Python 状态机(transitions)实践

Python 状态机(transitions)实践

用户4945346
发布于 2023-09-18 10:52:50
发布于 2023-09-18 10:52:50
什么是状态机?
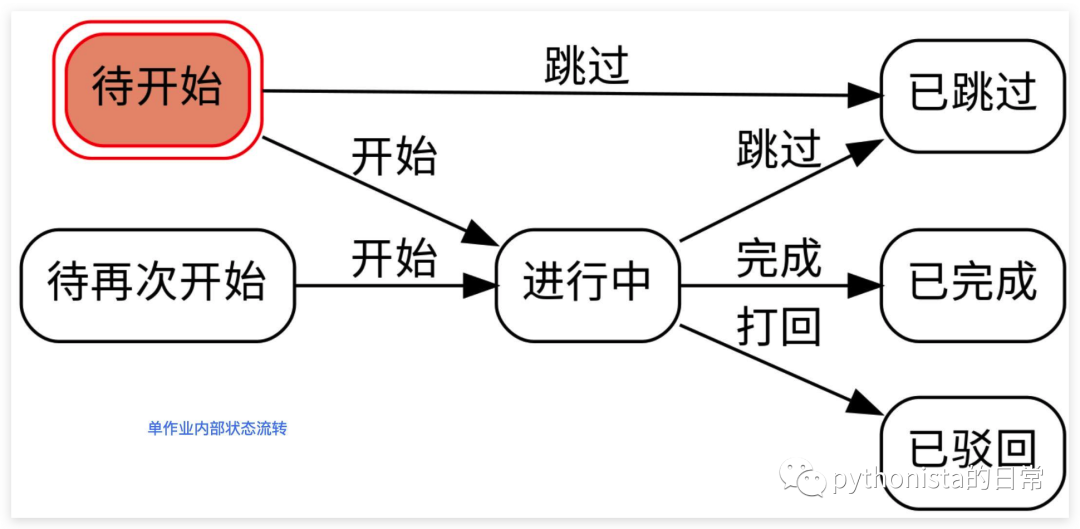
所谓状态机是表示有限个状态以及在这些状态之间的流转和状态变更前后所触发的动作等行为的数学模型。说白了就是定义类似上面那张图各个状态之间的流转转换,例如‘待开始’状态所能变更的状态以及‘待开始’状态变更之前的触发动作以及状态变更成功之后的操作,以及整个流程开始之前和流程结束之后能触发的动作。
状态机也是一种算法思想,简单而言,有限状态机由一组状态、一个初始状态、输入和根据输入及现有状态转换为下一个状态的转换函数组成。有限状态机是有限个状态以及在这些状态之间的转移和动作等行为的数学模型。
为什么要用状态机?
最近在做一个任务管理系统,涉及到任务状态之间的流转,需要根据当前的触发动作,来把当前任务的状态变更为特定的状态。虽然用流程方式实现了,但阅读起来费劲,还容易出错。所以就用了状态机。
transitions
transitions 是Python 中具有许多扩展的轻量级、面向对象的有限状态机实现库。
安装直接执行下面的指令即可
pip3 install transitions实战应用
1.上手弄一个最小的状态机
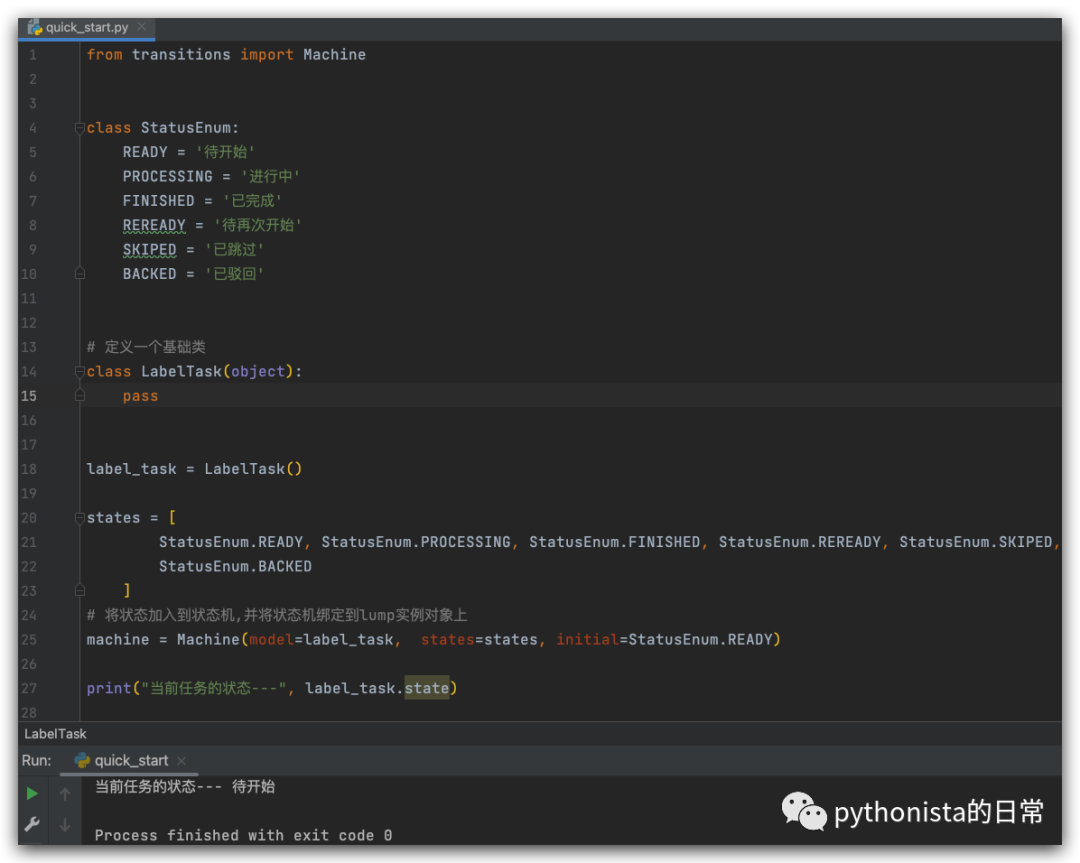
定义一个任务类 LabelTask ,定义任务状态 states, 再定义状态机machine,并将状态机绑定到 label_task 实例上。说它“最小”是因为虽然这个状态机在技术上是可操作的,但它实际上并没有做任何事情。它从状态开始,但永远不会进入另一个 '进行中' 状态,因为还没有定义状态之间的转换
2.增加任务之间的转换
from transitions import Machine
class StatusEnum:
READY = '待开始'
PROCESSING = '进行中'
FINISHED = '已完成'
REREADY = '待再次开始'
SKIPED = '已跳过'
BACKED = '已驳回'
# 定义一个基础类
class LabelTask:
states = [
StatusEnum.READY, StatusEnum.PROCESSING, StatusEnum.FINISHED, StatusEnum.REREADY, StatusEnum.SKIPED,
StatusEnum.BACKED
]
# 状态流转转换关系,下面第一个对象意思是,触发动作为'开始',允许操作的当前状态是StatusEnum.READY和StatusEnum.REREADY,
# 变更后的状态是StatusEnum.PROCESSING,状态变更成功之后会调用 after_started 方法
transitions = [{
'trigger': '开始',
'source': [StatusEnum.READY, StatusEnum.REREADY],
'dest': StatusEnum.PROCESSING,
'after': 'after_started'
}, {
'trigger': '完成',
'source': StatusEnum.PROCESSING,
'dest': StatusEnum.FINISHED,
'conditions': ['can_completed'], # 执行状态变更的前置校验
'after': 'after_completed'
}, {
'trigger': '打回',
'source': StatusEnum.PROCESSING,
'dest': StatusEnum.BACKED,
'conditions': ['can_backed'],
'after': 'after_backed'
}, {
'trigger': '跳过',
'source': [StatusEnum.READY, StatusEnum.PROCESSING],
'dest': StatusEnum.SKIPED,
'conditions': ['can_skiped'],
'after': 'after_skiped'
}]
