【Python与SEO】悟空问答自动采集及Zblog博客自动发布一条龙源码!

【Python与SEO】悟空问答自动采集及Zblog博客自动发布一条龙源码!

二爷
发布于 2023-09-02 08:14:26
发布于 2023-09-02 08:14:26
仅记录,一个简单的网站自动采集发布一条龙源码,程序运行启用了宝塔面板的计划任务,通过定时计划任务实现每日自动运行采集发布文章,理论上只需配置关键词文档及背景源图片!
实现功能:
- 悟空问答自动采集
- Zblog博客自动发布
- 可自动生成带标题无版权图片类似水印图片
- 文章发布后自动推送百度收录平台
- 可自行添加版权信息等其他附加文字内容信息
存在bug:
- 关键词文档保存会中断,程序会终止失效
- 其他n多未知bug
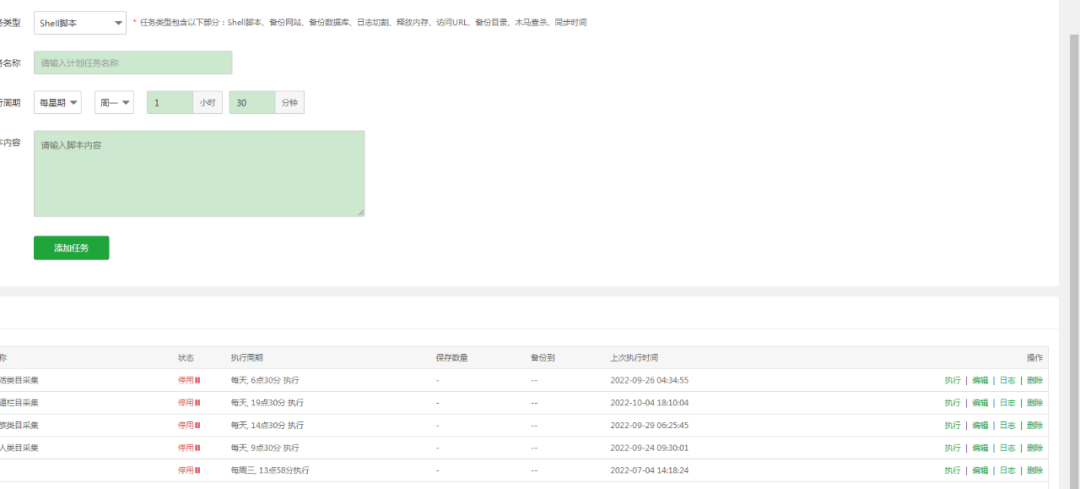
悟空问答采集平台规则已失效,请谨慎使用!
其实网上可以找到不少类似的自动采集发布源码程序,理论上就是解决以下几个问题:
- 采集源采集数据
- 数据整理分类处理
- 数据内容网站发布
为什么市面上有这么多垃圾站能够有排名,一方面的是它的需求量够大,这里本渣渣所说的需求量是指的有搜索需求量的关键词数据,另一方面大概率是坚持,坚持什么呢?多站点,不同行业不同站点去测试去采集发布,所谓东边不亮西边亮,总有一个会上去,你看到了效果,但其背后还有无数炮灰站点!
最后一个问题,文章重要还是词重要?本渣渣现在的回答是词重要,也就是需求,搜索需求,以满足搜索需求而设计网站内容,只有这样才有搜索体验而言。
这就是搜索到垃圾站想吃了狗屎一样,虽然内容牛头不对马嘴,但是确实满足了搜索需求,搜索词肯定是对了的!
搞站一句话:建议加大采集力度,一把梭哈,直接梭哈!
不要怂,就是干!
赢了会所嫩模,输了下海干活!

