ByConity(ByteHouse) CascadesOptimizer 初探 1
原创
ByConity(ByteHouse) CascadesOptimizer 初探 1
原创
jasong
修改于 2023-08-31 21:28:18
修改于 2023-08-31 21:28:18
一 ByConity Rewriter
~/Codes/Myself/C++/cpp_etudes/cpptree.pl Rewriter '' 1 0
^Rewriter$
└── Rewriter [vim Optimizer/Rewriter/Rewriter.h +28]
├── AddDynamicFilters [vim Optimizer/Rewriter/AddDynamicFilters.h +34]
├── AddExchange [vim Optimizer/Rewriter/AddExchange.h +30]
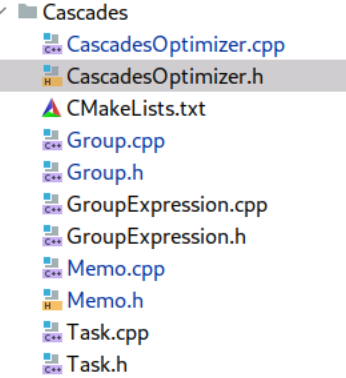
├── CascadesOptimizer [vim Optimizer/Cascades/CascadesOptimizer.h +40]
├── ColumnPruning [vim Optimizer/Rewriter/ColumnPruning.h +24]
├── IterativeRewriter [vim Optimizer/Iterative/IterativeRewriter.h +45]
├── MaterializedViewRewriter [vim Optimizer/Rewriter/MaterializedViewRewriter.h +33]
├── PredicatePushdown [vim Optimizer/Rewriter/PredicatePushdown.h +25]
├── RemoveCorrelatedExistsSubquery [vim Optimizer/Rewriter/RemoveApply.h +223]
├── RemoveCorrelatedInSubquery [vim Optimizer/Rewriter/RemoveApply.h +163]
├── RemoveCorrelatedQuantifiedComparisonSubquery [vim Optimizer/Rewriter/RemoveApply.h +284]
├── RemoveCorrelatedScalarSubquery [vim Optimizer/Rewriter/RemoveApply.h +60]
├── RemoveRedundantSort [vim Optimizer/Rewriter/RemoveRedundantSort.h +24]
├── RemoveUnCorrelatedExistsSubquery [vim Optimizer/Rewriter/RemoveApply.h +243]
├── RemoveUnCorrelatedInSubquery [vim Optimizer/Rewriter/RemoveApply.h +203]
├── RemoveUnCorrelatedQuantifiedComparisonSubquery [vim Optimizer/Rewriter/RemoveApply.h +263]
├── RemoveUnCorrelatedScalarSubquery [vim Optimizer/Rewriter/RemoveApply.h +125]
├── RemoveUnusedCTE [vim Optimizer/Rewriter/RemoveUnusedCTE.h +28]
├── SimpleReorderJoin [vim Optimizer/Rewriter/SimpleReorderJoin.h +29]
├── SimplifyCrossJoin [vim Optimizer/Rewriter/SimplifyCrossJoin.h +29]
├── UnifyJoinOutputs [vim Optimizer/Rewriter/UnifyJoinOutputs.h +25]
└── UnifyNullableType [vim Optimizer/Rewriter/UnifyNullableType.h +39]
主要先分享 CascadesOptimizer 二 基础知识
Rewriter 初始化过程
查询过程主要有 class InterpreterSelectQueryUseOptimizer : public IInterpreter 初始化和执行
static std::tuple<ASTPtr, BlockIO> executeQueryImpl(
const char * begin,
const char * end,
ContextMutablePtr context,
bool internal,
QueryProcessingStage::Enum stage,
bool has_query_tail,
ReadBuffer * istr)
{
..
ParserQuery parser(end, ParserSettings::valueOf(settings.dialect_type));
parser.setContext(context.get());
/// TODO: parser should fail early when max_query_size limit is reached.
ast = parseQuery(parser, begin, end, "", max_query_size, settings.max_parser_depth);
auto interpreter = InterpreterFactory::get(ast, context, SelectQueryOptions(stage).setInternal(internal));
res = interpreter->execute();
}
std::unique_ptr<IInterpreter> InterpreterFactory::get(ASTPtr & query, ContextMutablePtr context, const SelectQueryOptions & options)
{
if (query->as<ASTSelectQuery>())
{
if (QueryUseOptimizerChecker::check(query, context)) {
return std::make_unique<InterpreterSelectQueryUseOptimizer>(query, context, options);
}
/// This is internal part of ASTSelectWithUnionQuery.
