自动记账:Python+Beancount


前言
你好,我是测试蔡坨坨。
这是复式记账系列的第四篇文章。在此之前,我们分别讨论了「一年之余,财富何方?」、「财富梳理:复式记账之道」以及「财富编织:Beancount复式记账指南」。分别解决了三个问题:“为什么要记账?”、“如何科学记账?”以及“复式记账工具Beancount的使用”。
相信对于看过前三篇文章并仍然选择继续阅读的你来说,Beancount记账应该是有一定吸引力的。
当我尝试使用Beancount手动记账一段时间后,虽然确实体会到了复式记账带来的财务清晰感,但由于手动记账过于单调乏味,逐渐感到疲倦。为了让记账这件事能够持续且高效地进行下去,实现自动记账势在必行。
在「财富编织:Beancount复式记账指南」文章末尾,也提出了自动记账的方案:
- 使用Python/Java等编程语言,实现账单(微信/支付宝账单)的自动导入和解析。
- 对于没有出现在账单中的交易,可以借助机器人(如Telegram、企业微信、钉钉)来实现
快速随时记账。
在本篇文章中,我们将着手实现第一个方案,即使用Python来实现账单的自动导入和解析。
当我将目光投向自动化复式记账领域,开始寻找相关轮子时,发现GitHub上确实有几个比较完善的工具。然而,它们的扩展性并不理想,有些只适用于支付宝账单,有些则只适用于微信账单。因此,我决定自己动手丰衣足食,实现一个扩展性较好、能够兼容支付宝、微信等账单的自动化复式记账轮子。
项目结构
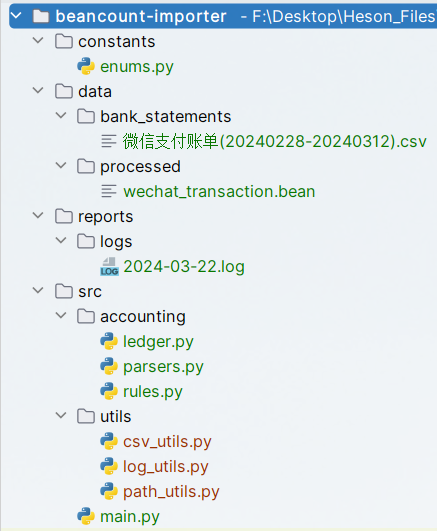
- constants:存放常量和枚举类
- enums.py:枚举类定义
- data:存放账单数据和其他数据文件
- bank_statements:存放账单记录数据
- processed:存放处理后的数据
- reports:存放报告文件
- logs:日志文件
- src:源代码目录
- utils:辅助工具函数
- csv_utils.py:CSV文件操作工具类
- log_utils.py:日志封装类
- path_utils.py:路径封装类
- accounting:核心会计功能模块
- ledger.py:复试记账模块
- rules.py:记账规则模块
- parsers.py:账单解析器模块
- main.py:项目入口文件,主函数
- utils:辅助工具函数
账单下载
微信账单
打开微信 - 我 - 服务 - 钱包 - 点击右上角的账单 - 再点右上角的常见问题 - 下载账单 - 用于个人对账
支付宝账单
打开支付宝 - 我的 - 账单 - 再点击左上角的更多 - 开具交易流水证明 - 用于个人对账 - 申请
读取CSV账单文件
在处理微信账单和支付宝账单之前,我们首先需要读取这些CSV文件。在读取CSV文件时,需确保文件的编码格式是UTF-8。因此,可以编写一个函数来检查文件的编码格式,当文件编码格式非UTF-8时将其转换为UTF-8编码。代码实现如下:
# author: 测试蔡坨坨
# datetime: 2024/1/14 13:02
# function: CSV文件工具类
import csv
import chardet
from src.utils.log_utils import LogUtils
class CSVUtils(object):
def __init__(self, file_path):
self.file_path = file_path
self.logger = LogUtils().logger()
def detect_encoding(self):
"""
获取文件编码
:return: encoding
"""
with open(self.file_path, 'rb') as f:
result = chardet.detect(f.read())
file_encoding = result['encoding']
self.logger.info(f'文件编码格式: {file_encoding}')
return file_encoding
def convert_to_utf8(self):
"""
编码格式统一utf8
:return:
"""
try:
# 检测文件编码
detected_encoding = self.detect_encoding()
if (detected_encoding is not None) and (detected_encoding.lower() != 'utf-8'):
with open(self.file_path, 'r', encoding=self.detect_encoding()) as raw_file:
csv_content = raw_file.read()
with open(self.file_path, 'w', encoding='utf-8') as utf8_file:
# 将内容写入 UTF-8 编码文件
utf8_file.write(csv_content)
self.logger.info(f'原文件编码格式:{detected_encoding},新文件编码格式:utf-8')
