Spark Core 整体介绍


一. 简介
二. 核心概念
1. num-executor优化
–num-executors: 执行器个数,执行器数可以为节点个数,也可以为总核数(单节点核数*节点数),也可以是介于俩者之间(用于调优) –executor-cores: 执行器核数, 核数可以1,也可以为单节点的内核书,也可以是介于俩者之间(用于调优) –executor-memory: 执行器内存, 可以为最小内存数(单节点内存总数/单节点核数),也可以为最大内存数(单节点内存总数),也可以是介于俩者之间(用于调优)
使用较小的executors 核数较小,内核较小 使用较大的executors 核数较大,内核较大 使用优化的executors 核数合适,内核合适
executor优化策略 从执行器核数入手,以此类推
参考: https://my.oschina.net/u/4331678/blog/3629181
2. 节点
2.1 Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。Driver 在 Spark 作业执行时主要负责:
1. 将代码逻辑转化为任务; 2. 在 Executor 之间调度任务(job); 3. 跟踪 Executor 的执行情况(task)。
2.2 Executor
Spark 执行器节点,负责在 Spark 作业中运行具体任务,任务之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。Executor 有两个核心功能:
1. 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程; 2. 通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD提供内存式存储。RDD 是直接缓存在 Executor 程内的,因此任务可以在运行时充分利用缓存数据加速运算。
2.3 spark core ask 执行流程
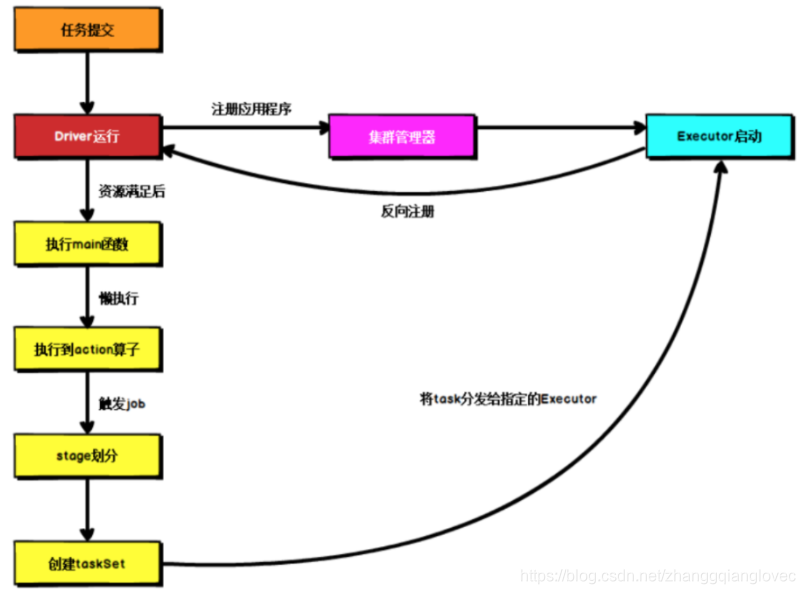
不论spark以何种方式部署,在任务提交后,都先启动Driver,然后Driver向集群管理器注册应用程序,之后集群管理器根据此任务的配置文件分配Executor并启动,然后Driver等待资源满足,执行 main 函数,Spark的查询为懒执行,当执行到 action 算子时才开始真正执行,开始反向推算,根据宽依赖进行 stage 的划分,随后每一个 stage 对应一个 taskset,一个taskset 中有多个 task,task 会被分发到指定的 Executor 去执行,在任务执行的过程中,Executor 也会不断与 Driver 进行通信,报告任务运行情况。
参考:https://www.cnblogs.com/valjeanshaw/p/12532723.html
3. 部署模式
spark共支持3种集群管理器,Standalone,Mesos和Yarn
3.1 Standalone
独立模式,Spark 原生的最简单的一个集群管理器。 它可以运行在各种操作系统上,自带完整的服务,无需依赖任何其他资源管理系统,使用 Standalone 可以很方便地搭建一个集群。
3.2 Apache Mesos
Mesos也是一个强大的分布式资源管理框架,是以与Linux内核同样的原则而创建的,允许多种不同的框架部署在其上
3.3 Hadoop Yarn
Hadoop生态下的统一资源管理机制,在上面可以运行多套计算框架,如mapreduce、spark 等,根据 driver 在集群中的位置不同,部署模式可以分为 yarn-client 和 yarn-cluster。
Spark 的运行模式取决于传递给 SparkContext 的 MASTER 环境变量的值,spark在yarn上部署: yarn-client:Driver在本地,Executor在Yarn集群,配置:–deploy-mode client yarn-cluster:Driver和Executor都在Yarn集群,配置:–deploy-mode cluster
4. Yarn模式的运行机制
4.1 yarn-client
spark task yarn client 模式
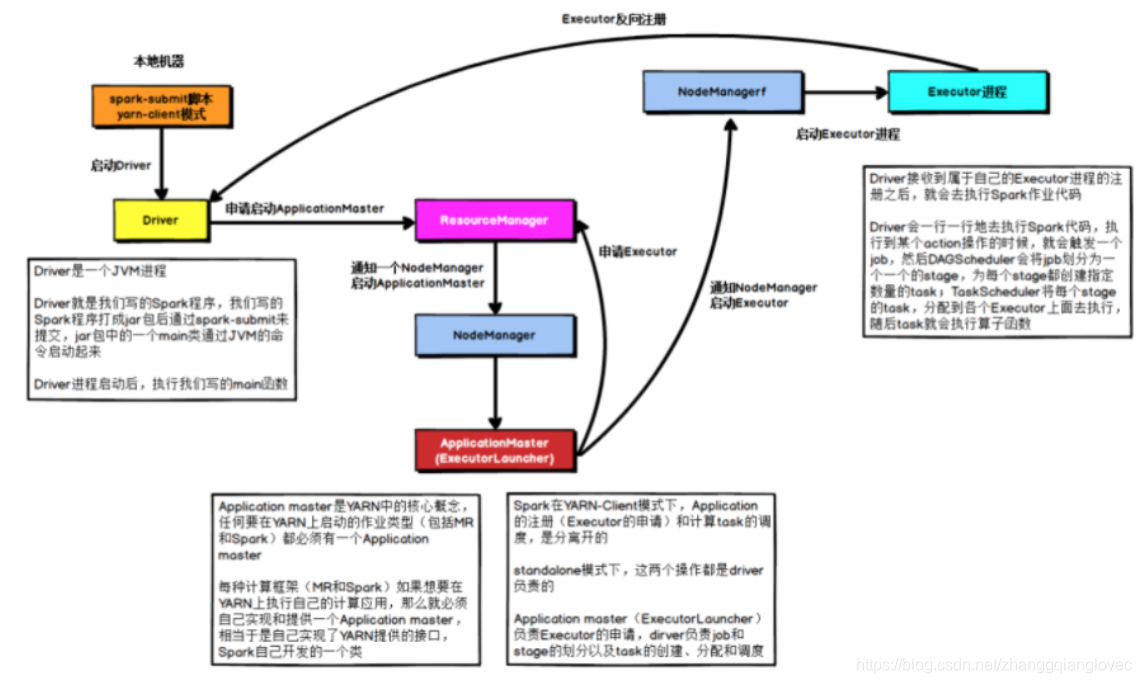
在YARNClient模式下,Driver在任务提交的本地机器上运行,Driver会向ResourceManager申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。 ResourceManager接到ApplicationMaster的资源申请后会分配container,然后 ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Executor进程启动后会向Driver反向注册。另外一条线,Driver自身资源满足的情况下,Driver开始执行main函数,之后执行Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,Executor注册完成后,Driver将task分发到各个Executor上执行。
