Elasticsearch系列组件:Beats高效的日志收集和传输解决方案

Elasticsearch系列组件:Beats高效的日志收集和传输解决方案

栗筝i
发布于 2023-10-23 15:28:38
发布于 2023-10-23 15:28:38
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析等,都有广泛的应用。 本文将介绍 Elastic Stack 组件 Beats 的介绍、原理、安装与简单使用。
1、Beats介绍
1.1、Beats简介
Beats 是 Elastic Stack 的一部分,它是一系列轻量级的数据采集器。Beats 可以在你的服务器上采集各种类型的数据,并将这些数据发送到 Elasticsearch 或者 Logstash 进行后续处理。
主要功能和用途:
- 数据采集:Beats 可以采集各种类型的数据,包括日志文件(Filebeat)、网络数据(Packetbeat)、系统和服务的运行指标(Metricbeat)、Windows 事件日志(Winlogbeat)等。
- 数据转发:Beats 可以将采集到的数据发送到 Elasticsearch 进行索引,也可以发送到 Logstash 进行更复杂的处理。
- 轻量级:Beats 设计的目标是轻量级和低资源占用,因此它可以在所有类型的服务器上运行,甚至包括在 IoT 设备上。
- 易于扩展:Beats 提供了开发者指南,用户可以根据自己的需求编写自定义的 Beats。
总的来说,Beats 是 Elastic Stack 中负责数据采集的组件,它可以帮助用户轻松地从各种源头采集数据,并将数据发送到 Elasticsearch 或 Logstash 进行后续的处理和分析。
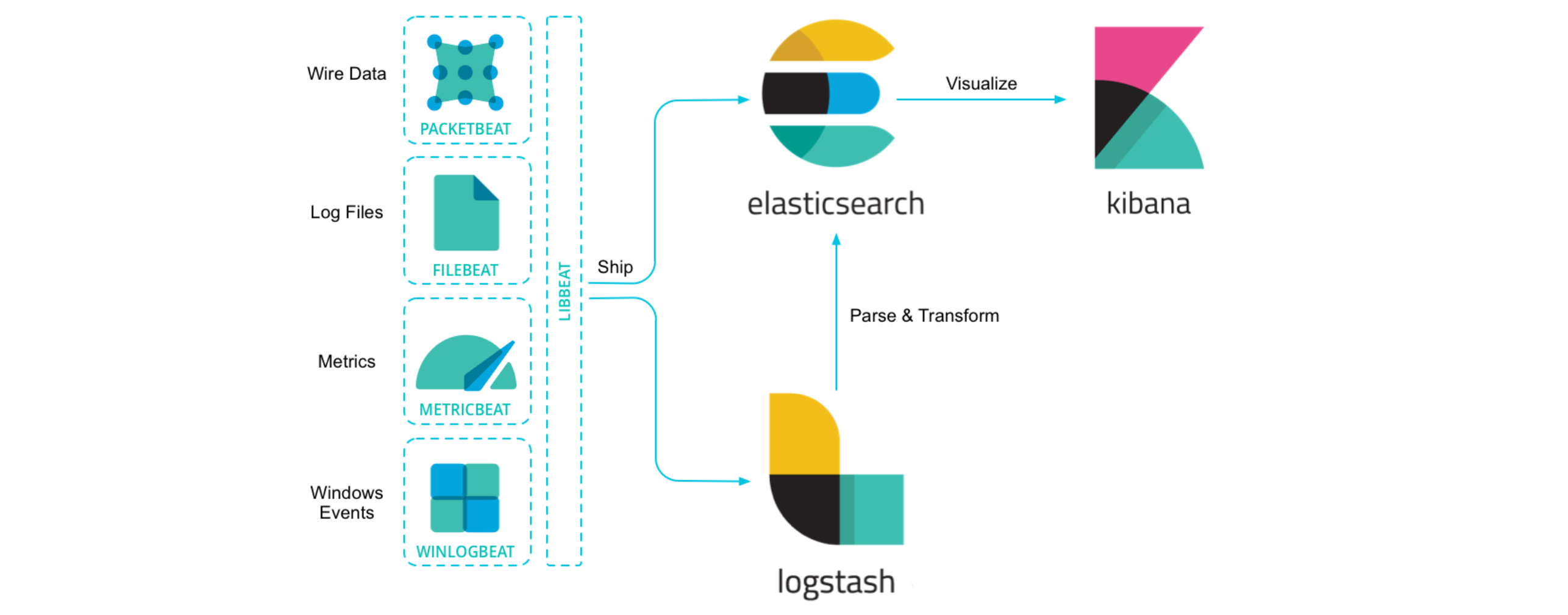
1.2、Beats系列组件
Beats 不是一个单独的软件,而是一系列的数据采集器。每一个 Beat 都是一个独立的组件,负责采集特定类型的数据,并将这些数据发送到 Elasticsearch 或者 Logstash 进行后续处理。例如,Filebeat 专门用于收集和转发日志文件,Metricbeat 用于收集系统和服务的运行指标,Packetbeat 用于收集网络流量数据等。
- Filebeat:主要用于收集和转发日志文件。它可以监控指定的日志目录或文件,当日志更新时,Filebeat 就会读取更新的内容并发送到 Elasticsearch 或 Logstash。使用场景包括日志分析、故障排查等。
- Metricbeat:用于收集系统和服务的运行指标,如 CPU 使用率、内存使用量、网络流量、磁盘 I/O 等。它可以定期收集这些指标并发送到 Elasticsearch 或 Logstash。使用场景包括系统监控、性能分析等。
- Packetbeat:用于收集网络流量数据。它可以实时捕获网络流量,然后解析出各种协议的信息(如 HTTP、MySQL、Redis 等),并将这些信息发送到 Elasticsearch 或 Logstash。使用场景包括网络监控、安全分析等。
- Winlogbeat:专门用于收集 Windows 事件日志。它可以读取 Windows 事件日志,然后将日志数据发送到 Elasticsearch 或 Logstash。使用场景包括 Windows 系统监控、安全分析等。
- Auditbeat:用于收集 Linux 审计框架的数据,以及文件的改变数据。它可以帮助你了解在系统上发生了什么,包括哪些文件被改变,以及系统调用等。使用场景包括系统审计、文件完整性检查等。
- Heartbeat:用于定期检查你的服务是否可用。它可以定期发送请求到你的服务,然后收集响应时间等信息,并将这些信息发送到 Elasticsearch 或 Logstash。使用场景包括服务监控、可用性检查等。
1.3、Beats组件安装
我们这里以安装 Beats 系列组件之一的 Filebeat 为例
