猿创征文 | 大数据比赛以及日常开发工具箱

猿创征文 | 大数据比赛以及日常开发工具箱


最近一直在参加安徽省大数据与人工智能应用竞赛,因此学习了很长一段时间的大数据,也积攒了一些大数据的开发经验;工欲善其事,必先利其器,所以想要给准备学习大数据的同学总结一下自己在大数据开发中所用到的工具。
一、VMware Workstation
1、 VMware Workstation 简介及使用场景
VMware Workstation,相信大家都不陌生了,由于目前的大部分的电脑都是预装了 Windows ,不少和我一样为了避免安装双系统从而进行 Linux 等方面的开发的用户就会使用该软件来安装 Linux 虚拟机来进行相关开发。而在日常大数据的学习及开发中,会需要搭建 “一主二从” 的计算机集群,如果使用物理机搭建集群,对于我这样一个学生党来说是负担不起的;而通过 VMware Workstation 便可以虚拟化物理设备,来在主机上安装多个操作系统,从而来搭建多计算机集群。
VMware 界面展示
2、VMware 的优势
当然,能够实现搭建计算机集群功能的不止 VMware,像是免费的 VirtualBox、Windows 自带的 Hyper-V 等等,那为什么要选择 VMware 呢?主要是因为以下几点优势:
1、首先,VMware 在硬件虚拟化这个方向算是老大,相较于 VirtualBox 等其他硬件虚拟化平台,VMware WorkStation 更加地稳定,而且出错了在网络上或是官网上都能找到答案。
2、其次,VMware 能够提高硬件利用率,降低相关开销,同时兼具灵活性和可控性,在给虚拟机分配硬件资源时更加容易操作。
3、VMware 能够桥接到本机,即模拟了真实的实验环境,又保证了本机的安全。
二、Xshell
1、Xhell 简介及使用场景
有了虚拟机,就要想办法对虚拟机进行连接,如果不使用桌面的话,一直对着卡顿的虚拟机命令行敲命令是很难受的。而使用一款中端模拟软件就能轻松的解决这个问题。这里我强推 XShell,尤其是 Xshell 最近推出了个人免费版,不再需要花钱或上网寻找破解版来使用该软件;其次,该软件还有一个配套软件 Xftp,与 Xshell 同样好用,只需要 Xshell 连接到虚拟机,便可以点击 Xftp 图标来使用 Xftp 将本机文件发送到虚拟机节点上。

Xshell 界面展示
2、Xshell 的优势
当然,能够进行 SSH 连接到虚拟机的应用不止 Xshell,像是 Putty、XManager、secureCRT 甚至你的 CMD 都是可以进行 SSH 连接的。但我独钟 Xshell,主要体现在以下几点:
- 界面设计清晰简洁,让人一目了然,非常符合自己开发时的需求。
- 可以保存自己的终端,大部分 SSH 连接软件每次用完之后再次使用还要再次输入,非常难受;而且 Xshell 可以保存自己终端的账号密码,每次点击即用,非常方便。
- 支持多标签,一机多连,多机多连。这对大数据分布式开发来说是非常重要的,因为大数据经常要搞集群,需要连接多个主机,多标签可以让你无需来回切换窗口,即可完成操作。
- Xftp 与 Xshell 互联,传输文件非常方便,无需安装多个软件即可进行文件传输操作。
- 最主要的是目前 Xshell 面向个人用户推出了免费版本,大家可以放心食用。
三、IDEA
1、IDEA 简介及使用场景
IDEA嘛,相信大家都懂的😁,学习过 Java 的小伙伴一定都了解或使用过这款软件吧!虽然相较于 Eclipse、MyEclipse 等软件来说有点吃性能,但毕竟 2022 年了,电脑的性能已经比之前强了不少,JetBrain 也对 IDEA 的性能做了优化,使用 IDEA 用来学习 Java 是非常不错滴👍。而且如果你是 Java 基础来学习大数据,只需要安装 Scala 插件,就能在一个编译器上使用 Java 编写 MapReduce 代码以及使用 Scala 编写 Spark 代码了。其次,IDEA 中自带了很多插件,像是 Maven 插件,让你不用配置繁琐的 Maven 本地环境就可以体会到 Maven 所给你带来的便捷,其它的插件大家也可以自行探索哦!
