开源了一个免费的搜索引擎工具,可以给你的ChatGPT插上翅膀了
原创
开源了一个免费的搜索引擎工具,可以给你的ChatGPT插上翅膀了
原创
本文介绍了自己开源搜索引擎工具 https://github.com/bravekingzhang/search-engine-tool
可以通过给ChatGPT提供最新的知识上下文来解决其训练知识的局限性。
1. 背景
因为OpenAI的横空出世,大家都习惯于使用OpenAI来问问题,但是OpenAI有一个致命的问题,就是只知道他训练的知识,而不知道新的知识,比如你问他今天深圳的天气如何,问他一些热点新闻,他是没有任何概念的。
解决办法
通常我们为了让大模型“感知“到新的知识,我们需要将新的知识材料提供给他大模型学习,因此基于软件开发第一定律,没有什么是做不到的,如果做不到,就加一层,如果还是做不到,就在加一层,咋们这个层就是一个通过搜索获取当前最新信息的层,将摘要给到大模型学习,然后大模型基于这些个新学习的知识来回答你的问题。
下面是这个工具搜索信息的效果,搜索结果可以通过参数控制条数,这样喂给ChatGPT等工具的信息不至于过多。
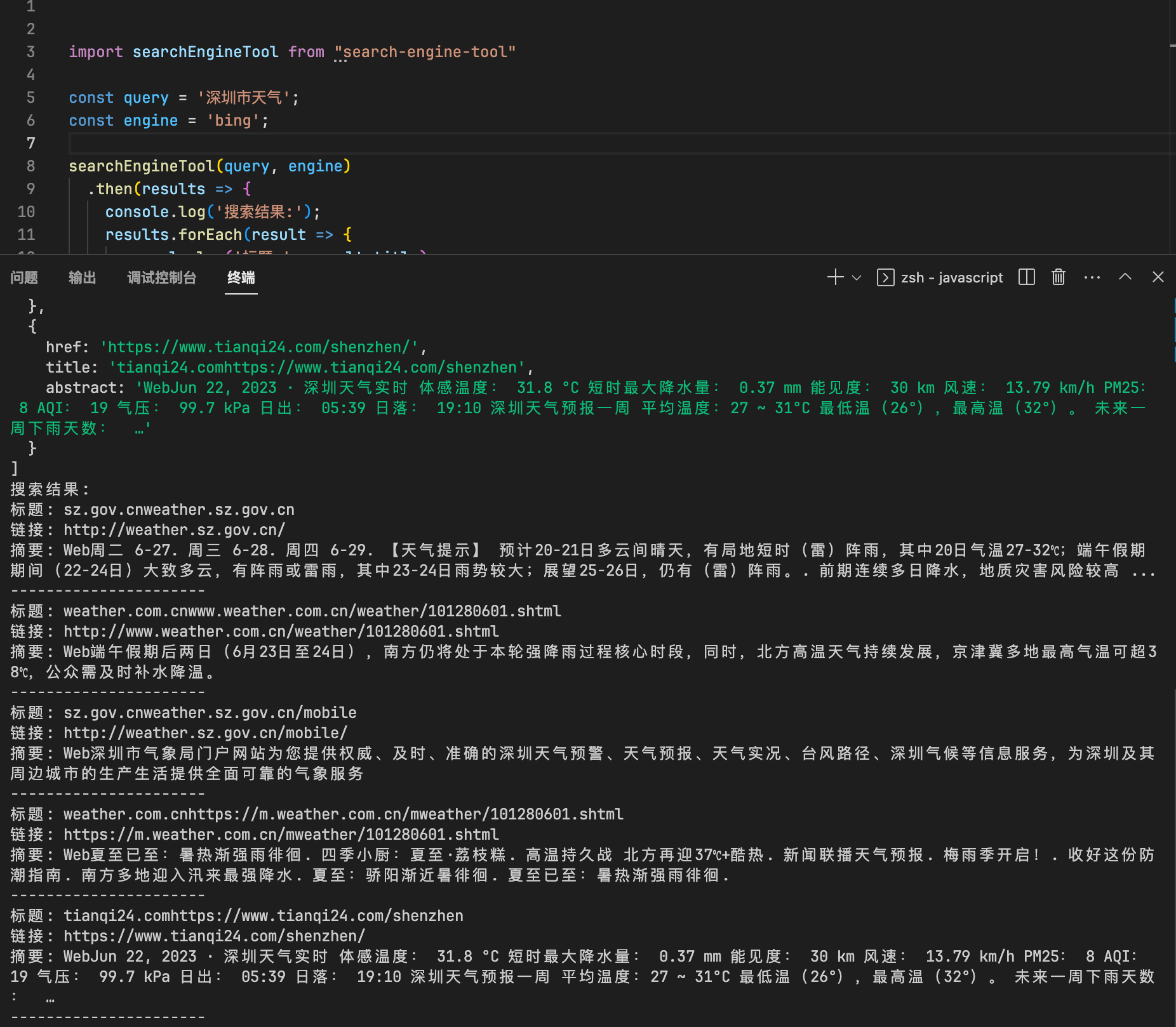
方案对比
为什么不直接使用 Google search API,而要自己造轮子,其原因就是一是因为巨硬们提供的API都是要付费的,免费计划也需要绑visa卡等,特别麻烦,因此还不如自己动手实现一个免费的。
2.原理
原理很简单,使用 无头浏览器 去访问 Google,bing 等搜索网站,分析网页内容,提取摘要。下面我直接给出搜索bing的代码:
async function bingSearch(query) {
try {
//https://serpapi.com/bing-search-api
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(
`https://www.bing.com/search?form=QBRE&q=${encodeURIComponent(
query
)}&cc=US`
);
const summaries = await page.evaluate(() => {
const liElements = Array.from(
document.querySelectorAll("#b_results > .b_algo")
