PostgreSQL 查询语句开发写不好是必然,不是PG的锅

PostgreSQL 查询语句开发写不好是必然,不是PG的锅

AustinDatabases
发布于 2024-01-26 19:19:31
发布于 2024-01-26 19:19:31
最近一个同学在群里咨询PG的语句执行的计划的问题,
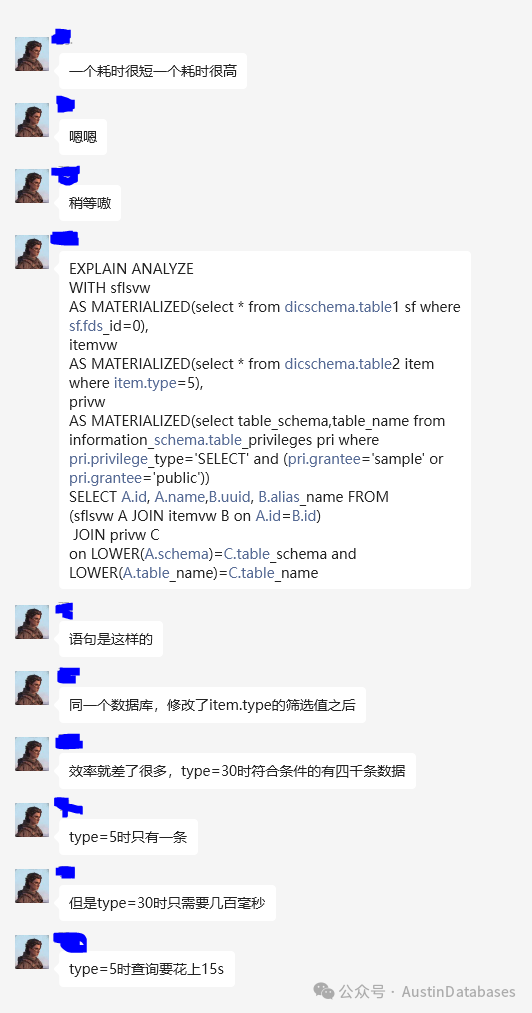
当时指出了一些问题,基于时间的原因知道有问题,但没有说出具体的问题,当时也提到这样写语句,数据库基本上无法走执行计划,因为没有统计分析。
基于不能白说人,光便宜嘴的,做厚脸皮的坏习惯。这个问题的好好的掰扯掰扯。
开发人员为什么不愿意写SQL ,或写不好SQL。 实际开发人员的脑子和DBA的脑子,他不是一个脑子,DBA是逻辑性,严谨性,和条理性,开发人员的脑子,是跳跃的,同时是抽象的,以及面向对象的方式来处理事务的。所以一个SQL 语句他就不是一个面向对象的概念,程序人员,写不好SQL 是很正常的。
这位同学把SQL写成这样就是典型的对象思维模式。但基于数据库的过程性思维,这样做就是对数据库的大大不敬。
我用另一个类似的SQL来模拟一下,相关的语句的以及实际的执行计划
explain analyze SELECT f.film_id, f.title, COUNT(r.rental_id) AS num_rentals, AVG(p.amount) AS average_amount
FROM film f
JOIN inventory i ON f.film_id = i.film_id
JOIN rental r ON i.inventory_id = r.inventory_id
JOIN payment p ON r.rental_id = p.rental_id
GROUP BY f.film_id, f.title;
explain analyze
WITH inventory_w as materialized(select * from inventory),
rental_w as materialized (select * from rental),
payment_w as materialized(select * from payment)
SELECT f.film_id, f.title, COUNT(r.rental_id) AS num_rentals, AVG(p.amount) AS average_amount
FROM film f
JOIN inventory_w i ON f.film_id = i.film_id
JOIN rental_w r ON i.inventory_id = r.inventory_id
JOIN payment_w p ON r.rental_id = p.rental_id
GROUP BY f.film_id, f.title;
语句1 是正常的语句 ,语句2是这位同学的语句,我们在看一下语句的执行计划。
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
-----
HashAggregate (cost=1194.15..1206.65 rows=1000 width=59) (actual time=20.612..21.072 rows=958 loops=1)
Group Key: f.film_id
Batches: 1 Memory Usage: 577kB
-> Hash Join (cost=715.56..1084.68 rows=14596 width=29) (actual time=5.115..16.883 rows=14596 loops=1)
Hash Cond: (i.film_id = f.film_id)
-> Hash Join (cost=639.06..969.70 rows=14596 width=12) (actual time=4.794..13.561 rows=14596 loops=1)
Hash Cond: (r.inventory_id = i.inventory_id)
-> Hash Join (cost=510.99..803.28 rows=14596 width=14) (actual time=3.905..9.586 rows=14596 loops=1)
Hash Cond: (p.rental_id = r.rental_id)
-> Seq Scan on payment p (cost=0.00..253.96 rows=14596 width=10) (actual time=0.005..1.142 rows=14596 loops=1)
-> Hash (cost=310.44..310.44 rows=16044 width=8) (actual time=3.882..3.882 rows=16044 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 755kB
-> Seq Scan on rental r (cost=0.00..310.44 rows=16044 width=8) (actual time=0.004..1.746 rows=16044 loop
s=1)
-> Hash (cost=70.81..70.81 rows=4581 width=6) (actual time=0.879..0.880 rows=4581 loops=1)
Buckets: 8192 Batches: 1 Memory Usage: 243kB
