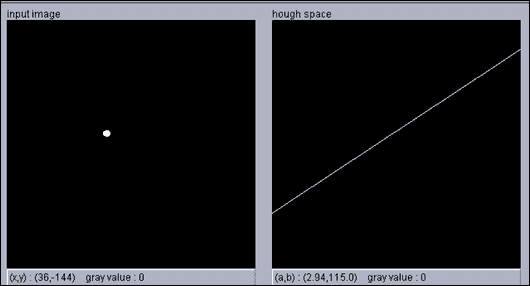
在下图中,我们在x和y空间中有五个点(左)。 当转换为斜率和截距空间时,我们得到五行(右):
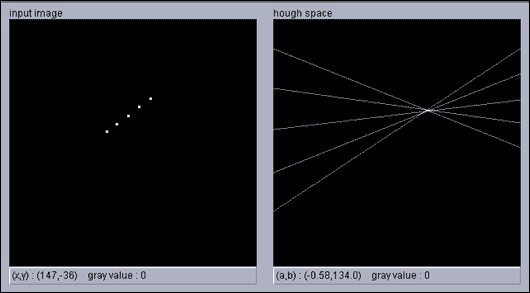
现在,x和y空间中的每个点都将投票给一个斜率,并在该斜率和截距空间中进行拦截,因此我们要做的就是在参数空间中找到最大值,这就是适合我们的点:
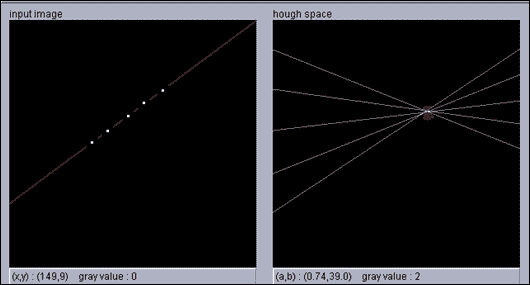
在上一幅图像的右图中,您可以基于左图中的点的投票找到最大值,在左图中,您可以看到最大值是拟合这些点的直线的斜率和截距。
对于垂直线,斜率是无穷大,这就是为什么使用线的极坐标方程代替斜率和截距形式更实际的原因。 在这种情况下,我们要处理的方程是r = x cosθ + y sinθ,我们又有两个参数r(ρ)和θ,我们将遵循相同的思想,只是现在的空间为r和θ而不是斜率和截距。
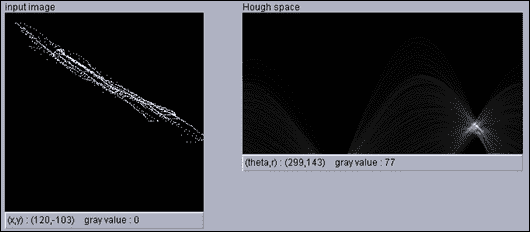
我们再次遵循投票系统,找到代表我们的点的直线的r和θ最大值。 但是,这一次x和y空间中的点将是正弦曲线,如果两个或多个正弦曲线在同一r和θ处相交,则意味着它们属于同一行:
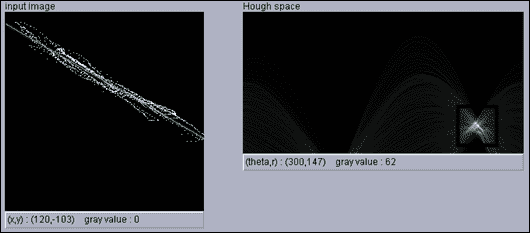
注意
您可以在这个页面上使用小程序查看霍夫变换的运行情况。
使用霍夫变换检测直线
在 OpenCV 中,我们具有霍夫线变换的两种实现:
- 标准霍夫变换:该过程与先前说明的过程非常相似; 但是,由于算法必须检查给定图像中的所有边缘点,因此被认为是较慢的选择。
- 概率霍夫线变换:此选项是我们将在示例中使用的选项。 在概率版本中,该算法尝试通过利用检测线条所需的投票分数差异来最小化检测线条所需的计算量。 直观地,对于强行或长线,在决定累加器仓位是否达到非偶然计数之前,我们只需要支持点的一小部分就可以投票。 但是,对于较短的行,需要确定更高的部分。 总之,该算法试图使确定拟合线所需的边缘点数量最少。
UI 定义
我们将添加一个新的菜单项以启动霍夫变换算法。 转到res/menu/soft_scanner.xml文件并打开它以包含以下菜单项:
<item android:id="@+id/action_HTL"
android:enabled="true"
android:visible="true"
android:title="@string/action_HL">
</item>检测和绘制线条
使用霍夫线变换的过程分为四个步骤:
- 加载感兴趣的图像。
- 使用 Canny 检测图像边缘; 输出将是二进制图像。
- 在二进制图像上调用标准或概率霍夫线变换。
- 画出检测到的线。
在SoftScanner活动中,我们需要编辑onOptionesItemSelected()方法并添加以下情况:
else if(id==R.id.action_HTL)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat binaryImage=new Mat();
Imgproc.cvtColor(sampledImage, binaryImage, Imgproc.COLOR_RGB2GRAY);
Imgproc.Canny(binaryImage, binaryImage, 80, 100);
Mat lines = new Mat();
int threshold = 50;
Imgproc.HoughLinesP(binaryImage, lines, 1, Math.PI/180, threshold);
Imgproc.cvtColor(binaryImage, binaryImage, Imgproc.COLOR_GRAY2RGB);
for (int i = 0; i < lines.cols(); i++)
{
double[] line = lines.get(0, i);
double xStart = line[0],
yStart = line[1],
xEnd = line[2],
yEnd = line[3];
org.opencv.core.Point lineStart = new org.opencv.core.Point(xStart, yStart);
org.opencv.core.Point lineEnd = new org.opencv.core.Point(xEnd, yEnd);
Core.line(binaryImage, lineStart, lineEnd, new Scalar(0,0,255), 3);
}
displayImage(binaryImage);
return true;
}该代码实际上非常简单,以下步骤用于检测和绘制线条:
我们首先处理,如果用户单击菜单项但未加载图像:
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}然后,我们初始化一个新的Mat对象,并将加载的图像从全彩色空间转换为灰度空间。 最后,我们调用Imgproc.Canny()将灰度图像转换为仅显示边缘的二进制图像:
Mat binaryImage=new Mat();
Imgproc.cvtColor(sampledImage, binaryImage, Imgproc.COLOR_RGB2GRAY);
Imgproc.Canny(binaryImage, binaryImage, 80, 100);下一步是调用Imgproc.HoughLinesP(),它是原始霍夫变换方法的概率版本,并传入以下参数:
- 一个
Mat对象,代表加载图像的二进制图像版本 - 一个
Mat对象,用于将检测到的线保留为参数x_start, y_start, x_end, y_end - 参数
ρ的分辨率(以像素为单位)的倍数; 在我们的例子中,我们将其设置为一个像素 - 参数
θ的弧度分辨率的双精度; 在我们的情况下,我们将其设置为 1 度(pi / 180) - 累加器阈值的整数,仅返回具有足够投票的行
注意
通常,当使用霍夫变换的概率版本时,您将使用较小的阈值,因为该算法用于最小化用于投票的点数。 但是,在标准的霍夫变换中,应使用更大的阈值。
以下是代码:
Mat lines = new Mat();
int threshold = 50;
Imgproc.HoughLinesP(binaryImage, lines, 1, Math.PI/180, threshold);最后,我们将二进制图像转换为完整的色彩空间以显示检测到的线条,然后在检测到的线条上循环并使用参数逐一绘制它们,x_start, y_start, x_end, y_end:
Imgproc.cvtColor(binaryImage, binaryImage, Imgproc.COLOR_GRAY2RGB);
for (int i = 0; i < lines.cols(); i++)
{
double[] line = lines.get(0, i);
double xStart = line[0],
yStart = line[1],
xEnd = line[2],
yEnd = line[3];
org.opencv.core.Point lineStart = new org.opencv.core.Point(xStart, yStart);
org.opencv.core.Point lineEnd = new org.opencv.core.Point(xEnd, yEnd);
Core.line(binaryImage, lineStart, lineEnd, new Scalar(0,0,255), 3);
}
displayImage(binaryImage);您可以在以下输入图像中在网格中记录检测到的霍夫线:
从边缘图像检测到的粗线(蓝色)
使用霍夫变换检测圆
OpenCV 为提供了霍夫变换的另一种实现,但是这次,我们没有检测线,而是按照将x, y空间转换为参数空间的相同思想来检测圆。
对于圆的方程r² = (x - a)² + (y - b)²,我们有三个参数r, a, b,其中a和b分别是圆在x和y方向上的中心 ,r是半径。
现在,参数空间是三维的,属于该圆的每个边缘点都将在此三维空间中投票,然后我们在参数空间中搜索最大值以检测圆的中心和半径。
此过程非常,占用大量内存和计算量,并且三维空间将非常稀疏。 好消息是,OpenCV 使用称为霍夫梯度法的方法实现了圆形霍夫变换。
霍夫梯度法的工作方式如下:对于第一步,我们应用边缘检测器,例如 Canny 边缘检测器。 在第二步中,我们为每个边缘像素沿梯度方向递增累加器单元(二维空间)。 直观地,如果我们遇到一个圆,则具有较高投票权的累加单元实际上是该圆的中心。 现在我们已经建立了一个潜在中心的列表,我们需要找到圆的半径。 因此,对于每个中心,我们通过根据边缘像素到中心的距离对边缘像素进行排序来考虑边缘像素,并保持最大边缘像素数量支持(投票)的单个半径:
UI 定义
为了触发圆形霍夫变换,我们将一个菜单项添加到现有菜单中。 转到res/menu/soft_scanner.xml文件并打开它以包含以下菜单项:
<item android:id="@+id/action_CHT"
android:enabled="true"
android:visible="true"
android:title="@string/action_CHT">
</item>检测和绘制圆
检测圆的过程与检测线的过程非常相似:
- 加载感兴趣的图像。
- 将其从全彩色空间转换为灰度空间。
- 在灰度图像上调用圆形霍夫变换方法。
- 画出检测到的圆圈。
我们编辑onOptionsItemSelected()以处理圆霍夫变换的情况:
else if(id==R.id.action_CHT)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat grayImage=new Mat();
Imgproc.cvtColor(sampledImage, grayImage, Imgproc.COLOR_RGB2GRAY);
double minDist=20;
int thickness=5;
double cannyHighThreshold=150;
double accumlatorThreshold=50;
Mat circles = new Mat();
Imgproc.HoughCircles(grayImage, circles, Imgproc.CV_HOUGH_GRADIENT, 1, minDist,cannyHighThreshold,accumlatorThreshold,0,0);
Imgproc.cvtColor(grayImage, grayImage, Imgproc.COLOR_GRAY2RGB);
for (int i = 0; i < circles.cols(); i++)
{
double[] circle = circles.get(0, i);
double centerX = circle[0],
centerY = circle[1],
radius = circle[2];
org.opencv.core.Point center = new org.opencv.core.Point(centerX, centerY);
Core.circle(grayImage, center, (int) radius, new Scalar(0,0,255),thickness);
}
displayImage(grayImage);
return true;
}圆霍夫变换的代码与一样,用于检测线,以下部分除外:
double minDist=20;
int thickness=5;
double cannyHighThreshold=150;
double accumlatorThreshold=50;
Mat circles = new Mat();
Imgproc.HoughCircles(grayImage, circles, Imgproc.CV_HOUGH_GRADIENT, 1, minDist,cannyHighThreshold,accumlatorThreshold,0,0);
Imgproc.cvtColor(grayImage, grayImage, Imgproc.COLOR_GRAY2RGB);
for (int i = 0; i < circles.cols(); i++)
{
double[] circle = circles.get(0, i);
double centerX = circle[0],
centerY = circle[1],
radius = circle[2];
org.opencv.core.Point center = new org.opencv.core.Point(centerX, centerY);
Core.circle(grayImage, center, (int) radius, new Scalar(0,0,255),thickness);
}我们通过调用Imgproc.HoughCircles()并将以下参数传递给它来检测圆:
- 一个
Mat对象,表示 8 位单通道灰度输入图像。 - 一个
Mat对象,将保存检测到的圆。 矩阵的每一列将包含一个由这些参数x, y, r表示的圆。 - 检测方法的整数。 当前,OpenCV 仅实现霍夫梯度算法。
- 用于的双精度数设置累加器和输入图像大小之间的比率。 例如,如果我们传递
1,则累加器将具有与输入图像相同的大小(宽度和高度)。 如果我们通过3,则累加器大小将为输入图像的三分之一。 - 检测到的圆心之间的最小距离的两倍值。 请注意,距离越大,您将错过的真实圆圈越多; 距离越短,您将检测到的假圆圈越多。
- 用于内部 Canny 边缘检测器上限阈值的 double 值; 下限阈值将是上限阈值的一半。
- 累加器阈值的两倍,表示每个检测到的中心的票数。
- 我们正在寻找的最小半径的整数; 如果您不知道,则可以通过
0。 - 要检测的最大半径的整数; 如果未知,则通过
0。
最后,我们循环检测到的圆并使用Core.circle()逐一绘制。
总结
在本章中,我们介绍了空间滤波的概念,并展示了从降噪到边缘检测在卷积核中的不同应用。 我们已经看到了如何使用 OpenCV 通过平均,高斯和中值过滤器来平滑图像。 我们还将 OpenCV 实现用于 Sobel 和 Canny 边缘检测器。 除了图像平滑和边缘检测之外,我们还介绍了一种称为霍夫变换的著名形状分析技术,以使线条和圆适合边缘像素。
在下一章中,我们将继续开发该应用,以便使用这些概念来检测边缘和拟合线以找到适当的变换并进行一些透视校正,从而使我们使用设备的摄像头捕获的文档看起来像是被扫描的。
四、应用 2-应用透视校正
在本章中,我们将继续在第 3 章, “App 2:软件扫描程序”中启动的应用为基础。
我们将使用已经讨论过的概念(即边缘检测和霍夫线变换)对四边形对象进行透视校正。 将透视变换应用于对象将改变我们观察对象的方式。 当您为文档,收据等拍照时,如果您想更好地查看捕获的图像或类似扫描的副本,此想法将派上用场。
我们将看到如何使用三种不同的方式来实现这个想法:
- 刚性透视校正
- 灵活的透视校正
- 手动透视校正
图像变换和透视校正
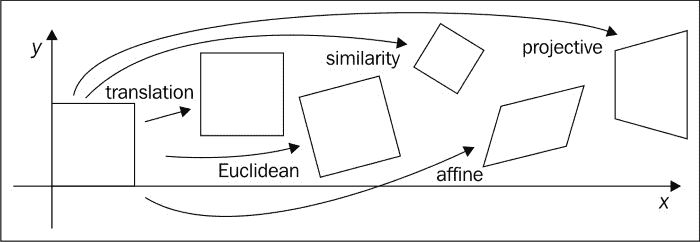
图像可以经过一系列转换。 最简单的列出在这里。
平移
基本上,在图像坐标平移中,我们要做的是将每个像素移位p = [x, y],其量为t = [t[x], t[y]]。 例如,我们可以将像素p的转换写为p' = p + t。
旋转和平移
在此转换中,我们将旋转应用于每个像素,然后进行平移。 由于保留了欧几里得距离,因此该变换也称为二维欧几里得变换。
我们可以将此变换写为p' = Rp + t,其中R是2×2矩阵,等于R = [cosθ, -sinθ; sinθ, cosθ],θ是旋转角度。
缩放旋转
这也称为,称为相似性变换,在此变换中,我们添加了比例因子s,以便可以将变换表示为p' = sRp + t。 此变换将保留线之间的角度。