Elastic 公司的官方下载页面的链接。在这个页面上,你可以下载 Elastic Stack 的各个组件,包括 Elasticsearch、Kibana、Logstash、Beats 等。这个页面提供了各个组件的最新版本下载链接,以及历史版本的下载链接:Past Releases of Elastic Stack Software | Elastic
在这里,我们将选择 filebeat,并确保所选的 filebeat 版本与我们正在使用的 Elasticsearch 版本一致:

选择后选择「Download」开始下载,并在下载成功后解压到指定位置即可。
2、使用FileBeat对接ES,监控logback日志
2.1、使用FileBeat对接ES,监控logback日志
使用 Filebeat 对接 Elasticsearch 监控 logback 日志,可以按照以下步骤进行:
- 安装 Filebeat:根据你的操作系统,从 Elastic 官网下载并安装 Filebeat;
- 配置 Filebeat:在 Filebeat 的配置文件(通常是 filebeat.yml)中,需要配置两个主要部分,一是输入(input),二是输出(output)。
输入:指定 Filebeat 需要收集的日志文件的位置。如果你的 logback 日志文件位于 /var/log/app/*.log,那么可以这样配置:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/app/*.log输出:指定 Filebeat 将数据发送到哪里。如果你的 Elasticsearch 服务运行在 localhost:9200,那么可以这样配置:
output.elasticsearch:
hosts: ["localhost:9200"]- 启动 Filebeat:保存并关闭配置文件后,运行 Filebeat。在命令行中,可以使用以下命令启动 Filebeat:
./filebeat -e- 验证数据是否已经发送到 Elasticsearch:你可以查询 Elasticsearch 来验证是否已经接收到来自 Filebeat 的数据。例如,你可以在 Kibana 中查看这些数据,或者直接查询 Elasticsearch 的 API。
以上就是使用 Filebeat 对接 Elasticsearch 监控 logback 日志的基本步骤。在实际操作中,可能还需要根据你的具体需求进行一些额外的配置,例如设置多个输入源、配置日志旋转、添加字段等。
2.2、测试查看效果
我们使用 Python 实现一个生成日志文件的简单脚本
import time
import random
import os
def generate_log():
log_file = os.path.expanduser('~/test.log')
# 如果文件不存在,则创建文件
if not os.path.exists(log_file):
with open(log_file, 'w') as file:
pass
while True:
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
operation = random.choice(["操作1", "操作2", "操作3"]) # 随机选择操作信息
log = f"{current_time} - {operation}\n"
with open(log_file, 'a') as file:
file.write(log)
print(log) # 在控制台打印日志信息
time.sleep(60) # 暂停60秒,即每分钟插入一条日志
if __name__ == '__main__':
generate_log()这个脚本使用了time和random模块。在generate_log函数中,通过time.strftime函数获取当前时间,并使用random.choice函数随机选择操作信息。然后将时间和操作信息拼接成一条日志,并使用with open语句打开/var/log/test.log文件,以追加模式写入日志。最后使用time.sleep函数暂停60秒,即每分钟插入一条日志。
