Pandas库的基础使用系列---数据查看
原创
Pandas库的基础使用系列---数据查看
原创
IT蜗壳-Tango
发布于 2023-12-11 23:20:46
发布于 2023-12-11 23:20:46
前言
我们上篇文章中介绍了,如何加载excel和csv数据,其实除了这两种数据外,还可以从网站或者数据库中读取数据,这部分我们放到后面再和大家介绍。
有了数据,我们该如何查看呢,今天就和我一起看看如何查看数据的行,列的数据。
head()方法
我们先通过上次内容介绍的read_excel()方法将数据加载到pd这个变量
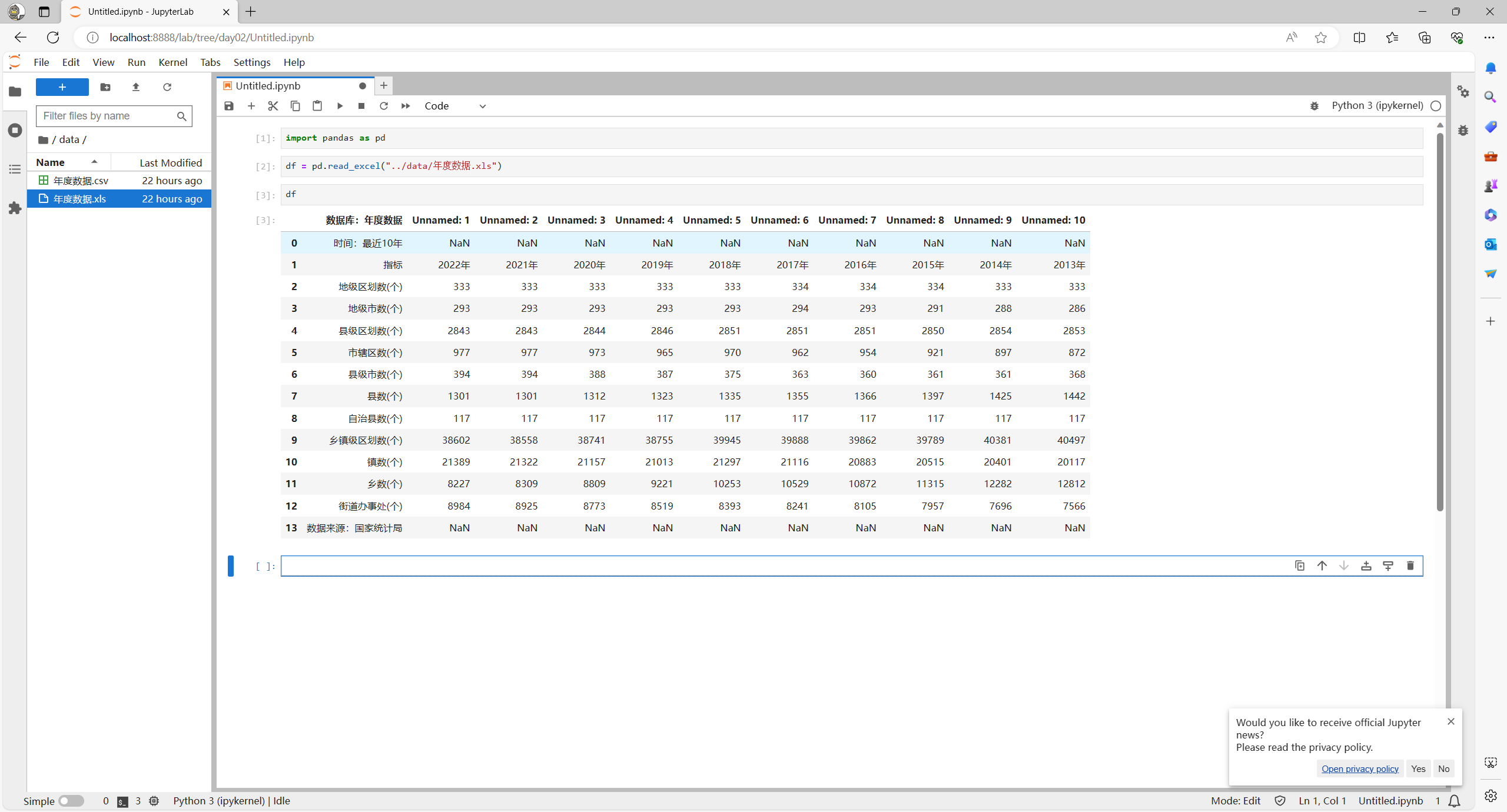
image-20231211222500146
通常我们可以通过head()这个方法,查看整个数据的前5行。运行效果如下

image-20231211222616947