except FileNotFoundError:
print(f"File not found: {self.file_path}")
except Exception as e:
print(f"Error converting file: {e}")
def read_csv(self, start_row=1):
"""
读取csv文件并转换成列表
:param start_row: 从第N行读起
:return:
"""
self.convert_to_utf8()
data = []
try:
with open(self.file_path, 'r', newline='', encoding='utf-8') as file:
csv_reader = csv.reader(file)
# Skip rows until reaching the specified start_row
for _ in range(start_row - 1):
next(csv_reader)
# Read data from the specified start_row
for row in csv_reader:
# Remove '\t' from each element in the row
row = [element.replace('\t', '') for element in row]
data.append(row)
except FileNotFoundError:
self.logger.error(f'File not found: {self.file_path}')
except Exception as e:
self.logger.error(f'Error reading CSV file: {e}')
return data
定义枚举值
对于一些固定的常量,比如:供应商、账户、账单类型、交易类型,在enums.py中定义枚举类:
# author: 测试蔡坨坨
# datetime: 2024/3/20 1:01
# function: 枚举类
from enum import Enum
class AccountEnum(Enum):
ASSETS_CURRENT_BANK_CMB1234 = 'Assets:Current:Bank:CMB1234'
ASSETS_CURRENT_BANK_ABC5770 = 'Assets:Current:Bank:ABC1234'
ASSETS_CURRENT_WECHAT_MINIFUND = 'Assets:Current:Wechat:MiniFund'
ASSETS_CURRENT_WECHAT_WALLET = 'Assets:Current:Wechat:Wallet'
EXPENSES_FOOD = 'Expenses:Food'
EXPENSES_TRANSPORT = 'Expenses:Transport'
EXPENSES_CLOTHING = 'Expenses:Clothing'
EXPENSES_OTHER = 'Expenses:Other'
EXPENSES_COMMUNICATION = 'Expenses:Communication'
EXPENSES_DAILY = 'Expenses:Daily'
LIABILITIES_HUABEI = 'Liabilities:Huabei'
INCOME_OTHER = 'Income:Other'
INCOME_SIDELINE = 'Income:Sideline'
def __str__(self):
return self.value
class ProviderEnum(Enum):
WECHAT = 'wechat'
ALIPAY = 'alipay'
def __str__(self):
return self.value
class WechatColumnEnum(Enum):
TRADE_TYPE = 1 # 交易类型
TRADE_OBJECT = 2 # 交易对方
PRODUCT = 3 # 商品
INCOME_EXPENSE = 4 # 收/支
PAY_METHOD = 6 # 交易方式
PAY_STATUS = 7 # 交易状态
class AlipayColumnEnum(Enum):
TRADE_TYPE = 1
TRADE_OBJECT = 2
PRODUCT = 4
INCOME_EXPENSE = 5
PAY_METHOD = 7
PAY_STATUS = 8
账单解析
提取每条交易记录中的有用字段,例如:交易类型、交易对方、商品、收支情况、交易方式、交易状态。不同供应商的账单,字段所处的列可能不一样,我们可以利用前面定义的枚举类来指定每个字段在CSV文件中的列序号。然后,编写一个函数来解析每条记录,并根据指定的列序号提取字段的值。如下代码所示:
# author: 测试蔡坨坨
# datetime: 2024/2/20 1:14
# function: 账单解析
from constants.enums import AlipayColumnEnum, ProviderEnum, WechatColumnEnum