仿射
在仿射转换中,平行线保持平行,并且可以表示为p' = Ap*,其中p* = [x, y, 1]和A = [a, b, c; d, e, f]。
透视变换
这也称为,称为投影变换,在此变换中,我们使用3×3矩阵而不是2×3矩阵来更改像素的视点。 仿射变换和透视变换之间的主要区别是后者不保留平行线,而仅保留其直线性。
有人可以说,透视校正的主要思想是找到一个透视变换矩阵,该矩阵可以应用于图像以获得对感兴趣对象的更好观察。
要找到此矩阵,我们首先需要使用我们在第 3 章, “App 2:软件扫描程序”中讨论的想法来检测感兴趣的对象,选择一组兴趣点,然后指定这些兴趣点的位置,以便更好地查看对象。
这一组点的一个示例可能是对象角,如果我们找到一个透视变换矩阵来将这些角的坐标更改为与设备屏幕的角相对应的,我们将获得类似扫描的视图 。
根据前面的示例,我们将讨论透视校正的三种方式,并演示找到这些角的不同方法,以建立所需的对应关系以找到合适的透视变换矩阵。
刚性透视校正
我们进行透视校正的第一个试验将是一成不变的尝试。 我们将按照以下步骤操作:
- 将输入图像转换为灰度。
- 使用 Canny 边缘检测器获取边缘图像。
- 使用概率霍夫变换检测边缘图像中的线条。
- 找到感兴趣对象的边界线。
- 估计感兴趣对象的边界矩形; 因此,之所以称为刚性是因为对象不需要具有平行的相对边,但是我们将通过对四边形对象使用矩形估计来强制执行此操作。
- 建立一个矩形的四个角的列表。
- 在矩形角和屏幕角之间施加对应关系。
- 使用对应关系获得透视变换矩阵。
- 将变换矩阵应用于输入图像,以获取感兴趣对象的校正透视图。
UI 定义
我们将添加附加菜单项以开始透视校正过程。 转到res/menu/soft_scanner.xml文件并打开它以包含以下菜单项:
<item
android:id="@+id/action_rigidscan"
android:enabled="true"
android:orderInCategory="6"
android:title="@string/action_rigidscan"
android:visible="true">
</item>使用对象边界框估计透视变换
在活动中,我们需要编辑onOptionesItemSelected()方法并通过选择刚性扫描选项来添加新的案例来处理用户。
第一步是确保用户已经加载了图像:
else if(id==R.id.action_rigidscan)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}将输入图像转换为灰度图像:
Mat gray = new Mat();
Imgproc.cvtColor(sampledImage, gray, Imgproc.COLOR_RGB2GRAY);使用 Canny 边缘检测器构建边缘图像:
Mat edgeImage=new Mat();
Imgproc.Canny(gray, edgeImage, 100, 200);构建边缘图像后,我们需要检测线,因此我们使用概率霍夫线变换:
Mat lines = new Mat();
int threshold = 50;
Imgproc.HoughLinesP(edgeImage, lines, 1, Math.PI/180, threshold,60,10);声明并初始化所需的变量,以找到感兴趣的对象的最多四条边界线,并丢弃在对象本身上检测到的所有线,以便更好地估计边界矩形:
boolean [] include=new boolean[lines.cols()];
double maxTop=edgeImage.rows();
double maxBottom=0;
double maxRight=0;
double maxLeft=edgeImage.cols();
int leftLine=0;
int rightLine=0;
int topLine=0;
int bottomLine=0;
ArrayList<org.opencv.core.Point> points=new ArrayList<org.opencv.core.Point>();在下面的for循环中,我们测试每一行以找到感兴趣对象的最左侧边界线。 找到后,我们将其对应的include数组元素设置为true,以避免在搜索其他边界线时再次选择同一条线:
for (int i = 0; i < lines.cols(); i++)
{
double[] line = lines.get(0, i);
double xStart = line[0], xEnd = line[2];
if(xStart<maxLeft && !include[i])
{
maxLeft=xStart;
leftLine=i;
}
if(xEnd<maxLeft && !include[i])
{
maxLeft=xEnd;
leftLine=i;
}
}
include[leftLine]=true;找到线后,我们将其两个点添加到points数组列表中。 稍后我们估计边界矩形时,将使用此数组列表:
double[] line = lines.get(0, leftLine);
double xStartleftLine = line[0],
yStartleftLine = line[1],
xEndleftLine = line[2],
yEndleftLine = line[3];
org.opencv.core.Point lineStartleftLine = new org.opencv.core.Point(xStartleftLine, yStartleftLine);
org.opencv.core.Point lineEndleftLine = new org.opencv.core.Point(xEndleftLine, yEndleftLine);
points.add(lineStartleftLine);
points.add(lineEndleftLine);我们执行相同的操作来找到最右边的边界线:
for (int i = 0; i < lines.cols(); i++)
{
line = lines.get(0, i);
double xStart = line[0], xEnd = line[2];
if(xStart>maxRight && !include[i])
{
maxRight=xStart;
rightLine=i;
}
if(xEnd>maxRight && !include[i])
{
maxRight=xEnd;
rightLine=i;
}
}
include[rightLine]=true;将属于最右边边界线的点添加到points数组列表中:
line = lines.get(0, rightLine);
double xStartRightLine = line[0],
yStartRightLine = line[1],
xEndRightLine = line[2],
yEndRightLine = line[3];
org.opencv.core.Point lineStartRightLine = new org.opencv.core.Point(xStartRightLine, yStartRightLine);
org.opencv.core.Point lineEndRightLine = new org.opencv.core.Point(xEndRightLine, yEndRightLine);
points.add(lineStartRightLine);
points.add(lineEndRightLine);找到顶部边界线:
```java
for (int i = 0; i < lines.cols(); i++)
{
line = lines.get(0, i);
double yStart = line[1],yEnd = line[3];
if(yStart<maxTop && !include[i])
{
maxTop=yStart;
topLine=i;
}
if(yEnd<maxTop && !include[i])
{
maxTop=yEnd;
topLine=i;
}
}
include[topLine]=true;
```- 将属于顶部边界线的点添加到
points数组列表中:
```java
line = lines.get(0, topLine);
double xStartTopLine = line[0],
yStartTopLine = line[1],
xEndTopLine = line[2],
yEndTopLine = line[3];
org.opencv.core.Point lineStartTopLine = new org.opencv.core.Point(xStartTopLine, yStartTopLine);
org.opencv.core.Point lineEndTopLine = new org.opencv.core.Point(xEndTopLine, yEndTopLine);
points.add(lineStartTopLine);
points.add(lineEndTopLine);
```- 找到底边框:
```java
for (int i = 0; i < lines.cols(); i++)
{
line = lines.get(0, i);
double yStart = line[1],yEnd = line[3];
if(yStart>maxBottom && !include[i])
{
maxBottom=yStart;
bottomLine=i;
}
if(yEnd>maxBottom && !include[i])
{
maxBottom=yEnd;
bottomLine=i;
}
}
include[bottomLine]=true;
```- 将底线点添加到
points数组列表中:
```java
line = lines.get(0, bottomLine);
double xStartBottomLine = line[0],
yStartBottomLine = line[1],
xEndBottomLine = line[2],
yEndBottomLine = line[3];
org.opencv.core.Point lineStartBottomLine = new org.opencv.core.Point(xStartBottomLine, yStartBottomLine);
org.opencv.core.Point lineEndBottomLine = new org.opencv.core.Point(xEndBottomLine, yEndBottomLine);
points.add(lineStartBottomLine);
points.add(lineEndBottomLine);
```- 我们使用从检测到的边界线中选择的点列表来初始化点矩阵
MatOfPoint2f对象:
```java
MatOfPoint2f mat=new MatOfPoint2f();
mat.fromList(points);
```- 我们通过调用
Imgproc.minAreaRect()并传入我们先前初始化的点的矩阵来找到边界矩形。 该函数尝试找到适合一组点并具有所有可能矩形的最小面积的矩形。 当我们使用感兴趣对象的边界线上的点时,我们将获得该对象的边界矩形:
```java
RotatedRect rect= Imgproc.minAreaRect(mat);
```- 现在,我们将估计矩形的四个角点提取到点数组中:
```java
org.opencv.core.Point rect_points[]=new org.opencv.core.Point [4];
rect.points(rect_points);
```- 进行透视校正后,初始化将用于显示感兴趣对象的新图像。 我们还将使用该图像的四个角找到变换,以最小化这些角与相应的感兴趣对象的角之间的距离。 因此,基本上,我们试图做的是找到一个转换(缩放,旋转或平移),该转换将使感兴趣对象的四个角尽可能接近新初始化图像的四个角。
```java
Mat correctedImage=new Mat(sampledImage.rows(),sampledImage.cols(),sampledImage.type());
```- 现在,我们初始化两个
Mat对象,一个用于存储感兴趣对象的四个角,另一个用于存储图像的相应角,在透视校正后我们将在其中显示感兴趣的对象:
```java
Mat srcPoints=Converters.vector_Point2f_to_Mat(Arrays.asList(rect_points));
Mat destPoints=Converters.vector_Point2f_to_Mat(Arrays.asList(new org.opencv.core.Point[]{
new org.opencv.core.Point(0, correctedImage.rows()),
new org.opencv.core.Point(0, 0),
new org.opencv.core.Point(correctedImage.cols(),0),
new org.opencv.core.Point(correctedImage.cols(), correctedImage.rows())
}));
```- 我们通过调用
Imgproc.getPerspectiveTransform()并将其传递到源和目标角点来计算所需的转换矩阵:
```java
Mat transformation=Imgproc.getPerspectiveTransform(srcPoints, destPoints);
```最后,我们应用通过Imgproc.warpPerspective()方法并传递以下参数计算出的变换:
* 源图像的Mat对象; 在这种情况下,就是包含感兴趣对象的图像
* 输出图像的Mat对象
* 我们要应用的转换的Mat对象
* 一个Size对象,用于保存输出图像的大小
Imgproc.warpPerspective(sampledImage, correctedImage, transformation, correctedImage.size());最后一步是在应用适当的转换后显示我们感兴趣的对象:
```java
displayImage(correctedImage);
```

转换之前(左)和之后(右)灵活的透视校正
现在,我们已经执行了刚性校正,我们希望获得更好的结果。 如前所述,使用透视校正的主要原因是找到感兴趣对象的四个角点。 在“刚性透视校正”部分中,我们使用估计的边界矩形找到感兴趣对象的角; 但是,如您所知,矩形的每个相对侧都是平行的,这可能会降低透视校正的结果,因为现实世界中的平行线在投影时必须在称为图片平面的消失点的地方相交。
因此,使用平行线估计角点不是我们的最佳选择,我们可以通过将投影线(从霍夫变换中找到的投影线)保持在图片中并使用简单的几何图形找到它们之间的交点来做得更好,以便找到四个角落。
我们将执行的步骤如下:
- 使用高斯过滤器将输入图像转换为灰度和平滑。
- 使用 Canny 边缘检测器找到边缘图像。
- 使用概率性霍夫线变换来找到感兴趣对象的边缘线。
- 通过计算所有检测到的线之间的交点,找到边缘图像中的每个角。
- 使用上一步中找到的角(顶点)来近似另一个多边形。 必须执行此步骤以最大程度减少顶点数量,从而消除无用的角。 但是,我们仍然保持与原始多边形相同的结构。
- 现在我们有了代表感兴趣对象的最小角集,我们需要对它们进行排序,以使左上角首先出现,然后是右上角,右下角,最后是左下角。
- 在排序的角和屏幕角之间强加一个对应关系。
- 使用对应关系获得透视变换矩阵。
- 将变换矩阵应用于输入图像以获取感兴趣对象的校正透视图。
UI 定义
我们将使用一个菜单来启动灵活的透视校正过程。 转到res/menu/soft_scanner.xml文件并打开它以包含以下菜单项:
<item
android:id="@+id/action_flexscan"
android:enabled="true"
android:orderInCategory="7"
android:title="@string/action_flexscan"
android:visible="true">
</item>应用灵活的透视校正
在SoftScanner 活动中,我们需要编辑onOptionesItemSelected()方法并为灵活扫描添加新的大小写:
第一步是确保用户加载了图像:
else if(id==R.id.action_flexscan)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}我们遵循与“刚性透视校正”分相同的步骤来获取边线:
Mat gray = new Mat();
Imgproc.cvtColor(sampledImage, gray, Imgproc.COLOR_RGB2GRAY);
Imgproc.GaussianBlur(gray, gray, new Size(7,7), 0);
Mat edgeImage=new Mat();
Imgproc.Canny(gray, edgeImage, 100, 300);
Mat lines = new Mat();
int threshold = 100;
Imgproc.HoughLinesP(edgeImage, lines, 1, Math.PI/180, threshold,60,10);我们使用公式:
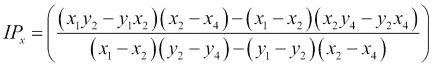
和:
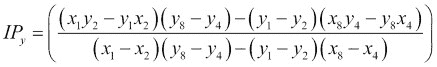
ArrayList<org.opencv.core.Point> corners=new ArrayList<org.opencv.core.Point>();
for (int i = 0; i < lines.cols(); i++)
{
for (int j = i+1; j < lines.cols(); j++)
{
org.opencv.core.Point intersectionPoint = getLinesIntersection(lines.get(0, i), lines.get(0, j));
if(intersectionPoint!=null)
{
corners.add(intersectionPoint);
}
}
}现在我们有了交点,我们需要找到另一个与检测到的多边形具有相同结构但顶点更少的多边形。 为此,我们使用Imgproc.approxPolyDP()方法,并将以下参数传递给它:
一个Mat对象,用于存储我们找到的角列表。
一个Mat对象,它将存储近似多边形的新顶点。
代表原始多边形和近似多边形之间最大距离的双精度数。 在这种情况下,我们使用Imgproc.arcLength()方法计算原始多边形的周长,然后将其乘以一个小因子0.02,然后使用结果设置两个形状之间的最大距离。
一个布尔值,指示形状是否闭合,在我们的示例中为:
MatOfPoint2f cornersMat=new MatOfPoint2f();
cornersMat.fromList(corners);
MatOfPoint2f approxConrers=new MatOfPoint2f();
Imgproc.approxPolyDP(cornersMat, approxConrers, Imgproc.arcLength(cornersMat, true)*0.02, true);在此步骤中,我们只需确保近似的多边形至少具有四个角:
if(approxConrers.rows()<4)
{
Context context = getApplicationContext();
CharSequence text = "Couldn't detect an object with four corners!";
int duration = Toast.LENGTH_LONG;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}我们将近似角复制到角列表中,然后使用此列表查找多边形质心,将用于对近似角点进行排序。 良好的质心近似值是所有近似角点的平均值。
corners.clear();
Converters.Mat_to_vector_Point2f(approxConrers,corners);
org.opencv.core.Point centroid=new org.opencv.core.Point(0,0);
for(org.opencv.core.Point point:corners)
{
centroid.x+=point.x;
centroid.y+=point.y;
}
centroid.x/=corners.size();
centroid.y/=corners.size();现在,我们开始根据多边形质心对角点进行排序。 我们首先将它们分成两个列表,一个列表将保留 Y 坐标小于质心的顶角,第二个列表将 Y 坐标大于质心的底角。 然后,我们根据上角列表中的 X 坐标对左上角和右上角进行排序,并对底部列表进行相同操作:
ArrayList<org.opencv.core.Point> top=new ArrayList<org.opencv.core.Point>();
ArrayList<org.opencv.core.Point> bottom=new ArrayList<org.opencv.core.Point>();
for (int i = 0; i < corners.size(); i++)
{
if (corners.get(i).y < center.y)
top.add(corners.get(i));
else
bottom.add(corners.get(i));
}
org.opencv.core.Point topLeft = top.get(0).x > top.get(1).x ? top.get(1) : top.get(0);
org.opencv.core.Point topRight = top.get(0).x > top.get(1).x ? top.get(0) : top.get(1);
org.opencv.core.Point bottomLeft = bottom.get(0).x > bottom.get(1).x ? bottom.get(1) :bottom.get(0);
org.opencv.core.Point bottomRight = bottom.get(0).x > bottom.get(1).x ? bottom.get(0) : bottom.get(1);
corners.clear();
corners.add(topLeft);
corners.add(topRight);
corners.add(bottomRight);
corners.add(bottomLeft);然后,像在“刚性透视校正”部分中所做的那样,我们建立排序的角和图像角之间的对应关系:
Mat correctedImage=new Mat(sampledImage.rows(),sampledImage.cols(),sampledImage.type());
Mat srcPoints=Converters.vector_Point2f_to_Mat(corners);
Mat destPoints=Converters.vector_Point2f_to_Mat(Arrays.asList(new org.opencv.core.Point[]{
new org.opencv.core.Point(0, 0),
new org.opencv.core.Point(correctedImage.cols(), 0),
new org.opencv.core.Point(correctedImage.cols(),correctedImage.rows()),new org.opencv.core.Point(0,correctedImage.rows())}));我们通过调用Imgproc.getPerspectiveTransform()并将其传递到源和目标角点来计算所需的变换矩阵:
Mat transformation=Imgproc.getPerspectiveTransform(srcPoints, destPoints);我们应用通过Imgproc.warpPerspective()方法计算出的变换:
```java
Imgproc.warpPerspective(sampledImage, correctedImage, transformation, correctedImage.size());
```- 最后,在应用适当的转换后,我们显示感兴趣的对象:
```java
displayImage(correctedImage);
```
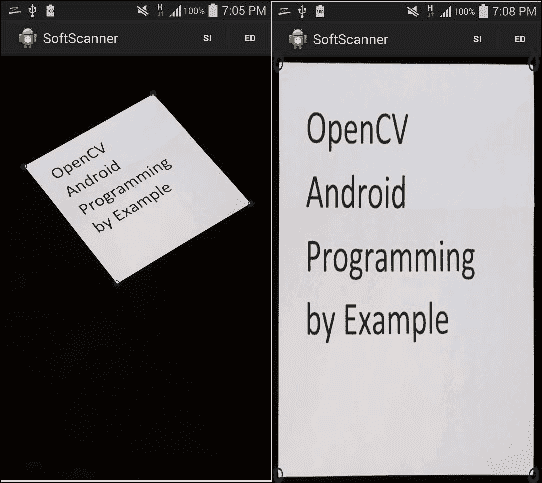
转换之前(左)和之后(右)手动透视校正
我们可以包括的另一个选择是利用设备的触摸屏,并使用户手动选择感兴趣对象的角。 如果背景噪声过多并且自动透视校正未提供所需的结果,则此选项可能会派上用场。
我们将遵循的步骤与“刚性透视校正”部分中所看到的非常相似:
- 让用户选择感兴趣对象的四个角。
- 找到对象质心。
- 根据对象质心对选择的角进行排序。
- 在排序的角和屏幕角之间强加一个对应关系。
- 使用对应关系获得透视变换矩阵。
- 将变换矩阵应用于输入图像,以获取感兴趣对象的校正透视图。
UI 定义
用户选择四个角后,我们将再添加一个菜单项来触发手动过程。 转到res/menu/soft_scanner.xml文件并打开它以包含以下菜单项:
<item
android:id="@+id/action_manScan"
android:enabled="true"
android:orderInCategory="8"
android:title="@string/action_manscan"
android:visible="true">
</item>手动选择角点
用户选择感兴趣的角点后,我们将遵循相同的过程。 但是,技巧是将设备屏幕上选择的坐标映射到感兴趣对象的坐标:
在活动onCreate()方法中,我们将onTouch()事件处理器附加到ImageView。 在事件处理器中,我们首先使用用于显示加载图像的比例因子,将ImageView中所选角的坐标投影到加载图像。 在加载的图像上获得正确的坐标后,以下步骤将与之前相同:
final ImageView iv = (ImageView) findViewById(R.id.SSImageView);
iv.setOnTouchListener(new OnTouchListener() {
@Override
public boolean onTouch(View view, MotionEvent event) {
int projectedX = (int)((double)event.getX() * ((double)sampledImage.width()/(double)view.getWidth()));
int projectedY = (int)((double)event.getY() * ((double)sampledImage.height()/(double)view.getHeight()));
org.opencv.core.Point corner = new org.opencv.core.Point(projectedX, projectedY);
corners.add(corner);
Core.circle(sampledImage, corner, (int) 5, new Scalar(0,0,255),2);
displayImage(sampledImage);
return false;
}
}); 我们需要确保用户加载了图像并选择了四个角:
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
if(corners.size()!=4)
{
Context context = getApplicationContext();
CharSequence text = "You need to select four corners!";
int duration = Toast.LENGTH_LONG;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}计算对象质心并相应地对四个角进行排序:
org.opencv.core.Point centroid=new org.opencv.core.Point(0,0);
for(org.opencv.core.Point point:corners)
{
centroid.x+=point.x;
centroid.y+=point.y;
}
centroid.x/=corners.size();
centroid.y/=corners.size();
sortCorners(corners,centroid);然后,像在“刚性透视校正”部分:
Mat correctedImage=new Mat(sampledImage.rows(),sampledImage.cols(),sampledImage.type());
Mat srcPoints=Converters.vector_Point2f_to_Mat(corners);
Mat destPoints=Converters.vector_Point2f_to_Mat(Arrays.asList(new org.opencv.core.Point[]{
new org.opencv.core.Point(0, 0),
new org.opencv.core.Point(correctedImage.cols(), 0),
new org.opencv.core.Point(correctedImage.cols(),correctedImage.rows()),
new org.opencv.core.Point(0,correctedImage.rows())}));中所做的那样,构建排序后的角点与图像角点之间的对应关系。
我们通过调用Imgproc.getPerspectiveTransform()并将其传递到源和目标角点来计算所需的变换矩阵:
Mat transformation=Imgproc.getPerspectiveTransform(srcPoints, destPoints);我们应用通过Imgproc.warpPerspective()方法计算出的变换:
Imgproc.warpPerspective(sampledImage, correctedImage, transformation, correctedImage.size());最后,我们在应用了适当的变换后显示了我们感兴趣的对象:
displayImage(correctedImage);总结
我们已经看到了如何使用透视变换来更改图像中对象的视图。 我们演示了关于四边形对象的想法,并讨论了进行透视校正的三种不同方法。
在下一章中,我们将探讨不同类型的图像特征,以及如何找到它们以及它们为何重要。
五、应用 3-全景查看器
在本章中,我们将开始开发新的应用。 该应用的目标是将两个图像拼接在一起以形成全景视图。 我们将介绍图像特征的概念及其重要性,然后将它们付诸实践。
我们可以总结如下主题:
- 特征检测
- 特征说明
- 特征匹配
- 图像拼接
图像特征
在本节中,我们将了解图像特征的含义以及它们为何重要的原因。
想象一下,遇见一个人并立即检测到该人的脸(眼睛,鼻子和许多其他人脸特征)的情况。 问题是我们该怎么做? 我们检测这些人脸特征所遵循的算法是什么? 我们如何描述它们? 此外,当我们看到另一个具有相同人脸特征的人时,我们可以轻松地发现两个人之间的匹配特征。 我们用来衡量这种相似性的指标是什么?