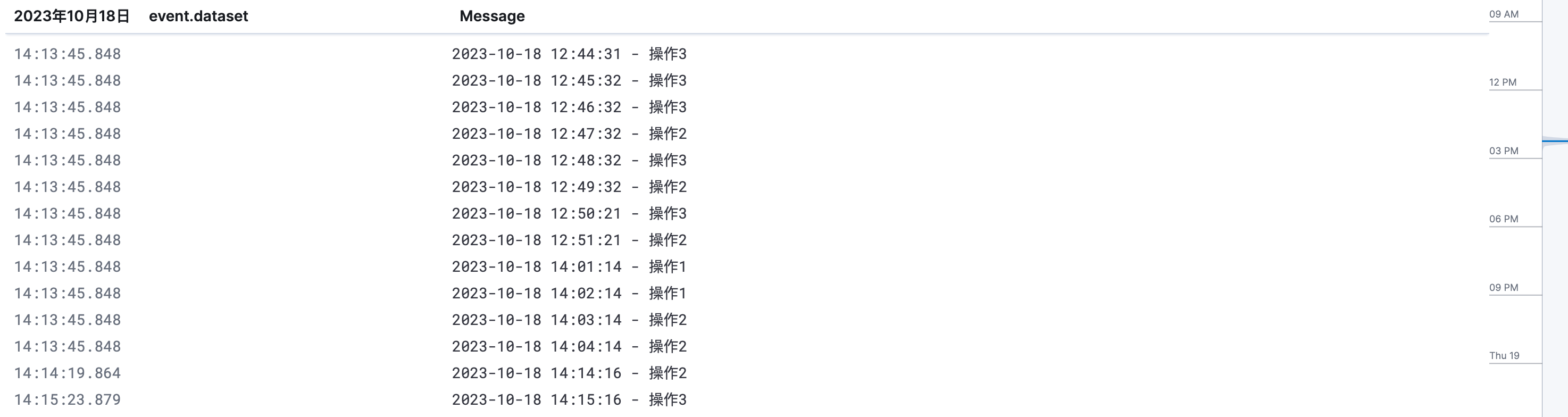
2.3、查看效果
可以通过 kinada 查看效果:
3、Beats数据处理原理
3.1、Beats数据处理原理
Beats 是 Elastic Stack(以前称为 ELK Stack)的一部分,主要负责数据收集。它包括多种类型的 Beat,如 Filebeat、Metricbeat、Packetbeat、Auditbeat 等,每种 Beat 都负责收集一种特定类型的数据。
以下是 Beats 数据收集的基本原理:
- 数据收集:每种 Beat 都会在运行的主机上收集特定类型的数据。例如,Filebeat 会收集日志文件,Metricbeat 会收集系统和服务的指标,Packetbeat 会收集网络流量数据,Auditbeat 会收集审计数据。
- 数据处理:在收集数据之后,Beat 可以对数据进行一些处理,如解析、归一化、丰富等。这是通过配置文件中的处理器(processor)来完成的。
- 数据输出:处理过的数据会被发送到配置的输出目标。Beat 支持多种类型的输出,如 Elasticsearch、Logstash、Kafka、Redis 等。最常见的配置是将数据发送到 Elasticsearch,以便在 Kibana 中进行搜索和可视化。
- 数据转发:在某些情况下,Beat 可以将数据发送到 Logstash 进行更复杂的处理,然后再由 Logstash 将数据发送到 Elasticsearch。
- 模块和集成:为了简化配置和使用,Beat 提供了一系列的模块和集成,可以方便地收集、解析和可视化特定服务(如 Nginx、MySQL、Docker 等)的数据。
总的来说,Beats 的工作原理就是在主机上收集数据,处理数据,然后将数据发送到输出目标。
3.2、Beats和Logstash
Beats 和 Logstash 都是 Elastic Stack 的组件,主要负责数据的收集和处理,但它们的功能和使用场景有所不同。
Beats 是一系列轻量级的数据收集器,每种 Beat 都负责收集一种特定类型的数据。例如,Filebeat 用于收集日志文件,Metricbeat 用于收集系统和服务的指标。Beats 的主要优点是轻量级和低资源消耗,可以直接在数据源(如服务器或容器)上运行。
Logstash 是一个强大的数据处理管道工具,可以接收来自多种源的数据,对数据进行复杂的转换和处理,然后将数据发送到多种目标。Logstash 的主要优点是功能强大和灵活,可以处理各种格式的数据,并支持多种输入、过滤器和输出插件。
以下是 Beats 和 Logstash 的一些主要区别:
- 资源消耗:Beats 是轻量级的,通常在数据源上运行,占用的资源较少。Logstash 功能更强大,但占用的资源也更多,通常在单独的服务器或容器上运行。
- 数据处理能力:Beats 的数据处理能力较弱,主要进行简单的数据解析和丰富。Logstash 的数据处理能力强,可以进行复杂的数据转换和处理。
- 使用场景:如果你只需要收集特定类型的数据,并且数据处理需求较简单,那么使用 Beats 可能更合适。如果你需要处理各种格式的数据,或者需要进行复杂的数据处理,那么使用 Logstash 可能更合适。
在实际使用中,Beats 和 Logstash 通常会一起使用。例如,你可以使用 Beats 在服务器上收集数据,然后将数据发送到 Logstash 进行处理,最后由 Logstash 将处理过的数据发送到 Elasticsearch。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-10-19,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号