C#爬虫知识介绍

C#爬虫知识介绍

爬虫
爬虫(Web Crawler)是指使用程序自动获取互联网上的信息和数据的一种技术手段。它通常从一个起始网址出发,按照一定的规则递归地遍历网页,并将有用的信息提取出来,然后存储到本地或者数据库中,以供后续分析和使用。爬虫的本质是通过程序模拟了人类在互联网上的浏览、搜索行为,把互联网上的信息主动拉取到自己的数据库中,从而实现全网数据的自动化采集和处理。
爬虫的原理主要就是以下几个步骤:
- 通过网络请求,获取要抓取的网页的源代码
- 解析源代码,筛选出需要的信息
- 将信息存储到本地或者数据库中
其中,第二步是爬虫技术的瓶颈之一,因为需要精准地定位和提取所需信息,针对不同的网站和数据结构进行特定的处理和解析。同时,为了防止过于频繁的请求被网站封禁,爬虫需要一定的协议和规范,比如 Robots 协议、Sitemap 协议等。
总之,爬虫是一项非常重要的网络技术,可以用于数据的抓取、监测、分析、挖掘等方面,但也需要遵守相关法律法规和伦理道德,不得用于非法或侵犯隐私的目的。
爬虫核心价值和意义
爬虫的核心价值在于它可以从互联网上自动化地获取大量的数据,并进行深度挖掘和分析,从而帮助人们快速了解和掌握互联网上的各种信息和资源。具体来说,爬虫的意义主要体现在以下几个方面:
- 帮助各类企业和机构进行市场调研和数据分析。爬虫可以获取各种产品、营销、竞争对手等方面的数据,帮助企业了解市场状况、行业趋势、客户需求等,从而制定更加有效的营销策略和产品方案。
- 优化搜索引擎的效果和用户体验。搜索引擎需要大量的数据来进行索引和排名,爬虫可以帮助搜索引擎获取更多更准确的信息,提高搜索引擎的性能和用户满意度。
- 支持科研和教育机构开展大数据分析和挖掘。爬虫可以获取各种学术、科技、文化、教育等方面的数据和信息,支持科研团队进行大数据分析和挖掘,从而推动人类文明、科技和社会的发展。
- 便捷民生实用和信息服务。爬虫可以从互联网上获取各种民生实用的信息和服务,比如天气预报、新闻资讯、交通出行等,帮助广大民众获取自己所需的信息和服务,提高生活品质和便利程度。
总之,爬虫是一项具有广泛应用前景和社会价值的技术,它对于人们的生产、学习、生活、娱乐等方面都有着极大的意义和作用。同时,由于爬虫也涉及到一些隐私和安全问题,所以在使用爬虫技术时,也应当遵循相关法律法规和道德规范。
数据爬虫
数据爬虫(Data Crawler)是一种用于获取互联网上大量数据的技术,它的主要任务就是从各种异构数据源中自动化地抽取和收集数据,并将数据存储在一个方便管理和分析的系统中。数据爬虫主要包括网页爬虫、API爬虫、RSS爬虫等多种类型,其中最常用的是网页爬虫。
数据爬虫与传统的爬虫技术相比,其目的更加明确,主要是为了获取特定类型和规模的数据,以满足数据分析、数据挖掘、人工智能等各种业务需求。数据爬虫需要通过一系列的技术手段来挖掘数据,其中包括:
- 选定数据源和搜索关键字。在对数据进行爬取之前,需要先明确数据获取的来源和目标,以及用于搜索的关键字或者过滤条件。