/// Even if there is SELECT without union, it is represented by ASTSelectWithUnionQuery with single ASTSelectQuery as a child.
return std::make_unique<InterpreterSelectQuery>(query, context, options);
}
...
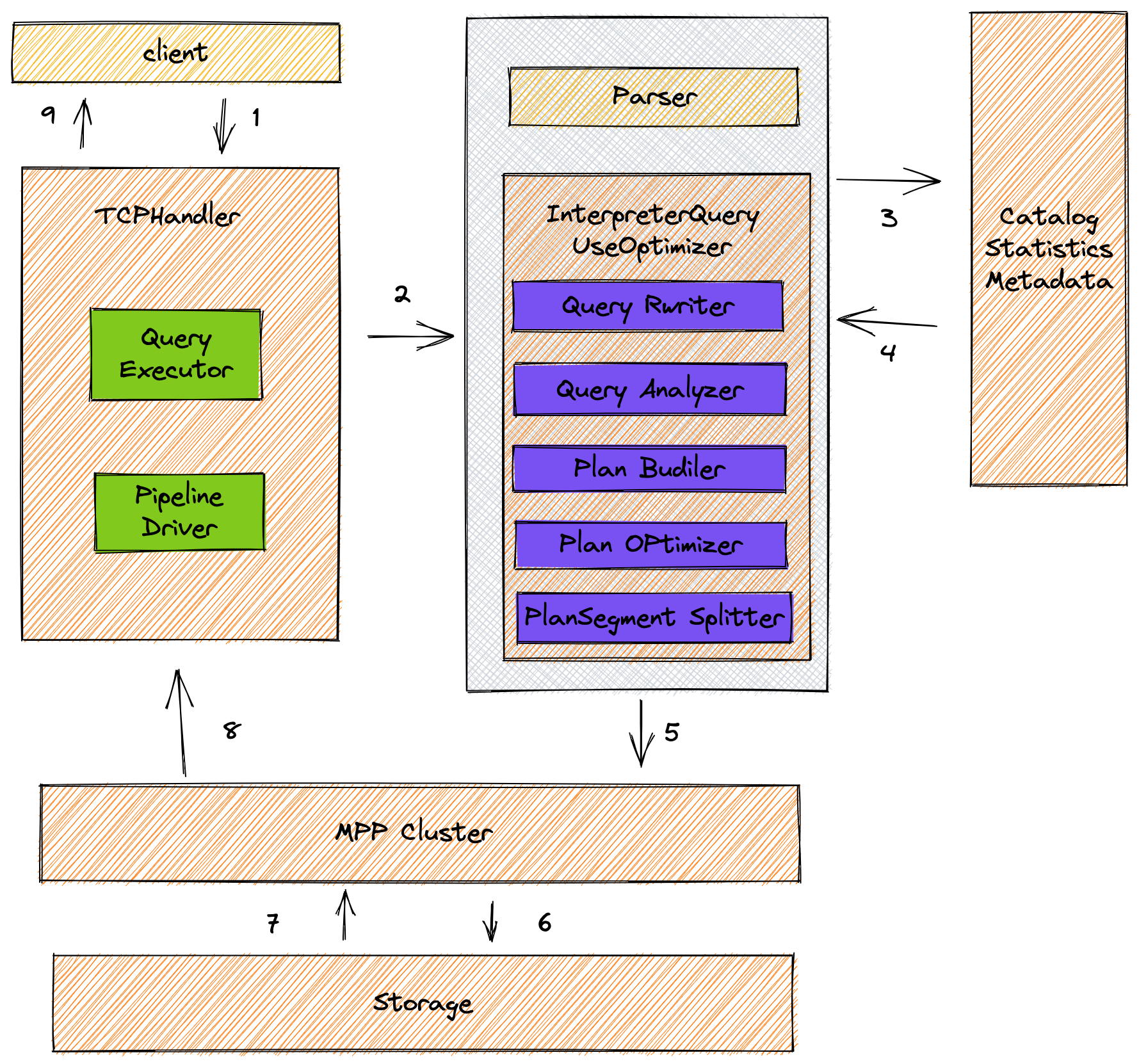
}buildQueryPlan() 四步走
ast -> rewrite -> ananlyze -> query paln -> optimizer
buildQueryPlan()
BlockIO InterpreterSelectQueryUseOptimizer::execute()
->1 getPlanSegment();(PlanSegmentTreePtr InterpreterSelectQueryUseOptimizer::getPlanSegment())
->1.2 buildQueryPlan(); (QueryPlanPtr InterpreterSelectQueryUseOptimizer::buildQueryPlan())
{
//ast -> rewrite -> ananlyze -> query paln -> optimizer
auto cloned_query = query_ptr->clone();
cloned_query = QueryRewriter().rewrite(cloned_query, context);
AnalysisPtr analysis = QueryAnalyzer::analyze(cloned_query, context);
query_plan = QueryPlanner().plan(cloned_query, *analysis, context);
PlanOptimizer::optimize(*query_plan, context);
return query_plan
}
1 QueryAnalyzer::analyze
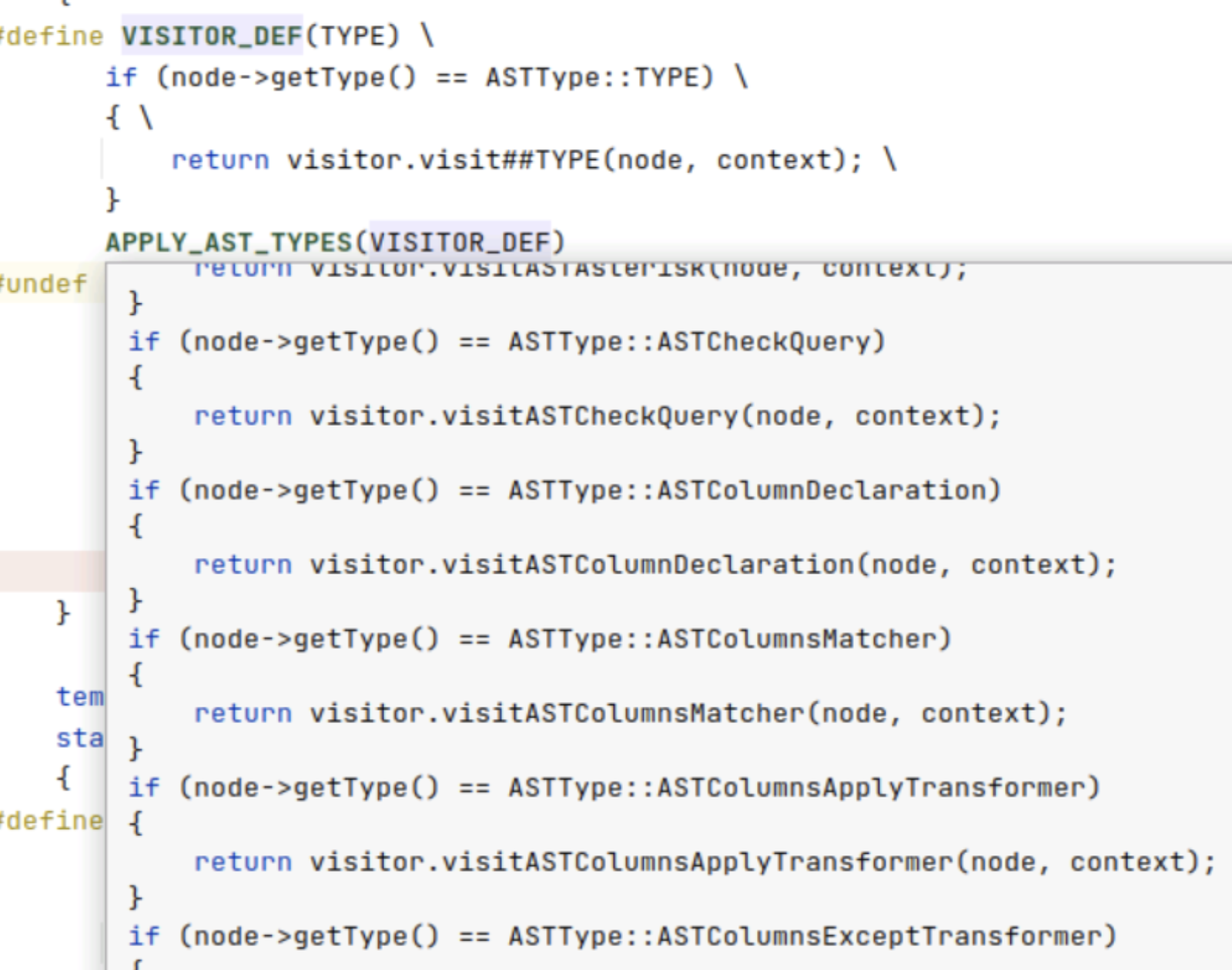
首先介绍一个类 ASTVisitorUtil, 该类accept 方法哄定义实现, 将 ASTVisitor 抽象方案virtual R visit##TYPE, 不但解析于对子类的调用
template <typename R, typename C>
class ASTVisitor
{
public:
virtual ~ASTVisitor() = default;
virtual R visitNode(ASTPtr &, C &) { throw Exception("Visitor does not supported this AST node.", ErrorCodes::NOT_IMPLEMENTED); }
#define VISITOR_DEF(TYPE) \
virtual R visit##TYPE(ASTPtr & node, C & context) { return visitNode(node, context); }
APPLY_AST_TYPES(VISITOR_DEF)
#undef VISITOR_DEF
};
class ASTVisitorUtil
{
public:
template <typename R, typename C>
static R accept(ASTPtr && node, ASTVisitor<R, C> & visitor, C & context)
{
return accept(node, visitor, context);
}
template <typename R, typename C>
static R accept(ASTPtr & node, ASTVisitor<R, C> & visitor, C & context)
{
#define VISITOR_DEF(TYPE) \
if (node->getType() == ASTType::TYPE) \
{ \
return visitor.visit##TYPE(node, context); \
}
APPLY_AST_TYPES(VISITOR_DEF)
#undef VISITOR_DEF
/* #define qianru #define
if(node->getType() == ASTType::ASTSelectQuery) {
return visitor.visitASTSelectQuery(node, context);
}*/
return visitor.visitNode(node, context);
}
我们看下围绕ASTVistor的子类实现
~/Codes/Myself/C++/cpp_etudes/cpptree.pl ASTVisitor '' 1 0
^ASTVisitor$
└── ASTVisitor [vim Parsers/ASTVisitor.h +61]
├── DomainVisitor [vim Optimizer/DomainTranslator.h +56]
├── ExprAnalyzerVisitor [vim Analyzers/ExprAnalyzer.cpp +56]