这个方法通常可以使用在确认数据是不是我们想要的,这时并不需要把所有的数据都显示出来,可以通过这个方法来查看前5行的数据即可。
shape属性
我们如果想要获取整个sheet有多少列以及多少行时,可以通过shape这个属性来得到。

image-20231211222949379
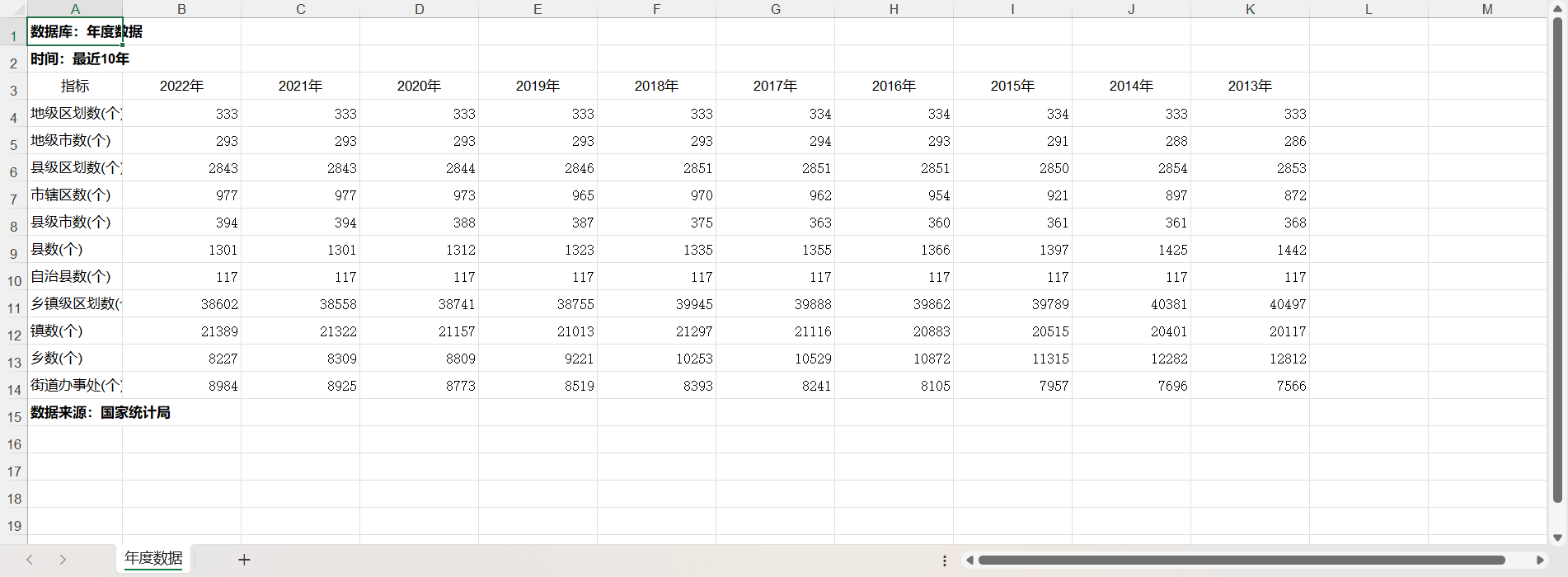
image-20231211223030515
可以看到它返回的是一个元组,元组的第一个元素代表的就是行数,第二个参数就是列数。
columns属性
我们如果想获取这个表格的列名或者表头,则可以使用columns这个属性

image-20231211223432892
但是,对于我们这个张表格来说看起来很奇怪,这也是实际业务场景中经常遇到的问题,表格的作成者可能出于看起来“好看”或什么其他的原因,经常会出现入上图那样,在表格的上方会加一些说明性的文字,从而使我们的代码在执行的时候总是会出现一些奇怪的表现。
那么该如何解决这个问题呢?