-> Seq Scan on inventory i (cost=0.00..70.81 rows=4581 width=6) (actual time=0.006..0.395 rows=4581 loops=1)
-> Hash (cost=64.00..64.00 rows=1000 width=19) (actual time=0.318..0.318 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 59kB
-> Seq Scan on film f (cost=0.00..64.00 rows=1000 width=19) (actual time=0.009..0.192 rows=1000 loops=1)
Planning Time: 0.936 ms
Execution Time: 21.430 ms
(21 rows)
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
-------------------
HashAggregate (cost=655305.94..655318.44 rows=1000 width=59) (actual time=40.379..40.798 rows=958 loops=1)
Group Key: f.film_id
Batches: 1 Memory Usage: 577kB
CTE inventory_w
-> Seq Scan on inventory (cost=0.00..70.81 rows=4581 width=16) (actual time=0.013..0.306 rows=4581 loops=1)
CTE rental_w
-> Seq Scan on rental (cost=0.00..310.44 rows=16044 width=36) (actual time=0.009..1.176 rows=16044 loops=1)
CTE payment_w
-> Seq Scan on payment (cost=0.00..253.96 rows=14596 width=26) (actual time=0.013..1.039 rows=14596 loops=1)
-> Merge Join (cost=50245.36..453526.17 rows=26819274 width=35) (actual time=28.044..36.896 rows=14596 loops=1)
Merge Cond: (p.rental_id = r.rental_id)
-> Sort (cost=1301.47..1337.96 rows=14596 width=16) (actual time=7.088..8.035 rows=14596 loops=1)
Sort Key: p.rental_id
Sort Method: quicksort Memory: 1069kB
-> CTE Scan on payment_w p (cost=0.00..291.92 rows=14596 width=16) (actual time=0.018..3.860 rows=14596 loops=1)
-> Materialize (cost=48943.89..50781.33 rows=367488 width=23) (actual time=20.568..24.275 rows=16048 loops=1)
-> Sort (cost=48943.89..49862.61 rows=367488 width=23) (actual time=20.565..22.205 rows=16044 loops=1)
Sort Key: r.rental_id
Sort Method: quicksort Memory: 1638kB
-> Merge Join (cost=1900.29..7435.52 rows=367488 width=23) (actual time=11.574..15.878 rows=16044 loops=1)
Merge Cond: (i.inventory_id = r.inventory_id)
-> Sort (cost=458.76..470.21 rows=4581 width=23) (actual time=2.943..3.163 rows=4581 loops=1)
Sort Key: i.inventory_id
Sort Method: quicksort Memory: 550kB
-> Hash Join (cost=76.50..180.20 rows=4581 width=23) (actual time=0.303..2.118 rows=4581 loops=1)
Hash Cond: (i.film_id = f.film_id)
-> CTE Scan on inventory_w i (cost=0.00..91.62 rows=4581 width=6) (actual time=0.014..0.983
rows=4581 loops=1)
-> Hash (cost=64.00..64.00 rows=1000 width=19) (actual time=0.280..0.281 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 59kB
-> Seq Scan on film f (cost=0.00..64.00 rows=1000 width=19) (actual time=0.007..0.154
rows=1000 loops=1)
-> Sort (cost=1441.53..1481.64 rows=16044 width=8) (actual time=8.621..10.039 rows=16044 loops=1)
