集成学习方法——随机森林
原创

之前我们介绍过决策树,随机森林(Random Forest)是将多个决策树(Decision Tree)组合在一起形成一个强大的分类器或回归器,是一种集成学习(Ensemble Learning)方法。
随机森林的主要思想是通过随机选择样本和特征来构建多个决策树,并通过集成这些决策树的预测结果来达到更准确的分类或回归结果。具体步骤如下:
随机选择部分训练样本集;
随机选择部分特征子集;
构建决策树,对每个节点进行特征选择和分裂;
再进行重复,构建多个决策树;
对每个决策树,根据投票或平均值等方法,获得最后的分类或回归结果。
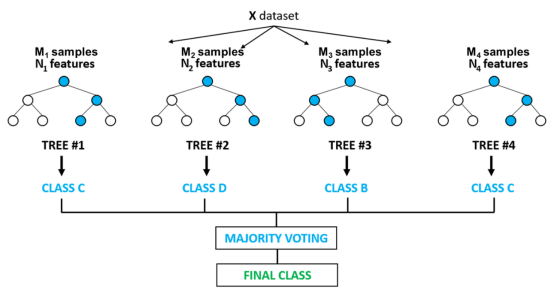
具体而言,随机森林可以通过引入随机性来降低过拟合的风险,并增加模型的多样性。对于分类问题,随机森林采用投票机制来选择最终的类别标签;对于回归问题,随机森林采用平均值作为最终的输出。
随机森林相较于单个决策树具有以下优点:
准确性高:随机森林通过多个决策树的集成,可以减少单个决策树的过拟合风险,从而提高整体的准确性。
鲁棒性强:随机森林对于噪声和异常值具有较好的容错能力,因为它的预测结果是基于多个决策树的综合结果。
处理高维数据:随机森林可以处理具有大量特征的数据,而且不需要进行特征选择,因为每个决策树只使用了部分特征。
可解释性强:随机森林可以提供每个特征的重要性度量,用于解释模型的预测结果。
然而,随机森林也有一些限制和注意事项:
训练时间较长:相比于单个决策树,随机森林的训练时间可能会更长,因为需要构建多个决策树。
内存消耗较大:随机森林对于大规模数据集和高维特征可能需要较大的内存存储。
随机性导致不可复现性:由于随机性的引入,每次构建的随机森林可能会有所不同,这导致模型的结果不具有完全的可重复性。
总的来说,随机森林是一个强大的机器学习方法,它通过构建多个决策树,并根据一定规则进行集成,以提高模型的准确性和稳定性。
喜欢点赞收藏转发,以备不时之需。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号