4.2 yarn-cluster
spark task yarn cluster 模式
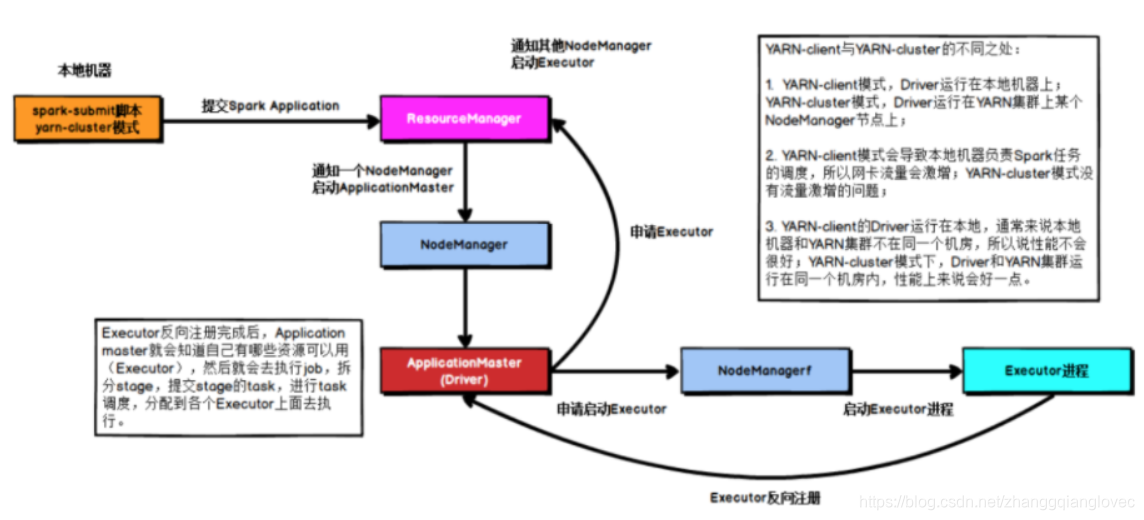
在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster,随后 ResourceManager 分配 container,在合适的 NodeManager上启动 ApplicationMaster,此时的ApplicationMaster 就是 Driver。
Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager会分配container,然后在合适的 NodeManager 上启动 Executor 进程,Executor 进程启动后会向 Driver 反向注册。另外一条线,Driver自身资源满足的情况下,开始执行main函数,之后执行Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,Executor注册完成后,Driver将task分发到各个Executor上执行。
参考:https://www.cnblogs.com/valjeanshaw/p/12532723.html
4. 任务调度
Driver会根据用户程序准备任务,并向Executor分发任务,在这儿有几个Spark的概念需要先介绍一下: Job:以Action算子为界,遇到一个Action方法就触发一个Job Stage:Job的子集,一个job至少有一个stage,以shuffle(即RDD宽依赖)为界,一个shuffle划分一个stage Task: Stage 的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
spark在具体任务的调度中,总的分两路进行:Stage级别调度和Task级别调度。 Spark RDD通过转换(Transactions)算子,形成了血缘关系图DAG,最后通过行动(Action)算子,触发Job并调度执行。 DAGScheduler负责Stage级的调度,主要是将DAG切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。 TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行
4.1 Spark Stage级调度
Spark的任务调度是从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来处理。
DAGScheduler主要做两个部分的事情:
- 切分stage AGScheduler会根据RDD的血缘关系构成的DAG进行切分,将一个Job划分为若干Stages,具体划分策略是:从后往前,由最终的RDD不断通过依赖回溯判断父依赖是否是宽依赖,遇到一个shuffle就划分一个Stage。无shuffle的称为窄依赖,窄依赖之间的RDD被划分到同一个Stage中。划分的Stages分两类,一类叫做ResultStage,为DAG最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据。
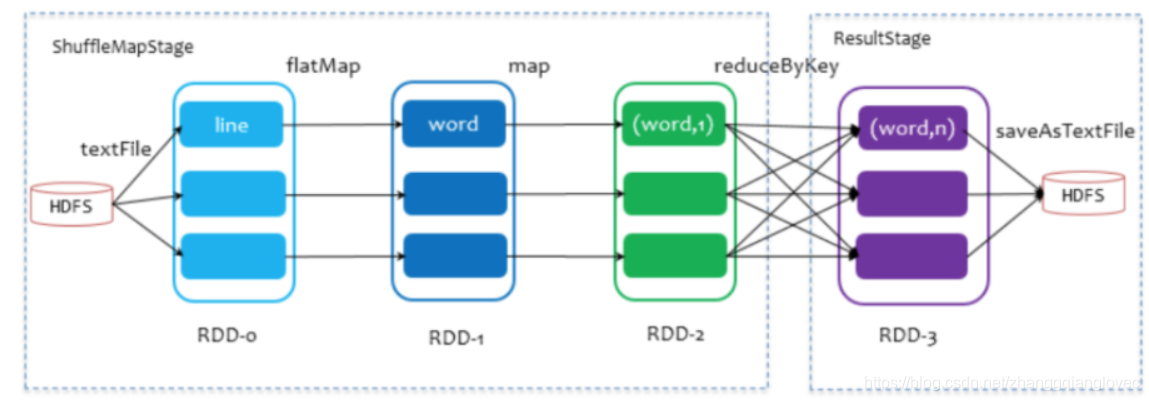
stage任务调度本身是一个反向的深度遍历算法,以下图wordcount为例。此处只有saveAsTextFile为行动算子,该 Job 由 RDD-3 和 saveAsTextFile方法组成,根据依赖关系回溯,知道回溯至没有依赖的RDD-0。回溯过程中,RDD-2和RDD-3存在reduceByKey的shuffle,会划分stage,由于RDD-3在最后一个stage,即划为ResultStage,RDD-2,RDD-1,RDD-0,这些依赖之间的转换算子flatMap,map没有shuffle,因为他们之间是窄依赖,划分为ShuffleMapStage。
spark task dagscheduler dag调度
- 打包Taskset提交Stage 一个Stage如果没有父Stage,那么从该Stage开始提交,父Stage执行完毕才能提交子Stage。Stage提交时会将Task信息(分区信息以及方法等)序列化并被打包成TaskSet交给TaskScheduler,一个Partition对应一个Task,另一方面TaskScheduler会监控Stage的运行状态,只有Executor丢失或者Task由于Fetch失败才需要重新提交失败的Stage以调度运行失败的任务,其他类型的Task失败会在TaskScheduler的调度过程中重试。
4.2 Spark Task 级调度
SparkTask的调度是由TaskScheduler来完成,TaskScheduler将接收的TaskSet封装为TaskSetManager加入到调度队列中。同一时间可能存在多个TaskSetManager,一个TaskSetManager对应一个TaskSet,而一个TaskSet含有n多个task信息,这些task都是同一个stage的。 TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态,SchedulerBackend会监控到有资源后,会询问TaskScheduler有没有任务要运行,TaskScheduler会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行。