class Parsers(object):
@staticmethod
def generator_rule(provider, trade_type, trade_object, product, income_expense,
pay_method, pay_status, debit_account, credit_account):
column = WechatColumnEnum if provider == ProviderEnum.WECHAT else AlipayColumnEnum
rule = {
'route': {
column.value: value
for column, value in
zip(column, [trade_type, trade_object, product, income_expense, pay_method, pay_status])
},
'account': {
'debit': debit_account,
'credit': credit_account
}
}
return rule
微信账单样式:

支付宝账单样式:

解析规则
根据每条交易记录的有效字段定义匹配规则,且每个字段支持正则匹配,并确认每笔交易在记账中的借方和贷方。如下示例:
class Rules:
# (供应商, 交易类型, 交易对方, 商品, 收支, 支付方式, 当前状态, 借方, 贷方)
wechat_rules = [
# 借:费用增加 贷:资产减少
(ProviderEnum.WECHAT, '商户消费', '', '美团', '支出', '零钱通', '支付成功', AccountEnum.EXPENSES_FOOD, AccountEnum.ASSETS_CURRENT_WECHAT_MINIFUND),
(ProviderEnum.WECHAT, '商户消费', '', '美团|叮咚买菜', '支出', '招商银行.*1234', '支付成功|已退款', AccountEnum.EXPENSES_FOOD, AccountEnum.ASSETS_CURRENT_BANK_CMB1234),
(ProviderEnum.WECHAT, '商户消费', '', '车', '支出', '招商银行.*1234', '支付成功', AccountEnum.EXPENSES_TRANSPORT, AccountEnum.ASSETS_CURRENT_BANK_CMB1234),
(ProviderEnum.WECHAT, '商户消费', '', '手机话费', '支出', '招商银行.*1234', '支付成功', AccountEnum.EXPENSES_COMMUNICATION, AccountEnum.ASSETS_CURRENT_BANK_CMB1234),
(ProviderEnum.WECHAT, '商户消费|转账|微信红包|扫二维码付款', '', '', '支出', '招商银行.*1234', '支付成功|对方已收钱|已转账', AccountEnum.EXPENSES_OTHER, AccountEnum.ASSETS_CURRENT_BANK_CMB1234)
# 借:资产增加 贷:收入增加
(ProviderEnum.WECHAT, '红包|转账', '', '', '收入', '', '已存入零钱|已到账', AccountEnum.ASSETS_CURRENT_WECHAT_WALLET, AccountEnum.INCOME_OTHER),
(ProviderEnum.WECHAT, '其他', '赞赏作者的收款', '/', '收入', '', '已到账', AccountEnum.ASSETS_CURRENT_WECHAT_WALLET, AccountEnum.INCOME_SIDELINE)
# 借:资产增加 贷:资产减少
(ProviderEnum.WECHAT, '转入零钱通-来自招商银行.*1234', '', '/', '/', '招商银行.*1234', '支付成功', AccountEnum.ASSETS_CURRENT_WECHAT_MINIFUND, AccountEnum.ASSETS_CURRENT_BANK_CMB1234),
(ProviderEnum.WECHAT, '转入零钱通-来自零钱', '', '', '/', '零钱', '支付成功', AccountEnum.ASSETS_CURRENT_WECHAT_MINIFUND, AccountEnum.ASSETS_CURRENT_WECHAT_WALLET),
(ProviderEnum.WECHAT, '零钱通转出-到招商银行.*1234', '', '/', '/', '零钱通', '支付成功', AccountEnum.ASSETS_CURRENT_BANK_CMB1234, AccountEnum.ASSETS_CURRENT_WECHAT_MINIFUND)
]
alipay_rules = [