其实很简单,我们只需将他前两行跳过即可,你可以使用如下语句重新加载一次数据
df = pd.read_excel("../data/年度数据.xls", skiprows=2)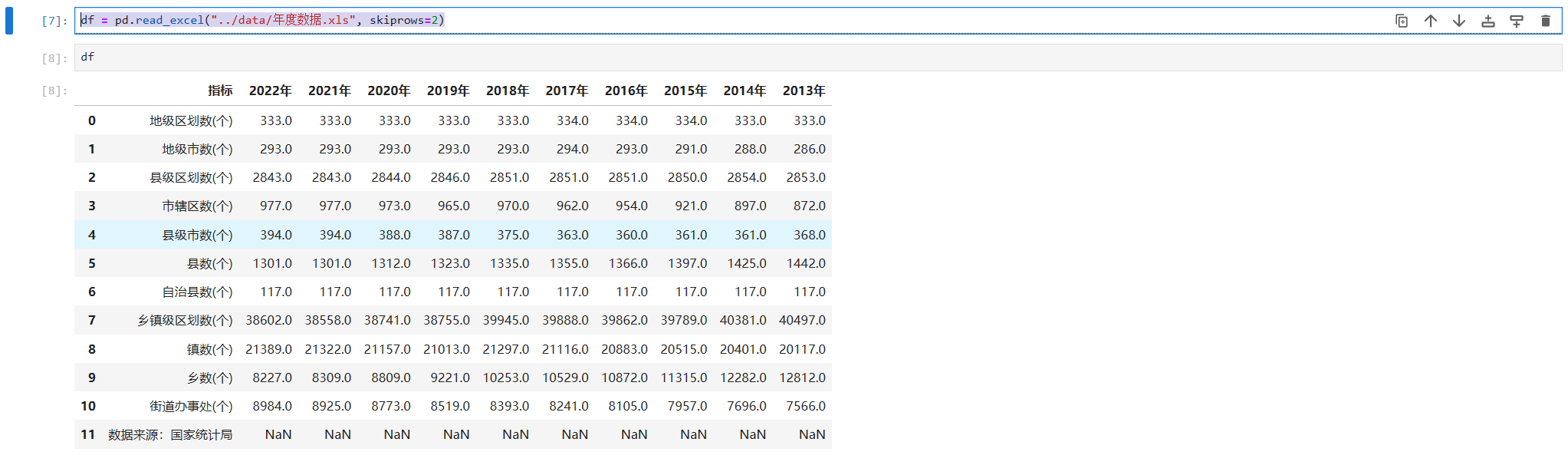
image-20231211223920981
这时我们再通过df.columns来查看一下

image-20231211224004756
这时是不是看着舒服了很多。
可以细心的你,可能已经发现,第十一行的数据似乎也不是我们想要的,那么怎也将他忽略掉呢?