TaskSetManager按照一定的调度规则一个个取出task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。 Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的运行状态
4.3 失败重试和白名单
对于运行失败的Task,TaskSetManager会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中等待重新执行,当重试次数过允许的最大次数,整个Application失败。在记录Task失败次数过程中,TaskSetManager还会记录它上一次失败所在的ExecutorId和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。
参考:https://www.cnblogs.com/valjeanshaw/p/12532723.html
5. DAG(有向无环图)
Lineage(血缘关系),即DAG拓扑排序的结果优点
优点 惰性调用、管道化、避免同步等待、不需要保存中间结果、每次操作变得简单
6. RDD
一个 RDD 就是一个分布式对象集合,提供了一种高度受限的共享内存模型,其本质上是一个只读的分区记录集合,不能直接修改。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段,并且一个 RDD 的不同分区可以保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算
正是 RDD 的这种惰性调用机制,使得转换操作得到的中间结果不需要保存,而是直接管道式的流入到下一个操作进行处理
6.1 设计与运行原理
在实际应用中,存在许多迭代式算法和交互式数据挖掘工具,这些应用场景的共同之处在于不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。而 Hadoop 中的 MapReduce 框架都是把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销,并且通常只支持一些特定的计算模式。而 RDD 提供了一个抽象的数据架构,从而让开发者不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同 RDD 之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销。
6.2 特性
- 高效的容错性
- 中间结果持久化到内存
6.3 RDD依赖关系
窄依赖(Narrow Dependency)与宽依赖(Wide Dependency)
RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide Dependencies用来解决数据容错时的高效性。
Narrow Dependencies是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
Wide Dependencies是指子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。对与Wide Dependencies,这种计算的输入和输出在不同的节点上,lineage方法对与输入节点完好,而输出节点宕机时,通过重新计算,这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上其祖先追溯看是否可以重试(这就是lineage,血统的意思),Narrow Dependencies对于数据的重算开销要远小于Wide Dependencies的数据重算开销。
spark rdd dependencice 依赖
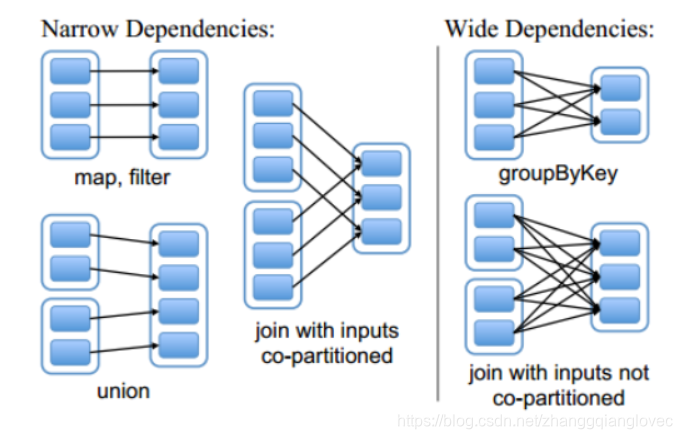
其中,窄依赖表示的是父 RDD 和子 RDD 之间的一对一关系或者多对一关系,主要包括的操作有 map、filter、union 等;而宽依赖则表示父 RDD 与子 RDD 之间的一对多关系,即一个父 RDD 转换成多个子 RDD,主要包括的操作有 groupByKey、sortByKey 等。
spark core rdd 依赖
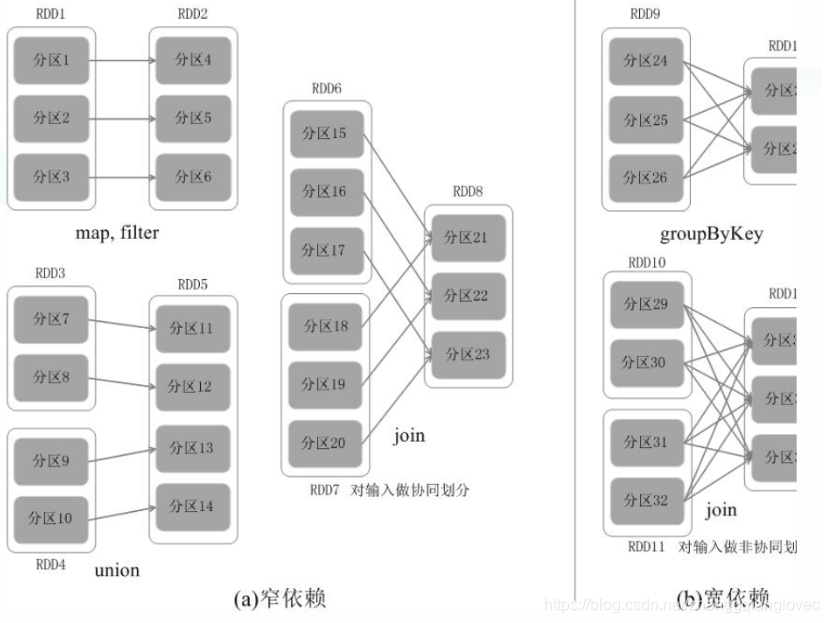
对于窄依赖的 RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的 RDD,则通常伴随着 Shuffle 操作,即首先需要计算好所有父分区数据,然后在节点之间进行 Shuffle。因此,在进行数据恢复时,窄依赖只需要根据父 RDD 分区重新计算丢失的分区即可,而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父 RDD 分区,开销较大。