├── ExpressionWithAggregateRewriter [vim Optimizer/Rewriter/MaterializedViewRewriter.cpp +912]
├── QueryAnalyzerVisitor [vim Analyzers/QueryAnalyzer.cpp +71]
├── QueryPlannerVisitor [vim QueryPlan/QueryPlanner.cpp +87]
├── QueryUseOptimizerVisitor [vim Optimizer/QueryUseOptimizerChecker.h +40]
├── TranslationMapVisitor [vim QueryPlan/TranslationMap.cpp +100]
├── UnwrapCastInComparisonVisitor [vim Optimizer/UnwrapCastInComparison.h +43]
├── SimpleExpressionRewriter [vim Optimizer/SimpleExpressionRewriter.h +27]
│ ├── AddTableInputRefRewriter [vim Optimizer/Rewriter/MaterializedViewRewriter.cpp +145]
│ ├── AggregateRewriter [vim Optimizer/Rewriter/MaterializedViewRewriter.cpp +1242]
│ ├── EquivalencesRewriter [vim Optimizer/Rewriter/MaterializedViewRewriter.cpp +127]
│ ├── ExpressionRewriterVisitor [vim Optimizer/ExpressionRewriter.h +36]
│ ├── GroupByKeyRewrite [vim Optimizer/Rewriter/MaterializedViewRewriter.cpp +1298]
│ ├── InlinerVisitor [vim Optimizer/ExpressionInliner.h +32]
│ ├── SwapTableInputRefRewriter [vim Optimizer/Rewriter/MaterializedViewRewriter.cpp +108]
│ ├── SymbolMapper::IdentifierRewriter [vim QueryPlan/SymbolMapper.cpp +22]
│ └── SymbolTransformMap::Rewriter [vim Optimizer/SymbolTransformMap.cpp +97]
└── ExpressionVisitor [vim Analyzers/ExpressionVisitor.h +28]
├── ExtractExpressionVisitor [vim Analyzers/analyze_common.cpp +118]
├── ExtractSubqueryVisitor [vim QueryPlan/QueryPlanner.cpp +1648]
├── FreeReferencesToLambdaArgumentVisitor [vim Analyzers/QueryAnalyzer.cpp +1656]
├── PostAggregateExpressionVisitor [vim Analyzers/QueryAnalyzer.cpp +1495]
├── VerifyNoAggregateWindowOrGroupingOperationsVisitor [vim Analyzers/QueryAnalyzer.cpp +1436]
└── ExpressionTraversalIncludeSubqueryVisitor [vim Analyzers/ExpressionVisitor.h +112]
└── ExpressionTraversalVisitor [vim Analyzers/ExpressionVisitor.h +263]
├── ExtractSubqueryTraversalVisitor [vim QueryPlan/QueryPlanner.cpp +1625]
└── PostAggregateExpressionTraverser [vim Analyzers/QueryAnalyzer.cpp +1568]
以下子类以为因为上面四步走展开
├── QueryAnalyzerVisitor [vim Analyzers/QueryAnalyzer.cpp +71]
├── QueryPlannerVisitor [vim QueryPlan/QueryPlanner.cpp +87]memo 相关设计
class Memo {
GroupId addNewGroup()
{
auto new_group_id = groups.size();
groups.emplace_back(std::make_shared<Group>(new_group_id));
return new_group_id;
}
std::vector<GroupPtr> groups;
std::unordered_set<GroupExprPtr, GroupExprPtrHash, GroupExprPtrEq> group_expressions;