这时,就需要使用组合技能了,
首先我们通过shape这个属性,获取到最大行数,然后再减去去掉这一行即可
df = pd.read_excel("../data/年度数据.xls")
total_rows = df.shape[0]
skip_rows = [0, 1, total_rows]
df = pd.read_excel("../data/年度数据.xls", skiprows=skip_rows)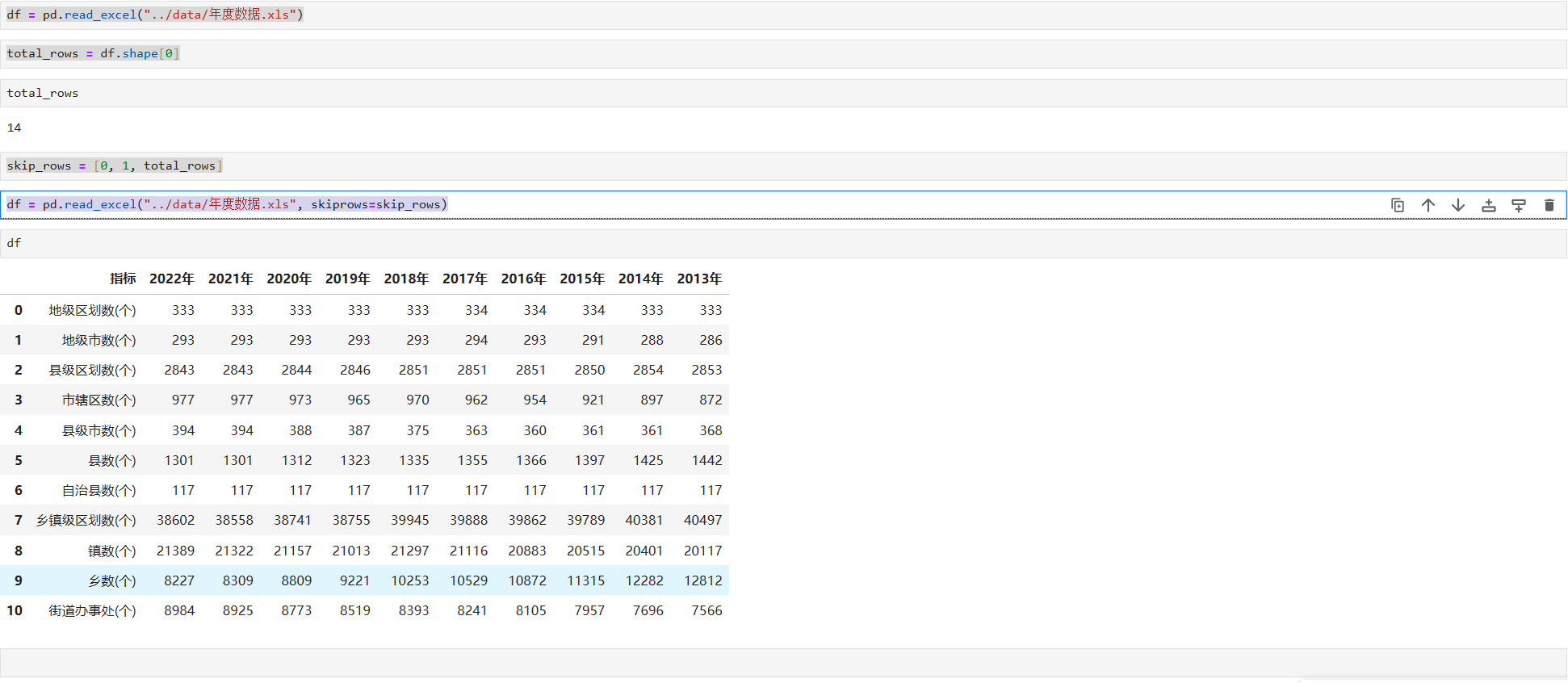
image-20231211225106408
获取指定行的数据
获取行通常我们有三种方法可以完成
- loc: 基于索引标签获取行子集(行名)
- iloc:基于行索引获取子集(行号)
- ix(最新版本以及不支持了,这里就不介绍了)
loc
我们注意到,我们的excel表中并没有0~10的那列索引,这一列时pandas自动帮我们生成的,如果我们还想使用之前的指标那列作为索引该如何操作呢?