- 使用爬虫程序获取数据。针对不同的数据源和类型,需要编写相应的爬虫程序来实现数据的自动化获取和处理。
- 数据解析和清洗。爬取下来的数据通常包含垃圾数据、重复数据等,需要进行解析和去重等清洗处理,以保证数据质量和有效性。
- 数据存储和管理。将获取的数据存储在一个可管理、可查询的数据库中,以方便后续的数据分析和挖掘。
爬虫攻防
爬虫攻防策略分为攻击和防御两方面:
攻击方技术手段:
- 伪装成浏览器访问。通过在头部添加浏览器信息,让服务器认为是浏览器发送请求。
- 模拟登录。通过模拟用户登录,获取身份验证信息,从而绕过网站的登录验证。
- 破解验证码。通过图像识别技术,自动识别和破解网站的验证码。
- 动态IP代理。通过使用多个动态IP代理,更换IP地址,避免服务器对IP地址进行封锁。
- 加速爬取速度。使用多线程或多机并行化,提高爬取速度,获取更多数据。
防御方技术手段:
- IP封禁。根据IP地址对不正常的请求进行封锁。服务器统计IP地址的请求数量,如果超过阈值,则自动封禁该IP地址。
- 限制访问频率。根据访问频率对爬取请求进行限制,降低服务器负担,并避免被爬虫攻击。
- 网络流量分析。通过分析流量特征,及时判断是否遭受爬虫攻击,并对异常流量进行识别和拦截。
- SSL加密。通过使用SSL/TLS协议加密数据传输,加强数据安全性,避免爬虫通过中间人攻击等方式窃取数据传输。
- 限制爬取深度。限制一个IP地址对某个网站的爬取深度,不但减轻了目标服务器的压力,也可以提高服务器抵御爬虫攻击的能力。
- 加密数据。通过对数据进行加密处理,避免爬虫程序直接获取和解析数据。
总之,对于爬虫攻防,攻击方和防御方都有各自的技术手段。攻击方主要是通过伪装、破解、加速等方法来绕过反爬虫策略抓取数据,而防御方则通过IP封禁、限制访问频率、SSL加密、限制访问深度等技术手段来保护服务器安全,避免爬虫攻击。
爬虫定制及网络数据资源如何抓取
爬虫定制和网络数据资源抓取的实现通常包括以下步骤:
- 确定目标网站和数据。首先,需要明确目标网站和要抓取的数据,包括数据的格式、存储方式、更新频率等。若目标网站有些许限制,则需考虑如何设计爬虫程序,规避反爬虫机制。
- 分析目标网站页面结构。通过分析目标网站所属的技术栈,来确定爬虫所要使用的工具或技术,通过对目标网站的访问和页面分析来了解页面的 HTML、CSS、JS等,提取数据的方式。
- 开发爬虫程序。根据目标网站的页面结构,编写爬虫程序,实现数据的抓取、清洗和存储。Python 等编程语言提供了多个爬虫框架,如Scrapy,BeautifulSoup 等,可加快开发进度。
- 验证和测试。对开发的爬虫程序进行验证和测试,确保数据的准确性和完整性。同时,要注意在爬取过程中不要对目标站点造成太大的负担,规避反爬虫机制,比如设置请求头信息。
- 迭代和优化。当爬虫程序开发完成后,在不断爬取数据的过程中,需要对程序进行迭代和优化,减少爬虫程序的判断逻辑,提高程序运行效率,降低爬取数据的周期。