附完整源码供参考,仅记录,平台已失效:
# 悟空问答采集处理
# -*- coding: utf-8 -*-
import requests, json
import re
import xmlrpc.client
from PIL import ImageFont, ImageDraw, Image
import time
import datetime
import os
import random
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 协议头列表
ua_list = [
"Mozilla/5.0(compatible;Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36; 360Spider",
"Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)",
"Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)",
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML,like Gecko)Chrome/41.0.6633.1032 Mobile Safari/537.36;Bytespider;",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 YisouSpider/5.0 Safari/537.36",
]
now = datetime.datetime.now()
s = now.strftime('%y%m%d')
fs = f'/www/wwwroot/xxxx.cn/zb_users/upload/{s}/'
os.makedirs(fs, exist_ok=True)
# 生成时间戳图片名
def create_img_name():
"""
获取当前时间,生成时间戳
以时间戳命名图片名
"""
t = time.time()
img_name = int(t) # 秒级时间戳
img_name = f'{img_name}.jpeg'
return img_name
# 生成文件名
def create_wjm():
"""
获取当前日期生成保存图片的文件夹名称
"""
now = datetime.datetime.now()
s = now.strftime('%y%m%d')
# r'/www/wwwroot/xxxx.cn/zb_users/upload'
print(s)
return s
# 标题转图片
def write_txt_img(title, fs):
"""
以文章标题和背景图片合成图片并保存图片文件
"""
bgimg = Image.open(f'/www/wwwroot/PythonSEO/pwsh/{(random.randint(1, 309))}.png')
draw = ImageDraw.Draw(bgimg) # 读取
fnt = ImageFont.truetype('/www/wwwroot/PythonSEO/pm.ttf', 50) # 设置字体及大小
draw.text((50, 150), title, fill='red', font=fnt) # 写入文本1 位置坐标 颜色
# bgimg.show() # 显示图片
bgimg = bgimg.convert("RGB") # 改成三通道色
img_name = create_img_name()
bgimg.save(f'{fs}{img_name}') # 保存图片
print("文字写入图片成功!")
return img_name
# 获取下拉词
def get_sug(word):
"""
获取百度下拉词列表
"""
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
url = 'https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=%s&sugmode=2&json=1&p=3&sid=1427_21091_21673_22581&req=2&pbs=%%E5%%BF%%AB%%E6%%89%%8B&csor=2&pwd=%%E5%%BF%%AB%%E6%%89%%8B&cb=jQuery11020924966752020363_1498055470768&_=1498055470781' % word
r = requests.get(url, verify=False) # 请求API接口,取消了HTTPS验证
cont = r.content # 获取返回的内容
# print(cont)
res = cont[41: -2].decode('gbk') # 只取返回结果中json格式一段,并且解码为unicode
res_json = json.loads(res) # json格式转换
keywords = res_json['s']
print(keywords)
return keywords # 返回关键词列表
def get_qlist(word):
"""
获取悟空问答列表,已失效!
"""
headers = {'user-agent': random.choice(ua_list)}
url = f"https://wukong.toutiao.com/wenda/web/question/association/?title={word}"
response = requests.get(url=url, headers=headers, timeout=6)
question_list = response.json()['question_list']
if question_list:
question = question_list[0]
qtitle = question['title']
img_name = write_txt_img(qtitle, fs)
qid = question['qid']
get_content(headers, word, qid, img_name, qtitle)
else:
path = r"/www/wwwroot/PythonSEO/fail.txt"
con = f'{word}---{question_list}---获取悟空问答失败!-{datetime.datetime.now()}'
save_txt(con, path)
print(question)
return question
# 获取问答详情
def get_content(headers, title, qid, img_name, name):
"""
获取悟空问答详情,已失效!
同时插入分类及发布文章数据
"""
url = f"https://wukong.toutiao.com/wenda/web/question/loadmorev1/?qid={qid}&count=10"
response = requests.get(url=url, headers=headers, timeout=6)
print(response.status_code)
ans_list = response.json()['data']['ans_list']
if ans_list:
print(f'有 {len(ans_list)} 个回答数据!')
text = get_content_abstract_text(ans_list, img_name, name)
# category = "品味生活"
category = "品味生活"
zbgfb(name, text[1], category, title, text[0])
else:
path = r"/www/wwwroot/PythonSEO/fail.txt"
con = f'{title}---{ans_list}---获取悟空问答详情失败!-{datetime.datetime.now()}'
save_txt(con, path)
# 回答数据处理,简介数据整合
def get_content_abstract_text(ans_list, img_name, name):
"""
获取悟空问答数据规整简单合并处理
"""
content = ''
excerpt = ''
for ans in ans_list:
abstract_text = ans['abstract_text']
# print(abstract_text) #简介
abstract_texts = abstract_text.split('。')[:-1]
abstext = '。'.join(abstract_texts)
if abstext != '':
print(abstext)
excerpt = f'{excerpt}{abstext}'
content = f"{content}{abstext}。</br>"
exce = excerpt.split('。')
excerpt = f'{name}{exce[0]},{exce[1]}。'
result = add_html(content, img_name, name)
print(result)
text = excerpt, result