IDEA 界面展示
四、Hadoop
1、Hadoop 简介及使用场景
提到大数据,就必不可少的要提到 Hadoop 了。Hadoop 是由 Apache 基金会所开发的分布式系统基础架构,可以让用户在不了解分布式底层细节的情况下进行分布式项目的开发。Hadoop 主要由 HDFS、MapReduce、YARN 组成, 下图中的 Hadoop 生态主要是依托于 Hadoop 平台而相互兼容、发展起来的应用框架,进行大数据开发就要从 Hadoop 这块基石开始学习,进而扩展,强化自己的能力。

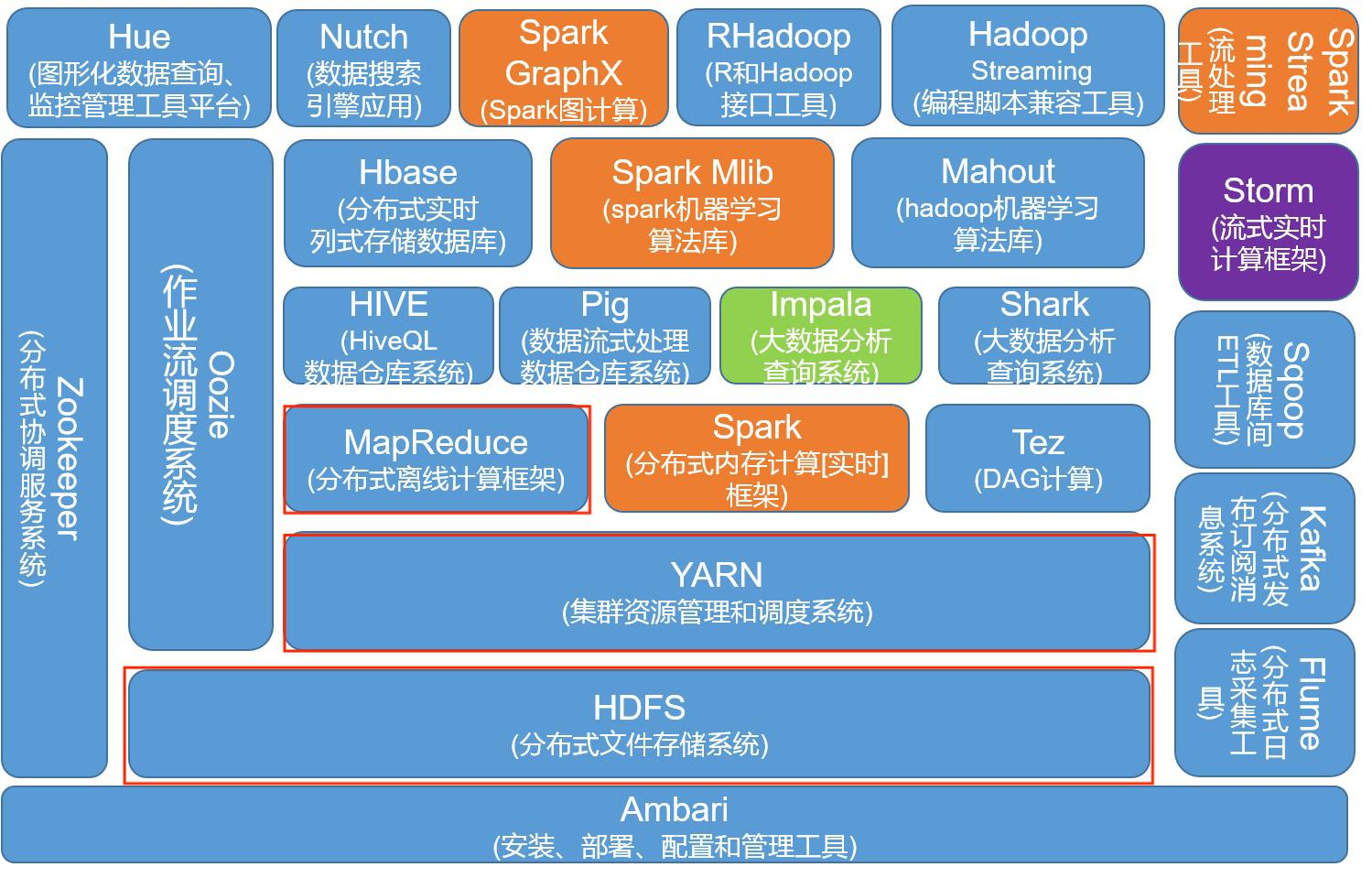
Hadoop 生态图
2、为什么选择 Hadoop?