我们仅遵循检测,描述和匹配特征的过程。 从计算机的角度来看,我们希望该过程能够找到可以重复提取,充分表示和准确匹配的特征。
这些特征被认为是良好的特征,要衡量特征的优劣,我们应考虑其鲁棒性和不变性(尤其是缩放和旋转不变性;例如,我们的人脸特征(例如眼睛)不变) 脸部比例;无论脸是大还是小,您都可以轻松检测到眼睛在哪里)。 通常,为了实现这种鲁棒性,我们将检测到的特征的质量属性与用于描述特征的方法的质量属性结合起来考虑。
例如,我们将看到一些特征检测器,即哈里斯和 FAST,以单尺度(单尺度)查找特征,而其他特征检测器(例如 ORB)通过构建所谓的尺度空间,在多尺度上查找特征。
我发现这是一个很好的机会,它介绍了比例尺空间的基本概念,即使用不同的比例尺缩小方法来构建图像金字塔。 最简单的方法是删除 X 和 Y 方向上的所有其他像素。 因此,例如,如果您有一个100x100的图像,则从 x 和 y 中删除所有其他像素将生成100x100的图像。 您一直重复此步骤,直到达到程序可以使用的最小可接受范围。

特征检测器
首先要问的是,在计算机视觉的背景下,哪些特征是好的特征? 为了回答这个问题,让我们以山顶的图像为例。 我们可以开始查看这座山脉(矩形 2)边界内的特征,但是问题是无法重复找到或无法充分描述这些特征,因此它们将很难匹配。
另一个要寻找的候选人是山的边缘。 我们已经在第 3 章,“应用 2-软件扫描程序”中学习了如何检测边缘,因此可以轻松找到这种类型的特征。 但是,问题在于如何唯一地描述它们,因为如果查看矩形 1.1 和 1.2,您很容易将它们混淆为同一条边。 这个问题被称为孔径问题,同样,将很难匹配。
矩形 3 呢? 这个矩形看起来是一个不错的选择,因为如果您沿任何方向移动它,它下面的区域都会看起来不同,因此是唯一的。 基于此,我们可以说转角是要考虑的好特征。
了解哈里斯角点检测器
我们回答了哪些特征是好的特征的问题,并给出了一个好的特征的示例。 现在,我们需要找到一种方法来轻松检测它们。 因此,让我们考虑山顶图像。 如果我们开始使用正方形窗口扫描图像,则角落将具有最大的强度变化,因为与边缘不同,两个正交方向将发生变化,而边缘仅沿一个方向(x 或 y)发生变化 。
这是哈里斯角点探测器背后的基本思想。 我们试图找到一个补丁,如果我们在该补丁内以不同的方向移动扫描窗口,它将在强度上产生最大的变化或变化。
哈里斯角检测器是旋转不变的。 但是,它不是尺度不变的。
UI 定义
创建具有空白活动PanoActivity的新应用并添加从设备库加载图像的功能以及加载 OpenCV 库之后,我们将在菜单项中添加第一个菜单项,来在加载的图片上执行哈里斯角点检测器。 转到res/menu/pano.xml文件并打开它以包含以下菜单项:
<itemandroid:id="@+id/action_harris"
android:orderInCategory="2"
android:title="@string/action_harris">
</item>使用哈里斯角点检测器
OpenCV 为您提供了不同的兴趣点或特征检测器,并且该 API 具有非常简单的接口,可用于类org.opencv.features2d。 FeatureDetector具有工厂方法,并且给定检测器 ID,该工厂方法将返回与此 ID 对应的特征检测器的实例。
我们更新onOptionsItemSelected以处理哈里斯菜单项:
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat greyImage=new Mat();
MatOfKeyPoint keyPoints=new MatOfKeyPoint();
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);
FeatureDetector detector = FeatureDetector.create(FeatureDetector.HARRIS);
detector.detect(greyImage, keyPoints);
Features2d.drawKeypoints(greyImage, keyPoints, greyImage);
displayImage(greyImage);步骤非常简单,如下所示:
我们首先将输入图像转换为灰度并实例化关键点对象的矩阵:
Mat greyImage=new Mat();
MatOfKeyPoint keyPoints=new MatOfKeyPoint();
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);我们使用FeatureDetector.create工厂方法实例化我们选择的特征检测器,并传递其 ID:
FeatureDetector detector = FeatureDetector.create(FeatureDetector.HARRIS);使用以下命令调用detect方法:
detector.detect(greyImage, keyPoints);调用detect方法以查找具有以下参数的兴趣点:
- 代表输入图像的
Mat对象 MatOfKeyPoint对象,用于存储检测到的兴趣点
为了显示检测到的兴趣点,我们调用Feature2d.drawKeypoints():
Features2d.drawKeypoints(greyImage, keyPoints, greyImage);我们使用以下参数调用Feature2d.drawKeypoints():
- 作为输入图像的
Mat对象 - 要绘制的
MatOfKeyPoint - 输出图像的
Mat对象
最后,显示检测到兴趣点的图像:
displayImage(greyImage);调用本地哈里斯角点检测器
在许多情况下,您的应用将需要实时响应,例如检测手机摄像头的视频源中的特征。 仅依靠 Java 调用可能无法提供所需的表现,因此会错过最后期限。 在这种情况下,每秒超过 20 帧; 这就是为什么我觉得这是一个向您介绍本机 OpenCV API 的好机会。 您不需要熟悉 C++。 但是,了解语言结构将非常有帮助。
我们需要做的第一件事是在项目中添加 C++ 支持。
在 Eclipse 中使用本机 OpenCV 库
- 在项目浏览器中的项目名称上单击鼠标右键。
- 导航至新建 | 其他 | C/C++ | 转换为 C/C++ 项目。
- 选择“Makefile 项目”,选择“其他工具链”,然后单击“完成”:
- 定义环境变量
NDKROOT,指向 NDK 的主文件夹,例如C:\NVPACK\android-ndk-r10c。 - 在项目浏览器中的项目名称上单击鼠标右键,然后选择属性。
- 单击树节点 C/C++ 构建。 在构建器设置选项卡中,清除使用默认构建命令复选框,然后在构建命令文本框中输入以下内容:
${NDKROOT}/ndk-build.cmd。 - 转到“行为”选项卡,然后在“工作台构建行为”组中,选中“基于资源保存构建”,并清除“制作构建目标”文本框。 清除“构建(增量构建)”复选框的“制作构建目标”文本框:
- 此时,调用 NDK 生成项目将失败,并且要解决此问题,我们需要在项目文件夹下创建一个新文件夹,并将其命名为
jni。 - 在此文件夹中,我们将有三个文件:

-
Android.mk的内容应如下:
```java
LOCAL_PATH := $(call my-dir)
include$(CLEAR_VARS)
# Must include the opencv.mk file, change the path accordingly include C:\NVPACK\OpenCV-2.4.8.2-Tegra-sdk\sdk\native\jni\OpenCV-tegra3.mk
# Name the library and list the cpp source files
LOCAL_MODULE := Pano
LOCAL_SRC_FILES := Pano.cpp
LOCAL_LDLIBS += -llog -ldl
include$(BUILD_SHARED_LIBRARY)
```Application.mk的含量应如下:
```java
APP_PLATFORM := android-9
APP_ABI := armeabi-v7a
APP_STL := gnustl_static
APP_CPPFLAGS := -frtti -fexceptions
```- 对于
cpp文件,它可以为空,并且仅包含一个标题:
```java
#include <jni.h>
```- 生成项目。
- 我们需要包括一些目录,以便我们可以编写 C++ 代码并使用标准模板库(STL)和 OpenCV。 为此,请右键单击“项目名称 | 属性 | C/C++ 常规 | 路径和符号”。
### 注意
STL 为您提供了一组现成的类,它们实现了不同的数据结构和算法。- 选择 GNU C++,添加以下目录,然后根据您的安装更改路径:
```java
${NDKROOT}/platforms/android-9/arch-arm/usr/include
${NDKROOT}/sources/cxx-stl/gnu-libstdc++/4.6/include
${NDKROOT}/sources/cxx-stl/gnu-libstdc++/4.6/libs/ armeabi-v7a/include
C:\NVPACK\OpenCV-2.4.8.2-Tegra-sdk\sdk\native\jni\include
```在 Android Studio 中使用本机 OpenCV 库
在项目视图中,右键单击应用节点,然后选择打开模块设置或按F4。
选择“SDK 位置”。 在“Android NDK 位置”中,选择 NDK 所在的目录。 请注意,我们将使用实验性 Gradle 插件版本 2.5 来构建项目; 因此,我们需要 NDK 版本 r10e:
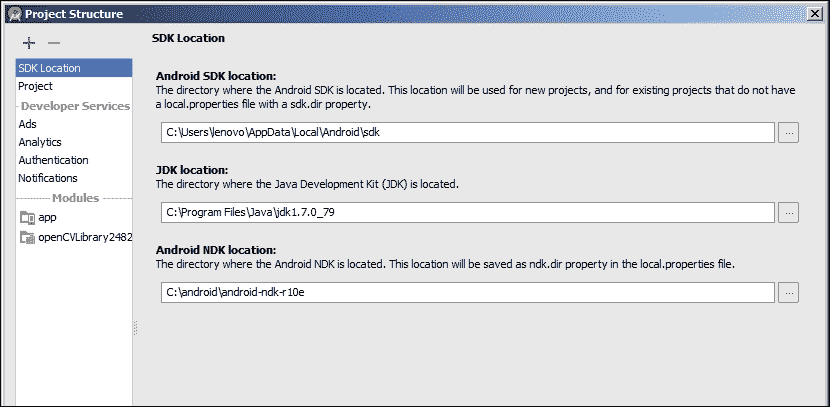
如果您使用的是 Android Studio 1.3.2,则需要更新gradle-wrapper.properties并更改分发 URL,如下所示:
distributionUrl=https\://services.gradle.org/distributions/gradle-2.5-all.zip在项目的build.gradle文件中,如下更新依赖项类路径:
dependencies {classpath 'com.android.tools.build:gradle-experimental:0.2.0'}在项目文件夹中,在app\src\main下创建两个文件夹jni和jniLibs。
在jni文件夹中,创建一个新文件,并将其命名为Pano.cpp。
现在,导航到<OpenCV4AndroidSDKFolder>\sdk\native\libs\,并将所有文件夹复制到新创建的jniLibs文件夹中。 您的项目树应如下所示:
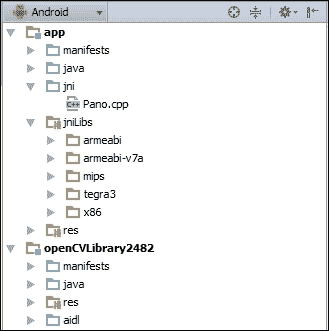
我们需要更新build.gradle中的领域特定语言(DSL),以便我们的模块可以与 Gradle 2.5 一起使用。 为此,请更新构建文件以使其与以下内容匹配,并保持依赖方法不变。 请注意,您将需要更新绝对路径以匹配您的安装:
applyplugin: 'com.android.model.application' model {
android {
compileSdkVersion = 23 buildToolsVersion = "23.0.1" defaultConfig.with {
applicationId = "com.app3.pano" minSdkVersion.apiLevel = 15 targetSdkVersion.apiLevel = 19 versionCode = 1 versionName = "1.0"
}
}
//Make sure to build with JDK version 7
compileOptions.with {
sourceCompatibility=JavaVersion.VERSION_1_7 targetCompatibility=JavaVersion.VERSION_1_7
}
android.ndk {
moduleName = "Pano" ldLibs += ['log']
cppFlags += "-std=c++11" cppFlags += "-fexceptions" cppFlags += "-I${file("<OpenCV4AndroidSDK_Home>/sdk/native/jni/include")}".toString()
cppFlags += "-I${file("<OpenCV4AndroidSDK_Home>/sdk/native/jni/include/opencv")}".toString()
ldLibs += ["android", "EGL", "GLESv2", "dl", "log", "z"]// , "ibopencv_core" stl = "gnustl_shared}
android.buildTypes {
release {
minifyEnabled= false proguardFiles+= file('proguard-rules.pro')
}
}
android.productFlavors {
create("arm") {
ndk.with {
abiFilters += "armeabi" File curDir = file('./')
curDir = file(curDir.absolutePath)
String libsDir = curDir.absolutePath+"\\src\\main\\jniLibs\\armeabi\\" //"-L" + ldLibs += libsDir + "libopencv_core.a" ldLibs += libsDir + "libopencv_imgproc.a" ldLibs += libsDir + "libopencv_java.so" ldLibs += libsDir + "libopencv_features2d.a"
}
}
create("armv7") {
ndk.with {
abiFilters += "armeabi-v7a" File curDir = file('./')
curDir = file(curDir.absolutePath)
String libsDir = curDir.absolutePath+"\\src\\main\\jniLibs\\armeabi-v7a\\" //"-L" + ldLibs += libsDir + "libopencv_core.a" ldLibs += libsDir + "libopencv_imgproc.a" ldLibs += libsDir + "libopencv_java.so" ldLibs += libsDir + "libopencv_features2d.a"
}
}
create("x86") {
ndk.with {
abiFilters += "x86"
}
}
create("mips") {
ndk.with {
abiFilters += "mips"
}
}
create("fat") {
}
}
}
}最后,我们需要为 OpenCV 模块更新build.gradle文件,以便与以下内容匹配:
apply plugin: 'com.android.model.library' model {
android {
compileSdkVersion = 23 buildToolsVersion = "23.0.1" defaultConfig.with {
minSdkVersion.apiLevel = 15 targetSdkVersion.apiLevel = 19
}
}
//Make sure to build with JDK version 7
compileOptions.with {
sourceCompatibility=JavaVersion.VERSION_1_7 targetCompatibility=JavaVersion.VERSION_1_7
}
android.buildTypes {
release {
minifyEnabled= false proguardFiles+= file('proguard-rules.pro')
}
}
}现在,同步并构建项目。
处理本机部分
无论您选择哪种 IDE ,都可以按照以下步骤将本机代码添加到应用中:
打开Pano.cpp并添加以下代码; 我们稍后将通过代码:
#include<jni.h>
#include<opencv2/core/core.hpp>
#include<opencv2/imgproc/imgproc.hpp>
#include<opencv2/features2d/features2d.hpp>
#include<vector>
extern"C" {
JNIEXPORT void JNICALL Java_com_app3_pano_PanoActivity_FindHarrisCorners(JNIEnv*, jobject, jlong addrGray, jlong addrRgba)
{
cv::Mat& mGr = *(cv::Mat*)addrGray;
cv::Mat& mRgb = *(cv::Mat*)addrRgba;
cv::Mat dst_norm;
cv::Mat dst = cv::Mat::zeros(mGr.size(),CV_32FC1);
//the size of the neighbor in which we will check
//the existence of a corner
int blockSize = 2;
//used for the Sobel kernel to detect edges before
//checking for corners
int apertureSize = 3;
// a free constant used in Harris mathematical formula
double k = 0.04;
//corners response threshold
float threshold=150;
cv::cornerHarris( mGr, dst, blockSize, apertureSize, k, cv::BORDER_DEFAULT );
cv::normalize( dst, dst_norm, 0, 255, cv::NORM_MINMAX, CV_32FC1, cv::Mat() );
for( unsignedint i = 0; i < dst_norm.rows; i++ )
{
float * row=dst_norm.ptr<float>(i);
for(int j=0;j<dst_norm.cols;j++)
{
if(row[j]>=threshold)
{
cv::circle(mRgb, cv::Point(j, i), 10, cv::Scalar(255,0,0,255));
}
}
}
}
}我们在PanoActivity类中声明了本机方法,以便稍后可以调用本机代码:
public native void FindHarrisCorners(long matAddrGr, long matAddrRgba);我们构建本机库并在活动中声明本机方法,但是当我们尝试调用本机方法时,会收到java.lang.UnsatisfiedLinkError,因为尚未加载本机库。 为此,我们更改onManagerConnected()方法以在 OpenCV 初始化后加载本机库:
private BaseLoaderCallback mLoaderCallback = new BaseLoaderCallback(this) {
@Override
public void onManagerConnected(int status) {
switch (status) {
case LoaderCallbackInterface.SUCCESS:
{
Log.i(TAG, "OpenCV loaded successfully");
// Load native library after(!) OpenCV initialization
System.loadLibrary("Pano");
} break;
default:
{
super.onManagerConnected(status);
} break;
}
}
};现在,我们准备通过菜单项使用本机库来触发本机哈里斯角检测器。 因此,打开res/menu/pano.xml并添加以下菜单项:
<itemandroid:id="@+id/action_nativeHarris"
android:orderInCategory="2"
android:title="@string/action_nativeHarris">
</item>在PanoActivity中,更改onOptionsItemSelected()以处理本机情况:
else if(id==R.id.action_nativeHarris)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat greyImage=new Mat();
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);
FindHarrisCorners(greyImage.getNativeObjAddr(),sampledImage.getNativeObjAddr());
displayImage(sampledImage);
}我们列出了调用哈里斯角点检测器的本机实现所需的步骤; 但是,我们仍然需要仔细阅读 C++ 代码的细节,以了解我们所做的事情,以便您可以扩展并基于在此处学习的思想。 当然,具有 C++ 语言构造的基本思想将非常有益。
我们首先包含所需的头文件列表:
#include<opencv2/core/core.hpp>
#include<opencv2/imgproc/imgproc.hpp>
#include<opencv2/features2d/features2d.hpp>
#include<vector>按照此命名约定Java_Fully_Qualified_Class_Name_MethodName声明我们将使用的函数。 我们在PanoActivity中声明的方法仅采用两个参数:灰度和彩色图像的地址; 但是,本机方法需要四个。 前两个始终在任何 JNI 方法声明中使用。 后两个对应于我们发送的地址(在 Java 中jlong映射到long):
JNIEXPORT void JNICALL Java_com_app3_pano_PanoActivity_FindHarrisCorners(JNIEnv*, jobject, jlong addrGray, jlong addrRgba)我们将参考发送给Mat参考,其中一个用于灰度图像,另一个用于彩色图像:
cv::Mat& mGr = *(cv::Mat*)addrGray;
cv::Mat& mRgb = *(cv::Mat*)addrRgba;我们声明并初始化将用于检测角点的变量的列表:
cv::Mat dst_norm;
cv::Mat dst = cv::Mat::zeros(mGr.size(),CV_32FC1);
int blockSize = 2;
intapertureSize = 3;
double k = 0.04;
float threshold=150;我们将哈里斯角点检测器的本地实现称为“实现”,并将角点的响应归一化为0和255之间:
cv::cornerHarris( mGr, dst, blockSize, apertureSize, k, cv::BORDER_DEFAULT );
cv::normalize( dst, dst_norm, 0, 255, cv::NORM_MINMAX, CV_32FC1, cv::Mat() );我们在归一化的角点处循环并在检测到的角点处绘制一个圆,以防其响应大于阈值:
for( unsignedint i = 0; i < dst_norm.rows; i++ )
{
float * row=dst_norm.ptr<float>(i);
for(int j=0;j<dst_norm.cols;j++)
{
if(row[j]>=threshold)
{
cv::circle(mRgb, cv::Point(j, i), 10, cv::Scalar(255,0,0,255));
}
}
}
左图是使用 Java 包装程序的 HCD,右图是本机 HCD
了解 FAST 角点检测器
应用于实时应用时,在速度方面会有更好的检测器。 在本节中,我们将描述 FAST 角点检测器的工作原理。
让我们考虑一个像素P。如果我们在像素P的圆形邻域中测试 16 个像素,并且其中 12 个像素的强度大于或小于P的强度加/减a,则说P是一个潜在的兴趣点或角。 阈。
该过程的计算量很大,因此为了加快检测速度,提出了另一种测试方法。 该算法首先在特定位置(1、9、5、13)仅测试 4 个像素; 如果其中三个大于或小于P的强度加/减阈值,则继续其他 8 个像素; 否则,将丢弃此像素:

UI 定义
将以下菜单项添加到res/menu/pano.xml:
<itemandroid:id="@+id/action_fast"
android:orderInCategory="4"
android:title="@string/action_fast">
</item>使用 FAST 角点检测器
打开PanoActivity并编辑onOptionsItemSelected()以包括以下情况:
else if(id==R.id.action_fast)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat greyImage=new Mat();
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);
MatOfKeyPoint keyPoints=new MatOfKeyPoint();
FeatureDetector detector=FeatureDetector.create(FeatureDetector.FAST);
detector.detect(greyImage, keyPoints);
Features2d.drawKeypoints(greyImage, keyPoints, greyImage);
displayImage(greyImage);
}如前所述,OpenCV 具有非常简单的接口和工厂方法来构建不同的检测器。 哈里斯探测器和 FAST 之间的唯一区别是我们发送给工厂方法的以下参数:
FeatureDetector detector = FeatureDetector.create(FeatureDetector.FAST);其余代码完全相同。
使用本机 FAST
在本节中,我们将向PanoActivity类添加另一个本机方法,以将本机实现调用到 FAST 角点检测器:
打开活动类并添加以下声明:
public native void FindFastFeatures(long matAddrGr, long matAddrRgba);该方法有两个参数。 第一个是灰度图像的地址,第二个是彩色版本的地址。
将以下方法添加到Pano.cpp文件中:
JNIEXPORT void JNICALL Java_com_app3_pano_PanoActivity_FindFastFeatures(JNIEnv*, jobject, jlong addrGray, jlong addrRgba)
{
cv::Mat& mGr = *(cv::Mat*)addrGray;
cv::Mat& mRgb = *(cv::Mat*)addrRgba;
std::vector<cv::KeyPoint> v;
cv::FastFeatureDetector detector(50);
detector.detect(mGr, v);
for( unsignedint i = 0; i < v.size(); i++ )
{
const cv::KeyPoint& kp = v[i];
cv::circle(mRgb, cv::Point(kp.pt.x, kp.pt.y), 10, cv::Scalar(255,0,0,255));
}
}在前面的代码中,我们首先实例化关键点的向量和阈值为50的FastFeatureDetector对象,并通过传入灰度图像和关键点的空向量来调用detection方法。 然后,我们为每个检测到的关键点绘制一个圆圈。
我们在res/menu/pano.xml中添加了另一个菜单项:
<itemandroid:id="@+id/action_nativefast"
android:orderInCategory="5"
android:title="@string/action_fastnative">
</item>最后,打开PanoActivity并编辑onOptionsItemSelected()以包含以下情况:
else if(id==R.id.action_nativefast)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat greyImage=new Mat();
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);
FindFastFeatures(greyImage.getNativeObjAddr(),sampledImage.getNativeObjAddr());
displayImage(sampledImage);
}
左图是使用 Java 包装程序的 FAST,右图是本机 FAST
了解 ORB 特征检测器
OpenCV 实验室的另一个重要检测器,也是一个描述符,是两个非常有名但已申请专利的算法(比例不变特征变换(SIFT)和加速鲁棒特征(SURF)的替代物 ORB。 要使用 SIFT 和 SURF,您需要付费; 但是,ORB 在计算成本和匹配表现方面提供了一种免费的良好选择。
在本节中,我们将讨论 ORB 的检测器部分。 它主要使用我们在上一节中看到的 FAST 算法,并添加了以下一些重要补充:
- ORB 首先使用 FAST 算法检测兴趣点或角点
- 它使用哈里斯(Harris)来为每个角指定分数(基于检测到的角附近的强度变化)
- 它对计分的兴趣点进行排序,并且仅考虑前 N 个角
- 它使用图像金字塔生成多尺度兴趣点,而不是 FAST 检测到的单尺度兴趣点
- 它计算兴趣点邻域的强度加权质心
- 该算法利用兴趣点和质心计算此向量方向,并将其指定为兴趣点方向; 这一步对于算法的描述部分很重要
UI 定义
将以下菜单项添加到res/menu/pano.xml:
<itemandroid:id="@+id/action_orb"
android:orderInCategory="6"
android:title="@string/action_orb">
</item>使用 ORB 特征检测器
我们需要在PanoActivity类中编辑onOptionsItemSelected()以包括以下情况:
else if(id==R.id.action_orb)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat greyImage=new Mat();
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);
MatOfKeyPoint keyPoints=new MatOfKeyPoint();
FeatureDetector detector = FeatureDetector.create(FeatureDetector.ORB);
detector.detect(greyImage, keyPoints);
Features2d.drawKeypoints(greyImage, keyPoints, greyImage);
displayImage(greyImage);
}在不同特征检测器之间切换非常简单。 我们只是将 ORB 的 ID 传递给factory方法,然后调用detect方法。
使用本机 ORB
在本节中,我们将使用 ORB 检测器的本机实现,并将预处理步骤移至 CPP 文件,以便将 JNI 调用的开销减少到仅一个调用:
打开PanoActivity类并添加以下声明:
public native void FindORBFeatures(long matAddrRgba, int featuresNumber);该方法带有两个参数,即本地对象的地址和要检测的最大特征数。
在Pano.cpp中,添加以下方法实现:
JNIEXPORT void JNICALL Java_com_app3_pano_PanoActivity_FindORBFeatures(JNIEnv*, jobject, jlong addrRgba, jint featuresNumber)
{
cv::Mat& mRgb = *(cv::Mat*)addrRgba;
cv::Mat grayImg;
std::vector<cv::KeyPoint> v;
cv::cvtColor(mRgb,grayImg,cv::COLOR_RGBA2GRAY);
cv::OrbFeatureDetector detector(featuresNumber);
detector.detect(grayImg, v);
cv::drawKeypoints(grayImg,v,mRgb,cv::Scalar::all(-1),cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
}我们将将彩色图像转换为Pano.cpp的预处理步骤进行了处理。 我们通过调用cv::cvtColor并传递输入图像,输出图像和映射代码来实现。 然后,我们实例化一个ORBFeatureDetector对象,该对象的最大特征数量等于我们发送的参数。
在下一行,我们调用detect方法。 最后,我们使用cv::drawKeypoints方法绘制关键点,并传递输入图像(用于检测关键点的图像),KeyPoint的向量,输出图像,用于绘制关键点的颜色(using cv::Scalar::all(-1)表示 (使用的颜色将是随机的),最后是标志用作每个关键点的圆,其大小等于关键点大小并绘制关键点方向。
将以下菜单项添加到res/menu/pano.xml:
<itemandroid:id="@+id/action_nativeorb"
android:orderInCategory="7"
android:title="@string/action_orbnative">
</item>最后,打开PanoActivity并编辑onOptionsItemSelected()以包含以下情况:
else if(id==R.id.action_nativeorb)
{
if(sampledImage==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an image first!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat copy=sampledImage.clone();
FindORBFeatures(copy.getNativeObjAddr(),100);
displayImage(copy);
}
左图是使用 Java 包装程序的 ORB,右图是具有特征比例和方向的本机 ORB
特征描述和匹配
使用图像特征过程的第二步是特征描述。 特征描述符用于为您提供有关兴趣点的更多信息,并在检测到的特征的局部区域/邻域中进行计算。
可以按照局部区域的形状(矩形或圆形),采样模式(密集采样,其中局部区域中的所有像素都将对特征描述或稀疏采样做出贡献)对特征描述符进行分类 )和频谱(二进制,其中描述向量将仅为 1 和 0 或使用任何标量值或其他值的标量)。
OpenCV 提供了属于不同类别的特征描述符。 但是,在本节中,由于 SIFT 和 SURF(密集和标量)描述符是专利算法,您必须付费才能使用它们,因此,我们仅关注稀疏的二进制描述符(也称为局部二进制描述符)。
使用像素对采样方法,无论描述符的形状如何,都可以计算局部二进制描述符,在此方法中,比较选定的像素对以生成表示描述向量的二进制字符串。 例如,如果我们有一对像素(P1, P2),则比较P1和P2的强度。 如果P1的强度大于P2,则将1放入描述向量中,否则将插入0。
了解 BRIEF 和 ORB 特征描述符
二进制鲁棒独立基本特征(BRIEF)描述符被认为是提出的最简单也是第一个本地二进制描述符。 为了使用长度为 N 的描述向量描述兴趣点,该算法通过几种随机方法(均匀,高斯等)在31x31色块区域中选择了 N 个随机像素对,并将它们进行比较以构造二进制字符串。
对于 ORB,描述符通过将兴趣点转向规范方向(假设我们在检测阶段知道了兴趣点主导方向)将方向添加到 BRIEF,然后计算描述。 结果,我们实现了一些旋转不变性。 例如,如果兴趣点主导方向为 90 度,则在使用 ORB 对其进行描述之前,将兴趣点及其邻域旋转为向上指向(方向= 0),然后描述该兴趣点,以便实现旋转不变性。
对于像素对采样方法,ORB 离线学习了如何选择像素对,以最大程度地提高方差并减小相关性,以便每个选择的像素都向描述符添加新信息。
使用随机化方法(BRIEF)或学习的采样方法(ORB)选择像素对会导致非对称描述符形状,如下所示:
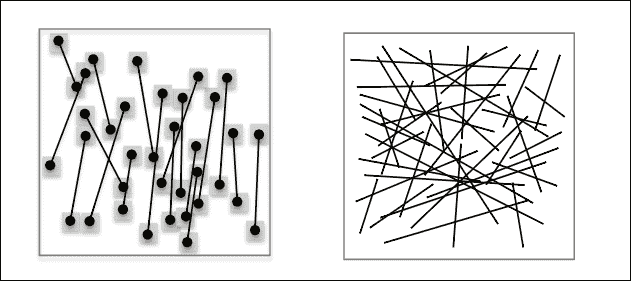
了解 BRISK 特征描述符
二进制鲁棒不变可扩展关键点(BRISK)描述符建立在以四个同心环排列的 60 个点上,因此,点对采样形状为圆形且对称。 每个点代表一个圆形采样区域(用于选择采样对),随着我们远离兴趣点,该区域的大小会增加。
为了计算方向,使用高斯过滤器对每个采样区域进行平滑处理,然后计算局部梯度。 采样对分为两组:长段,两对之间的距离大于某个阈值,并与局部梯度一起使用以计算方向角,以引导兴趣点,从而实现旋转不变性。 第二类是短段,其中两对之间的距离低于另一个阈值,并用于通过比较 512 对来构造 512 位二进制描述符。 下图描述了 BRISK 采样区域的分布:

了解 FREAK 特征描述符
快速视网膜关键点(FREAK)描述符的圆形形状是基于人的视网膜系统,其中受体细胞的密度在中心最高,而随着我们离开而降低。 对于采样模式,使用离线训练算法学习最佳像素对,以最大化点对方差并最小化相关性。
匹配特征
一旦确定了适合您需要的描述符上的,就需要选择一个距离函数来确定特征匹配。 根据您选择的描述符,有很多距离函数可以使用。 对于本地二进制特征,最喜欢的选择是汉明距离以测量两个等长二进制字符串之间的差异。 该操作非常高效且快速,因为它可以使用机器语言指令或 XOR 操作后跟一个位计数来执行。
使用特征匹配
在本部分中,我们将更新应用,以便您可以将具有不同描述符的不同检测器混合使用,以找到匹配的特征。
UI 定义
我们将在应用菜单中定义两个组。 一个用于我们使用的检测器集合,另一个用于描述符的集合。 我们还将添加一个菜单项,您可以在其中选择要在给定场景中找到的对象。 打开res/menu/pano.xml并添加以下项目:
<item android:orderInCategory="8" android:id="@+id/detector" android:title="@string/list_detector">
<menu><group android:checkableBehavior="single">
<item android:id="@+id/harris_check"
android:title="@string/action_harris"/>
<item android:id="@+id/fast_check"
android:title="@string/action_fast" android:checked="true"/>
<item android:id="@+id/orbD_check"
android:title="@string/action_orb" />
</group></menu>
</item>
<item android:orderInCategory="9" android:id="@+id/descriptor" android:title="@string/list_descriptor">
<menu><group android:checkableBehavior="single">
<item android:id="@+id/BRIEF_check"
android:title="@string/action_brief"/>
<item android:id="@+id/ORB_check"
android:title="@string/action_orb" android:checked="true"/>
<item android:id="@+id/BRESK_check"
android:title="@string/action_brisk"/>
<item android:id="@+id/FREAK_check"
android:title="@string/action_freak"/>
</group></menu>
</item>
<item android:id="@+id/action_match"
android:orderInCategory="10"
android:title="@string/action_match">
</item>
<item
android:id="@+id/action_selectImgToMatch"
android:orderInCategory="1"
android:showAsAction="never"
android:title="@string/action_selectImgToMatch"/>在场景中查找对象
我们将按照此过程在给定场景中找到对象。 首先,加载场景,然后加载对象图像,最后选择match。 要执行匹配过程,我们编辑onOptionsItemSelected()以包括以下情况:
else if(id==R.id.action_match)
{
if(sampledImage==null || imgToMatch==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an object and a scene to match!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
int maximumNuberOfMatches=10;
Mat greyImage=new Mat();
Mat greyImageToMatch=new Mat();
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);
Imgproc.cvtColor(imgToMatch, greyImageToMatch, Imgproc.COLOR_RGB2GRAY);
MatOfKeyPoint keyPoints=new MatOfKeyPoint();
MatOfKeyPoint keyPointsToMatch=new MatOfKeyPoint();
FeatureDetector detector=FeatureDetector.create(detectorID);
detector.detect(greyImage, keyPoints);
detector.detect(greyImageToMatch, keyPointsToMatch);
DescriptorExtractor dExtractor = DescriptorExtractor.create(descriptorID);
Mat descriptors=new Mat();
Mat descriptorsToMatch=new Mat();
dExtractor.compute(greyImage, keyPoints, descriptors);
dExtractor.compute(greyImageToMatch, keyPointsToMatch, descriptorsToMatch);
DescriptorMatcher matcher = DescriptorMatcher.create(DescriptorMatcher.BRUTEFORCE_HAMMING);
MatOfDMatch matches=new MatOfDMatch();
matcher.match(descriptorsToMatch,descriptors,matches);
ArrayList<DMatch> goodMatches=new ArrayList<DMatch>();
List<DMatch> allMatches=matches.toList();
double minDist = 100;
for( int i = 0; i < descriptorsToMatch.rows(); i++ )
{
double dist = allMatches.get(i).distance;
if( dist < minDist ) minDist = dist;
}
for( int i = 0; i < descriptorsToMatch.rows() && goodMatches.size()<maximumNuberOfMatches; i++ )
{
if(allMatches.get(i).distance<= 2*minDist)
{
goodMatches.add(allMatches.get(i));
}
}
MatOfDMatch goodEnough=new MatOfDMatch();
goodEnough.fromList(goodMatches);
Mat finalImg=new Mat();
Features2d.drawMatches(greyImageToMatch, keyPointsToMatch, greyImage, keyPoints, goodEnough, finalImg,Scalar.all(-1),Scalar.all(-1),new MatOfByte(), Features2d.DRAW_RICH_KEYPOINTS + Features2d.NOT_DRAW_SINGLE_POINTS);
displayImage(finalImg);
}我们首先确保场景和对象图像已加载:
if(sampledImage==null || imgToMatch==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an object and a scene to match!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}将场景和对象图像都转换为灰度:
Imgproc.cvtColor(sampledImage, greyImage, Imgproc.COLOR_RGB2GRAY);
Imgproc.cvtColor(imgToMatch, greyImageToMatch, Imgproc.COLOR_RGB2GRAY);根据从应用菜单进行的选择来构造检测器对象,并使用它来检测场景和对象图像中的特征:
MatOfKeyPoint keyPoints=new MatOfKeyPoint();
MatOfKeyPoint keyPointsToMatch=new MatOfKeyPoint();
FeatureDetector detector = FeatureDetector.create(detectorID);
detector.detect(greyImage, keyPoints);
detector.detect(greyImageToMatch, keyPointsToMatch);我们对所使用的描述符类型执行相同的操作。 OpenCV 具有与检测器相似的描述符接口。 您在DescriptorExtractor类上调用一个create方法,并传递要使用的描述符的 ID。 在本例中,ID 基于我们从应用菜单中所做的选择。
DescriptorExtractor dExtractor = DescriptorExtractor.create(descriptorID);接下来,我们通过在创建的描述符对象上调用计算方法并传递图像,检测到的关键点和空的Mat对象来存储在场景和对象图像中检测到的每个特征的描述,以存储描述 :
Mat descriptors=new Mat();
Mat descriptorsToMatch=new Mat();
dExtractor.compute(greyImage, keyPoints, descriptors);
dExtractor.compute(greyImageToMatch, keyPointsToMatch, descriptorsToMatch);然后,我们通过在DescriptorMacther类上调用create方法并传递您选择的distance函数的 ID 来构造匹配器对象。 在我们的例子中,我们使用的是本地二进制描述符。 因此,汉明距离将是我们最喜欢的选择:
DescriptorMatcher matcher = DescriptorMatcher.create(DescriptorMatcher.BRUTEFORCE_HAMMING);现在,我们准备通过在匹配器对象上调用match方法,并传递对象特征描述,场景特征描述和DMatch对象的空矩阵,从场景和对象图像中找到匹配特征。 DMatch对象是一个简单的数据结构,用于存储两个匹配的描述符及其距离(在我们的示例中为汉明距离):
MatOfDMatch matches=new MatOfDMatch();
matcher.match(descriptorsToMatch,descriptors,matches);最后,我们选择最佳匹配点并绘制它们:
ArrayList<DMatch> goodMatches=new ArrayList<DMatch>();
List<DMatch> allMatches=matches.toList();
double minDist = 100;
for( int i = 0; i <descriptorsToMatch.rows(); i++ )
{
double dist = allMatches.get(i).distance;
if( dist < minDist ) minDist = dist;
}
for( int i = 0; i <descriptorsToMatch.rows() && goodMatches.size()<maximumNuberOfMatches; i++ )
{
if( allMatches.get(i).distance<= 2*minDist)
{
goodMatches.add(allMatches.get(i));
}
}
MatOfDMatch goodEnough=new MatOfDMatch();
goodEnough.fromList(goodMatches);
Mat finalImg=new Mat();
Features2d.drawMatches(greyImageToMatch, keyPointsToMatch, greyImage, keyPoints, goodEnough, finalImg,Scalar.all(-1),Scalar.all(-1),new MatOfByte(),Features2d.DRAW_RICH_KEYPOINTS + Features2d.NOT_DRAW_SINGLE_POINTS);
displayImage(finalImg);
使用 ORB 进行特征检测和描述对于缩放和旋转是不变的
原生特征匹配
我们已经看到如何使用 Java 包装器检测,描述和匹配特征。 但是,如果将这些步骤组合到一个 JNI 调用中会更快,因为该过程需要许多步骤,并且每个步骤都转换为对本机代码的单个 JNI 调用。
在本节中,我们将在应用的本机端执行特征检测,描述和匹配过程。
UI 定义
我们将添加一个新菜单项以执行本机进程。 打开res/menu/pano.xml并添加以下项目:
<itemandroid:id="@+id/action_native_match"
android:orderInCategory="11"
android:title="@string/action_native_match">
</item>本机匹配过程
在本节中,我们将将过程和预处理步骤移至应用的本机端。 从而将总的 JNI 开销减少到最小:
我们首先在活动类中声明一个新的本机方法。 本机方法引用对象图像,场景图像,检测器 ID 和描述符 ID 并返回具有匹配结果的图像:
public native void FindMatches(long objectAddress, long sceneAddress,int detectorID, int descriptorID,long matchingResult);我们在Pano.cpp文件中定义了本机方法:
JNIEXPORT void JNICALL Java_com_app3_pano_PanoActivity_FindMatches(JNIEnv*, jobject, jlong objectAddress, jlong sceneAddress,jint detectorID, jint descriptorID,jlong matchingResult)
{
cv::Mat& object = *(cv::Mat*)objectAddress;
cv::Mat& scene = *(cv::Mat*)sceneAddress;
cv::Mat& result = *(cv::Mat*)matchingResult;
cv::Mat grayObject;
cv::Mat grayScene;
//Convert the object and scene image to grayscale
cv::cvtColor(object,grayObject,cv::COLOR_RGBA2GRAY);
cv::cvtColor(scene,grayScene,cv::COLOR_RGBA2GRAY);
std::vector<cv::KeyPoint> objectKeyPoints;
std::vector<cv::KeyPoint> sceneKeyPoints;
cv::Mat objectDescriptor;
cv::Mat scenceDescriptor;
//Construct a detector object based on the input ID
if(detectorID==1)//FAST
{
cv::FastFeatureDetector detector(50);
detector.detect(grayObject, objectKeyPoints);
detector.detect(grayScene, sceneKeyPoints);
}
else if(detectorID==5)//ORB
{
cv::OrbFeatureDetector detector;
detector.detect(grayObject, objectKeyPoints);
detector.detect(grayScene, sceneKeyPoints);
}
//Construct a descriptor object based on the input ID
if(descriptorID==3)//ORB
{
cv::OrbDescriptorExtractor descriptor;
descriptor.compute(grayObject,objectKeyPoints,objectDescriptor);
descriptor.compute(grayScene,sceneKeyPoints,scenceDescriptor);
}
else if(descriptorID==4)//BRIEF
{
cv::BriefDescriptorExtractor descriptor;
descriptor.compute(grayObject,objectKeyPoints,objectDescriptor);
descriptor.compute(grayScene,sceneKeyPoints,scenceDescriptor);
}
else if(descriptorID==5)//BRISK
{
cv::BRISK descriptor;
descriptor.compute(grayObject,objectKeyPoints,objectDescriptor);
descriptor.compute(grayScene,sceneKeyPoints,scenceDescriptor);
}
else if(descriptorID==6)//FREAK
{
cv::FREAK descriptor;
descriptor.compute(grayObject,objectKeyPoints,objectDescriptor);
descriptor.compute(grayScene,sceneKeyPoints,scenceDescriptor);
}
//Construct a brute force matcher object using the
//Hamming distance as the distance function
cv::BFMatcher matcher(cv::NORM_HAMMING);
std::vector< cv::DMatch> matches;
matcher.match( objectDescriptor, scenceDescriptor, matches);
//Select the best matching points and draw them
double min_dist = 100;
for( int i = 0; i < objectDescriptor.rows; i++ )
{
double dist = matches[i].distance;
if( dist < min_dist ) min_dist = dist;
}
std::vector< cv::DMatch> good_matches;
for( int i = 0; i < objectDescriptor.rows; i++ )
{
if( matches[i].distance <= 3*min_dist )
{
good_matches.push_back( matches[i]);
}
}
drawMatches( grayObject, objectKeyPoints, grayScene, sceneKeyPoints,good_matches, result, cv::Scalar::all(-1), cv::Scalar::all(-1),std::vector<char>(), cv::DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS+cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