此外,Spark 还提供了数据检查点和记录日志,用于持久化中间 RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark 会对数据检查点开销和重新计算 RDD 分区的开销进行比较,从而自动选择最优的恢复策略
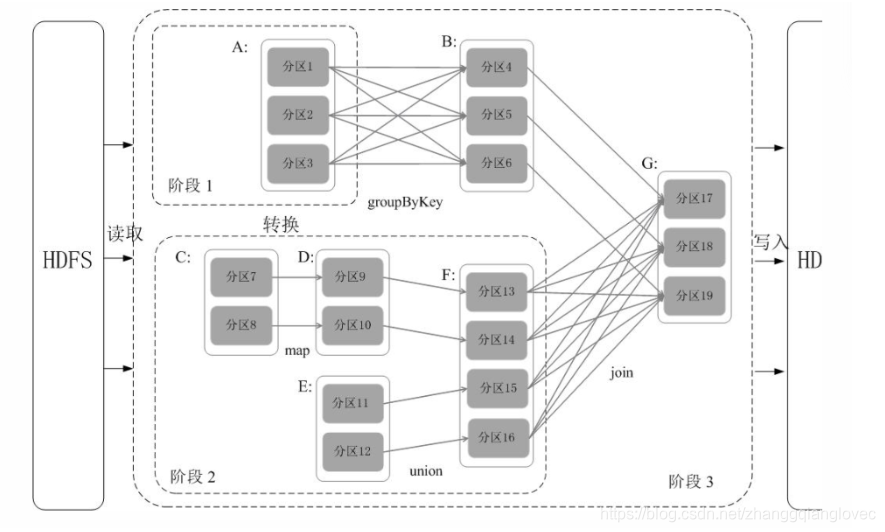
1. 阶段划分 Spark 通过分析各个 RDD 的依赖关系生成了 DAG ,再通过分析各个 RDD 中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在 DAG 中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。
。然后在执行行为操作时,反向解析 DAG,由于从 A 到 B 的转换和从 B、F 到 G 的转换都属于宽依赖,则需要从在宽依赖处进行断开,从而划分为三个阶段。把一个 DAG 图划分成多个 “阶段” 以后,每个阶段都代表了一组关联的、相互之间没有 Shuffle 依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给 Executor 运行。
spark core rdd stage 阶段
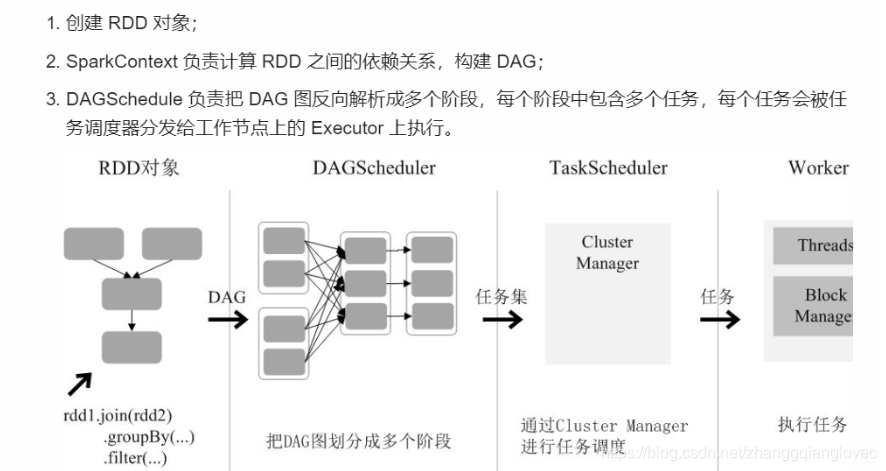
2. 运行过程 RDD 在 Spark 架构中的运行过程:
- 创建 RDD 对象;
- SparkContext 负责计算 RDD 之间的依赖关系,构建 DAG;
- DAGSchedule 负责把 DAG 图反向解析成多个阶段,每个阶段中包含多个任务,每个任务会被任务调度器分发给工作节点上的 Executor 上执行。
spark core rdd task 任务执行
参考: https://www.cnblogs.com/ydcode/p/11009323.html *****
3. 惰性操作 RDD的创建和转换方法都是惰性操作。当Spark应用调用操作方法或者保存RDD至存储系统的时候,RDD的转换计算才真正执行。惰性操作的好处:惰性操作使得Spark可以高效的执行RDD计算。直到Spark应用需要操作结果时才进行计算,Spark可以利用这一点优化RDD操作。这使得操作流水线化,而且还避免在网路间不必要的数据传输。
6.4 RDD持久化
cache/persist 是lazy算子,只有遇到action算子才会执行
Spark 的缓存具有容错机制,如果一个缓存的 RDD 的某个分区丢失了,Spark 将按照原来的计算过程,自动重新计算并进行缓存
StorageLevel类,里面设置了RDD的各种缓存级别,总共有12种
Spark非常重要的一个功能特性就是可以将RDD持久化在内存中。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD。 巧妙使用RDD持久化,甚至在某些场景下,可以将spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。
cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中去除缓存,那么可以使用unpersist()方法。
spark rdd persistence 持久化

1. RDD持久化使用场景 1、第一次加载大量的数据到RDD中 2、频繁的动态更新RDD Cache数据,不适合使用Spark Cache、Spark lineage
2. 持久化策略 MEMORY_ONLY,MEMORY_AND_DISK,MEMORY_ONLY_SER,MERORY_AND_DISK_SER,DISK_ONLY,MEMORY_ONLY_2,MEMORY_AND_DISK_2
spark rdd persisit 持久化策略

3. 持久化策略选择
策略 | 优势 | 缺陷 | 解决方案 |
|---|---|---|---|
MEMORY_ONLY | 性能最高,需要内存必须足够大,不存在序列化反序列化 | RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常 | MEMORY_ONLY_SER |
MEMORY_ONLY_SER | 比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的 | 能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常 | C |
MERORY_AND_DISK_SER | 序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘 | C | C |
DISK_ONLY和后缀为_2 | 不建议使用DISK_ONLY和后缀为_2的级别 | 完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用, 因为在内存中会有两个副本,如果其中一份内存崩溃就可以立即切换到另一份副本进行快速的计算,这就极大提升了计算,用空间换时间 | C |
// linesRDD.cache()
// linesRDD.persist(StorageLevel.MEMORY_ONLY)