当然,站在企业的角度来说,Hadoop 可以解决问题,并且最主要的是成本低与其完整的生态圈。其次,Hadoop 的高可靠性、高扩展性、高效性、高容错性都为大数据的开发提供了保障。总结来说有以下几点:
- 速度:Hadoop 允许跨数据集进行并行处理,可以将任务拆分并在分布式服务器上并发运行。
- 容错:Hadoop 可以处理某个节点发生故障以及某些数据文件损坏的情况,可以从其它节点上进行数据恢复。
- 可扩展:Hadoop 分布式文件系统(简称 HDFS)允许数据拆分,并通过简单的硬件配置将数据存储到服务器集群中。
- 多种格式:Hadoop 文件系统可以存储各种数据格式,包括非结构化数据(如视频文件)、半结构化数据(如 XML 文件)与结构化数据(SQL 数据库中包含的数据)。
- 开源:Hadoop 遵循 Apache 开源协议,每个人以及企业都可以使用 Hadoop 来搭建自己的项目,并参与到项目的构建中。
五、Hive
1、Hive 简介及使用场景
Hive 是一个构建在 Hadoop 上的数据仓库工具,通过 Hive,能够将结构化的数据文件映射为一张数据库表,并通过 SQL 语句转变成 MapReduce 来完成数据的查询功能。当然,这也是比赛以及大数据开发中的重要一环。在比赛中,一般会有一大题是使用 Hive 进行结构化数据操作的,学习过 SQL 的小伙伴一般都能完成。而在开发以及生产过程中,Hive 突出的优势在于一些对于实时性要求不高的场合,比如数据分析,高效地处理大数据。

六、Spark
1、Spark 简介及使用场景
Spark 是 Apache 开源的一种专门用于交互式查询、机器学习和实时工作负载的开源框架,通过内存处理的方式,能够极大的提高大数据分析的效率以及性能。从一些学术网站上也可以看到,关于 Spark 的论文数量也是非常多的,这也意味着 Spark 仍然是一个比较流行的技术,目前在大数据开发中也是一项不可或缺的技术。在一些实时性较高的场景下,Spark 应用的场景更为广泛。

2、Spark vs Hadoop(Spark 的特点)
业内,人们常用 Hadoop 与 Spark 作比较,以此来体现 Spark 的优势所在;这里我们也与 Hadoop 作对比,体现一下 Spark 的优势所在:
- 处理速度方面,Spark 会比 Hadoop 快很多,据说在 10~100 倍,这是因为 Spark 是直接在内存中处理数据,并不需要读写磁盘;而 Hadoop 的数据存储在各个分布式的数据源上,并通过 MapReduce 进行处理,与磁盘交互更多。
- 可扩展性方面, 当数据量快速增长时,Hadoop 通过 Hadoop分布式文件系统(HDFS)快速扩展以适应需求。反过来,Spark 依赖于容错的 HDFS 来处理大量数据。