# 借:费用增加 贷:资产减少
(ProviderEnum.ALIPAY, '服饰装扮', '', '', '支出', '招商银行.*1234', '交易成功|等待确认收货', AccountEnum.EXPENSES_CLOTHING, AccountEnum.ASSETS_CURRENT_BANK_CMB1234),
(ProviderEnum.ALIPAY, '餐饮美食', '', '', '支出', '招商银行.*1234', '交易成功|等待确认收货', AccountEnum.EXPENSES_FOOD, AccountEnum.ASSETS_CURRENT_BANK_CMB1234),
(ProviderEnum.ALIPAY, '交通出行', '', '', '支出', '招商银行.*1234', '交易成功', AccountEnum.EXPENSES_TRANSPORT, AccountEnum.ASSETS_CURRENT_BANK_CMB1234),
# 借:费用增加 贷:负债增加
(ProviderEnum.ALIPAY, '交通出行', '', '火车票', '支出', '花呗', '交易成功', AccountEnum.EXPENSES_TRANSPORT, AccountEnum.LIABILITIES_HUABEI),
# 借:负债减少 贷:资产减少
(ProviderEnum.ALIPAY, '信用借还', '', '花呗', '不计收支', '招商银行.*1234', '还款成功', AccountEnum.LIABILITIES_HUABEI, AccountEnum.ASSETS_CURRENT_BANK_CMB1234),
]
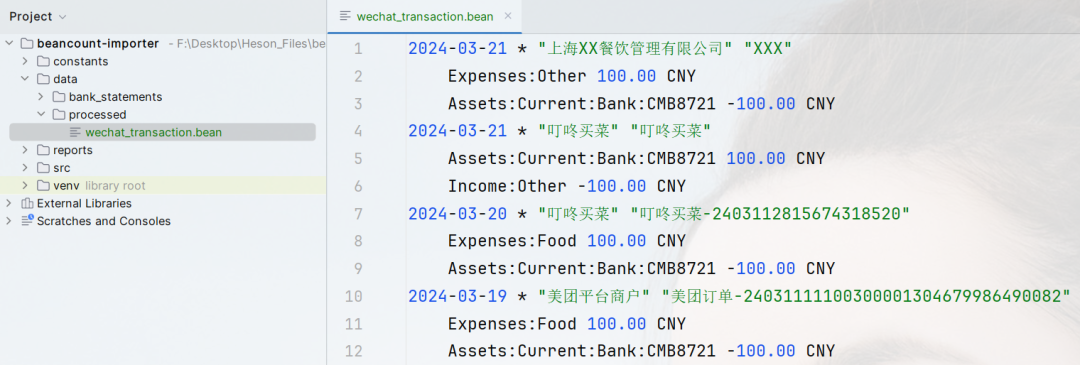
记账
定义好解析规则后,接着就是将账单中的每一笔交易与定义好的规则进行匹配,若命中规则便按照Beancount交易记录的格式进行记账,并输出到文件中。
Beancount记账语法:
2024-01-01 * "滴滴打车" "打车到公司,银行卡支付"
Expenses:Traffic:Taxi 200.00 CNY
Assets:Card:1234 -200.00 CNY
其中需要注意日期格式、交易方、交易备注、金额保留两位小数……
代码实现如下:
# author: 测试蔡坨坨
# datetime: 2024/3/20 1:39
# function: 记账
import os
import re
from datetime import datetime
from constants.enums import ProviderEnum
from src.accounting.parsers import Parsers
from src.accounting.rules import Rules
from src.utils.csv_utils import CSVUtils
from src.utils.log_utils import LogUtils
from src.utils.path_utils import PathUtils
class Ledger(object):
def __init__(self):
self.logger = LogUtils().logger()
self.rules_wechat = [Parsers.generator_rule(*pattern) for pattern in Rules.wechat_rules]
self.rules_alipay = [Parsers.generator_rule(*pattern) for pattern in Rules.alipay_rules]
def contains_keywords(self, text, keyword_pattern):
"""
正则匹配
:param text: 充值|会员
:param keyword_pattern: 商户消费充值支出招商银行(1234)支付成功
:return:
"""
# 构建正则表达式
regex = re.compile(keyword_pattern, flags=re.IGNORECASE)
return bool(regex.search(text))
def process_row(self, provider, row, outer_file_path):
"""
记账
:param provider:
:param row:
:param outer_file_path:
:return:
"""
matched = False # 默认情况下,认为未匹配到规则
# 解析规则
match_rules = None
if provider == ProviderEnum.WECHAT:
match_rules = self.rules_wechat
elif provider == ProviderEnum.ALIPAY:
match_rules = self.rules_alipay
for rule in match_rules:
if all(self.contains_keywords(row[key], value) for key, value in rule['route'].items()):