}
class Group
{
GroupId id = UNDEFINED_GROUP;
std::unordered_map<Property, WinnerPtr, PropertyHash> lowest_cost_expressions;
std::vector<GroupExprPtr> logical_expressions;//逻辑表表达式
std::vector<GroupExprPtr> physical_expressions;//物理表达式
std::optional<PlanNodeStatisticsPtr> statistics;
JoinSets join_sets;
std::unordered_set<CTEId> cte_set;//yu dangqian group xiangugan de
UInt32 max_table_scans = 0;
void addExpression(const GroupExprPtr & expression, CascadesContext & context);
}
class GroupExpression
{
QueryPlanStepPtr step;
GroupId group_id;
std::vector<GroupId> child_groups;//group expresion 关联的groupid
//每个groupexpression 有独立的hash值
size_t GroupExpression::hash()
{
size_t hash = step->hash();
hash = MurmurHash3Impl64::combineHashes(hash, IntHash64Impl::apply(child_groups.size()));
for (auto child_group : child_groups)
{
hash = MurmurHash3Impl64::combineHashes(hash, child_group);
}
return hash;
}
}
2 QueryPlanner().plan(cloned_query, *analysis, context);
class QueryPlannerVisitor : public ASTVisitor<RelationPlan, const Void>
{
public:
QueryPlannerVisitor(
ContextMutablePtr context_,
CTERelationPlans & cte_plans_,
Analysis & analysis_,
TranslationMapPtr outer_context_)
: context(std::move(context_))
, cte_plans(cte_plans_)
, analysis(analysis_)
, outer_context(std::move(outer_context_))
, use_ansi_semantic(context->getSettingsRef().dialect_type != DialectType::CLICKHOUSE)
, enable_shared_cte(context->getSettingsRef().cte_mode != CTEMode::INLINED)
, enable_implicit_type_conversion(context->getSettingsRef().enable_implicit_type_conversion)
, enable_subcolumn_optimization_through_union(context->getSettingsRef().enable_subcolumn_optimization_through_union)
{
}
RelationPlan visitASTSelectIntersectExceptQuery(ASTPtr & node, const Void &) override;
RelationPlan visitASTSelectWithUnionQuery(ASTPtr & node, const Void &) override;
RelationPlan visitASTSelectQuery(ASTPtr & node, const Void &) override;
RelationPlan visitASTSubquery(ASTPtr & node, const Void &) override;
RelationPlan visitASTExplainQuery(ASTPtr & node, const Void &) override;
//QueryPlannerVisitor //process 非常重要 , accept 如上节介绍 ,最终会调用 visitASTSelectQuery
RelationPlan process(ASTPtr & node) { return ASTVisitorUtil::accept(node, *this, {}); }
」
QueryPlanPtr QueryPlanner::plan(ASTPtr & query, Analysis & analysis, ContextMutablePtr context)
-> RelationPlan relation_plan = planQuery(query, nullptr, analysis, context, cte_plans);