- 机器学习方面,Spark 能够更好地进行机器学习方相关操作,Spark 的 MLLib 库可以让其在内存中迭代执行 ML 的计算,从而更好的完成机器学习的相关操作。
七、Obsidian
1、Obsidian 功能简介
Obsidian 是我一直推荐的免费笔记软件,每次学习大数据的内容我都会记录到这款软件里;最近 Obsidian 更新到了 1.0 版本,在界面性能等方面都进行了优化,更是让我爱不释手。Obsidian 还具有文档关系图谱、插件扩展等引人注目的功能;通过文档关系图谱,我们就能轻松管理知晓文档之间的联系,以便梳理自己的思维;通过安装插件,就能够丰富 Obsidian 的功能,比如思维脑图、Excalidraw 绘图等功能。还在为没有合适的笔记软件而发愁的小伙伴一定要试一试。
Obsidian 界面展示
八、JupyterLab
1、JupyterLab 简介及使用场景
相信不少使用过 Python 的同学都使用过 Jupyter Notebook 吧,毕竟大部分教程似乎都是使用 Jupyter Notebook 平台来完成的。然而,在使用 Jupyter Notebook 的时候总是感觉有些力不从心,代码提示、文件目录浏览等功能都没有在 Jupyter Notebook 上得以实现。而 JupyterLab 具有更好的交互性,模块化界面设计以及同一文档多视图等特点都能够帮助我们更好地开发,百度飞桨的 BML CodeLab、和鲸社区的 ModelWhale 似乎都是基于 JupyterLab 打造,以便给用户带来更好的体验。
JupyterLab 界面展示
九、Pyecharts
1、Pyecharts 简介及使用场景
分析完数据后,如何将我们分析的数据精美地呈现出来呢?Pyecharts 绝对不能错过。Echarts 是百度开源的数据可视化工具,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可,将 Echarts 与 Python 结合,Pyecharts 便由此诞生。使用 Pyecharts 来进行数据可视化,能够向他人展现出十分惊艳的效果。(下图是使用 Pyecharts 画出的 3D 地图)
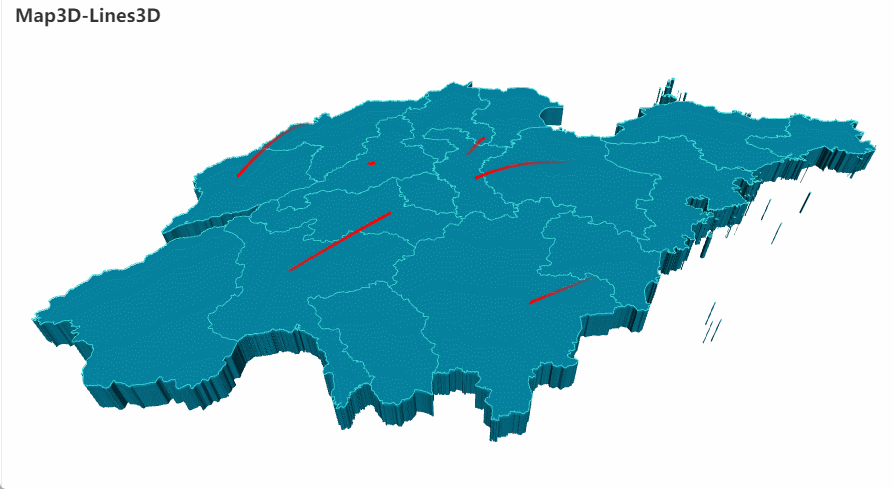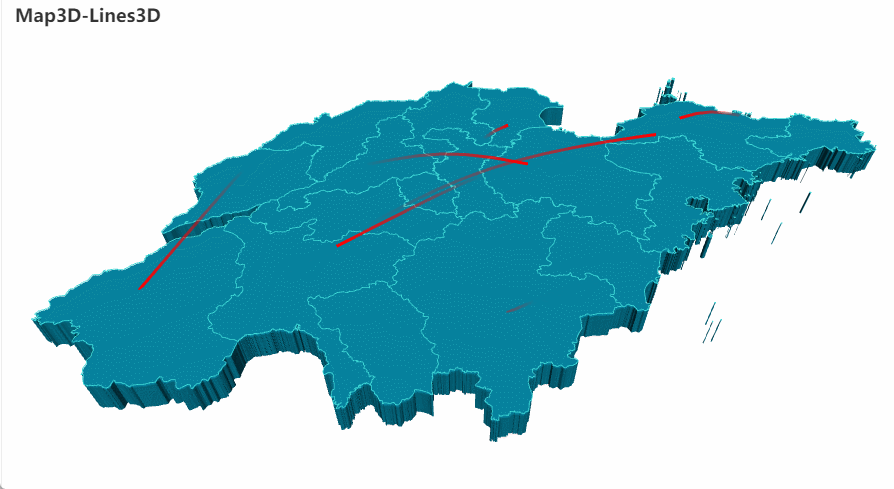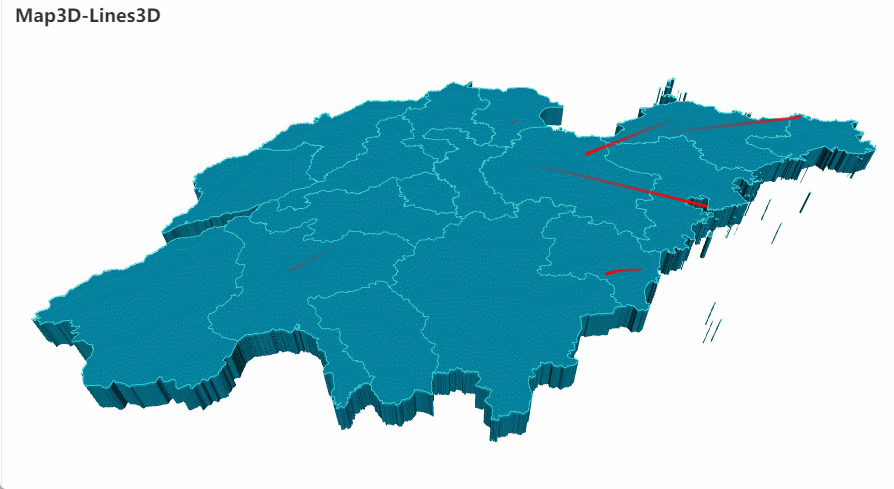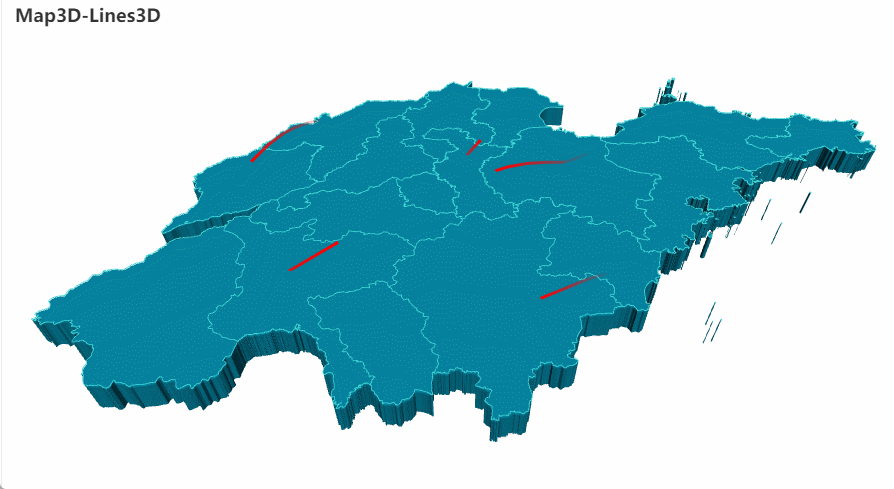
Pyecharts 3D地图案例
2、Pyecharts、Matplotlib 比赛时混用建议