// linesRDD.unpersist()- cache方法其实是persist方法的一个特例:调用的是无参数的persist(),代表缓存级别是仅内存的情况
- persist方法有三种,分为默认无参数仅内存级别的persist(),还有persist(newLevel):这个方法需要之前对RDD没有设置过缓存级别
- persist(newLevel,allowOverride):这个方法适用于之前对RDD设置过缓存级别,但是想更改缓存级别的情况。
- 取消缓存统一使用unpersist()方法
- persist是lazy级别的(前面的算子都是lazy的每执行,所以他肯定也要是lazy级别的),unpersist是eager级别的(即调用的时候会立即清除)。
缓存实现的原理:DiskStore磁盘存储和MemoryStore内存存储 DiskStore磁盘存储:spark会在磁盘上创建spark文件夹,命名为(spark-local-x年x月x日时分秒-随机数),block块都会存在这里,然后把block id映射成相应的文件路径,就可以存取文件了 MemoryStore内存存储:使用hashmap管理block就行了,block id作为key,MemoryEntry为value
4. Spark 的存储级别的选择 核心问题是在内存使用率和 CPU 效率之间进行权衡。建议按下面的过程进行存储级别的选择 :
如果使用默认的存储级别(MEMORY_ONLY),存储在内存中的 RDD 没有发生溢出,那么就选择默认的存储级别。默认存储级别可以最大程度的提高 CPU 的效率,可以使在 RDD 上的操作以最快的速度运行。 如果内存不能全部存储 RDD,那么使用 MEMORY_ONLY_SER,并挑选一个快速序列化库将对象序列化,以节省内存空间。使用这种存储级别,计算速度仍然很快。 除了在计算该数据集的代价特别高,或者在需要过滤大量数据的情况下,尽量不要将溢出的数据存储到磁盘。因为,重新计算这个数据分区的耗时与从磁盘读取这些数据的耗时差不多。 如果想快速还原故障,建议使用多副本存储级别(例如,使用 Spark 作为 web 应用的后台服务,在服务出故障时需要快速恢复的场景下)。所有的存储级别都通过重新计算丢失的数据的方式,提供了完全容错机制。但是多副本级别在发生数据丢失时,不需要重新计算对应的数据库,可以让任务继续运行。
5. 缓存删除 Spark 自动监控各个节点上的缓存使用率,并以最近最少使用的方式(LRU)将旧数据块移除内存。如果想手动移除一个 RDD,而不是等待该 RDD 被 Spark 自动移除,可以使用 RDD.unpersist() 方法
6. 缓存时机 1)计算特别耗时 2)计算链条很长,失败的时候会有很大的代价,假设900个步骤在第800个步骤缓存,801的步骤失败了就会在800个步骤开始恢复 3)shuffle之后:shuffle是进行分发数据,缓存之后假设后面失败就不需要重新shuffle 4)checkpoint之前:checkpoint是把整个数据放到分布是文件系统中或磁盘,checkpoint是在当前作业执行之后,再触发一个作业,恢复时前面的步骤就不需要计算 缓存是不一定可靠的,缓存在内存中不一定是可靠的,把数据缓存在内存中有可能会丢失,例如只缓存在内存中,而不同时放在内存和磁盘上,可能内存crash(奔溃),crash内存现在有一种办法就是用Tachyon做底层存储,但是使用checkpoint的数数据一定放在文件系统上,这个时候数据就不会丢失。假设缓存了100万个数据分片,开始缓存是成功的,由于内存的紧张在一些机器上把一些数据分片清理掉了,那这时候就需要重新计
checkpoint所在的RDD也一定要persist(在checkpoint之前,手动进行checkpoint)持久化数据,为什么?checkpoint的工作机制,是lazy级别的,在触发一个作业的时候,开始计算job,job算完之后,转过来spark的调度框架发现RDD有checkpoint标记,转过来框架本身又基于这个checkpoint再提交一个作业,checkpoint会触发一个新的作业,如果不进行持久化,进行checkpoint的时候会重算,如果第一次计算的时候就进行了persist,那么进行checkpoint的时候速度会非常的快。 5)shuffle之前persist
注意: cache之后一定不能立即有其它算子,不能直接去接算子。 因为在实际工作的时候,cache后有算子的话,它每次都会重新触发这个计算过程。 如果数据缓存到一台机器上,如果数据量比较小的话,就放在本地执行计算,如果数据量比较大的话,不幸数据被放在一台机器上了,它会先排队,宁愿等一会儿,如果不行了,就从其它机器上抓取缓存。一般情况下是不会跨越机器抓缓存的。
在 shuffle 操作中(例如 reduceByKey),即便是用户没有调用 persist 方法,Spark 也会自动缓存部分中间数据。这么做的目的是,在 shuffle 的过程中某个节点运行失败时,不需要重新计算所有的输入数据。如果用户想多次使用某个 RDD,强烈推荐在该 RDD 上调用 persist 方法。
思考: 1. cache/persist 序列化/反序列化机制?
- cache/persist 数据量大的话,其他节点怎么处理? 内存保存在单个节点还是多个节点? disk序列化和反序列化在多节点时怎么处理的?cache/persist 数据量小的话,其他节点怎么处理?