def __init__(self, label_task_id, assignment_id, collection_params, api_request):
pass
def after_started(self):
"""
执行'开始'动作之后的触发动作
"""
pass
def after_completed(self):
"""
执行'完成'动作之后的触发动作
"""
pass
def after_backed(self):
"""
执行打回'打回'之后的触发动作
"""
pass
def after_skiped(self):
"""
执行打回'跳过'之后的触发动作
"""
pass
def can_completed(self):
"""
允许操作'完成'动作的条件
"""
if self.assignment_cat == '挑选':
# 挑选任务没有上报信息, 直接把当前输入数据集文件传递给下一步
self.dataset_path = self.api_request.get_dataset(self.assignment_dataset_id)['data']['attributes']['prefix']
return True
assert self.collection_params, '没有上报信息,不能完成'
assert self.dataset_path, '上报信息必需包含新文件路径'
return True
def can_backed(self):
"""
允许操作'打回'动作的条件
"""
assert self.assignment_index > 0, '第一步不能打回'
assert self.collection_params, '没有上报信息,不能打回'
assert self.dataset_path, '上报信息必需包含新文件路径'
return True
def can_skiped(self):
"""
允许操作'跳过'动作的条件
"""
assert self.assignment_index == 0, '只有第一个阶段才能跳过'
return True
label_task = LabelTask()
machine = Machine(
label_task,
states=label_task.states,
transitions=label_task.transitions,
initial=label_task.assignment_status, # 初始状态
model_attribute='assignment_status', # 改为读取label_task.assignment_status这个值作为任务的状态
auto_transitions=False # 禁止to_«state»()方法使用
)
# 触发任务改变任务额状态
label_task.trigger('开始')
print("当前任务的状态---", label_task.state)
在原来的基础上增加了任务流转关系 transitions,transitions 里定义了多个字典对象,每个对象表示每个触发动作的 以这个为例
{
'trigger': '完成', # 表示触发动作接收‘完成’这个动作,即 label_task.trigger('完成')
'source': StatusEnum.PROCESSING, # 当前任务的状态
'dest': StatusEnum.FINISHED, # 变更之后的状态
'conditions': ['can_completed'], # 执行状态变更的前置校验
'after': 'after_completed' # 状态变更下一个状态之后的触发方法
}值得注意的是回调方法,比如 can_completed 和 after_completed 这些都定义在基础类中即 LabelTask 。状态机 Machine 直接收对应的参数值。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-10 17:50,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 pythonista的日常 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号