);
const firstFiveLiElements = liElements.slice(0, 5);
return firstFiveLiElements.map((li) => {
const abstractElement = li.querySelector(".b_caption > p");
const linkElement = li.querySelector("a");
const href = linkElement.getAttribute("href");
const title = linkElement.textContent;
const abstract = abstractElement ? abstractElement.textContent : "";
return { href, title, abstract };
});
});
await browser.close();
console.log(summaries);
return summaries;
} catch (error) {
console.error("An error occurred:", error);
}
}这里,搜索使用无头浏览器打开构造好的查询链接,然后等待网页渲染完,无头浏览器的好处就是可以将异步内容获取到,如果有些搜索工具不是异步返回搜索结果的,那么连无头浏览器都不需要,直接使用axios访问,拿到body,使用cheeryio解析就更快了,但是原理都是一样的。
通过querySelector方式拿到一些搜索的条目,获取链接等等,组装成一个搜索元信息就处理完了一个,这里最关键的是通过querySelector获取需要的搜索结果,有一个简单的办法,使用console控制台打开,然后选中元素:
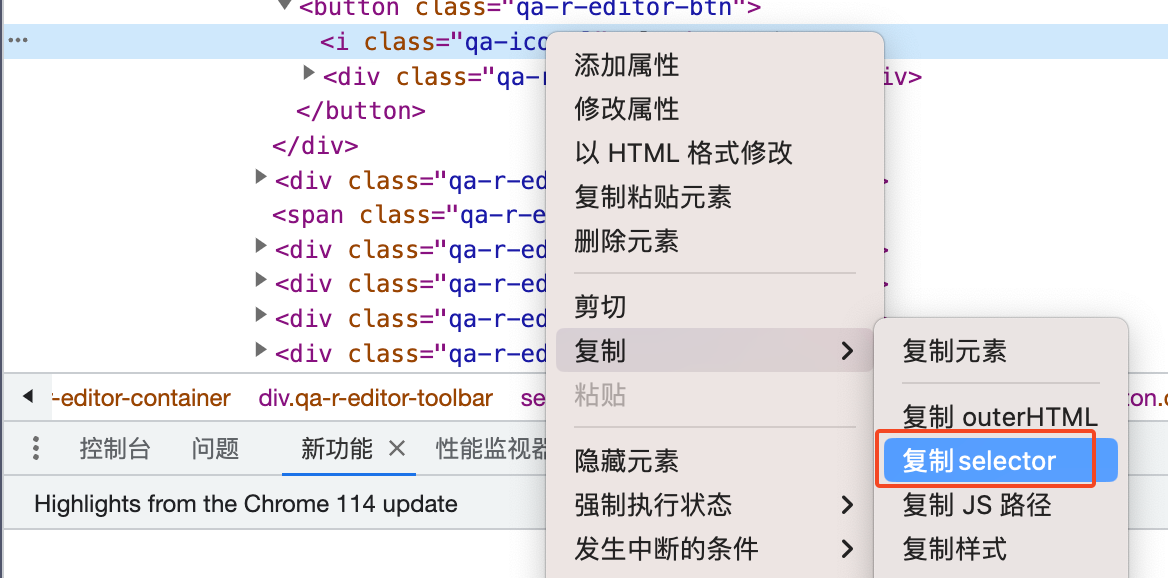
复制selector ,在做一些简单的调整即可拿到你要的元素的路径了。
其他的,一些搜索工具如Google,等就不再一一介绍,原理都是一样。
3.总结
这样子,我们通过一定的prompt工程,把用户询问的问题工具prompt工具包装一下,交给ChatGPT去回答,ChatGPT就可以基于当前的知识进行回答了。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