- 如果未使用cache/persist,rdd的中间数据怎么管理? 应该也时内存,只是没有缓存下来,下次应用时需要重新计算
参考: https://blog.csdn.net/qq_38617531/article/details/86893628 ***** https://blog.csdn.net/weixin_43786255/article/details/105083535 *** https://blog.csdn.net/u013007900/article/details/79287991 ** cache 的性能比对,明证cache 不一定就比没有cache性能好,需要考虑 memery 指标 https://www.jianshu.com/p/24198183e04d ** cache()和persist()的使用是有规则的: 必须在transformation或者textfile等创建一个rdd之后,直接连续调用cache()或者persist()才可以,如果先创建一个rdd,再单独另起一行执行cache()或者persist(),是没有用的,而且会报错,大量的文件会丢失。 ??? 保留质疑
6.5 Shuffle
1. 类型 HashShuffleManager Hash Based Shuffle 普通机制的Hash shuffle | 合并机制的Hash shuffle 1).普通机制:M(map task的个数)*R(reduce task的个数) 2).优化机制:C(core的个数)*R(Reduce的个数)
SortShuffleManager Sort Based Shuffle 普通运行机制 | bypass运行机制 1).普通机制:2M 2).bypass机制,没有排序:2M
2. shuffler算子 reduceByKey groupByKey join
3. shuffle性能调优 https://www.cnblogs.com/jiashengmei/p/14207320.html *****
参考: https://zhuanlan.zhihu.com/p/70331869 *** https://www.cnblogs.com/itboys/p/9226479.html * https://blog.csdn.net/zhanglh046/article/details/78360762 *** https://blog.csdn.net/zp17834994071/article/details/107873873 https://baijiahao.baidu.com/s?id=1672894335409653158&wfr=spider&for=pc https://www.jianshu.com/p/bebffc3c72bd
6.6 CheckPoint 检查点
在RDD计算,通过checkpoint进行容错,做checkpoint有两种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错,默认是logging the updates方式,通过记录跟踪所有生成RDD的转换(transformations)也就是记录每个RDD的lineage(血统)来重新计算生成丢失的分区数据。
6.7 Spark Core
CheckPoint 写流程 CheckPoint 读流程
类型 LocalRDDCheckpointData ReliableRDDCheckpointData
6.8 Join
1. Spark SQL Join
Hash Join: broadcast hash join和shuffle hash join Sort-Merge Join:
2. Spark RDD Join
参考: https://www.cnblogs.com/jiashengmei/p/14207320.html *****
3. Spark Streaming
参考: https://www.cnblogs.com/superhedantou/p/9004820.html **
// 如果采用persist把数据放在内存中,虽然是快速的,但是也是最不可靠的;如果把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏,系统管理员可能清空磁盘。 http://www.itcast.cn/news/20180911/15503121940.shtml *****
https://cloud.tencent.com/developer/article/1534001 *****
7. Fault Tolerant 容错
对于流式计算来说,容错性至关重要。首先我们要明确一下 Spark 中 RDD 的容错机制。每一个 RDD 都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系( lineage ),所以只要输入数据是可容错的,那么任意一个 RDD 的分区( Partition )出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
一般来说,分布式数据集的容错性有两种方式:数据检查点和记录数据的更新。
面向大规模数据分析,数据检查点操作成本很高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低得多,同时还需要消耗更多的存储资源。
因此, Spark 选择记录更新的方式。但是,如果更新粒度太细太多,那么记录更新成本也不低。因此, RDD 只支持粗粒度转换,即只记录单个块上执行的单个操作,然后将创建 RDD 的一系列变换序列(每个 RDD 都包含了他是如何由其他 RDD 变换过来的以及如何重建某一块数据的信息。因此 RDD 的容错机制又称“血统 (Lineage) ”容错)记录下来,以便恢复丢失的分区。
Lineage 本质上很类似于数据库中的重做日志( Redo Log ),只不过这个重做日志粒度很大,是对全局数据做同样的重做进而恢复数据。
虽然只支持粗粒度转换限制了编程模型,但我们发现 RDD 仍然可以很好地适用于很多应用,特别是支持数据并行的批量分析应用,包括数据挖掘、机器学习、图算法等,因为这些程序通常都会在很多记录上执行相同的操作。RDD 不太适合那些异步更新共享状态的应用,例如并行 web 爬行器。
对于宽依赖, Stage 计算的输入和输出在不同的节点上,对于输入节点完好,而输出节点死机的情况,通过重新计算恢复数据这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上追溯其祖先看是否可以重试(这就是 lineage ,血统的意思),窄依赖对于数据的重算开销要远小于宽依赖的数据重算开销。
窄依赖和宽依赖的概念主要用在两个地方:一个是容错中相当于 Redo 日志的功能;另一个是在调度中构建 DAG 作为不同 Stage 的划分点。
1. 依赖关系的特性
第一,窄依赖可以在某个计算节点上直接通过计算父 RDD 的某块数据计算得到子 RDD 对应的某块数据;宽依赖则要等到父 RDD 所有数据都计算完成之后,并且父 RDD 的计算结果进行 hash 并传到对应节点上之后才能计算子 RDD 。