df = pd.read_excel("../data/年度数据.xls", skiprows=skip_rows, index_col=0)我们可以通过index_col来指定索引列,运行结果如下
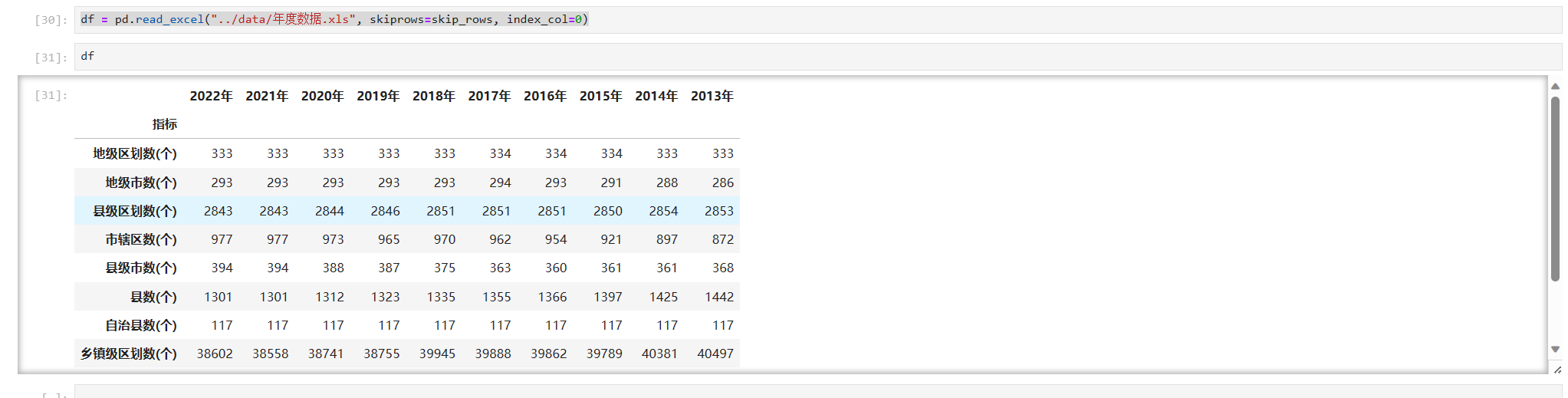
image-20231211230006834
这时,我们可以看到,自动添加的那列索引以及没有了。
接下来我们就可以使用loc这个方法来获取指定行的数据了,例如我们获取县数(个)这行的数据
df.loc["县数(个)"]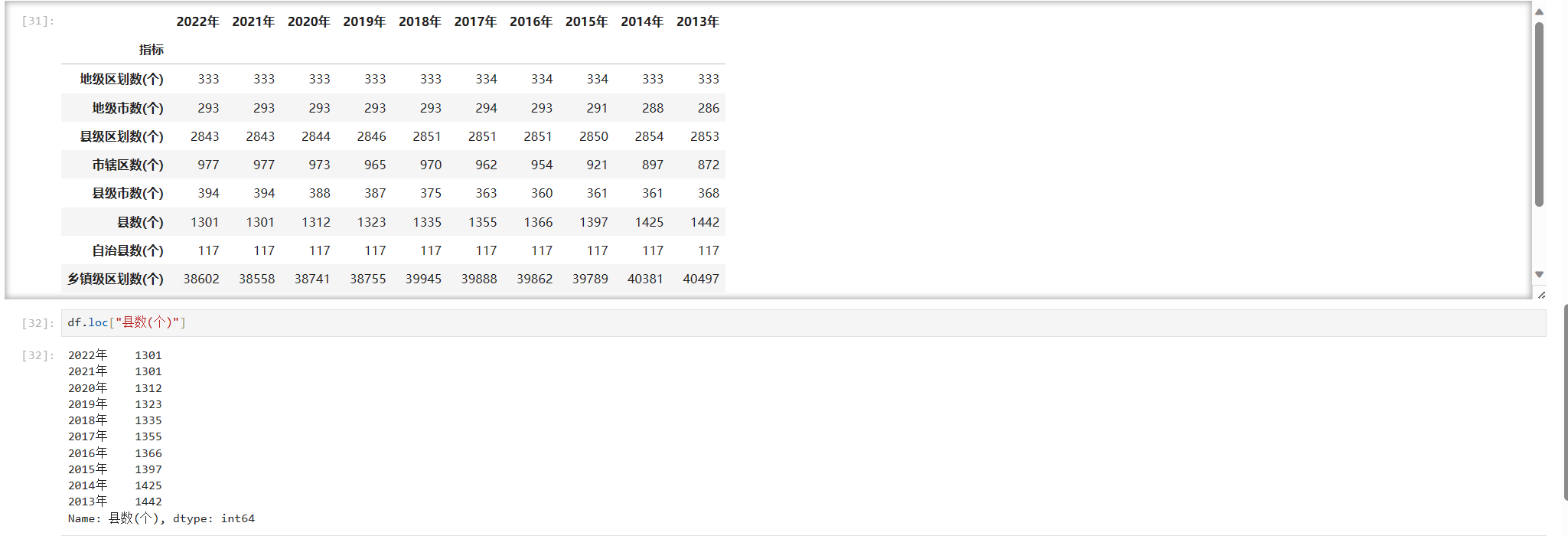
image-20231211230435695
可以看到,我们可以正常的获取到,如果要同时获取多行,只需修改列表中的参数即可

image-20231211230556292
这里需要注意的是我们使用的的是一个列表作为参数传给了
df.loc[]这个方法,不要少了中括号哦。
通过iloc来获取行数据