{
//QueryPlannerVisitor 还是非常重要的实现
QueryPlannerVisitor visitor{context, cte_plans, analysis, outer_query_context};
-> return visitor.process(query);//这里即会调用
}最后调用visitASTSelectQuery
RelationPlan QueryPlannerVisitor::visitASTSelectQuery(ASTPtr & node, const Void &)
{
auto & select_query = node->as<ASTSelectQuery &>();
PlanBuilder builder = planFrom(select_query);
PRINT_PLAN(builder.plan, plan_from);
planFilter(builder, select_query, select_query.prewhere());
PRINT_PLAN(builder.plan, plan_prewhere);
planFilter(builder, select_query, select_query.where());
PRINT_PLAN(builder.plan, plan_where);
planAggregate(builder, select_query);
planFilter(builder, select_query, select_query.having());
PRINT_PLAN(builder.plan, plan_having);
planWindow(builder, select_query);
planSelect(builder, select_query);
PRINT_PLAN(builder.plan, plan_select);
planDistinct(builder, select_query);
planOrderBy(builder, select_query);
planLimitBy(builder, select_query);
planWithFill(builder, select_query);
planLimit(builder, select_query);
// planSampling(builder, select_query);
return planFinalSelect(builder, select_query);
}//这里主要为plan 添加 step 操作
void QueryPlannerVisitor::planOrderBy(PlanBuilder & builder, ASTSelectQuery & select_query)
{
if (!select_query.orderBy())
return;
auto & order_by_analysis = analysis.getOrderByAnalysis(select_query);
auto sorting_step = std::make_shared<SortingStep>(builder.getCurrentDataStream(), sort_description, limit, false, SortDescription{});
builder.addStep(std::move(sorting_step));
}
3 Plan Optimize
以上部分基本类似原生ClickHouse
optimize , getFullRewriters 初始化所有可优化的的算子, 那么CascadesOptimizer是一种optmize 方法
void PlanOptimizer::optimize(QueryPlan & plan, ContextMutablePtr context)
-> 1 optimize(plan, context, getFullRewriters());
-> FullWriter
const Rewriters & PlanOptimizer::getFullRewriters()
{
// the order of rules matters, DO NOT change.
static Rewriters full_rewrites = {
std::make_shared<HintsPropagator>(),
std::make_shared<ColumnPruning>(),
std::make_shared<UnifyNullableType>(),
std::make_shared<CascadesOptimizer>()
}
}
void PlanOptimizer::optimize(QueryPlan & plan, ContextMutablePtr context, const Rewriters & rewriters)
{
context->setRuleId(GraphvizPrinter::PRINT_PLAN_OPTIMIZE_INDEX);
Stopwatch rule_watch, total_watch;
total_watch.start();
for (const auto & rewriter : rewriters)
{
rewriter->rewrite(plan, context);
}下面我们正式进入 CascadesOptimizer