第二,数据丢失时,对于窄依赖只需要重新计算丢失的那一块数据来恢复;对于宽依赖则要将祖先 RDD 中的所有数据块全部重新计算来恢复。所以在长“血统”链特别是有宽依赖的时候,需要在适当的时机设置数据检查点。也是这两个特性要求对于不同依赖关系要采取不同的任务调度机制和容错恢复机制。
2. 容错原理
在容错机制中,如果一个节点死机了,而且运算窄依赖,则只要把丢失的父 RDD 分区重算即可,不依赖于其他节点。而宽依赖需要父 RDD 的所有分区都存在,重算就很昂贵了。可以这样理解开销的经济与否:在窄依赖中,在子 RDD 的分区丢失、重算父 RDD 分区时,父 RDD 相应分区的所有数据都是子 RDD 分区的数据,并不存在冗余计算。在宽依赖情况下,丢失一个子 RDD 分区重算的每个父 RDD 的每个分区的所有数据并不是都给丢失的子 RDD 分区用的,会有一部分数据相当于对应的是未丢失的子 RDD 分区中需要的数据,这样就会产生冗余计算开销,这也是宽依赖开销更大的原因。因此如果使用 Checkpoint 算子来做检查点,不仅要考虑 Lineage 是否足够长,也要考虑是否有宽依赖,对宽依赖加 Checkpoint 是最物有所值的。
3. Checkpoint 机制
通过上述分析可以看出在以下两种情况下, RDD 需要加检查点。
- DAG 中的 Lineage 过长,如果重算,则开销太大(如在 PageRank 中)。
- 在宽依赖上做 Checkpoint 获得的收益更大
参考: https://cloud.tencent.com/developer/news/590420
//Checkpoint 读流程及写流程 https://blog.csdn.net/u012137473/article/details/85165048 *****
8. Lineage 血统
Spark的主要区别在于它采用血统(Lineage)来时实现分布式运算环境下的数据容错性(节点失效、数据丢失)问题, RDD Lineage被称为RDD运算图或RDD依赖关系图,是RDD所有父RDD的图,它是在RDD上执行transformations函数并创建逻辑执行计划(logical execution plan)的结果,是RDD的逻辑执行计划。相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据转换(Transformation)操作(filter, map, join etc.)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage找到丢失的父RDD的分区进行局部计算来恢复丢失的数据,这样可以节省资源提高运行效率。这种粗颗粒的数据模型,限制了Spark的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
相比其他系统的细颗粒度的内存数据更新级别的备份或者 LOG 机制, RDD 的 Lineage 记录的是粗颗粒度的特定数据 Transformation 操作(如 filter 、 map 、 join 等)行为。当这个 RDD 的部分分区数据丢失时,它可以通过 Lineage 获取足够的信息来重新运算和恢复丢失的数据分区。因为这种粗颗粒的数据模型,限制了 Spark 的运用场合,所以 Spark 并不适用于所有高性能要求的场景,但同时相比细颗粒度的数据模型,也带来了性能的提升
利用内存加快数据加载,在众多的其它的In-Memory类数据库或Cache类系统中也有实现,Spark的主要区别在于它处理分布式运算环境下的数据容错性(节点实效/数据丢失)问题时采用的方案。为了保证RDD中数据的鲁棒性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的。相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据转换(Transformation)操作(filter, map, join etc.)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区
依赖关系决定Lineage的复杂程度,同时也是的RDD具有了容错性。因为当某一个分区里的数据丢失了,Spark程序会根据依赖关系进行局部计算来恢复丢失的数据。依赖的关系主要分为2种,分别是 宽依赖(Wide Dependencies)和窄依赖(Narrow Dependencies)。
RDD.toDebugString
参考: //Executor或Worker 节点失败,处理流程图 https://blog.csdn.net/lucklilili/article/details/102834382
//Lineage 处理过程 https://blog.csdn.net/lds_include/article/details/89205952
1. 容错原理
窄依赖得容错: 子RDD分区的容错依赖分区对应的父RDD分区,不需要重新对父RDD的所有分区进行计算
spark rdd lineage 窄依赖容错
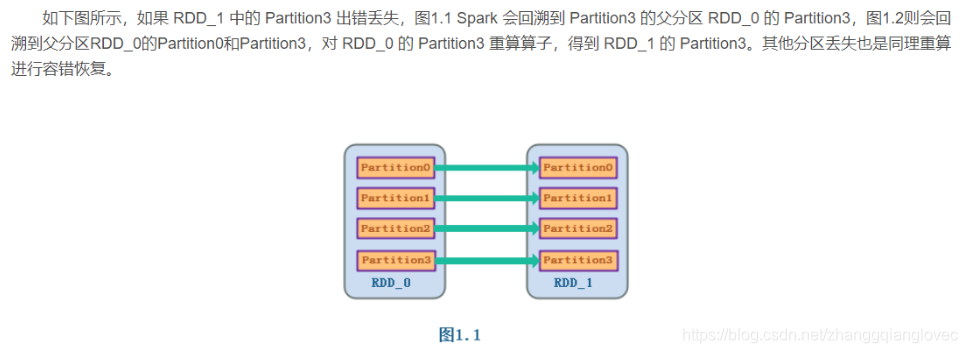
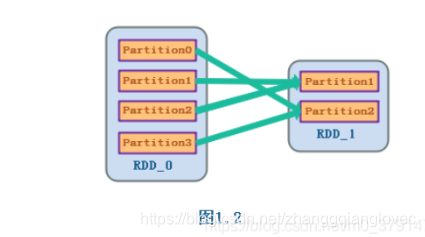
宽依赖得容错: 子RDD分区的容错需要对父RDD的所有分区进行计算,因为是宽依赖,所以没有对应的特定的父RDD分区
saprk rdd lineage 宽依赖容错
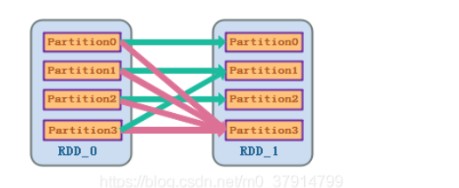
宽依赖+checkpoint: checkpoint有两种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错,默认是logging the updates方式,通过记录跟踪所有生成RDD的转换(transformations)也就是记录每个RDD的lineage(血统)来重新计算生成丢失的分区数据。在使用checkpoint算子来做检查点,不仅需要考虑Lineage长度,还也要考虑Lineage的复杂度(是否有宽依赖),对于Shuffle Dependency加Checkpoint是一个值得提倡的做法
spark rdd lineage checkpoint 宽依赖容错
参考: https://blog.csdn.net/m0_37914799/article/details/85009466 *****
9. 共享变量
参考: https://www.cnblogs.com/yy3b2007com/p/11439966.html 广播变量可以在driver程序中写入,在executor端读取。 累加器在executors中写入,而在驱动程序(driver端)读取。
1. broadcast