总之,要实现爬虫定制和网络数据资源抓取,需要有一定的编程基础和爬虫技术知识,同时合法合规地开展数据抓取时,也需要遵守相关法律法规和道德规范。
代码示例
HtmlAgilityPack的C#代码
internal class Program
{
private static void Main(string[] args)
{
//爬虫
//爬取网页源代码
//分析源代码
//提取有用信息
//保存信息
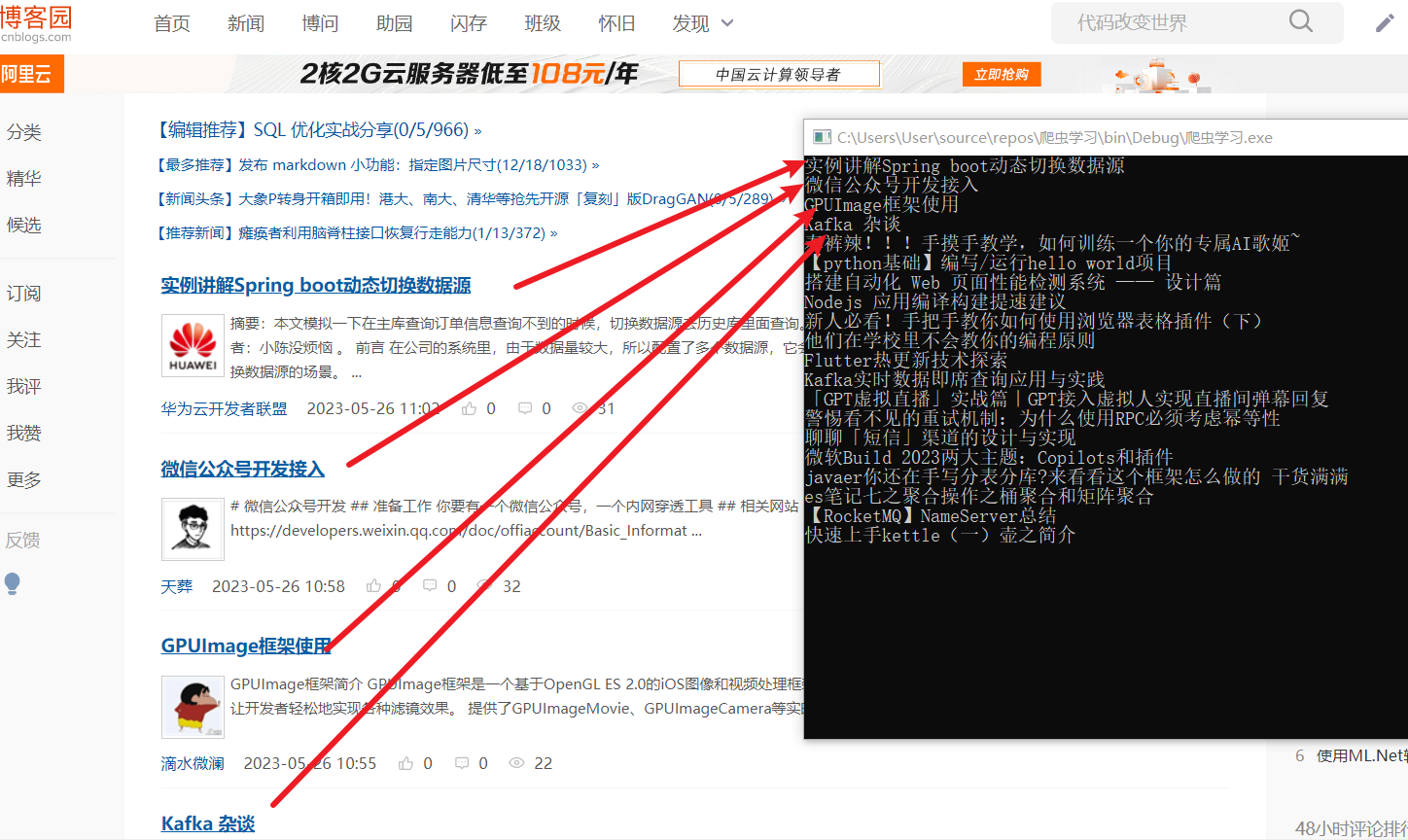
string url = "http://www.cnblogs.com/";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = "GET";
request.UserAgent = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
string html = reader.ReadToEnd();
var doc = new HtmlDocument(); //using HtmlAgilityPack;
doc.LoadHtml(html);
var nodes = doc.DocumentNode.SelectNodes("//a[@class='post-item-title']"); //xpath语法
foreach (var item in nodes)
{
Console.WriteLine(item.InnerText);
}
Console.ReadKey();
}
}
}
}
XPath 语法:https://www.w3cschool.cn/xpath/xpath-syntax.html
ScrapySharp 的C#爬虫代码
private static void Main(string[] args)
{
// 创建浏览器对象
ScrapingBrowser browser = new ScrapingBrowser();//nuget 安装 ScrapySharp
// 使用浏览器对象获取HTML文档
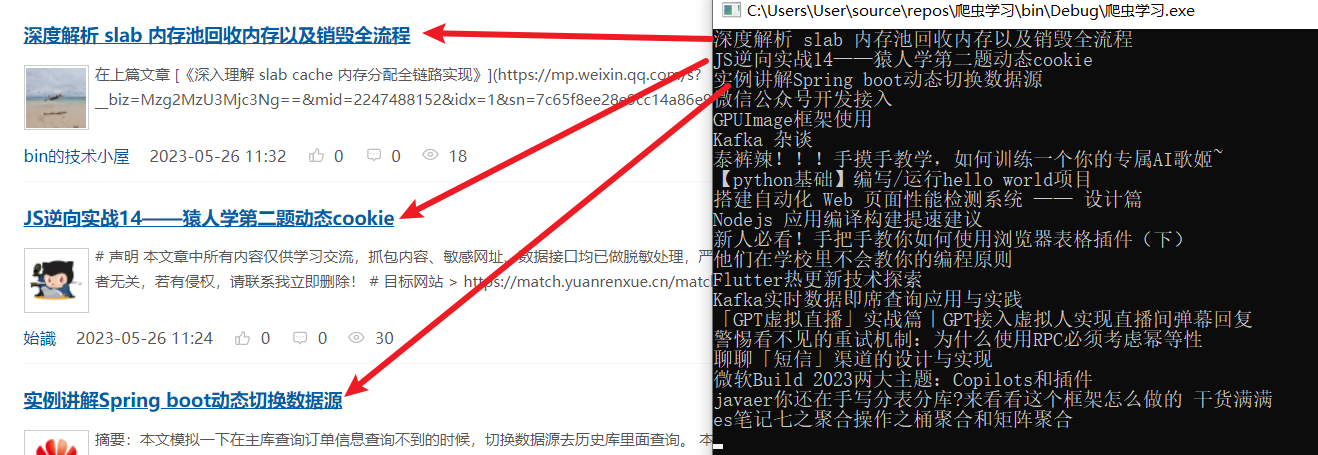
WebPage page = browser.NavigateToPage(new Uri("http://www.cnblogs.com"));
// 使用XPath查询所有节点
HtmlNodeCollection nodes = page.Html.SelectNodes("//a[@class='post-item-title']"); //xpath语法
if (nodes != null)
{
foreach (HtmlNode node in nodes)
{
Console.WriteLine(node.InnerText);
}
}
System.Console.ReadLine();
}
腾讯云开发者