Sort Key: r.inventory_id
Sort Method: quicksort Memory: 1137kB
-> CTE Scan on rental_w r (cost=0.00..320.88 rows=16044 width=8) (actual time=0.012..4.703 rows=16
044 loops=1)
Planning Time: 1.318 ms
Execution Time: 41.886 ms
(36 rows)
这里我们先看正常的语句,他先找到的 rental 表并对其进行了扫描,然后对payment 进行扫描,然后将两个表中的需要进行对接的部分进行hash 桶操作,然后进hash join ,然后在对inventory 进行扫描并再次产生hash桶,然后将结果再次hash join ,整体的cost 并不很高。
反观在语句中直接进行物化视图的方式,可以看到整体的cost 出奇的高整体的执行计划也变化了,从最后进行inventory的处理,变成一开始就对inventory 进行处理,后续处理的顺序也是按照生成执行计划,并且执行中的执行计划更改为merge join.
从这两点看
1 带有物化cte 方式的语句,并未走好的执行计划
2 没有走好的执行计划,有一点在这里,有可能是因为无法获得有效的统计信息。
同时还可以通过去掉物化的同样的语句来证明这点。我看可以看下面的语句,去掉了物化后,执行计划变得正常和健康了。
dvdrental=# explain analyze
dvdrental-# WITH inventory_w as (select * from inventory),
dvdrental-# rental_w as (select * from rental),
dvdrental-# payment_w as (select * from payment)
dvdrental-# SELECT f.film_id, f.title, COUNT(r.rental_id) AS num_rentals, AVG(p.amount) AS average_amountdvdrental-# FROM film f
dvdrental-# JOIN inventory_w i ON f.film_id = i.film_id
dvdrental-# JOIN rental_w r ON i.inventory_id = r.inventory_id
dvdrental-# JOIN payment_w p ON r.rental_id = p.rental_id
dvdrental-# GROUP BY f.film_id, f.title;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
-------------------------------
HashAggregate (cost=1194.15..1206.65 rows=1000 width=59) (actual time=19.510..19.927 rows=958 loops=1)
Group Key: f.film_id
Batches: 1 Memory Usage: 577kB
-> Hash Join (cost=715.56..1084.68 rows=14596 width=29) (actual time=5.849..16.226 rows=14596 loops=
1)
Hash Cond: (inventory.film_id = f.film_id)
-> Hash Join (cost=639.06..969.70 rows=14596 width=12) (actual time=5.263..12.812 rows=14596 l
oops=1)
Hash Cond: (rental.inventory_id = inventory.inventory_id)
-> Hash Join (cost=510.99..803.28 rows=14596 width=14) (actual time=3.401..8.266 rows=14
596 loops=1)
Hash Cond: (payment.rental_id = rental.rental_id)
-> Seq Scan on payment (cost=0.00..253.96 rows=14596 width=10) (actual time=0.008.
.1.101 rows=14596 loops=1)
-> Hash (cost=310.44..310.44 rows=16044 width=8) (actual time=3.369..3.369 rows=16
044 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 755kB
-> Seq Scan on rental (cost=0.00..310.44 rows=16044 width=8) (actual time=0.
007..1.534 rows=16044 loops=1)
-> Hash (cost=70.81..70.81 rows=4581 width=6) (actual time=1.851..1.852 rows=4581 loops=
1)
Buckets: 8192 Batches: 1 Memory Usage: 243kB
-> Seq Scan on inventory (cost=0.00..70.81 rows=4581 width=6) (actual time=0.009..