}在活动类中,编辑onOptionsItemSelected()以包括以下情况:
else if(id==R.id.action_native_match)
{
if(detectorID==FeatureDetector.HARRIS)
{
Context context = getApplicationContext();
CharSequence text = "Not a valid option for native matching";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
if(sampledImage==null || imgToMatch==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an object and a scene to match!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat finalImg=new Mat();
FindMatches(imgToMatch.getNativeObjAddr(),sampledImage.getNativeObjAddr(),detectorID,descriptorID,finalImg.getNativeObjAddr());
displayImage(finalImg);
} 
使用 ORB 进行本机匹配以进行特征检测和描述
拼接两个图像
图像拼接是处理,用于找到已经具有一定程度的重叠的图像之间的对应关系。
通常,拼接分为以下两个阶段:
- 图像配准和对齐:在此,我们给出了两个图像-一个作为源,另一个作为目标,并且该过程涉及在空间上注册目标图像以与源图像对齐。 该过程可以分为基于强度的对齐和基于特征的对齐。 我们将使用基于特征的对齐方式,因为我们已经熟悉了该方法的组成部分(在两个图像中查找,描述和匹配特征)。 此过程的结果是具有已知参数(即
3x3单应矩阵)的运动模型,该模型用于将一个图像的坐标映射到另一个图像。 扩展拼接应用以使用两个以上图像后,您将开始面临与全局配准相关的问题,并找到一组全局一致的对齐参数,以最大程度地减少所有图像对之间的配准不良。 用于解决此类问题的技术有:束调整(通过最小化每对图像之间的重投影误差来改善估计)和波校正(用于校正最终结果,因为通常会在波形输出中发现波浪状影响) 全景。 - 校正:对齐并对齐所有图像后,将需要对输入图像进行曝光校正,以使混合看起来更自然。 我们还需要通过称为多波段混合的过程去除可见的接缝和其他缝合伪像。
对我们来说幸运的是,OpenCV 与stitcher类捆绑在一起,该类将通过非常简单的接口执行拼接管线。 但是,OpenCV4Android SDK 不附带 Java 包装器,我认为这是您应该熟悉在应用中使用本机实现以便可以扩展并添加到当前版本的另一个原因。 OpenCV Java 包装器可以满足您的需求。 因此,要解决此问题,我们将向Pano.cpp添加另一个函数以调用stitcher类并返回结果。
UI 定义
我们将添加一个新的菜单项以执行本机缝合管线。 打开res/menu/pano.xml并添加以下项目:
<item android:id="@+id/action_native_stitcher" android:orderInCategory="11" android:title="@string/action_native_stitch">
</item>本地stitcher
在本节中,我们将为本地stitcher类实现 Java 包装器,以便可以在应用中使用它:
我们首先在activity类中声明一个新的本机方法。 本机方法引用第一个和第二个场景,并返回带有拼接结果的图像:
public native void Stitch(long sceneOneAddress, long sceneTwoAddress,long stitchingResult);我们在Pano.cpp中定义了新的拼接方法:
JNIEXPORTvoid JNICALL Java_com_app3_pano_PanoActivity_Stitch(JNIEnv*, jobject, jlong sceneOneAddress, jlong sceneTwoAddress,jlong stitchingResult) {
cv::Mat& sceneOne = *(cv::Mat*)sceneOneAddress;
cv::Mat& sceneTwo = *(cv::Mat*)sceneTwoAddress;
cv::Mat& result = *(cv::Mat*)stitchingResult;
/* The core stitching calls: */
//a list to store all the images that need to be stitched
std::vector<cv::Mat> natImgs;
natImgs.push_back(sceneOne);
natImgs.push_back(sceneTwo);
//create a stitcher object with the default pipeline
cv::Stitcher stitcher = cv::Stitcher::createDefault();
//stitch and return the result
stitcher.stitch(natImgs, result);
}在活动类中,编辑onOptionsItemSelected以包括以下情况:
else if(id==R.id.action_native_stitcher)
{
if(sampledImage==null || imgToMatch==null)
{
Context context = getApplicationContext();
CharSequence text = "You need to load an two scenes!";
int duration = Toast.LENGTH_SHORT;
Toast toast = Toast.makeText(context, text, duration);
toast.show();
return true;
}
Mat finalImg=new Mat();
Stitch(imgToMatch.getNativeObjAddr(),sampledImage.getNativeObjAddr(),finalImg.getNativeObjAddr());
displayImage(finalImg);
}总结
我们已经看到了如何使用本机和 Java 包装器检测,描述和匹配不同的特征。 此外,我们已经看到了图像特征的两种应用-一种可以在其中使用它们在场景中找到对象,另一种可以将两个图像拼接在一起以构建全景。
在下一章中,我们将换档并涉及机器学习的主题,以及如何使用学习算法来检测手势,并将其用于构建自动自拍应用。
六、应用 4 –自动自拍
在本章中,我们将开始开发新的应用。 该应用的目标是能够在不触摸手机屏幕的情况下自拍。 您的应用将能够检测到某个手势,该手势将触发保存当前相机帧的过程。
我们将介绍的主题包括:
- 用于对象检测的级联分类器
- 使用 OpenCV 操纵摄像机帧
- 使用训练过的级联分类器检测对象
级联分类器
在本节中,我们将讨论强大的级联分类器及其组件,Haar 特征,积分图像,自适应提升(Adaboost)和级联以构建一个物体检测器。
简而言之,要构造对象检测器,您可以使用正样本(例如,尺寸为24x24的人脸)和负样本(任何其他非人脸的图像)对其进行训练。 您将不断完善训练过程,以最大程度地减少训练错误(分类为非面部的面部总数和分类为面部的非面部总数)。
训练完成后,我们得到一张新图像,我们要求检测器检查其是否有正面样本(即面部)。 这样做的步骤如下:
- 检测器将使用扫描窗口扫描输入图像,并且每个扫描的窗口都会得到一个分数。
- 然后,如果检测器的分数大于某个阈值,则检测器将说该窗口包含正面样本。 否则,事实并非如此。
类 Haar 的特征
类 Haar 的特征是的另一种类型的特征,用于来检测诸如面孔,行人等的刚性物体。
《使用简单特征的增强级联的快速目标检测》论文,由 Paul Viola 和 Michael Jones 于 2001 年提出,介绍了类似 Haar 的特征的使用自适应提升和级联来检测人脸。 从那时起,许多其他特征和增强变化被用于产生许多其他对象类别的分类器。
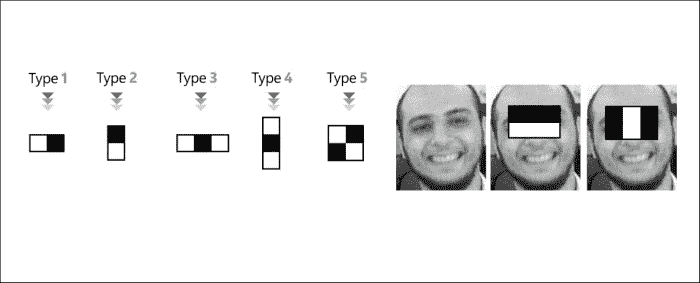
建立用于对象检测的级联分类器的第一步是尝试对有关正样本和负样本的丰富信息进行编码。 换句话说,我们需要确定哪些特征被认为足够好,可以将面孔和非面孔分开。 在本节中,我们将讨论与第 5 章,“App 3:全景查看器”中看到的特征不同的其他类型的特征。 此处使用的特征是固定大小的像素网格,在这种情况下,由于固定大小的网格定义了描述区域,因此无需检测兴趣点。
类似 Haar 的特征是固定大小的像素网格,分为黑色和白色区域,与我们在第 2 章,“应用 1-建立自己的暗室”中讨论的卷积核非常相似。 。 将 Haar 特征应用于给定的图像区域时,可以通过从黑色区域下的强度总和中减去白色区域下的像素强度之和来描述相应的图像区域,从而得到一个值。
类似 Haar 的特征设计灵活; 例如,您可以具有多个 Type 1 特征,但是将不同的高度和/或宽度应用于图像的不同区域。 因此,给定这些参数(特征类型(1、2、3、4 或 5),特征宽度,特征高度和应用该特征的图像区域),您将获得大量可用于描述正面和负面样本的特征。
注意
在 Viola 和 Jones 的工作中,该算法使用24x24窗口作为基本窗口大小(所有面部和非面部的尺寸都调整为24x24像素),如果考虑所有参数(类型,比例和位置),则我们最终拥有大小为 160,000 个特征的池。
下图是特征部件池的示例:

拥有如此众多的特征,将这样的算法应用于实时应用将是一个挑战。 因此,我们需要开始进行一些优化。
可以用来消除冗余特征或选择真正有区别的特征子集的一种优化技术是“自适应提升”,本章稍后将回到该算法的详细信息。
另一种优化技术用于计算特征值(即从黑色区域中减去白色区域),并且可以通过计算所谓的积分图像来实现。
完整图片
每当我们想要计算特征值时,我们都需要将白色斑块相加并从黑色斑块中减去,然后快速进行操作,Viola 和 Jones 提出了一个很好的技巧,称为积分图像, 如下:
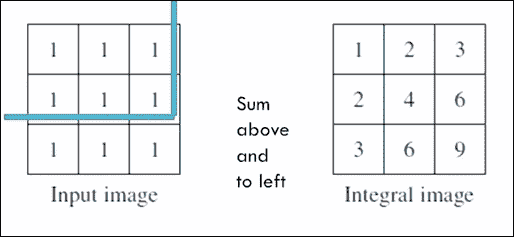
积分图像是与输入图像尺寸相同的图像,但是每个积分像素(i, j)是在输入像素(i, j)上方和左侧的所有输入像素的总和。 例如,当左上像素用(0, 0)索引时,值6的整数像素(1, 2)是所有输入像素(i, j)的总和,其中i <= 1,j <= 2。
计算完积分图像后,获得图像中任何区域的输入像素的总和将成为O(1)运算。
例如,考虑具有四个区域的积分图像:A,B,C和D。1表示的整数像素将所有输入像素的总和存储在区域A中,2表示的整数像素是区域A和B中所有输入像素的总和,由3表示的整数像素是区域A中所有输入像素的总和。C和C相同,积分像素4相同,它们将输入像素的总和存储在A,B,C和D。
现在,要获得区域D中输入像素的总和,您只需要四个整数角像素 1、2、3 和 4 的值,并使用简单的算术运算D = 4 + 1 - 2 - 3,您将获得输入区域总和,如下所示:

自适应提升
现在,我们已经使用使用积分图像技巧来优化特征计算,我们需要最小化要使用的特征数量。
为此,Viola 和 Jones 使用 Adaboost 算法选择了可以区分正样本和负样本的相关特征子集(也称为弱分类器),如下图所示:

最简单形式的 Adaboost 算法可以描述如下:
- 从均匀的正负样本权重开始。 所有样本(正样本或负样本)同等重要。
- 遍历特征/弱分类器池,然后选择加权加权分类误差最小的分类器。 注意 分类错误是使用此特征将多少张面孔分类为非面孔,将多少张非面孔分类为面孔。
- 增加错误分类的样本(负样本或正样本)的权重,以强调在下一次迭代中正确分类这些样本的重要性。
- 重复步骤 2 和 3,直到收敛为止。 在许多情况下,可以通过选择最多 N 个特征来收敛。
一旦我们获得了这些特征(弱分类器)的列表,便可以将它们线性组合以形成更强的分类器,其表现优于任何单独的弱分类器,最后确定一个阈值以最佳地将面孔和非面孔分开。
对于要分类的新图像,我们计算在输入图像上使用 Adaboost 选择的N个相关特征的数量,并根据所选阈值确定它是人脸还是非人脸。
级联
最后一个技巧为这种类型的分类器起了名字,以加快对任何给定图像的检测速度,其依据是我们需要使用尺寸为24x24的窗口扫描输入图像,例如 Viola 和 Jones 的作品。 但是,我们知道,在许多此类窗口中,不存在感兴趣的对象,因此需要对算法进行修改,以便尽快拒绝否定窗口并集中于可能的肯定窗口。
为此,我们构建了一系列强分类器,而不是训练一个强分类器。 因此,所有选定的特征都被分组为多个阶段,其中每个阶段都用于确定给定窗口是否肯定是包含感兴趣对象的否定窗口或可能是肯定窗口。 基本上,此更新使我们能够使用较小的一组相关特征尽早消除大量的负面窗口,如下所示:
训练过程完成后,我们得到一系列强大的分类器,这些分类器可以在任何给定图像上应用固定大小的滑动窗口,并检测给定窗口是否包含感兴趣的对象:

在下一部分中,我们将使用已经训练好的级联分类器,该分类器可以检测图像中的闭合手掌,并且将闭合手掌的存在作为提示来保存当前图像帧。
使用级联分类器检测对象
在本节中,我们将使用级联分类器来检测手机摄像头馈送中的闭合手掌,但首先,我们将介绍如何使用 OpenCV 访问手机摄像头。
使用 OpenCV 访问手机的摄像头
我们将按照前面章节中使用的相同步骤,首先创建一个名为AutoSelfie的空白活动新应用。
为了使应用能够访问手机的相机并能够保存图片,您需要在清单文件中添加以下两个权限:
<uses-permissionandroid:name="android.permission.CAMERA"/>
<uses-permissionandroid:name="android.permission.WRITE_EXTERNAL_STORAGE"/>您可以通过本章随附的代码捆绑包查找其余配置。
相机预览
OpenCV 为相机预览类提供 Java 实现,该类用于处理设备相机和 OpenCV 库之间的交互。 org.opencv.android.JavaCameraView类使相机可以在设备屏幕上处理和绘制帧。
到目前为止,使用JavaCameraView预览相机帧已经足够; 但是,我们将需要定义自己的相机视图类,以便以后能够扩展JavaCameraView类的功能。 现在,让我们看看如何定义自己的相机视图类:
创建一个名为com.app4.autodselfie.CamView的新 Java 类。
使新类扩展到org.opencv.android.JavaCameraView。
如下定义CamView类构造器:
public CamView(Context context, AttributeSet attrs) {
super(context, attrs);
}就是这个。 稍后,当我们向应用中添加拍照功能时,我们将回到此类。
UI 定义
在应用布局文件activity_auto_selfie.xml中,我们将主视图定义为CamView类(因为它是android.view.SurfaceView类的子类):
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent">
<com.app4.autoselfie.CamView
android:layout_width="fill_parent"
android:layout_height="fill_parent"
android:id="@+id/auto_selfie_activity_surface_view"/>
</LinearLayout>预览相机帧
返回活动AutoSelfie,我们将按照以下步骤开始从设备的摄像机接收帧:
更改活动类以实现CvCameraViewListener2接口,该接口会将活动类转变为用于监听我们CamView类,相机视图开始,相机视图停止和收到的相机帧的三个生命事件的监听器:
public class AutoSelfie extends Activity implements CvCameraViewListener2我们声明两个空的Mat对象-一个用于保存当前相机帧的 RGB 版本,另一个用于保存灰度版本:
private Mat mRgba;
private Mat mGray;我们实现了CvCameraViewListener2的三个缺失事件处理器。 开始摄影机视图后,我们将初始化两个Mat对象。 当摄像机视图停止时,我们将其释放,当我们开始接收摄像机帧时,我们将返回要在屏幕上绘制的当前帧的 RGB 版本:
public void onCameraViewStarted(int width, int height) {
mGray = new Mat();
mRgba = new Mat();
}
public void onCameraViewStopped() {
mGray.release();
mRgba.release();
}
public Mat onCameraFrame(CvCameraViewFrame inputFrame) {
mRgba=inputFrame.rgba();
return mRgba;
}更新onCreate()方法以找到我们在应用布局文件中定义的CamView对象,将相机设置为连接(正面或背面),在本例中,我们将连接至正面相机,最后 ,将我们的活动注册为CamView对象生命事件的监听器:
mOpenCvCameraView = (CamView) findViewById(R.id.auto_selfie_activity_surface_view);
mOpenCvCameraView.setCameraIndex(1);
mOpenCvCameraView.setCvCameraViewListener(this);最后,在成功加载 OpenCV 库后,我们可以使CamView 对象连接到设备摄像机; 只有这样onCameraViewStarted()才会被调用,CamView对象变为活动状态:
private BaseLoaderCallback mLoaderCallback = new BaseLoaderCallback(this) {
@Override
public void onManagerConnected(int status) {
switch (status) {
case LoaderCallbackInterface.SUCCESS:
{
Log.i(TAG, "OpenCV loaded successfully");
mOpenCvCameraView.enableView();
} break;
default:
{
super.onManagerConnected(status);
} break;
}
}
};注意
您会注意到,将设备直立放置时,绘制的框架会翻转。 不用担心,我们稍后会处理此问题。
检测摄像头框架中闭合的手掌
自动自拍应用的下一步是检测提示以捕获当前相机帧。 我发现,闭合的手掌是足够好的提示,您可以考虑其他提示,例如笑脸等。
正如我们在“级联分类器”部分中提到的那样,我们的检测器将是使用类似 Haar 特征的级联分类器。
注意
训练有素的阶段和所选特征将保存在 XML 文件中。 您可以直接从这个页面下载文件,也可以在本章随附的项目文件夹中找到该文件。