如果我们的表格并没有类似上面这种表头时该如何获取数据呢?这时我们可以通过指定行号来获取数据,同样我们以获取县数(个)这行的数据为例
df.iloc[5]可以看到,也可以很好的获取到。
多行和上面的用法类似
df.iloc[[2, 5]]
image-20231211231321954
获取指定列的数据
我们可以通过列名来获取数据
df["2021年"]
image-20231211231636143
获取多列和获取行的形式类似
df[["2021年","2014年"]]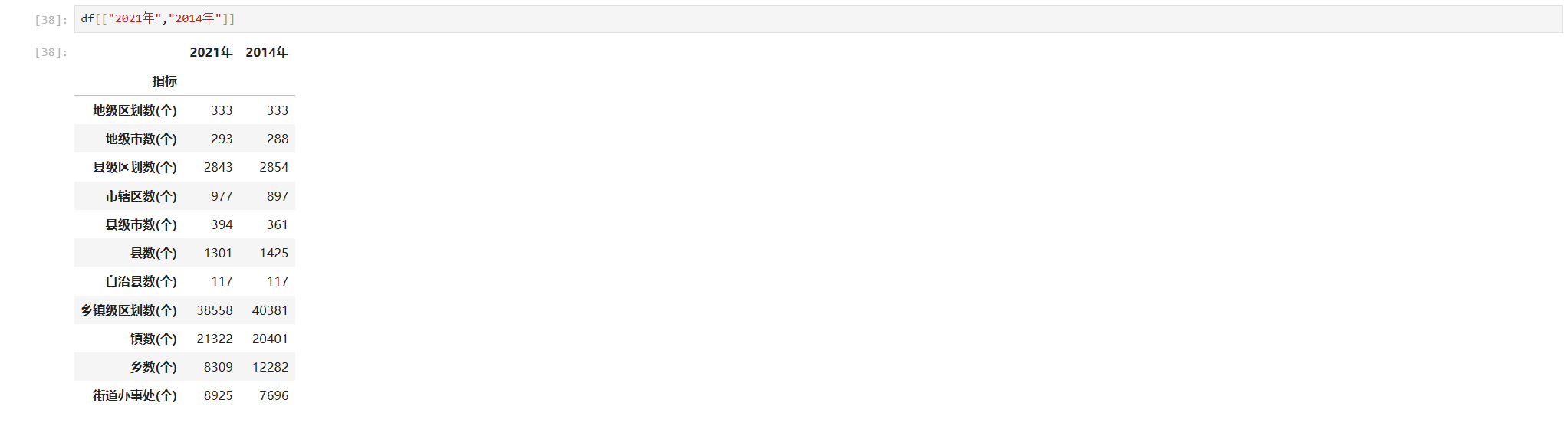
image-20231211231620819
结尾
好了,今天的内容就是这些,下期我们继续分享如果通过行和列一起获取指定单元格的数据。
我是Tango,一个热爱分享技术的程序猿,我们下期见。
我正在参与2023腾讯技术创作特训营第四期有奖征文,快来和我瓜分大奖!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号