# 交易时间
row[0] = datetime.strptime(row[0], "%Y-%m-%d %H:%M:%S").strftime("%Y-%m-%d")
# 金额
amount = 0.00
# 商品说明
detail = ''
# 微信账单
if provider == ProviderEnum.WECHAT:
amount = '{:.2f}'.format(float(row[5].replace('¥', '')))
detail = row[1] if row[3] == '/' else row[3]
# 支付宝账单
if provider == ProviderEnum.ALIPAY:
amount = '{:.2f}'.format(float(row[6].replace('¥', '')))
detail = row[4]
# 构建内容字符串
content = (f"{row[0]} * \"{row[2]}\" \"{detail}\"\n"
f"{' ' * 4}{rule['account']['debit']} {amount} CNY\n"
f"{' ' * 4}{rule['account']['credit']} -{amount} CNY\n")
# 将内容写入到文件
with open(outer_file_path, 'a', encoding='utf-8') as file:
file.write(content)
# mark matched
matched = True
# 如果匹配到一条规则,就退出循环,不再检查其他规则
break
return matched
def parse_bill(self, provider, start_row, file_path):
"""
解析账单
:param provider: 供应商
:param start_row: 开始行数
:param file_path: 文件路径
:return:
"""
outer_file_path = PathUtils().get_project_path() + 'data/processed/' + f'{provider}_transaction.bean'
# 判断文件是否存在
if os.path.exists(outer_file_path):
# 如果文件存在,删除文件
os.remove(outer_file_path)
self.logger.info(f'The file {outer_file_path} has been deleted.')
else:
self.logger.info(f'The file {outer_file_path} does not exist.')
csv_handler = CSVUtils(file_path)
# Reading CSV from the N row, each field separated by commas
data = csv_handler.read_csv(start_row)
unmatched_data = []
for row in data:
matched = self.process_row(provider, row, outer_file_path)
if not matched:
unmatched_data.append(row)
unmatched_data_num = len(unmatched_data)
# 未匹配到规则的订单
with open(outer_file_path, 'a', encoding='utf-8') as file:
file.write(f'\n未匹配到规则的订单共{unmatched_data_num}条:\n')
for row in unmatched_data:
file.write(f'{row}\n')
self.logger.info(f'\n{provider}未匹配到规则的订单共{unmatched_data_num}条:\n{unmatched_data}')
主函数
运行main.py主函数,完成自动记账。
# author: 测试蔡坨坨
# datetime: 2024/3/20 0:45
# function: 项目入口
from constants.enums import ProviderEnum
from src.accounting.ledger import Ledger
from src.utils.path_utils import PathUtils
class Main:
@staticmethod
def main():
file_path = PathUtils().get_project_path() + 'data/bank_statements/微信支付账单.csv'
Ledger().parse_bill(ProviderEnum.WECHAT, 18, file_path)
if __name__ == '__main__':
Main.main()
以上,完。
脚踏实地,仰望星空,和坨坨一起学习软件测试,升职加薪!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号