有些时候,我们只需要将我们的数据以图形的方式展现出来即可,并不需要过于的美观图形时(比如我们比赛时,时间紧急),可以考虑 Pyecharts 与 Matplotlib 混用的方式。这里不是指将两者的 api 以嵌套等方式结合起来,而是根据情况分别使用 Pyecharts 与 Matplotlib 进行作图。因为 Matplotlib 作图不需要写太多的代码,而且逻辑比较简单,相应的,功能也比较简单;当遇到 Matplotlib 做不了的图时(比如地图等),然后考虑使用 Pyecharts 来作图(毕竟比赛时间宝贵!)。
当然生产环境下还是使用 Pyecharts 比较好,毕竟需要用户认可才会买单。
十、Docker
1、Docker 简介及使用场景
容器技术是一种轻量级的虚拟化技术,随着云原生技术的发展而主键发展起来,其中比较出名的容器技术就是 Docker。Docker 是一个开源平台,它将应用源代码与操作系统(OS)库和在任何环境中运行该代码所需的依赖性结合起来,使开发者能够更快速的完成构建、部署、运行环境的需求。我在学习 Pyspark 时,因为懒得搭环境,就可以从 DockerHub 中直接拉取别人制作好的 pyspark 镜像,并直接运行即可,免去了安装操作系统、安装 Hadoop、Spark 等环境的麻烦。容器技术在未来的很长一段时间都不会没落,因此也建议学习计算机的小伙伴能够学习一下容器技术。
Docker 界面展示
2、Docker vs 虚拟机(Docker 的优势)
刚接触 Docker 小伙伴可能会认为 Docker 可以替代虚拟机了,但是实际上,两者还是有很大的差别的:
- 从性能上来看,Docker 所需的资源更少,这是因为 Docker 是轻量级架构,并且在操作系统级别进行虚拟化,直接与内核进行交互。而虚拟机则是在操作系统上插入了一个精简的软件曾,从而将计算机的资源抽象、转换后呈现出来。如果没有特殊需求的话,Docker 更适合大多数人的选择。
- 从兼容性来说,Docker 软件以及容器的移植更为方便,无需耗费太多的精力来考虑兼容性的问题;而移植一个系统到虚拟机软件来说是非常麻烦的。
- 从安全性来说,虚拟机不共享操作系统,与主机系统内核存在强制隔离,而容器与主机的隔离性很低,容器中可能存在风险以及漏洞,会对主机操作系统造成伤害。
- 从开发效率来说,个人觉得使用 Docker 更能会让开发效率翻倍,启动速度秒级,能运行的镜像数量远超于虚拟机,部署迅速等,都会减轻个人开发过程中的负担。
总的来说,Docker 是面向服务的,虚拟机是面向操作系统的,两者各有优劣,需要根据自己的需求来具体选择使用。
工具有很多种,只有选择好趁手的武器,才能更容易打怪升级。希望大家都能选择合适自己的工具,在自己所选的道路上越走越远!👍
腾讯云开发者