0.879 rows=4581 loops=1)
-> Hash (cost=64.00..64.00 rows=1000 width=19) (actual time=0.579..0.579 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 59kB
-> Seq Scan on film f (cost=0.00..64.00 rows=1000 width=19) (actual time=0.015..0.312 ro
ws=1000 loops=1)
Planning Time: 2.198 ms
Execution Time: 20.267 ms
所以这个同学在语句中添加这个物化视图,应该是从解耦的角度出发的,但出发了表在建立时和语句执行在一个事务里面,这些表并未有统计分析的数据,更不要提索引,所以没有统计分析的数据是无法通过cost来进行判断执行计划应该怎么走。这里建议去掉物化视图,在这个语句。
如果要解耦,可以写成一个事务的方式来执行,我们可以看,这里新建的物化视图,然后在查询的方案,也比原来的方案要快 50% 这还是在没有建立索引的情况下。
dvdrental=# begin;
BEGIN
dvdrental=*#
dvdrental=*# create MATERIALIZED VIEW inventory_t as select * from inventory;
SELECT 4581
dvdrental=*# create MATERIALIZED VIEW rental_t as select * from rental;
SELECT 16044
dvdrental=*# create MATERIALIZED VIEW payment_t as select * from payment;
SELECT 14596
dvdrental=*#
dvdrental=*#
dvdrental=*#
dvdrental=*# explain analyze SELECT f.film_id, f.title, COUNT(r.rental_id) AS num_rentals, AVG(p.amount) AS average_amount
dvdrental-*# FROM film f
dvdrental-*# JOIN inventory_t i ON f.film_id = i.film_id
dvdrental-*# JOIN rental_t r ON i.inventory_id = r.inventory_id
dvdrental-*# JOIN payment_t p ON r.rental_id = p.rental_id
dvdrental-*# GROUP BY f.film_id, f.title;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
------------------------------------------------------
Finalize GroupAggregate (cost=302435.43..304591.28 rows=1000 width=59) (actual time=26.798..27.974 rows
=958 loops=1)
Group Key: f.film_id
-> Gather Merge (cost=302435.43..304558.78 rows=2000 width=59) (actual time=26.771..27.129 rows=958
loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=302434.41..302436.91 rows=1000 width=59) (actual time=8.822..8.839 rows=319 loop
s=3)
Sort Key: f.film_id
Sort Method: quicksort Memory: 159kB
Worker 0: Sort Method: quicksort Memory: 25kB
Worker 1: Sort Method: quicksort Memory: 25kB
-> Partial HashAggregate (cost=302372.08..302384.58 rows=1000 width=59) (actual time=8.5
99..8.726 rows=319 loops=3)
Group Key: f.film_id
Batches: 1 Memory Usage: 577kB
Worker 0: Batches: 1 Memory Usage: 73kB
Worker 1: Batches: 1 Memory Usage: 73kB
-> Parallel Hash Join (cost=1430.74..201270.21 rows=13480249 width=35) (actual tim
e=4.102..7.594 rows=4865 loops=3)
Hash Cond: (r.rental_id = p.rental_id)
-> Merge Join (cost=1185.04..3978.22 rows=183555 width=23) (actual time=2.57
7..4.661 rows=5348 loops=3)
Merge Cond: (r.inventory_id = i.inventory_id)
-> Sort (cost=743.54..763.39 rows=7938 width=8) (actual time=1.671..2.