注意事项 1、能不能将一个RDD使用广播变量广播出去? 不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。 2、广播变量只能在Driver端定义,不能在Executor端定义。 3、在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。 4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。 5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
broadcast替代方案
- 闭包中直接捕获局部变量(动态变量不适合),这种方式每个task都有一个副本变量,比较占用网络IO
- Exector 采用单例直接加载资源文件(redis,hdfs,mysql等)
替代方案和广播得区别
- 线程安全 2.加载效率 3.存储结构
broadcast 得update spark core broad 类架构
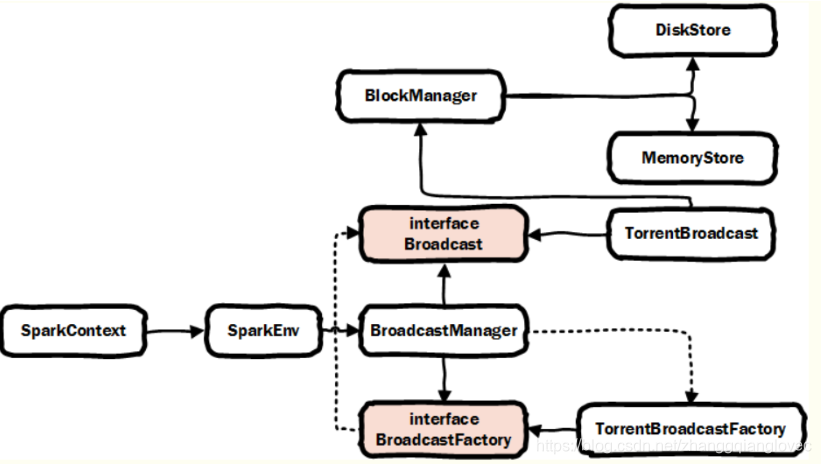
spark core broadcast 架构
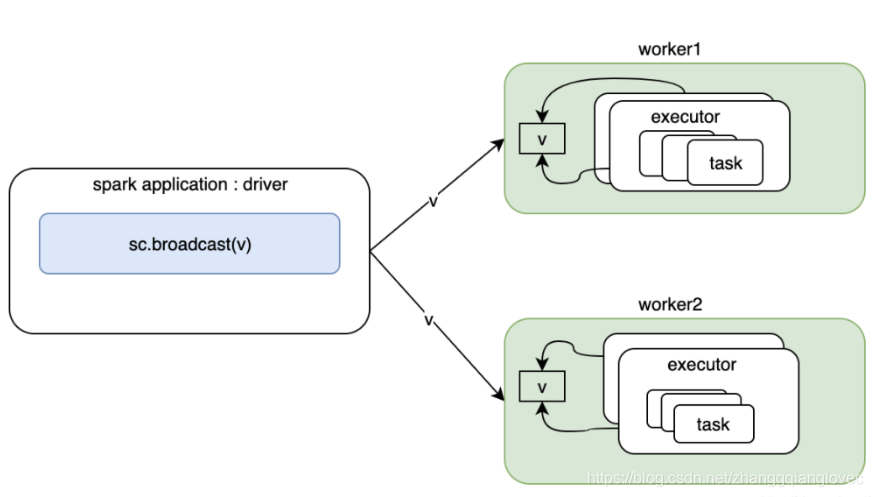
参考: https://www.cnblogs.com/yy3b2007com/p/10613035.html https://www.cnblogs.com/yy3b2007com/p/11439966.html https://blog.csdn.net/zg_hover/article/details/99712336
2. 累加器
Accumulator 类型 LongAccumulator 和自定义累加器(list,map,…)
累加器的出发时机 Transformation及Action那个合适? Transformation 使用时的注意事项? cache操作
参考: https://www.jianshu.com/p/c032f5f4ea4e
3. 闭包
闭包就是对 executors 可见的变量、方法或者代码片段。闭包会被序列化后发送给每个 executor
什么叫闭包: 跨作用域访问函数变量。又指的一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因而这些变量也是该表达式的一部分。
注意点:1.闭包中引用的变量是可序列化的(否则无法发送到executor) 2.不要在闭包中修改闭包外的变量(行为未定义)。
闭包清理 参考: https://my.oschina.net/freelili/blog/2878168
10. Spark 为什么快
参考: https://zhuanlan.zhihu.com/p/133708575
11. 数据倾斜的优化
数据倾斜优化 均匀数据分布的情况下,前面所说的优化建议就足够了。但存在数据倾斜时,仍然会有性能问题。主要体现在绝大多数task执行得都非常快,个别task执行很慢,拖慢整个任务的执行进程,甚至可能因为某个task处理的数据量过大而爆出OOM错误。
1. 分析数据分布
如果是Spark SQL中的group by、join语句导致的数据倾斜,可以使用SQL分析执行SQL中的表的key分布情况;如果是Spark RDD执行shuffle算子导致的数据倾斜,可以在Spark作业中加入分析Key分布的代码,使用countByKey()统计各个key对应的记录数
2. 数据倾斜的解决方案
1>.针对hive表中的数据倾斜,可以尝试通过hive进行数据预处理,如按照key进行聚合,或是和其他表join,Spark作业中直接使用预处理后的数据。 2>.如果发现导致倾斜的key就几个,而且对计算本身的影响不大,可以考虑过滤掉少数导致倾斜的key 3>.设置参数spark.sql.shuffle.partitions,提高shuffle操作的并行度,增加shuffle read task的数量,降低每个task处理的数据量 4>.针对RDD执行reduceByKey等聚合类算子或是在Spark SQL中使用group by语句时,可以考虑两阶段聚合方案,即局部聚合+全局聚合。第一阶段局部聚合,先给每个key打上一个随机数,接着对打上随机数的数据执行reduceByKey等聚合操作,然后将各个key的前缀去掉。第二阶段全局聚合即正常的聚合操作。 5>.针对两个数据量都比较大的RDD/hive表进行join的情况,如果其中一个RDD/hive表的少数key对应的数据量过大,另一个比较均匀时,可以先分析数据,将数据量过大的几个key统计并拆分出来形成一个单独的RDD,得到的两个RDD/hive表分别和另一个RDD/hive表做join,其中key对应数据量较大的那个要进行key值随机数打散处理,另一个无数据倾斜的RDD/hive表要1对n膨胀扩容n倍,确保随机化后key值仍然有效。 6>.针对join操作的RDD中有大量的key导致数据倾斜,对有数据倾斜的整个RDD的key值做随机打散处理,对另一个正常的RDD进行1对n膨胀扩容,每条数据都依次打上0~n的前缀。处理完后再执行join操作 参考: https://www.cnblogs.com/jiashengmei/p/14207320.html *****
12. Spark 性能调优
- spark rdd join时,俩个rdd都比较大时的处理逻辑?
- broadcast 数据量比较大时?
- spark sql join时的处理逻辑?
- sparksql 及spark rdd shuffle 导致的数据倾斜的优化?
- shuffle的性能优化?
- join性能优化? 参考: https://www.cnblogs.com/jiashengmei/p/14207320.html *****
三. 其他
1. 思考
- Spark 为什么快? 内存及线程
- Spark 四大特性
- Spark 主要进程
- Spark 底层的通信框架是什么? akka/netty 2.0
- Spark 有性能瓶颈吗? 有什么是Spark不能做但是Hadoop 可以处理? 数据量大于内存的情况
- 如何选型Spark 处理还是Hadoop 处理?
- spark rdd 对于的map/reduce的excetor 执行器个数
- spark rdd 的默认分片
- spark 闭包
- spark windows
- spark 共享变量
- spark shuffle
2. 参考
//外部参数传递 https://blog.csdn.net/weixin_40294332/article/details/97394975
//spark 参数解析 https://www.cnblogs.com/gxc2015/p/10112865.html
https://blog.csdn.net/zax_java/article/details/96964520 *** https://blog.csdn.net/knidly/article/details/80268871 ***** https://www.pianshen.com/article/38341005968/ *****
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-03-28,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号