return text
# 去除html代码标签
def re_html(content):
pattern = re.compile(r'<[^>]+>', re.S)
result = pattern.sub('', content)
# print(result)
return result
# 增加html代码标签
def add_html(content, img_name, name):
img = f'<p style="text-align: center;"><img style="width: 600px; height: 400px;" src="http://www.xxxx.cn/zb_users/upload/{create_wjm()}/{img_name}" title="{name}" alt="{name}"></p>'
# content=content.replace('。','。<br>').replace('?','?<br>').replace('!','!<br>')
result = f'{img}<p>{content}</p>'
# print(result)
return result
# 发布文章
def zbgfb(title, content, category, key, excerpt):
"""
zbolg博客接口发布文章
""""
username = "用户名"
password = "密码"
apiurl = "https://www.xxxx.cn/zb_system/xml-rpc/index.php" # 接口地址填写自己zblog域名地址
blogid = ''
s = xmlrpc.client.ServerProxy(apiurl) # 链接xmlrpc
# print(s)
keywords = get_sug(key)
if keywords == []:
blog = s.metaWeblog.newPost('', username, password, {
'title': title, # 标题
'description': content,
'categories': category, # 分类
'mt_keywords': key, # 标签
'mt_excerpt': excerpt, # 摘要
}, True)
else:
title = f'{title}-{keywords[0]}'
bq = '<p style="font-size:12px;color:#8a92a9;"> 声明:网站作品(图文、音视频)源于网络分享,仅供网友学习交流。若您的权利被侵害,请联系 微信:huguo00289 删除!</p>'
content = f'{content}<p>本文相关关键词:{key},{keywords[1]},{keywords[2]}</p>{bq}'
blog = s.metaWeblog.newPost('', username, password, {
'title': title, # 标题
'description': content,
'categories': category, # 分类
'mt_keywords': key, # 标签
'mt_excerpt': excerpt, # 摘要
}, True)
print(blog)
print("发布文章成功!")
path = r"/www/wwwroot/PythonSEO/pwshsuccess.txt"
con = f'{key}---{title}'
save_txt(con, path)
# 读取txt
def read_words():
words = []
with open('/www/wwwroot/PythonSEO/pwsh.txt', 'r', encoding='utf-8') as f:
datas = f.readlines()
print("读取关键词列表成功!")
for data in datas:
word = data.strip()
word = word.replace('\n', '')
words.append(word)
return words
# 写入txt
def save_txt(word, path):
with open(path, 'a+', encoding='utf-8') as f:
f.write(f'{word}\n')
# 写入txt
def save_words(words):
for word in words:
with open('/www/wwwroot/PythonSEO/pwsh.txt', 'a+', encoding='utf-8') as f:
f.write(f'{word}\n')
print("更新关键词列表成功!")
def ts(url):
"""
百度推送网页链接
"""
apiurl = "http://data.zz.baidu.com/urls?site=https://www.xxxx.cn&token=dnTPOlAAkXIW876V"
headers = {
"User-Agent": "curl/7.12.1",
"Host": "data.zz.baidu.com",
"Content-Type": "text/plain",
"Content-Length": "83",
}
response = requests.post(url=apiurl, data=url, headers=headers)
print(response)
print(response.json())
def tsll():
"""
百度推送多条网页链接数据
"""
url = "https://www.xxxx.cn/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
}
html = requests.get(url=url, headers=headers, timeout=8).content.decode('utf-8')
urls = re.findall(r'<h2><a href="(.+?)" target="_blank">', html, re.S)
# print(len(urls))
print(urls)
for url in urls:
with open("/www/wwwroot/PythonSEO/tsurls.txt", 'a+', encoding='utf-8') as f:
f.write(f'{url}\n')
ts(url)
tag_html = requests.get(url=urls[0], headers=headers, timeout=8).content.decode('utf-8')
id = re.findall(r"标签: <a href='https://www.xxxx.cn/tags-(.+?).html' title=", tag_html, re.S)[
0]
print(id)
tag_urls = []
tag_id = int(id)
for i in range(1, 11):
tag_url = f'https://www.xxxx.cn/tags-{tag_id}.html'
tag_urls.append(tag_url)
tag_id = tag_id - 1
# print(len(tag_urls))
print(tag_urls)
for tag_url in tag_urls:
with open("/www/wwwroot/PythonSEO/tsurls.txt", 'a+', encoding='utf-8') as f:
f.write(f'{tag_url}\n')
ts(tag_url)
def main():
words = read_words()
os.remove(r'/www/wwwroot/PythonSEO/pwsh.txt') # 删除文件
i = 0
for word in words:
word = word.replace('\ufeff', '')
try:
get_qlist(word)
words.remove(word)
i = i + 1
except Exception as e:
path = r"/www/wwwroot/PythonSEO/fail.txt"
con = f'{word}---运行出错:{e}!-{datetime.datetime.now()}'
save_txt(con, path)
words.remove(word)
time.sleep(random.randint(65, 140))
if i > 8:
tsll() # 推送链接
time.sleep(random.randint(120, 160))
if i > 18:
save_words(words)
tsll() # 推送链接
break
if __name__ == '__main__':
main()
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-11,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Python与SEO学习 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号