194 rows=5348 loops=3)
Sort Key: r.inventory_id
Sort Method: quicksort Memory: 1137kB
Worker 0: Sort Method: quicksort Memory: 25kB
Worker 1: Sort Method: quicksort Memory: 25kB
-> Parallel Seq Scan on rental_t r (cost=0.00..229.38 rows=7938
width=8) (actual time=0.004..0.576 rows=5348 loops=3)
-> Sort (cost=441.50..453.06 rows=4625 width=23) (actual time=2.707..3
.459 rows=16041 loops=1)
Sort Key: i.inventory_id
Sort Method: quicksort Memory: 550kB
-> Hash Join (cost=76.50..159.95 rows=4625 width=23) (actual tim
e=0.553..2.082 rows=4581 loops=1)
Hash Cond: (i.film_id = f.film_id)
-> Seq Scan on inventory_t i (cost=0.00..71.25 rows=4625 w
idth=6) (actual time=0.023..0.363 rows=4581 loops=1)
-> Hash (cost=64.00..64.00 rows=1000 width=19) (actual tim
e=0.516..0.516 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 59kB
-> Seq Scan on film f (cost=0.00..64.00 rows=1000 wi
dth=19) (actual time=0.009..0.370 rows=1000 loops=1)
-> Parallel Hash (cost=169.20..169.20 rows=6120 width=16) (actual time=1.390
..1.390 rows=4865 loops=3)
Buckets: 16384 Batches: 1 Memory Usage: 832kB
-> Parallel Seq Scan on payment_t p (cost=0.00..169.20 rows=6120 width
=16) (actual time=0.011..1.697 rows=14596 loops=1)
Planning Time: 0.823 ms
Execution Time: 28.579 ms
(39 rows)
所以结论:在语句执行中,不要在一个原子性的操作中,有建立表的活动,这样操作会让新建立的表并未有明确的统计信息协助处理查询。
同时后面这个同学又提出了即使这样改完,语句的执行效率还是不高的问题,提到了隐士转换的问题。
隐士转换的问题,主要发生在
由于查询条件中的变量,和对应查询中的字段column之间的类型不匹配而发生的变量值重新转换格式的问题,这里PG是支持自动进行转换的,但有的时候,你不能确定他转换的type 和实际的type 是否一致,而不一致就会导致执行计划无法正确,在有索引的情况下,也因为类型不匹配而导致的全表扫描或其他问题。
如果避免让数据库自己进行类型的转换,可以在自己的查询的语句值后面标定你的数据类型。如:下面的例子,可以看到,在有索引的情况下
INT ,BIGINT, NUMBERIC 都可以在标定的情况下走索引,而float则不可以,说明在float转换后,无法和原有的值进行匹配导致走了并行的扫描。
SQL的语句撰写本来并不复杂,而基于开发人员在SQL上的思维模式,都在面向对象化的思维处理,都想一条SQL解决问题的思路,以及不注意语句撰写中那些会导致无法走可以优化的执行计划,等等这些问题,会导致如上同学的一些问题。
dvdrental=# explain analyze select * from payment where amount = (888::numeric(5,2));
QUERY PLAN
---------------------------------------------------------------------------------------------------------
-------------
Index Scan using idx_payment on payment (cost=0.29..8.30 rows=1 width=26) (actual time=0.014..0.015 row
s=1 loops=1)
Index Cond: (amount = 888.00::numeric(5,2))
Planning Time: 0.180 ms
Execution Time: 0.029 ms
(4 rows)
dvdrental=# explain analyze select * from payment where amount = (888::int);
QUERY PLAN
---------------------------------------------------------------------------------------------------------
-------------
Index Scan using idx_payment on payment (cost=0.29..8.30 rows=1 width=26) (actual time=0.016..0.017 row
s=1 loops=1)
Index Cond: (amount = '888'::numeric)
Planning Time: 0.214 ms
Execution Time: 0.033 ms
(4 rows)
dvdrental=# explain analyze select * from payment where amount = (888::bigint);
QUERY PLAN
---------------------------------------------------------------------------------------------------------
-------------
Index Scan using idx_payment on payment (cost=0.29..8.30 rows=1 width=26) (actual time=0.015..0.017 row
s=1 loops=1)
Index Cond: (amount = '888'::numeric)
Planning Time: 0.189 ms
Execution Time: 0.031 ms
(4 rows)
dvdrental=# explain analyze select * from payment where amount = (888::float);
QUERY PLAN
---------------------------------------------------------------------------------------------------------
-----------
Gather (cost=1.00..273.23 rows=73 width=26) (actual time=4.008..8.529 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on payment (cost=0.00..199.23 rows=30 width=26) (actual time=1.278..1.279 rows=
0 loops=3)
Filter: ((amount)::double precision = '888'::double precision)
Rows Removed by Filter: 4865
Planning Time: 0.227 ms
Execution Time: 8.550 ms
(8 rows)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-25,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号