使用基于 Java 的级联分类器
一旦使训练有素的分类器检测到您选择的对象(在我们的情况下为闭合手掌),OpenCV 便会提供多尺度滑动窗口检测器,它将在滑动式窗口中运行训练有素的分类器,并在输入图像的多个比例上,以不同比例返回检测到的对象周围的边界框。
注意
使用我们在第 5 章,“App 3:全景查看器”中遇到的图像金字塔的概念构造了多个比例尺。
使用org.opencv.objdetect.CascadeClassifier类作为现成的滑动窗口检测器非常容易。 我们首先需要将训练有素的分类器 XML 文件复制到应用原始资源文件夹\res\raw\haarhand.xml中。
接下来,我们通过如下更改BaseLoaderCallback实现来声明并初始化org.opencv.objdetect.CascadeClassifier对象:
private File cascadeFile;
private CascadeClassifier cascadeClassifier;
private BaseLoaderCallback mLoaderCallback = new BaseLoaderCallback(this) {
@Override
public void onManagerConnected(int status) {
switch (status) {
case LoaderCallbackInterface.SUCCESS:
{
Log.i(TAG, "OpenCV loaded successfully");
try {
// load cascade file from application resources
InputStream is = getResources().openRawResource(R.raw.haarhand);
File cascadeDir = getDir("cascade", Context.MODE_PRIVATE);
cascadeFile = new File(cascadeDir, "haarhand.xml");
FileOutputStream os = new FileOutputStream(cascadeFile);
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = is.read(buffer)) != -1) {
os.write(buffer, 0, bytesRead);
}
is.close();os.close();
//Initialize the Cascade Classifier object using the
// trained cascade file
cascadeClassifier = new CascadeClassifier(cascadeFile.getAbsolutePath());
if (cascadeClassifier.empty()) {
Log.e(TAG, "Failed to load cascade classifier");
cascadeClassifier = null;
} else
Log.i(TAG, "Loaded cascade classifier from " + cascadeFile.getAbsolutePath());
cascadeDir.delete();
} catch (IOException e) {
e.printStackTrace();
Log.e(TAG, "Failed to load cascade. Exception thrown: " + e);
}
mOpenCvCameraView.enableView();
} break;
default:
{
super.onManagerConnected(status);
}
break;
}
}
};现在,我们准备处理每个相机帧,以检测闭合的手掌并自动拍照。
我们将使用的算法总结如下:
- 计算我们正在寻找的对象的最小尺寸(宽度和高度)。 在我们的情况下,最小尺寸将为框架尺寸的 20%。 当然,您可以根据需要更改最小大小,但是请注意,我们正在寻找的对象越小,检测算法将运行得越慢。
- 运行我们在当前帧上初始化的滑动窗口检测器,以第 1 步中指定的最小大小查找感兴趣的对象。
- 忽略假正面检测。 当滑动窗口检测器返回一个实际上不包含感兴趣对象的边界框时,就会发生误报检测。 为了最大程度地减少误报并稳定检测,我们执行以下操作:
- 首先,我们为每 100 个像素量化边界框。 换句话说,我们将相机帧划分为
100x100像素的空间存储桶,每个边界框根据其位置放置在相应的空间存储桶中。 - 其次,在
N个帧之后,我们检查是否有一个包含N边界框的存储桶。 这意味着对于N个连续帧来说,检测是稳定的,因此,它是假正例的可能性非常低。
- 首先,我们为每 100 个像素量化边界框。 换句话说,我们将相机帧划分为
- 一旦有了稳定的真实正检测(实际闭合手掌),便会保存当前的相机帧。
要开始实现此算法,我们首先需要更改CamView类以实现android.hardware.Camera.PictureCallback,以便为onPictureTaken()回调方法提供实现以保存给定的相机帧。
新的CamView类如下所示:
public class CamView extends JavaCameraView implements PictureCallback {
private static final String TAG = "AutoSelfie::camView";
private String mPictureFileName;
public CamView(Context context, AttributeSet attrs) {
super(context, attrs);
}
@Override
public void onPictureTaken(byte[] data, Camera camera) {
Log.i(TAG, "Saving a bitmap to file");
// The camera preview was automatically stopped. Start it
// again.
mCamera.startPreview();
mCamera.setPreviewCallback(this);
// Write the image in a file (in jpeg format)
try {
FileOutputStream fos = new FileOutputStream(mPictureFileName);
fos.write(data);
fos.close();
} catch (java.io.IOException e) {
Log.e("PictureDemo", "Exception in photoCallback", e);
}
}
public void takePicture(final String fileName) {
Log.i(TAG, "Taking picture");
this.mPictureFileName = fileName;
// Postview and jpeg are sent in the same buffers if the
//queue is not empty when performing a capture.
// Clear up buffers to avoid mCamera.takePicture to be stuck
//because of a memory issue
mCamera.setPreviewCallback(null);
// PictureCallback is implemented by the current class
mCamera.takePicture(null, null, this);
}
}一旦具备了保存相机帧的函数,就可以通过更改onCameraFrame()的实现来更新AutoSelfie 活动类,以便检测闭合的手掌:
public Mat onCameraFrame(CvCameraViewFrame inputFrame) {
//Flip around the Y axis
Core.flip(inputFrame.rgba(), mRgba, 1);
Core.flip(inputFrame.gray(),mGray,1);
if (mAbsoluteFaceSize == 0) {
int height = mGray.rows();
if (Math.round(height * mRelativeFaceSize) > 0) {
mAbsoluteFaceSize = Math.round(height * mRelativeFaceSize);
}
}
MatOfRect closedHands = new MatOfRect();
if (cascadeClassifier != null)
cascadeClassifier.detectMultiScale(mGray, closedHands, 1.1, 2, 2,new Size(mAbsoluteFaceSize, mAbsoluteFaceSize), new Size());
Rect[] facesArray = closedHands.toArray();
for (int i = 0; i < facesArray.length; i++)
{
Core.rectangle(mRgba, facesArray[i].tl(), facesArray[i].br(), HAND_RECT_COLOR, 3);
Point quatnizedTL=new Point(((int)(facesArray[i].tl().x/100))*100,((int)(facesArray[i].tl().y/100))*100);
Point quatnizedBR=new Point(((int)(facesArray[i].br().x/100))*100,((int)(facesArray[i].br().y/100))*100);
int bucktID=quatnizedTL.hashCode()+quatnizedBR.hashCode()*2;
if(rectBuckts.containsKey(bucktID))
{
rectBuckts.put(bucktID, rectBuckts.get(bucktID)+1);
rectCue.put(bucktID, new Rect(quatnizedTL,quatnizedBR));
}
else
{
rectBuckts.put(bucktID, 1);
}
}
int maxDetections=0;
int maxDetectionsKey=0;
for(Entry<Integer,Integer> e : rectBuckts.entrySet())
{
if(e.getValue()>maxDetections)
{
maxDetections=e.getValue();
maxDetectionsKey=e.getKey();
}
}
if(maxDetections>5)
{
Core.rectangle(mRgba, rectCue.get(maxDetectionsKey).tl(), rectCue.get(maxDetectionsKey).br(), CUE_RECT_COLOR, 3);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd_HH-mm-ss");
String currentDateandTime = sdf.format(new Date());
String fileName = Environment.getExternalStorageDirectory().getPath() + "/sample_picture_" + currentDateandTime + ".jpg";
mOpenCvCameraView.takePicture(fileName);
Message msg = handler.obtainMessage();
msg.arg1 = 1;
Bundle b=new Bundle();
b.putString("msg", fileName + " saved");
msg.setData(b);
handler.sendMessage(msg);
rectBuckts.clear();
}
return mRgba;
}让我们逐步讲解至的代码:
我们在 y 轴上翻转输入框以消除镜像效果:
//Flip around the Y axis
Core.flip(inputFrame.rgba(), mRgba, 1);
Core.flip(inputFrame.gray(),mGray,1);根据输入框的高度计算最小对象尺寸:
if (mAbsoluteFaceSize == 0) {
int height = mGray.rows();
if (Math.round(height * mRelativeFaceSize) > 0) {
mAbsoluteFaceSize = Math.round(height * mRelativeFaceSize);}}我们在级联分类器对象上调用detectMultiScale()方法来构建图像金字塔并在每个比例尺上运行滑动窗口检测器:
MatOfRect closedHands = new MatOfRect();
if (cascadeClassifier != null)
cascadeClassifier.detectMultiScale(mGray, closedHands, 1.1, 2, Objdetect.CASCADE_SCALE_IMAGE,new Size(mAbsoluteFaceSize, mAbsoluteFaceSize), new Size());我们使用以下参数调用detectMultiScale():
- 相机帧的灰度版本
- 空的
MatOfRect对象,用于存储检测到的边界框 - 比例因子,用于确定在每个比例下将输入帧减少多少(
1.1意味着将当前比例减少 10% 以构造金字塔中的下一个比例;具有较高的值意味着以更快的速度进行计算) 如果缩放比例在某些尺寸下未闭合手掌,则可能会丢失正面检测值) - 最小邻域大小,用于指定每次检测应保留多少个邻居才能保留; 否则,它将被丢弃(此参数用于减少误报,因为由于使用不同的比例,由于在同一区域中检测到许多真实邻居,因此真实误报会出现)-
flagCASCADE_SCALE_IMAGE缩放图像以构建图像金字塔 (因为还有另一种方法可以通过缩放特征来检测不同比例的对象),因此,为了提高表现和简化操作,我们将坚持在第 5 章,“应用 3-全景查看器” - 可以找到感兴趣对象的最小和最大尺寸
有了检测列表后,我们希望将它们分组为大小为100 x 100像素的空间分区,以通过不同的帧稳定检测并消除误报:
Rect[] facesArray = closedHands.toArray();
for (int i = 0; i < facesArray.length; i++){
//draw the unstable detection using the color red
Core.rectangle(mRgba, facesArray[i].tl(), facesArray[i].br(), HAND_RECT_COLOR, 3);
//group the detections by the top-left corner
Point quatnizedTL=new Point(((int)(facesArray[i].tl().x/100))*100,((int)(facesArray[i].tl().y/100))*100);
//group the detections by the bottom-right corner
Point quatnizedBR=new Point(((int)(facesArray[i].br().x/100))*100,((int)(facesArray[i].br().y/100))*100);
//get the spatial bucket ID using the grouped corners hashcodes
int bucktID= quatnizedTL.hashCode()+quatnizedBR.hashCode()*2;
//add or increase the number of grouped detections per bucket
if(rectBuckts.containsKey(bucktID)){
rectBuckts.put(bucktID, rectBuckts.get(bucktID)+1);
rectCue.put(bucktID, new Rect(quatnizedTL,quatnizedBR));
}
else{
rectBuckts.put(bucktID,1);
}
}我们对检测到对象的帧数进行阈值指示稳定检测。 如果帧数大于阈值,则保存当前帧:
int maxDetections=0;
int maxDetectionsKey=0;
for(Entry<Integer,Integer> e : rectBuckts.entrySet()){
if(e.getValue()>maxDetections){
maxDetections=e.getValue();
maxDetectionsKey=e.getKey();
}
}
//Threshold for a stable detection
if(maxDetections>5){
//Draw the stable detection in green
Core.rectangle(mRgba, rectCue.get(maxDetectionsKey).tl(), rectCue.get(maxDetectionsKey).br(), CUE_RECT_COLOR, 3);
//build the file name
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd_HH-mm-ss");
String currentDateandTime = sdf.format(new Date());
String fileName = Environment.getExternalStorageDirectory().getPath() +"/sample_picture_" + currentDateandTime + ".jpg";
//take the picture
mOpenCvCameraView.takePicture(fileName);
//show a notification that the picture is saved
Message msg = handler.obtainMessage();msg.arg1 = 1;
Bundle b=new Bundle();b.putString("msg", fileName + " saved");
msg.setData(b);handler.sendMessage(msg);
//clear the spatial buckets and start over
rectBuckts.clear();
}
return mRgba;
}总结
在本章中,我们基于著名的层叠分类器构建了一个用于自动拍照的新应用。 我们已经看到了从使用的特征类型到自适应提升学习算法和级联构建级联分类器的过程。 您还学习了如何使用经过训练的分类器来初始化和使用基于多尺度滑动窗口的检测器,以检测手掌闭合手势,并将这些检测作为提示从设备的相机捕获帧。
腾讯云开发者