CascadesOptimizer
Cascade 最终要的概念就是Mem, 基础支持大家可以大家上网去弥补下
void CascadesOptimizer::rewrite(QueryPlan & plan, ContextMutablePtr context) const
-> 1 CascadesContext 初始化 CascadesContext cascades_context{
context, plan.getCTEInfo(), WorkerSizeFinder::find(plan, *context), PlanPattern::maxJoinSize(plan, context)};
-> 2 memo 初始化 auto root = cascades_context.initMemo(plan.getPlanNode());
-> 3 optimize auto actual_property = optimize(root_id, cascades_context, single);
-> 4 plan update init memo
注意单个SQL 只会调用一次, 传递PlanRoot 给 cascade
GroupExprPtr CascadesContext::initMemo(const PlanNodePtr & plan_node)
{
PlanNodes nodes;
std::queue<PlanNodePtr> queue;
queue.push(plan_node);//root
//tree
while (!queue.empty())
{
auto node = queue.front();
//递归Init所有PlanNode
for (const auto & child : node->getChildren())
{
queue.push(child);
}
//递归 说明最先出初始化事叶子结点 ScanNode
auto cte_expr = initMemo(cte_info.getCTEDef(read_step->getId()));
memo.recordCTEDefGroupId(read_step->getId(), cte_expr->getGroupId());
node->setStatistics(memo.getGroupById(cte_expr->getGroupId())->getStatistics());
queue.pop();
}
GroupExprPtr root_expr;//这里就是返回值 GroupExpression 即为根GroupExpress
//将GroupExpression 放入对应的Group 中
recordPlanNodeIntoGroup(plan_node, root_expr, RuleType::INITIAL);
return root_expr;
}我们继续介绍 recordPlanNodeIntoGroup 函数在干什么,其实也是递归处理, 处理花group 和 对应的logical group expression
bool CascadesContext::recordPlanNodeIntoGroup(
const PlanNodePtr & plan_node, GroupExprPtr & group_expr, RuleType produce_rule, GroupId target_group)
{
-> auto new_group_expr = makeGroupExpression(plan_node, produce_rule);
{
GroupExprPtr CascadesContext::makeGroupExpression(const PlanNodePtr & node, RuleType produce_rule)
{
std::vector<GroupId> child_groups;
for (auto & child : node->getChildren())
{
//递归操作, 也说明了 先构建group scan ,上层group 才可以初始化完成
auto group_expr = makeGroupExpression(child, produce_rule);
auto memo_expr = memo.insertGroupExpr(group_expr, *this);//add new group groupid == null
}
// 这里我理解是非常的关键 初始化grouexprssion, 并且将 children group 传递下去
return std::make_shared<GroupExpression>(node->getStep(), std::move(child_groups), produce_rule);
}
//root group exrpresssion and return
group_expr = memo.insertGroupExpr(new_group_expr, *this, target_group);
// if memo exists the same expr, it will return the old expr
// so it is not equal, and return false
return group_expr == new_group_expr;
}
这里注意出现mem
class Memo
{
public:
//该函数拿出来 着重看下 target默认值, 会在函数处理中使用, 也会做group 构建操作
GroupExprPtr insertGroupExpr(GroupExprPtr group_expr, CascadesContext & context, GroupId target = UNDEFINED_GROUP);
private:
GroupId addNewGroup()
{
auto new_group_id = groups.size();
groups.emplace_back(std::make_shared<Group>(new_group_id));
return new_group_id;
}
/**
* Vector of groups tracked
*/
std::vector<GroupPtr> groups;
/**
* Map of cte id to group id
*/
std::unordered_map<size_t, GroupId> cte_group_id_map;
/**
* Vector of tracked GroupExpressions
* Group owns GroupExpressions, not the memo
*/
std::unordered_set<GroupExprPtr, GroupExprPtrHash, GroupExprPtrEq> group_expressions;
}; Memo insertGroupExpr
group_expressions.insert(group_expr); group expres 放入全局Memo
GroupId group_id;
if (target == UNDEFINED_GROUP)
{
group_id = addNewGroup();//UNDEFINED_GROUP 在以上逻辑处, 我立即这里应该都是会走的, 构造新的group
// LOG_DEBUG(context.getLog(), "New Group Id " << group_id << "; Rule Type: "
// << static_cast<int>(group_expr->getProducerRule()));
}
else
{
group_id = target;
}
auto group = getGroupById(group_id);
//group add expresion
group->addExpression(group_expr, context); // 将group expr 放入group
return group_expr;
到此也就出现group 的概念group addExpression
class Group
{
public:
explicit Group(GroupId id_) : id(id_) { }
std::unordered_map<Property, WinnerPtr, PropertyHash> lowest_cost_expressions;
/**
* Vector of equivalent logical expressions
*/
std::vector<GroupExprPtr> logical_expressions;
/**
* Vector of equivalent physical expressions
*/
std::vector<GroupExprPtr> physical_expressions;
}
void Group::addExpression(const GroupExprPtr & expression, CascadesContext & context)
{
expression->setGroupId(id);
if (expression->isPhysical())
{
physical_expressions.emplace_back(expression);
}
if (expression->isLogical())
{
logical_expressions.emplace_back(expression);//Opti xia yinggai doushi Logical
....
//这里有一部分暂且不介绍
}
}groupexpression
class GroupExpression
{
public:
//group hash group expresion 唯一标识
size_t GroupExpression::hash()
{
size_t hash = step->hash();
hash = MurmurHash3Impl64::combineHashes(hash, IntHash64Impl::apply(child_groups.size()));
for (auto child_group : child_groups)
{
hash = MurmurHash3Impl64::combineHashes(hash, child_group);
}
}
*/
std::vector<GroupId> child_groups; //当前expresion 相关的gruop id
/**
* Mask of explored rules
*/
std::bitset<static_cast<UInt32>(RuleType::NUM_RULES)> rule_mask;
」原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号