盘点一个Python自动化办公的问题——批量实现文件重命名(方法一)

盘点一个Python自动化办公的问题——批量实现文件重命名(方法一)

Python进阶者
发布于 2023-08-31 08:59:57
发布于 2023-08-31 08:59:57
一、前言
前几天在Python最强王者群【维哥】问了一个Python自动化办公处理的问题,一起来看看吧。
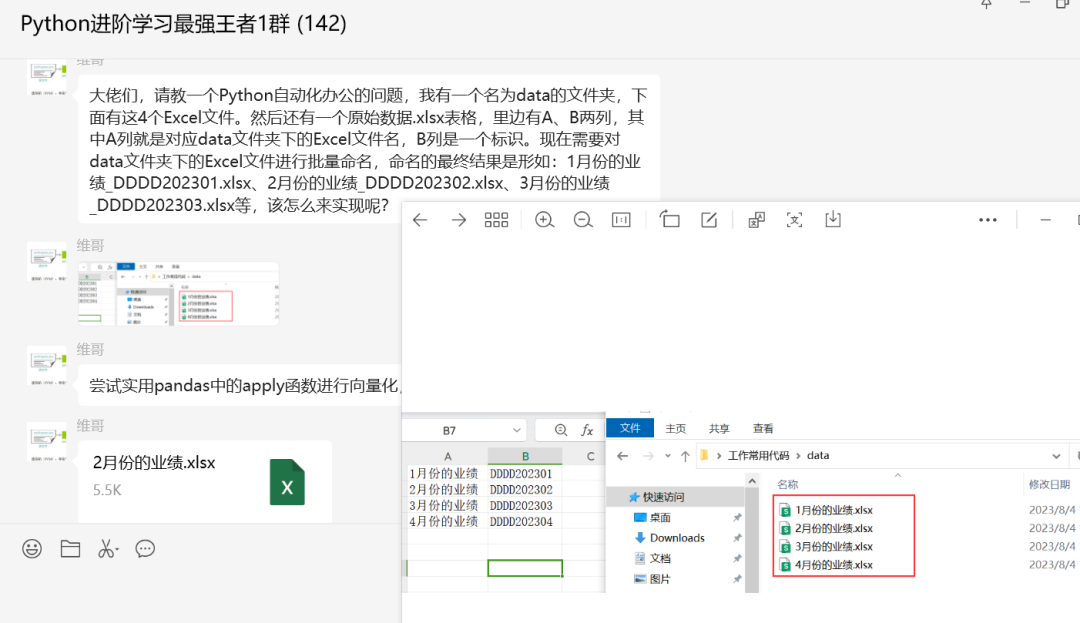
大佬们,请教一个Python自动化办公的问题,我有一个名为data的文件夹,下面有这4个Excel文件。然后还有一个原始数据.xlsx表格,里边有A、B两列,其中A列就是对应data文件夹下的Excel文件名,B列是一个标识。现在需要对data文件夹下的Excel文件进行批量命名,命名的最终结果是形如:1月份的业绩_DDDD202301.xlsx、2月份的业绩_DDDD202302.xlsx、3月份的业绩_DDDD202303.xlsx等,该怎么来实现呢?
二、实现过程
这个问题挺有意思的,而且是工作过程中时常会遇到的工作场景,非常实用,这里给大家一起分享下方法。这里【东哥】提供了一个解决办法,代码如下所示:
import os
import pandas as pd
# 读取原始数据.xlsx文件
df = pd.read_excel('原始数据.xlsx')
# 遍历data文件夹下的Excel文件
data_path = './data/'
files = os.listdir(data_path)
for file in files:
if file.endswith('.xlsx'):
# 获取文件名和文件后缀
file_name, file_ext = os.path.splitext(file)
# 获取月份信息
month = file_name[:2]
# 获取标识信息
id_num = df[df['文件名'] == file_name]['标识'].values[0]
# 新文件名
new_file_name = month + '份的业绩_' + id_num + file_ext
# 文件重命名
os.rename(data_path + file, data_path + new_file_name)
@维哥
代码运行之后,测试无误,
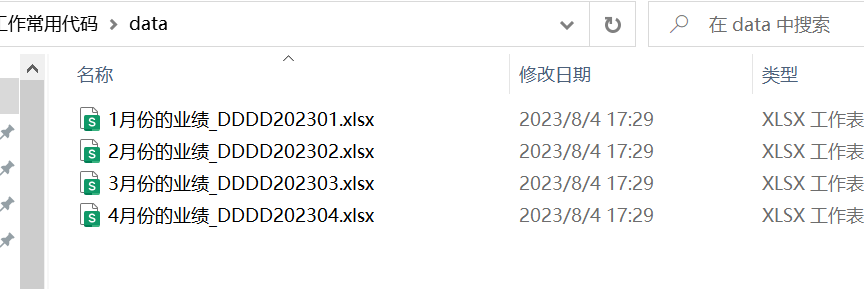
顺利地解决了粉丝的问题。

不过后来【吴超建】发现了一个问题,要是10月11月12月就有问题了,因为取值那块写死了,固定取的[:2],下一篇文章我们一起来看另外一个优化方法,顺利的解决当前的小问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python自动化办公Excel列删除处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
往期精彩文章推荐:
- if a and b and c and d:这种代码有优雅的写法吗?
- Pycharm和Python到底啥关系?
- 都说chatGPT编程怎么怎么厉害,今天试了一下,有个静态网页,chatGPT居然没搞定?
- 站不住就准备加仓,这个pandas语句该咋写?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-24,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Python爬虫与数据挖掘 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号